 應對ChatGPT,中國AI需要這三種能力
應對ChatGPT,中國AI需要這三種能力
這段時間,ChatGPT成了全球科技企業“群起而攻之”的風口,幾乎打開每一個社交媒體平臺、每一個微信群,都在激情討論ChatGPT。
不過我發現,經過一段時間的發酵,大家的情緒不再只是獵奇和興奮,一部分AI業內人士,已經率先進入了ChatGPT冷靜期。
一位長期從事NLP/AI的研究人士告訴我,NLP本來屬于長期坐冷板凳的領域,ChatGPT對話中錯誤隨處可見,LLM大語言模型的商業模式還不清晰,認知智能剛剛劃過了冰山一角,對目前ChatGPT的一波波信息轟炸已經審美疲勞了,是時候給ChatGPT降降溫了。
降溫是不可能降溫的,但找回常識和理性是必須的。
大膽預測,今年會是一個ChatGPT大年。
國產化的必然選擇,股市與投資者的熱捧,大量中國科技企業已經切實在跟進類ChatGPT,而且“chat”問答天然的低門檻和娛樂性,確實會吸引大量原本不關心技術的人開始玩AI。所以,盡管圍繞ChatGPT,有很多瘋狂炒作和無稽之談,但熱度勢必還會持續一段時間。
當然,如果你已經對ChatGPT資訊有點審美疲勞了,好消息是,大部分人在“調戲”ChatGPT之后,獵奇心理也會消失。加上ChatGPT在應用和體驗上還需要迭代,個人關注度會下降,而能夠用ChatGPT帶來業務價值的產業關注度,還會持續保溫。
所以,ChatGPT接下來的發展,不是“要么火要么涼”那么兩極分化,而是會經歷一個恒溫培育孵化的發展期。
擔心中國做不好ChatGPT的,不用急,一切才只是剛剛開始;認為中國ChatGPT可以彎道超車的,不用嗨,新技術還是要按照規律按部就班地發展進步。
從第一代生成式預訓練模型GPT-1到GPT-4,這條路OpenAI走了五年。可以說,沒有對大模型的長期投入與探索,是不可能一步登天,做出ChatGPT這樣的產品的。
那么,中國有沒有類似的AI企業,擁有支撐起類 ChatGPT的綜合實力呢?
通過國際權威咨詢機構IDC新近發布的《2022 中國大模型發展白皮書》,我們可以一窺國內大模型實力分布。
評估結果顯示,百度旗下的文心大模型表現非常突出,在市場格局中處于第一梯隊,產品能力、生態能力、應用能力全面領先,給百度即將發布的生成式對話產品文心一言,提供了強大的技術支持。
讓我們暫時排除“支持國貨”的民族情緒,帶著理性和常識去探究一下,文心大模型的水平到底怎么樣?文心一言等類ChatGPT產品,究竟能為用戶和市場提供什么樣的價值?
拆解ChatGPT:一匹以大模型為骨架的“特洛伊木馬”
ChatGPT的出現,代表了大語言模型的突破,將對話式AI與NLP技術帶到了一個全新的高度,展現了AI的更多可能性和商用潛力。
上個世紀,信息哲學領軍人盧西亞諾?弗洛里迪就說過,“人工智能就像特洛伊木馬, 把一種更具包容性的計算/信息的范式引入哲學的城堡。”而ChatGPT就是一匹看起來極其神奇的特洛伊木馬,令人類嘖嘖稱奇,擔心自己不再是城堡中唯一的萬物之靈。
當然,歸根結底,AI也好,ChatGPT也好,都是一匹人造的木馬,由人類創造,也為人類所驅使。
ChatGPT這匹“特洛伊木馬”的出現,更大的意義在于,它代表了一個標志——通過大模型這種方式,人工智能的知識瓶頸,是可以被打破的。
我們知道,算力、算法、數據,這AI三要素在當下基本得到了滿足,帶來了AI技術應用化的突破。但許多自然語言處理NLP任務,如機器翻譯、情感分析、問答系統、語言生成等,需要模型具有一定的語言知識和理解能力。張鈸院士曾提出:AI最重要的能力是知識。但知識,始終是AI的一個瓶頸。
ChatGPT的出現,標志著知識瓶頸是可以被打破的。通過大模型,學習海量的語料庫,可以獲取豐富的語言知識,對語言中的復雜結構、語義和邏輯,進行識別和處理。
大家感覺ChatGPT特別神奇,好像真的有自主思維一樣,正是源自知識能力融入大模型后,在泛化性、通用性、遷移性上的強大表現。
它是一個標志,也只是一個標志。
因為ChatGPT也并沒有徹底解決知識瓶頸,還存在一些局限性。比如由于中文語料不夠多,獲取的深度中文知識少,所以對中文的理解和問答效果都不如英文,經常出現常識性錯誤。
那么,問題來了。OpenAI又不向中國大陸開放服務,對于優化ChatGPT的中文能力顯然不會投入太多資源。同時,AI又廣泛應用在安防、識別、智慧城市等重要領域,安全性和可靠性也決定了,發展國產化ChatGPT,成為了必然的選擇。
好消息是,機會總是留給有準備的人,中國AI過去多年間不斷積累升級,并沒有在大模型時代令我們失望。
自2018年預訓練大模型成為風潮后,中國AI領域快速跟進,已經積累了大模型所需要的全產業鏈要素,包括算力基礎設施、數據集、算子庫、深度學習開發框架、AI開發工具,以及多個領域的大模型產品。
人家牽出了盤亮條順的“特洛伊木馬”,中國科技企業將自家拉磨的驢包裝成汗血寶馬,顯然就不太合適了。國產大模型必須足夠優秀,才能讓國人和企業放心支持。
IDC此時發布《2022中國大模型發展白皮書—— 元能力引擎筑基智能底座》,首提大模型評估框架,是一個大模型比武的好契機,讓我們可以綜合評估國產大模型的實力。
從文心的三輪驅動,稱稱國產大模型的重量
投資市場有句話,“在短期,市場是個投票器;在長期,市場是個稱重器。”遇到短期風口“豬也能在天上飛”,但長期來看,任何公司和概念都要靠扎扎實實的核心能力,長出翅膀,才能穿越風雨,持續騰飛。
放到ChatGPT概念上也一樣,各種國產類ChatGPT產品出現,到底是騾子是馬,得拉出來遛遛。
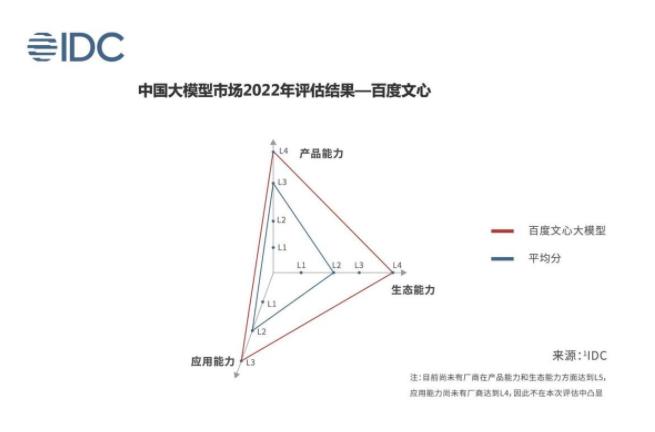
此次《白皮書》中,IDC搭建了大模型評估框架V1.0,選取國內主流廠商(N=9),從模型能力、工具平臺能力、開放性、應用廣度、應用深度、應用生態共6大維度的11項指標,進行打分評估。結果顯示,百度文心大模型的產品能力、生態能力達到L4水平,應用能力達到L3水平,處于第一梯隊。IDC中國副總裁兼首席分析師武連峰認為,百度文心大模型是其打造文心一言的堅實基礎。
現實進展來看,百度率先打開局面,即將推出類ChatGPT的生成式對話產品文心一言。
《白皮書》中提到,“模型+工具平臺+生態” 三級協同,是OpenAI在開發GPT大模型過程中的核心思路,經過長期的積累,也更容易形成競爭壁壘。
我們不妨從這三個角度出發,去稱稱百度文心大模型的重量,究竟與OpenAI有何差距?
第一,大模型的產品能力。
模型層,是大模型的核心引擎,也是相關產品的主要優勢和競爭賽點。
ChatGPT的成功,得益于大規模的數據集,較強的模型開發和算法調優能力,在NLP領域的長期積累,以及來自微軟的計算資源支撐等。總的來說,打造一個像ChatGPT這樣的大模型產品,需要對算法和技術有深入的理解,以及數據、算力等支持。
這方面,我們可以看到,百度要打造類ChatGPT產品,不是從零開始,而是有著長期積累和綜合優勢。
百度自2019年開始深入研發預訓練模型,發布了知識增強的產業級大模型文心ERNIE1.0。在深度學習的基礎上融入知識,將海量的知識積淀和自研的多源異構知識圖譜,投入到文心大模型的預訓練中,在知識的指導下,文心大模型的效率更高、效果更好,可解釋性更強。用于訓練的數據量級也有顯著優勢,模型參數達到萬億級別。2020年開始將文心大模型應用到搜索業務,可以說,百度在破解AI知識瓶頸這一問題上的探索,并不比OpenAI落后,更比國內很多科技企業要早得多。

目前,困擾國產ChatGPT的算力資源和成本問題,百度也在開發文心大模型的過程當中,與國內外硬件伙伴合作尋找解決方案,百度飛槳深度學習平臺向下適配各種硬件,以支持文心大模型的開發、高性能訓練、模型壓縮、服務部署的各種能力。
可以說,百度在大模型方面有著貫通全產業鏈的積累,能夠滿足類ChatGPT產品的開發需求,具有較強的先發優勢。
第二,應用工具平臺。
大模型的落地應用,是海外AI研究機構很少提及,卻是產業智能化不可規避的問題。真實的產業應用場景中,企業和開發者接入大模型的方式多種多樣,有的需要產品級的API接口,有的希望能夠開放深度定制,有的則對成本非常敏感。
所以,要讓大模型廣泛應用,就必須平臺提供完善的成體系的全棧工具鏈,包括深度學習框架、基礎模型庫、數據集、端到端開發套件、API接口等,才能讓更多行業人員或開發者,能夠低門檻甚至零門檻的將大模型應用于自己的業務中。
目前,ChatGPT還是沒有開源的,想要基于ChatGPT打造集成化的行業應用產品,還不現實。這一點上,和飛槳深度學習平臺生態共享的文心大模型,可以借助飛槳龐大且豐富的工具平臺,以及AI開發社區,加速大模型的產業化應用,更快建立起商業閉環。
第三,行業生態。
正如OpenAI的首席執行官山姆·奧特曼所說,ChatGPT的技術不應該被保留在科技行業的狹小范圍內,而應該擁抱真實世界。
但是,大模型與千行百業的融合,充滿了未知的領域,要一個行業、一個行業去探索,與開發者、行業用戶、上下游產業共創,這是一個苦活重活,確實大模型走向產業、擁抱真實世界的更優解。
生態建設上,百度文心大模型與飛槳深度學習平臺生態共享,前期已經做了大量的工作。《白皮書》顯示,百度飛槳生態已經凝聚了535萬開發者、服務20萬家企事業單位,與12家硬件伙伴聯合發布飛槳生態發行版、推動深度學習平臺與更多硬件適配,還與國內科研院所、實驗室以及高校強強聯手,一同攻克AI技術難關,目前賦能了389所高校,服務747名教師,學分課培養10萬余名AI學子 。
在此基礎上,文心大模型與眾多頭部企業合作,融合了通用數據和行業特有知識,推出行業大模型系列,比如能源行業NLP大模型國網-百度·文心、金融行業NLP大模型浦發-百度·文心等,顯著提升了大模型在行業任務上的應用效果,也在重點行業形成了大模型落地應用的參考路徑,給全球大模型走向商業化,起到一定的示范作用。
“模型+工具平臺+生態”,三輪驅動下,一點點將大模型推向廣闊的產業天地。
化解中國AI焦慮的另一種思路:大模型的產業突圍
ChatGPT火爆之后,大家可能聽到了類似的聲音,認為中國科技企業不像OpenAI這樣長期投入,中國AI缺乏元創新、底層創新,中國在ChatGPT上已經落后了追趕要花很多錢……
其實梳理百度文心大模型的進化史會發現,這些都是一種科技自立焦慮心理的“暈輪效應”,即因為某個細分領域、垂直領域的短板,而放大到對中國AI整體能力的質疑和虛無論,這顯然是不客觀的。至少在大模型這個領域,中國技術自信是很真實的。
ChatGPT熱潮也體現出,大模型成為發展AI技術的必然選擇。這也為化解中國AI焦慮,提供了另一種思路,那就是大模型的產業突圍。
IDC認為,大模型將會助推數字經濟,為智能化升級帶來新范式。對行業用戶而言,大模型已表現出巨大的潛力,企業應該盡早關注,在業務中布局。
但ChatGPT雖好,這類新技術在與行業融合時,實際中還會面對一系列適配問題,比如:
1.原始模型太大,難以在產線、礦山、園區等終端側部署。
2.需要與行業專精知識相結合,開發定制程度更高、更安全可靠的垂直應用。
3.服務商自行開發類ChatGPT成本太高,難度很大,商業效益難保障。
所以,要打通ChatGPT等新AI技術向產業釋放的一系列關節,真是“尋龍分金看纏山,一重山是一重關”,有著千山萬水要過。這時候,圍繞文心大模型這樣的產業級平臺,去撬動新技術的可能,或許才是真正的機遇所在。
在這個過程中,百度這樣的AI頭部玩家,接下來還需要做好三件事:
1.夯實AI基礎設施。通過文心大模型與飛槳深度學習平臺,夯實AI基礎設施底座,加速類ChatGPT產品的開發,持續技術創新的同時,提供基礎模型、豐富工具棧、API接口等必要資源,成為各行業都可以低門檻引入AI的創新底座。
2.進一步加強生態開放。有活力的創新開發環境,才有中國AI應用的百花齊放,頭部企業有責任為生態賦能,不斷向開發者釋放資源和支持。近日來,愛奇藝、集度汽車(通過Apollo)、小度、宇信科技、漢得信息、金蝶軟件、寶寶巴士、智聯招聘、太平洋汽車網等知名企業,都已經加入了百度文心一言生態圈,獲得該AI技術的“加持”。據說,文心一言還將會推出生態伙伴計劃,全面支持伙伴,共同發展商業市場。
3.探索無人區,不斷推動新技術與行業問題的結合。盡管每次AI領域的技術突破都會引發很大的輿論關注,但AI在行業當中的滲透率只有10%左右,還有大量空白地帶是可以與AI相結合的,需要頭部企業去引導和探索,形成示范案例。
總之,中美AI或許在頂級科研、底層技術上有差距,但中國科技企業、從業者、開發者以及無數行業和企業,從來沒有“躺平”過,一直在追逐著新技術的腳步。這些要素疊加在一起,是文心大模型的重量,也是中國AI的重量。
審核編輯黃宇
-
IDC
+關注
關注
4文章
391瀏覽量
37238 -
AI
+關注
關注
87文章
30979瀏覽量
269252 -
人工智能
+關注
關注
1791文章
47336瀏覽量
238696 -
nlp
+關注
關注
1文章
488瀏覽量
22046 -
OpenAI
+關注
關注
9文章
1095瀏覽量
6550 -
ChatGPT
+關注
關注
29文章
1563瀏覽量
7745
發布評論請先 登錄
相關推薦
ADS8688,ADS8688A,ADS8688AT三種型號有什么區別?如何選擇?
I2S有左對齊,右對齊跟標準的I2S三種格式,那么這三種格式各有什么優點呢?
基本放大電路有哪三種
單片機的三種總線結構
放大電路的三種組態可以放大什么
晶體管的三種工作狀態
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
555集成芯片的三種工作模式及區別
動態無功補償裝置的三種運行模式






 工商網監
工商網監
評論