") 【AI簡(jiǎn)報(bào)第20230217期】超越GPT 3.5的小模型來(lái)了!AI網(wǎng)戀詐騙時(shí)代開(kāi)啟
【AI簡(jiǎn)報(bào)第20230217期】超越GPT 3.5的小模型來(lái)了!AI網(wǎng)戀詐騙時(shí)代開(kāi)啟
嵌入式 AI
AI 簡(jiǎn)報(bào) 20230217 期
1. 超越GPT 3.5的小模型來(lái)了!
原文:https://mp.weixin.qq.com/s/gv_FJD0aIpDNbky54unj2Q
論文地址:https://arxiv.org/abs/2302.00923
項(xiàng)目地址:https://github.com/amazon-science/mm-cot
去年年底,OpenAI 向公眾推出了 ChatGPT,一經(jīng)發(fā)布,這項(xiàng)技術(shù)立即將 AI 驅(qū)動(dòng)的聊天機(jī)器人推向了主流話語(yǔ)的中心,眾多研究者并就其如何改變商業(yè)、教育等展開(kāi)了一輪又一輪辯論。
隨后,科技巨頭們紛紛跟進(jìn)投入科研團(tuán)隊(duì),他們所謂的「生成式 AI」技術(shù)(可以制作對(duì)話文本、圖形等的技術(shù))也已準(zhǔn)備就緒。
眾所周知,ChatGPT 是在 GPT-3.5 系列模型的基礎(chǔ)上微調(diào)而來(lái)的,我們看到很多研究也在緊隨其后緊追慢趕,但是,與 ChatGPT 相比,他們的新研究效果到底有多好?近日,亞馬遜發(fā)布的一篇論文《Multimodal Chain-of-Thought Reasoning in Language Models》中,他們提出了包含視覺(jué)特征的 Multimodal-CoT,該架構(gòu)在參數(shù)量小于 10 億的情況下,在 ScienceQA 基準(zhǔn)測(cè)試中,比 GPT-3.5 高出 16 個(gè)百分點(diǎn) (75.17%→91.68%),甚至超過(guò)了許多人類(lèi)。
這里簡(jiǎn)單介紹一下 ScienceQA 基準(zhǔn)測(cè)試,它是首個(gè)標(biāo)注詳細(xì)解釋的多模態(tài)科學(xué)問(wèn)答數(shù)據(jù)集 ,由 UCLA 和艾倫人工智能研究院(AI2)提出,主要用于測(cè)試模型的多模態(tài)推理能力,有著非常豐富的領(lǐng)域多樣性,涵蓋了自然科學(xué)、語(yǔ)言科學(xué)和社會(huì)科學(xué)領(lǐng)域,對(duì)模型的邏輯推理能力提出了很高的要求。

下面我們來(lái)看看亞馬遜的語(yǔ)言模型是如何超越 GPT-3.5 的。
包含視覺(jué)特征的 Multimodal-CoT
大型語(yǔ)言模型 (LLM) 在復(fù)雜推理任務(wù)上表現(xiàn)出色,離不開(kāi)思維鏈 (CoT) 提示的助攻。然而,現(xiàn)有的 CoT 研究只關(guān)注語(yǔ)言模態(tài)。為了在多模態(tài)中觸發(fā) CoT 推理,一種可能的解決方案是通過(guò)融合視覺(jué)和語(yǔ)言特征來(lái)微調(diào)小型語(yǔ)言模型以執(zhí)行 CoT 推理。
然而,根據(jù)已有觀察,小模型往往比大模型更能頻繁地胡編亂造,模型的這種行為通常被稱(chēng)為「幻覺(jué)(hallucination)」。此前谷歌的一項(xiàng)研究也表明( 論文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ),基于 CoT 的提示只有在模型具有至少 1000 億參數(shù)時(shí)才有用!
也就是說(shuō),CoT 提示不會(huì)對(duì)小型模型的性能產(chǎn)生積極影響,并且只有在與 ~100B 參數(shù)的模型一起使用時(shí)才會(huì)產(chǎn)生性能提升。
然而,本文研究在小于 10 億參數(shù)的情況下就產(chǎn)生了性能提升,是如何做到的呢?簡(jiǎn)單來(lái)講,本文提出了包含視覺(jué)特征的 Multimodal-CoT,通過(guò)這一范式(Multimodal-CoT)來(lái)尋找多模態(tài)中的 CoT 推理。
Multimodal-CoT 將視覺(jué)特征結(jié)合在一個(gè)單獨(dú)的訓(xùn)練框架中,以減少語(yǔ)言模型有產(chǎn)生幻覺(jué)推理模式傾向的影響。總體而言,該框架將推理過(guò)程分為兩部分:基本原理生成(尋找原因)和答案推理(找出答案)。
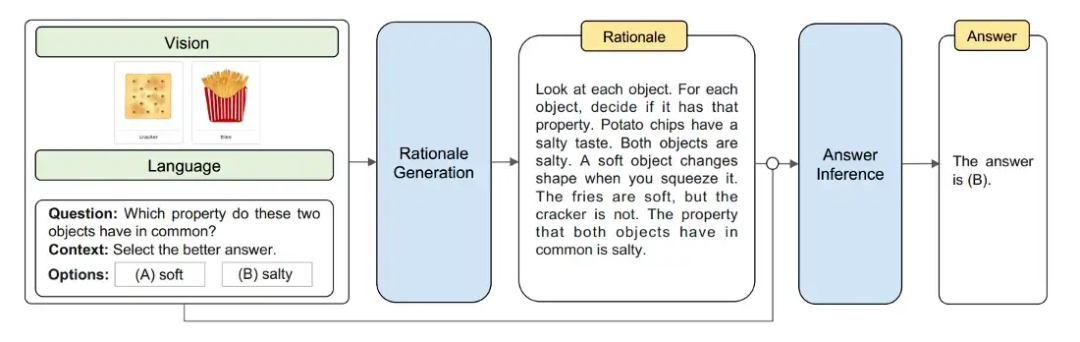
數(shù)據(jù)集
本文主要關(guān)注 ScienceQA 數(shù)據(jù)集,該數(shù)據(jù)集將圖像和文本作為上下文的一部分,此外,該數(shù)據(jù)集還包含對(duì)答案的解釋?zhuān)员憧梢詫?duì)模型進(jìn)行微調(diào)以生成 CoT 基本原理。此外,本文利用 DETR 模型生成視覺(jué)特征。
較小的 LM 在生成 CoT / 基本原理時(shí)容易產(chǎn)生幻覺(jué),作者推測(cè),如果有一個(gè)修改過(guò)的架構(gòu),模型可以利用 LM 生成的文本特征和圖像模型生成的視覺(jué)特征,那么 更有能力提出理由和回答問(wèn)題。
架構(gòu)
總的來(lái)說(shuō),我們需要一個(gè)可以生成文本特征和視覺(jué)特征并利用它們生成文本響應(yīng)的模型。
又已知文本和視覺(jué)特征之間存在的某種交互,本質(zhì)上是某種共同注意力機(jī)制,這有助于封裝兩種模態(tài)中存在的信息,這就讓借鑒思路成為了可能。為了完成所有這些,作者選擇了 T5 模型,它具有編碼器 - 解碼器架構(gòu),并且如上所述,DETR 模型用于生成視覺(jué)特征。
T5 模型的編碼器負(fù)責(zé)生成文本特征,但 T5 模型的解碼器并沒(méi)有利用編碼器產(chǎn)生的文本特征,而是使用作者提出的共同注意式交互層(co-attention-styled interaction layer)的輸出。
拆解來(lái)看,假設(shè) H_language 是 T5 編碼器的輸出。X_vision 是 DETR 的輸出。第一步是確保視覺(jué)特征和文本特征具有相同的隱藏大小,以便我們可以使用注意力層。
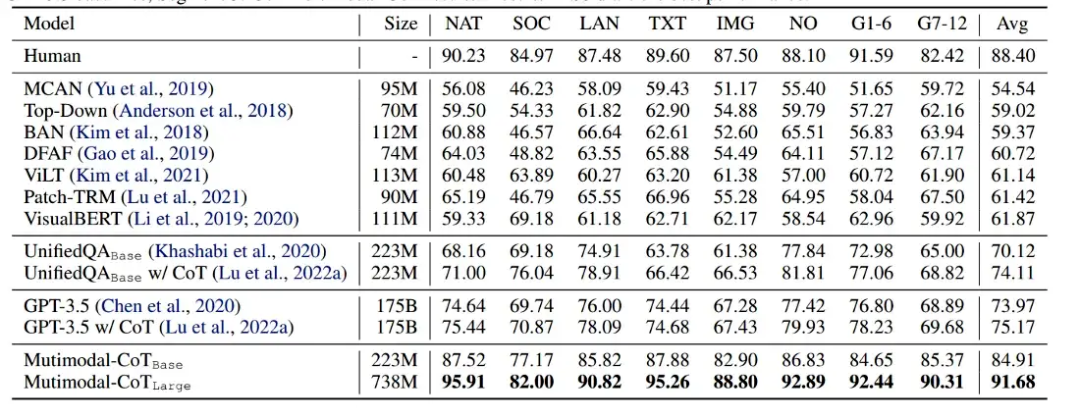
結(jié)果
作者使用 UnifiedQA 模型的權(quán)重作為 T5 模型的初始化點(diǎn),并在 ScienceQA 數(shù)據(jù)集上對(duì)其進(jìn)行微調(diào)。他們觀察到他們的 Multimodal CoT 方法優(yōu)于所有以前的基準(zhǔn),包括 GPT-3.5。
有趣的地方在于,即使只有 2.23 億個(gè)參數(shù)的基本模型也優(yōu)于 GPT-3.5 和其他 Visual QA 模型!這突出了擁有多模態(tài)架構(gòu)的力量。
結(jié)論
這篇論文帶來(lái)的最大收獲是多模態(tài)特征在解決具有視覺(jué)和文本特征的問(wèn)題時(shí)是多么強(qiáng)大。
作者展示了利用視覺(jué)特征,即使是小型語(yǔ)言模型(LM)也可以產(chǎn)生有意義的思維鏈 / 推理,而幻覺(jué)要少得多,這揭示了視覺(jué)模型在發(fā)展基于思維鏈的學(xué)習(xí)技術(shù)中可以發(fā)揮的作用。
從實(shí)驗(yàn)中,我們看到以幾百萬(wàn)個(gè)參數(shù)為代價(jià)添加視覺(jué)特征的方式,比將純文本模型擴(kuò)展到數(shù)十億個(gè)參數(shù)能帶來(lái)更大的價(jià)值。
2. AI照騙恐怖如斯!美女刷屏真假難辨,網(wǎng)友:AI網(wǎng)戀詐騙時(shí)代開(kāi)啟
原文:https://mp.weixin.qq.com/s/nELNzal7tjkbZ6uKkuGkeA
什么?這些不是真人照片,都是AI畫(huà)出來(lái)的?!
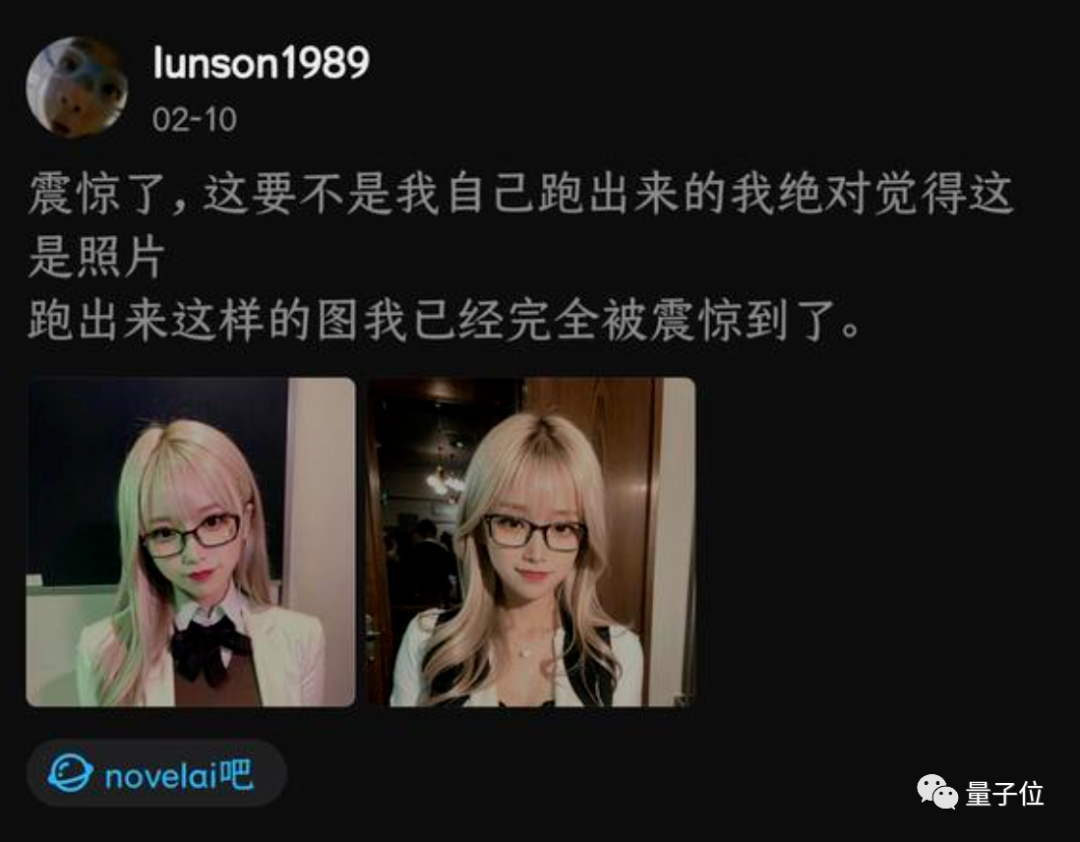
最近這樣一組美女圖片刷屏了,許多人看到第一反應(yīng)都是“AI逼真到這個(gè)份上了?”。

直到看到手部露出了破綻,才敢確定確實(shí)是AI畫(huà)的。

嗯….啥都不想說(shuō),看就得了,感興趣的小伙伴直接查看原文。
3. YOLOv7農(nóng)業(yè)方向應(yīng)用|基于注意力機(jī)制改進(jìn)的YOLOv7算法CBAM-YOLOv7
原文:https://mp.weixin.qq.com/s/HXKsTnSbr8Ks1VF2p7RoTA
論文鏈接:https://www.mdpi.com/2077-0472/12/10/1659/pdf
飼養(yǎng)密度是影響畜禽大規(guī)模生產(chǎn)和動(dòng)物福利的關(guān)鍵因素。然而,麻鴨養(yǎng)殖業(yè)目前使用的人工計(jì)數(shù)方法效率低、人工成本高、精度低,而且容易重復(fù)計(jì)數(shù)和遺漏。
在這方面,本文使用深度學(xué)習(xí)算法來(lái)實(shí)現(xiàn)對(duì)密集麻鴨群數(shù)量的實(shí)時(shí)監(jiān)測(cè),并促進(jìn)智能農(nóng)業(yè)產(chǎn)業(yè)的發(fā)展。本文構(gòu)建了一個(gè)新的大規(guī)模大麻鴨目標(biāo)檢測(cè)圖像數(shù)據(jù)集,其中包含1500個(gè)大麻鴨目標(biāo)的檢測(cè)全身幀標(biāo)記和僅頭部幀標(biāo)記。
此外,本文提出了一種基于注意力機(jī)制改進(jìn)的YOLOv7算法CBAM-YOLOv7,在YOLOv7的主干網(wǎng)絡(luò)中添加了3個(gè)CBAM模塊,以提高網(wǎng)絡(luò)提取特征的能力,并引入SE-YOLOv7和ECA-YOLOv7進(jìn)行比較實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明,CBAM-YOLOv7具有較高的精度,mAP@0.5和mAP@0.5:0.95略有改善。CBAM-YOLOv7的評(píng)價(jià)指標(biāo)值比SE-YOLOw7和ECA-YOLOv 7的提高更大。此外,還對(duì)兩種標(biāo)記方法進(jìn)行了比較測(cè)試,發(fā)現(xiàn)僅頭部標(biāo)記方法導(dǎo)致了大量特征信息的丟失,而全身框架標(biāo)記方法顯示了更好的檢測(cè)效果。
算法性能評(píng)估結(jié)果表明,本文提出的智能麻鴨計(jì)數(shù)方法是可行的,可以促進(jìn)智能可靠的自動(dòng)計(jì)數(shù)方法的發(fā)展。

隨著技術(shù)的發(fā)展,監(jiān)控設(shè)備在農(nóng)業(yè)中發(fā)揮著巨大的作用。有多種方法可以監(jiān)測(cè)個(gè)體動(dòng)物的行為,例如插入芯片記錄生理數(shù)據(jù)、使用可穿戴傳感器和(熱)成像技術(shù)。一些方法使用附著在鳥(niǎo)類(lèi)腳上的可穿戴傳感器來(lái)測(cè)量它們的活動(dòng),但這可能會(huì)對(duì)受監(jiān)測(cè)的動(dòng)物產(chǎn)生額外影響。特別是,在商業(yè)環(huán)境中,技術(shù)限制和高成本導(dǎo)致這種方法的可行性低。
因此,基于光流的視頻評(píng)估將是監(jiān)測(cè)家禽行為和生理的理想方法。最初,許多監(jiān)控視頻都是人工觀察的,效率低下,依賴(lài)于工作人員的經(jīng)驗(yàn)判斷,沒(méi)有標(biāo)準(zhǔn)。然而,近年來(lái),由于大數(shù)據(jù)時(shí)代的到來(lái)和計(jì)算機(jī)圖形卡的快速發(fā)展,計(jì)算機(jī)的計(jì)算能力不斷增強(qiáng),加速了人工智能的發(fā)展。與人工智能相關(guān)的研究正在增加,計(jì)算機(jī)視覺(jué)在動(dòng)物檢測(cè)中的應(yīng)用越來(lái)越廣泛。
例如,2014年Girshick等人提出的R-CNN首次引入了兩階段檢測(cè)方法。該方法使用深度卷積網(wǎng)絡(luò)來(lái)獲得優(yōu)異的目標(biāo)檢測(cè)精度,但其許多冗余操作大大增加了空間和時(shí)間成本,并且難以在實(shí)際的養(yǎng)鴨場(chǎng)中部署。Law等人提出了一種單階段的目標(biāo)檢測(cè)方法CornerNet和一種新的池化方法:角點(diǎn)池化。
然而,基于關(guān)鍵點(diǎn)的方法經(jīng)常遇到大量不正確的目標(biāo)邊界框,這限制了其性能,無(wú)法滿(mǎn)足鴨子飼養(yǎng)模型的高性能要求。Duan等人在CornerNet的基礎(chǔ)上構(gòu)建了CenterNet框架,以提高準(zhǔn)確性和召回率,并設(shè)計(jì)了兩個(gè)對(duì)特征級(jí)噪聲具有更強(qiáng)魯棒性的自定義模塊,但Anchor-Free方法是一個(gè)具有前兩個(gè)關(guān)鍵點(diǎn)組合的過(guò)程,并且由于網(wǎng)絡(luò)結(jié)構(gòu)簡(jiǎn)單、處理耗時(shí)、速率低和測(cè)量結(jié)果不穩(wěn)定,它不能滿(mǎn)足麻鴨工業(yè)化養(yǎng)殖所需的高性能和高準(zhǔn)確率的要求。
本文的工作使用了一種單階段目標(biāo)檢測(cè)算法,它只需要提取特征一次,就可以實(shí)現(xiàn)目標(biāo)檢測(cè),其性能高于多階段算法。目前,主流的單階段目標(biāo)檢測(cè)算法主要包括YOLO系列、SSD、RetinaNet等。本文將基于CNN的人群計(jì)數(shù)思想轉(zhuǎn)移并應(yīng)用到鴨計(jì)數(shù)問(wèn)題中。隨著檢測(cè)結(jié)果的輸出,作者嵌入了一個(gè)目標(biāo)計(jì)數(shù)模塊來(lái)響應(yīng)工業(yè)化的需求。目標(biāo)計(jì)數(shù)也是計(jì)算機(jī)視覺(jué)領(lǐng)域的一項(xiàng)常見(jiàn)任務(wù)。目標(biāo)計(jì)數(shù)可分為多類(lèi)別目標(biāo)計(jì)數(shù)和單類(lèi)別目標(biāo)計(jì)數(shù);本工作采用了一群大麻鴨的單類(lèi)別計(jì)數(shù)。
本文希望實(shí)現(xiàn)的目標(biāo)是:
建立了一個(gè)新的大規(guī)模的德雷克圖像數(shù)據(jù)集,并將其命名為“大麻鴨數(shù)據(jù)集”。大麻鴨數(shù)據(jù)集包含1500個(gè)標(biāo)簽,用于全身框架和頭部框架,用于鴨的目標(biāo)檢測(cè)。該團(tuán)隊(duì)首次發(fā)布了大麻鴨數(shù)據(jù)集
本研究構(gòu)建了大鴨識(shí)別、大鴨目標(biāo)檢測(cè)、大鴨圖像計(jì)數(shù)等全面的工作基線,實(shí)現(xiàn)了麻鴨的智能養(yǎng)殖
該項(xiàng)目模型引入了CBAM模塊來(lái)構(gòu)建CBAM-YOLOv7算法
本文很長(zhǎng),同時(shí)基礎(chǔ)理論和背景介紹的非常詳細(xì),感興趣的小伙伴可以翻看原文,進(jìn)行研究。
4. AutoML并非全能神器!新綜述爆火,網(wǎng)友:了解深度學(xué)習(xí)領(lǐng)域現(xiàn)狀必讀
原文:https://mp.weixin.qq.com/s/qR2bMaZby299PlEHUlNoBQ
如今深度學(xué)習(xí)模型開(kāi)發(fā)已經(jīng)非常成熟,進(jìn)入大規(guī)模應(yīng)用階段。
然而,在設(shè)計(jì)模型時(shí),不可避免地會(huì)經(jīng)歷迭代這一過(guò)程,它也正是造成模型設(shè)計(jì)復(fù)雜、成本巨高的核心原因,此前通常由經(jīng)驗(yàn)豐富的工程師來(lái)完成。
之所以迭代過(guò)程如此“燒金”,是因?yàn)樵谶@一過(guò)程中,面臨大量的開(kāi)放性問(wèn)題 (open problems)。
這些開(kāi)放性問(wèn)題究竟會(huì)出現(xiàn)在哪些地方?又要如何解決、能否并行化解決?
現(xiàn)在一篇論文綜述終于對(duì)此做出介紹,發(fā)出后立刻在網(wǎng)上爆火。
作者嚴(yán)謹(jǐn)?shù)貐⒖剂?strong style="font-size: inherit;color: inherit;line-height: inherit;">接近300篇文獻(xiàn),對(duì)大量應(yīng)用深度學(xué)習(xí)中的開(kāi)放問(wèn)題進(jìn)行分析,力求讓讀者一文了解該領(lǐng)域最新趨勢(shì)。

這篇論文要研究什么?
眾所周知,當(dāng)我們拿到一個(gè)機(jī)器學(xué)習(xí)問(wèn)題時(shí),通常處理的流程分為以下幾步:收集數(shù)據(jù)、編寫(xiě)模型、訓(xùn)練模型、評(píng)估模型、迭代、測(cè)試、產(chǎn)品化。
在這篇論文中,作者把上述這些流程比作一個(gè)雙層次的最佳化問(wèn)題。
內(nèi)層優(yōu)化回路需要最小化衡量模型效果評(píng)估的損失函數(shù),背后是為了尋求最佳模型參數(shù)而進(jìn)行的深入研究的訓(xùn)練過(guò)程。
而外層優(yōu)化回路的研究較少,包括最大化一個(gè)適當(dāng)選擇的性能指標(biāo)來(lái)評(píng)估驗(yàn)證數(shù)據(jù),這正是我們所說(shuō)的“迭代過(guò)程”,也就是追求最優(yōu)模型超參數(shù)的過(guò)程。
不過(guò),值得注意的是,面對(duì)不同的問(wèn)題,它的解也需要特定分析,有時(shí)候情況甚至?xí)浅?fù)雜。
例如,評(píng)估度量Mval是一個(gè)離散且不可微的函數(shù)。它并未被很好地定義,有時(shí)候甚至在某些自我監(jiān)督式和非監(jiān)督式學(xué)習(xí)以及生成模型問(wèn)題中不存在。
同時(shí),你也可能設(shè)計(jì)了一個(gè)非常好的損失函數(shù)Ltrain,結(jié)果發(fā)現(xiàn)它是離散或不可微的,這種情況下它會(huì)變得非常棘手,需要用特定方法加以解決。
因此,本篇論文的研究重點(diǎn)就是迭代過(guò)程中遇到的各種開(kāi)放性問(wèn)題,以及這些問(wèn)題中可以并行解決優(yōu)化的部分案例。
機(jī)器學(xué)習(xí)中開(kāi)放問(wèn)題有哪些?
論文將開(kāi)放性問(wèn)題類(lèi)型分為監(jiān)督學(xué)習(xí)和其他方法兩大類(lèi)。
值得一提的是,無(wú)論是監(jiān)督學(xué)習(xí)還是其他方法,作者都貼心地附上了對(duì)應(yīng)的教程地址:
如果對(duì)概念本身還不了解的話,點(diǎn)擊就能直接學(xué)到他教授的視頻課程,不用擔(dān)心有困惑的地方。
首先來(lái)看看監(jiān)督學(xué)習(xí)。
這里我們不得不提到AutoML。作為一種用來(lái)降低開(kāi)發(fā)過(guò)程中迭代復(fù)雜度的“偷懶”方法,它目前在機(jī)器學(xué)習(xí)中已經(jīng)應(yīng)用廣泛了。
通常來(lái)說(shuō),AutoML更側(cè)重于在監(jiān)督學(xué)習(xí)方法中的應(yīng)用,尤其是圖像分類(lèi)問(wèn)題。
畢竟圖像分類(lèi)可以明確采用精度作為評(píng)估指標(biāo),使用AutoML非常方便。
但如果同時(shí)考慮多個(gè)因素,尤其是包括計(jì)算效率在內(nèi),這些方法是否還能進(jìn)一步被優(yōu)化?
在這種情況下,如何提升性能就成為了一類(lèi)開(kāi)放性問(wèn)題,具體又分為以下幾類(lèi):
大模型、小模型、模型魯棒性、可解釋AI、遷移學(xué)習(xí)、語(yǔ)義分割、超分辨率&降噪&著色、姿態(tài)估計(jì)、光流&深度估計(jì)、目標(biāo)檢測(cè)、人臉識(shí)別&檢測(cè)、視頻&3D模型等。
這些不同的領(lǐng)域也面臨不同的開(kāi)放性問(wèn)題。
例如大模型中的學(xué)習(xí)率并非常數(shù)、而是函數(shù),會(huì)成為開(kāi)放問(wèn)題之一,相比之下小模型卻更考慮性能和內(nèi)存(或計(jì)算效率)的權(quán)衡這種開(kāi)放性問(wèn)題。
其中,小模型通常會(huì)應(yīng)用到物聯(lián)網(wǎng)、智能手機(jī)這種小型設(shè)備中,相比大模型需求算力更低。
又例如對(duì)于目標(biāo)檢測(cè)這樣的模型而言,如何優(yōu)化不同目標(biāo)之間檢測(cè)的準(zhǔn)確度,同樣是一種復(fù)雜的開(kāi)放性問(wèn)題。
在這些開(kāi)放性問(wèn)題中,有不少可以通過(guò)并行方式解決。如在遷移學(xué)習(xí)中,迭代時(shí)學(xué)習(xí)到的特征會(huì)對(duì)下游任務(wù)可泛化性和可遷移性同時(shí)產(chǎn)生什么影響,就是一個(gè)可以并行研究的過(guò)程。
同時(shí),并行處理開(kāi)放性問(wèn)題面臨的難度也不一樣。
例如基于3D點(diǎn)云數(shù)據(jù)同時(shí)施行目標(biāo)識(shí)別、檢測(cè)和語(yǔ)義分割,比基于2D圖像的目標(biāo)識(shí)別、檢測(cè)和分割任務(wù)更具挑戰(zhàn)性。
再來(lái)看看監(jiān)督學(xué)習(xí)以外的其他方法,具體又分為這幾類(lèi):
自然語(yǔ)言處理(NLP)、多模態(tài)學(xué)習(xí)、生成網(wǎng)絡(luò)、域適應(yīng)、少樣本學(xué)習(xí)、半監(jiān)督&自監(jiān)督學(xué)習(xí)、語(yǔ)音模型、強(qiáng)化學(xué)習(xí)、物理知識(shí)學(xué)習(xí)等。
以自然語(yǔ)言處理為例,其中的多任務(wù)學(xué)習(xí)會(huì)給模型帶來(lái)新的開(kāi)放性問(wèn)題。
像經(jīng)典的BERT模型,本身不具備翻譯能力,因此為了同時(shí)提升多種下游任務(wù)性能指標(biāo),研究者們需要權(quán)衡各種目標(biāo)函數(shù)之間的結(jié)果。
又如生成模型中的CGAN(條件GAN),其中像圖像到圖像翻譯問(wèn)題,即將一張圖片轉(zhuǎn)換為另一張圖片的過(guò)程。
這一過(guò)程要求將多個(gè)獨(dú)立損失函數(shù)進(jìn)行加權(quán)組合,并讓總損失函數(shù)最小化,就又是一個(gè)開(kāi)放性問(wèn)題。
其他不同的問(wèn)題和模型,也分別都會(huì)在特定應(yīng)用上遇到不同類(lèi)型的開(kāi)放性問(wèn)題,因此具體問(wèn)題依舊得具體分析。
經(jīng)過(guò)對(duì)各類(lèi)機(jī)器學(xué)習(xí)領(lǐng)域進(jìn)行分析后,作者得出了自己的一些看法。
一方面,AI表面上是一種“自動(dòng)化”的過(guò)程,從大量數(shù)據(jù)中產(chǎn)生自己的理解,然而這其中其實(shí)涉及大量的人為操作,有不少甚至是重復(fù)行為,這被稱(chēng)之為“迭代過(guò)程”。
另一方面,這些工作雖然能部分通過(guò)AutoML精簡(jiǎn),然而AutoML目前只在圖像分類(lèi)中有較好的表現(xiàn),并不意味著它在其他領(lǐng)域任務(wù)中會(huì)取得成功。
總而言之,應(yīng)用深度學(xué)習(xí)中的開(kāi)放性問(wèn)題,依舊比許多人想象得要更為復(fù)雜。
論文地址:https://arxiv.org/abs/2301.11316
5. ChatGPT的技術(shù)體系總結(jié)
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
0.參考資料
RLHF論文:Training language models to follow instructions with human feedback(https://arxiv.org/pdf/2203.02155.pdf)
摘要上下文中的 RLHF:Learning to summarize from Human Feedback (https://arxiv.org/pdf/2009.01325.pdf)
PPO論文:Proximal Policy Optimization Algorithms(https://arxiv.org/pdf/1707.06347.pdf)
Deep reinforcement learning from human preferences (https://arxiv.org/abs/1706.03741)
1.引言
1.1 ChatGPT的介紹
作為一個(gè) AI Chatbot,ChatGPT 是當(dāng)前比較強(qiáng)大的自然語(yǔ)言處理模型之一,它基于 Google 的 T5 模型進(jìn)行了改進(jìn),同時(shí)加入了許多自然語(yǔ)言處理的技術(shù),使得它可以與人類(lèi)進(jìn)行自然的、連貫的對(duì)話。ChatGPT 使用了 GPT(Generative Pre-training Transformer)架構(gòu),它是一種基于 Transformer 的預(yù)訓(xùn)練語(yǔ)言模型。GPT 的主要思想是將大量的語(yǔ)料庫(kù)輸入到模型中進(jìn)行訓(xùn)練,使得模型能夠理解和學(xué)習(xí)語(yǔ)言的語(yǔ)法、語(yǔ)義等信息,從而生成自然、連貫的文本。與其他 Chatbot 相比,ChatGPT 的優(yōu)勢(shì)在于它可以進(jìn)行上下文感知型的對(duì)話,即它可以記住上下文信息,而不是簡(jiǎn)單地匹配預(yù)先定義的規(guī)則或模式。此外,ChatGPT 還可以對(duì)文本進(jìn)行生成和理解,支持多種對(duì)話場(chǎng)景和話題,包括閑聊、知識(shí)問(wèn)答、天氣查詢(xún)、新聞閱讀等等。
盡管 ChatGPT 在自然語(yǔ)言處理領(lǐng)域已經(jīng)取得了很好的表現(xiàn),但它仍然存在一些局限性,例如對(duì)于一些復(fù)雜的、領(lǐng)域特定的問(wèn)題,它可能無(wú)法給出正確的答案,需要通過(guò)人類(lèi)干預(yù)來(lái)解決。因此,在使用 ChatGPT 進(jìn)行對(duì)話時(shí),我們?nèi)孕枰?jǐn)慎對(duì)待,盡可能提供明確、簡(jiǎn)潔、準(zhǔn)確的問(wèn)題,以獲得更好的對(duì)話體驗(yàn)。
1.2 ChatGPT的訓(xùn)練模式
ChatGPT 的訓(xùn)練模式是基于大規(guī)模文本數(shù)據(jù)集的監(jiān)督學(xué)習(xí)和自我監(jiān)督學(xué)習(xí),這些數(shù)據(jù)集包括了各種類(lèi)型的文本,例如新聞文章、博客、社交媒體、百科全書(shū)、小說(shuō)等等。ChatGPT 通過(guò)這些數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練,然后在特定任務(wù)的數(shù)據(jù)集上進(jìn)行微調(diào)。
對(duì)于 Reinforcement Learning from Human Feedback 的訓(xùn)練方式,ChatGPT 通過(guò)與人類(lèi)進(jìn)行對(duì)話來(lái)進(jìn)行模型訓(xùn)練。具體而言,它通過(guò)與人類(lèi)進(jìn)行對(duì)話,從而了解人類(lèi)對(duì)話的語(yǔ)法、語(yǔ)義和上下文等方面的信息,并從中學(xué)習(xí)如何生成自然、連貫的文本。當(dāng) ChatGPT 生成回復(fù)時(shí),人類(lèi)可以對(duì)其進(jìn)行反饋,例如“好的”、“不太好”等等,這些反饋將被用來(lái)調(diào)整模型參數(shù),以提高 ChatGPT 的回復(fù)質(zhì)量。Reinforcement Learning from Human Feedback 的訓(xùn)練方式,可以使 ChatGPT 更加智能,更好地模擬人類(lèi)的思維方式。不過(guò)這種訓(xùn)練方式也存在一些問(wèn)題,例如人類(lèi)反饋的主觀性和不確定性等,這些問(wèn)題可能會(huì)影響模型的訓(xùn)練效果。因此,我們需要在使用 ChatGPT 進(jìn)行對(duì)話時(shí),謹(jǐn)慎對(duì)待反饋,盡可能提供明確、簡(jiǎn)潔、準(zhǔn)確的反饋,以獲得更好的對(duì)話體驗(yàn)。
1.3 RLHF的介紹
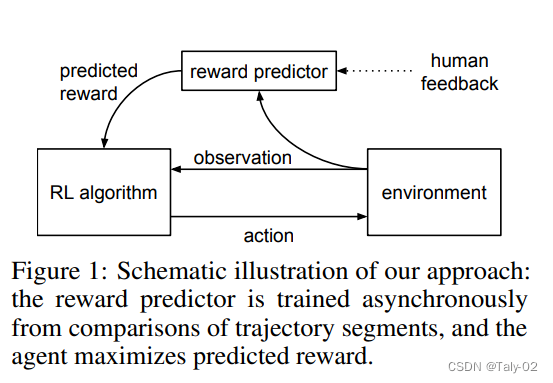
在過(guò)去的幾年中,語(yǔ)言模型通過(guò)根據(jù)人類(lèi)輸入提示生成多樣化且引人注目的文本顯示出令人印象深刻的能力。然而,什么才是“好”文本本質(zhì)上很難定義,因?yàn)樗侵饔^的并且依賴(lài)于上下文。有許多應(yīng)用程序,例如編寫(xiě)您需要創(chuàng)意的故事、應(yīng)該真實(shí)的信息性文本片段,或者我們希望可執(zhí)行的代碼片段。編寫(xiě)一個(gè)損失函數(shù)來(lái)捕獲這些屬性似乎很棘手,而且大多數(shù)語(yǔ)言模型仍然使用簡(jiǎn)單的下一個(gè)loss function(例如交叉熵)進(jìn)行訓(xùn)練。為了彌補(bǔ)損失本身的缺點(diǎn),人們定義了旨在更好地捕捉人類(lèi)偏好的指標(biāo),例如 BLEU 或 ROUGE。雖然比損失函數(shù)本身更適合衡量性能,但這些指標(biāo)只是簡(jiǎn)單地將生成的文本與具有簡(jiǎn)單規(guī)則的引用進(jìn)行比較,因此也有局限性。如果我們使用生成文本的人工反饋?zhàn)鳛樾阅芎饬繕?biāo)準(zhǔn),或者更進(jìn)一步并使用該反饋?zhàn)鳛閾p失來(lái)優(yōu)化模型,那不是很好嗎?這就是從人類(lèi)反饋中強(qiáng)化學(xué)習(xí)(RLHF)的想法;使用強(qiáng)化學(xué)習(xí)的方法直接優(yōu)化帶有人類(lèi)反饋的語(yǔ)言模型。RLHF 使語(yǔ)言模型能夠開(kāi)始將在一般文本數(shù)據(jù)語(yǔ)料庫(kù)上訓(xùn)練的模型與復(fù)雜人類(lèi)價(jià)值觀的模型對(duì)齊。
在傳統(tǒng)的強(qiáng)化學(xué)習(xí)中,智能的agent需要通過(guò)不斷的試錯(cuò)來(lái)學(xué)習(xí)如何最大化獎(jiǎng)勵(lì)函數(shù)。但是,這種方法往往需要大量的訓(xùn)練時(shí)間和數(shù)據(jù),同時(shí)也很難確保智能代理所學(xué)習(xí)到的策略是符合人類(lèi)期望的。Deep Reinforcement Learning from Human Preferences 則采用了一種不同的方法,即通過(guò)人類(lèi)偏好來(lái)指導(dǎo)智能代理的訓(xùn)練。具體而言,它要求人類(lèi)評(píng)估一系列不同策略的優(yōu)劣,然后將這些評(píng)估結(jié)果作為訓(xùn)練數(shù)據(jù)來(lái)訓(xùn)練智能代理的深度神經(jīng)網(wǎng)絡(luò)。這樣,智能代理就可以在人類(lèi)偏好的指導(dǎo)下,學(xué)習(xí)到更符合人類(lèi)期望的策略。除了減少訓(xùn)練時(shí)間和提高智能代理的性能之外,Deep Reinforcement Learning from Human Preferences 還可以在許多現(xiàn)實(shí)場(chǎng)景中發(fā)揮作用,例如游戲設(shè)計(jì)、自動(dòng)駕駛等。通過(guò)使用人類(lèi)偏好來(lái)指導(dǎo)智能代理的訓(xùn)練,我們可以更好地滿(mǎn)足人類(lèi)需求,并創(chuàng)造出更加智能和人性化的技術(shù)應(yīng)用
2. 方法介紹
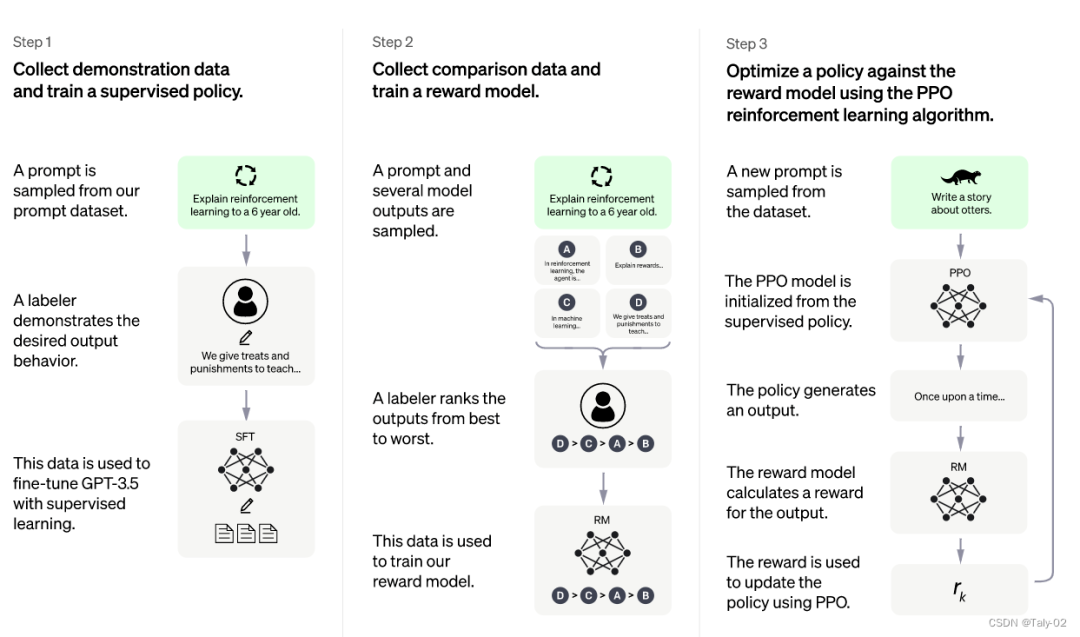
監(jiān)督調(diào)優(yōu)模型:在一小部分已經(jīng)標(biāo)注好的數(shù)據(jù)上進(jìn)行有監(jiān)督的調(diào)優(yōu),讓機(jī)器學(xué)習(xí)從一個(gè)給定的提示列表中生成輸出,這個(gè)模型被稱(chēng)為 SFT 模型。 模擬人類(lèi)偏好,讓標(biāo)注者們對(duì)大量 SFT 模型輸出進(jìn)行投票,這樣就可以得到一個(gè)由比較數(shù)據(jù)組成的新數(shù)據(jù)集。然后用這個(gè)新數(shù)據(jù)集來(lái)訓(xùn)練一個(gè)新模型,叫做 RM 模型。 用 RM 模型進(jìn)一步調(diào)優(yōu)和改進(jìn) SFT 模型,用一種叫做 PPO 的方法得到新的策略模式。
2.1 監(jiān)督調(diào)優(yōu)模型
2.2 訓(xùn)練回報(bào)模型
利用prompt 生成多個(gè)輸出。 利用標(biāo)注者對(duì)這些輸出進(jìn)行排序,獲得一個(gè)更大質(zhì)量更高的數(shù)據(jù)集。 把模型將 SFT 模型輸出作為輸入,并按優(yōu)先順序?qū)λ鼈冞M(jìn)行排序。
2.3 使用 PPO 模型微調(diào) SFT 模型
幫助性:判斷模型遵循用戶(hù)指示以及推斷指示的能力。 真實(shí)性:判斷模型在封閉領(lǐng)域任務(wù)中有產(chǎn)生虛構(gòu)事實(shí)的傾向。 無(wú)害性:標(biāo)注者評(píng)估模型的輸出是否適當(dāng)、是否包含歧視性?xún)?nèi)容。
6. 一文梳理清楚Python OpenCV 的知識(shí)體系
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
圖像讀取; 窗口創(chuàng)建; 圖像顯示; 圖像保存; 資源釋放。
cv2.imread()、cv2.namedWindow()、cv2.imshow()、cv2.imwrite()、cv2.destroyWindow()、cv2.destroyAllWindows()、 cv2.imshow()、cv2.cvtColor()、cv2.imwrite()、cv2.waitKey()。VideoCapture 類(lèi),該類(lèi)常用的方法有:open() 函數(shù); isOpened() 函數(shù); release() 函數(shù); grab() 函數(shù); retrieve() 函數(shù); get() 函數(shù); set() 函數(shù);
VideoWriter 類(lèi),用于保存視頻文件。Point 類(lèi)、Rect 類(lèi)、Size 類(lèi)、Scalar 類(lèi),除此之外,在 Python 中用 numpy 對(duì)圖像進(jìn)行操作,所以 numpy 相關(guān)的知識(shí)點(diǎn),建議提前學(xué)習(xí),效果更佳。cv2.line(); cv2.circle(); cv2.rectangle(); cv2.ellipse(); cv2.fillPoly(); cv2.polylines(); cv2.putText()。
cv2.setMouseCallback() ,滑動(dòng)條涉及兩個(gè)函數(shù),分別是:cv2.createTrackbar() 和 cv2.getTrackbarPos()。cv2.split(),通道合并函數(shù) cv2.merge()。cv2.add(); cv2.addWeighted(); cv2.subtract(); cv2.absdiff(); cv2.bitwise_and(); cv2.bitwise_not(); cv2.bitwise_xor()。
圖像縮放 cv2.resize(); 圖像平移 cv2.warpAffine(); 圖像旋轉(zhuǎn) cv2.getRotationMatrix2D(); 圖像轉(zhuǎn)置 cv2.transpose(); 圖像鏡像 cv2.flip(); 圖像重映射 cv2.remap()。
非線性濾波:中值濾波、雙邊濾波,
方框?yàn)V波 cv2.boxFilter(); 均值濾波 cv2.blur(); 高斯濾波 cv2.GaussianBlur(); 中值濾波 cv2.medianBlur(); 雙邊濾波 cv2.bilateralFilter()。
固定閾值:cv2.threshold(); 自適應(yīng)閾值:cv2.adaptiveThreshold()。
消除噪聲; 分割獨(dú)立元素或連接相鄰元素; 尋找圖像中的明顯極大值、極小值區(qū)域; 求圖像的梯度;
膨脹 cv2.dilate(); 腐蝕 cv2.erode()。
cv2.morphologyEx() 函數(shù)進(jìn)行操作。濾波:濾出噪聲対?rùn)z測(cè)邊緣的影響 ; 增強(qiáng):可以將像素鄰域強(qiáng)度變化凸顯出來(lái)—梯度算子 ; 檢測(cè):閾值方法確定邊緣 ;
Canny 算子,Canny 邊緣檢測(cè)函數(shù) cv2.Canny(); Sobel 算子,Sobel 邊緣檢測(cè)函數(shù) cv2.Sobel(); Scharr 算子,Scharr 邊緣檢測(cè)函數(shù) cv2.Scahrr() ; Laplacian 算子,Laplacian 邊緣檢測(cè)函數(shù) cv2.Laplacian()。
標(biāo)準(zhǔn)霍夫變換、多尺度霍夫變換 cv2.HoughLines() ; 累計(jì)概率霍夫變換 cv2.HoughLinesP() ; 霍夫圓變換 cv2.HoughCricles() 。
matplotlib 模塊對(duì)直方圖進(jìn)行繪制。計(jì)算直方圖用到的函數(shù)是 cv2.calcHist()。直方圖均衡化 cv2.equalizeHist(); 直方圖對(duì)比 cv2.compareHist(); 反向投影 cv2.calcBackProject()。
模板匹配 cv2.matchTemplate(); 矩陣歸一化 cv2.normalize(); 尋找最值 cv2.minMaxLoc()。
查找輪廓 cv2.findContours(); 繪制輪廓 cv2.drawContours() 。
尋找凸包 cv2.convexHull() 與 凸性檢測(cè) cv2.isContourConvex(); 輪廓外接矩形 cv2.boundingRect(); 輪廓最小外接矩形 cv2.minAreaRect(); 輪廓最小外接圓 cv2.minEnclosingCircle(); 輪廓橢圓擬合 cv2.fitEllipse(); 逼近多邊形曲線 cv2.approxPolyDP(); 計(jì)算輪廓面積 cv2.contourArea(); 計(jì)算輪廓長(zhǎng)度 cv2.arcLength(); 計(jì)算點(diǎn)與輪廓的距離及位置關(guān)系 cv2.pointPolygonTest(); 形狀匹配 cv2.matchShapes()。
cv2.watershed() 。cv2.inpaint(),學(xué)習(xí)完畢可以嘗試人像祛斑應(yīng)用。GrabCut 算法 cv2.grabCut(); 漫水填充算法 cv2.floodFill(); Harris 角點(diǎn)檢測(cè) cv2.cornerHarris(); Shi-Tomasi 角點(diǎn)檢測(cè) cv2.goodFeaturesToTrack(); 亞像素角點(diǎn)檢測(cè) cv2.cornerSubPix()。
“FAST” FastFeatureDetector; “STAR” StarFeatureDetector; “SIFT” SIFT(nonfree module) Opencv3 移除,需調(diào)用 xfeature2d 庫(kù); “SURF” SURF(nonfree module) Opencv3 移除,需調(diào)用 xfeature2d 庫(kù); “ORB” ORB Opencv3 移除,需調(diào)用 xfeature2d 庫(kù); “MSER” MSER; “GFTT” GoodFeaturesToTrackDetector; “HARRIS” (配合 Harris detector); “Dense” DenseFeatureDetector; “SimpleBlob” SimpleBlobDetector。
meanShift, camShift,粒子濾波, 光流法 等。meanShift 跟蹤算法 cv2.meanShift(); CamShift 跟蹤算法 cv2.CamShift()。
人臉檢測(cè):從圖像中找出人臉位置并標(biāo)識(shí); 人臉識(shí)別:從定位到的人臉區(qū)域區(qū)分出人的姓名或其它信息; 機(jī)器學(xué)習(xí)。
———————End———————
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進(jìn)RT-Thread官方微信交流群!

↓點(diǎn)擊閱讀原文
愛(ài)我就請(qǐng)給我在看
原文標(biāo)題:【AI簡(jiǎn)報(bào)第20230217期】超越GPT 3.5的小模型來(lái)了!AI網(wǎng)戀詐騙時(shí)代開(kāi)啟
文章出處:【微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
31文章
1301瀏覽量
40265
原文標(biāo)題:【AI簡(jiǎn)報(bào)第20230217期】超越GPT 3.5的小模型來(lái)了!AI網(wǎng)戀詐騙時(shí)代開(kāi)啟
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
AI時(shí)代算力的重要性及現(xiàn)狀:平衡發(fā)展與優(yōu)化配置的挑戰(zhàn)
AI大模型在自然語(yǔ)言處理中的應(yīng)用
大模型時(shí)代的算力需求
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜

Anthropic發(fā)布最新AI模型Claude 3.5,引入Artifacts新功能
Anthropic 發(fā)布Claude 3.5 Sonnet模型運(yùn)行速度是Claude 3 Opus的兩倍





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論