 聊聊SystemVerilog編碼層面提速的若干策略
聊聊SystemVerilog編碼層面提速的若干策略
今天別的先不聊,就單從代碼習慣出發聊聊SystemVerilog編碼層面提速的若干策略。
本篇的主體策略來自Cliff Cummings和其團隊多年以來得出的一些研究結論,所展示的策略主要偏重于定性分析,而非定量分析,偏重結論而非詳細的理論論述。如果大家感興趣,可以自己設計仿真實驗進一步定量分析,或深入查閱文獻資料深究原理。
值得一提的是,本文雖偏重定性分析和結論擺出,但是這些結論還是具有很不錯的價值,例如對SystemVerilog仿真速度的編碼層面優化方法提供了一些思路和認知,對SystemVerilog代碼風格建立提供了一個新的觀察視角,當你在代碼提速優化“山窮水盡”之時,也許因為某條“柳暗花明”。
好了,廢話不說了,請出干貨:
1.頻繁的函數/任務調用會增加開銷
比如:用foreach遍歷方式計數(foreach有內置函數),不如單獨的計數器!如下代碼:
這樣寫比較慢:

這樣寫比較快:

對于簡單調用,編譯器可以將函數/任務內聯以避免堆棧幀操作,但復雜調用因為編譯器性能考慮原因通常不會內聯,每個函數/任務都將數據引用或完整的數據副本推送到調用堆棧,并處理任何指定的返回。如此就會增加仿真時間了。如果這個函數/任務本身又被循環掉用,時間就會浪費更多!
上面的反例代碼,通過foreach遍歷來統計mad_q中的元素數,每次都需要掉用一次內部的內置函數,將會慢于一個獨立的計數器!
2.計算表達式、引用請“逃出”循環
例2.1:循環條件中不要帶計算,每次循環都會計算一次
這樣寫比較慢:

這樣寫比較快:
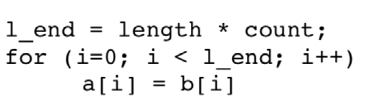
例2.2:和循環因子無關的計算應在循環外計算好
這樣寫比較慢:
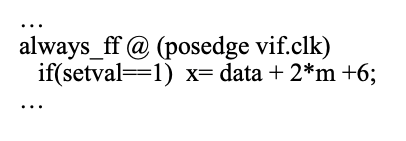
這樣寫比較快:
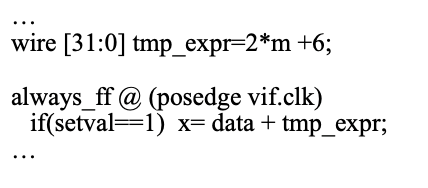
例2.3:引用不要和循環沾邊
這樣寫比較慢:

這樣寫比較快:

這個例子比較慢的代碼把例如comms.proto.pkt….的引用帶入了循環里。
在硬件世界中,可以預先計算分層引用,因為這些引用在運行時是靜態的。在systemverilog testbench中,引用通常是同時遍歷類實例層次結構和動態類型,所有這些都可以在仿真運行期間更改。因此,模擬器必須遍歷所有引用才能獲得數據,這顯然會降低速度。
3.對于條件的相關編碼長點兒心吧
例3.1:簡單的條件短路

第一行if中通過“或”聯系起來的條件,當其中term1為1時,則后續不用判斷則可以得出if條件整體成立。
同理第二行if中通過“與”聯系起來的條件,當其中term1為0時,則后續不用判斷則可以得出if條件整體不成立。
所以這樣寫這個條件會比較快,例如:
if(最高頻率的條件 || 次高頻率的條件 || 最低頻率的條件),把最高頻率的寫在最前面。
例3.2:能條件成立后才進行計算的,就不要著急放到前面算。
比如下面這個例子,data的計算是調用了randomize()這個函數,但是用這個值是在一個If(live==TRUE)條件成立之后才用的!假如條件沒成立,那就是沒用上,沒用上前面是不白算了?自然就浪費資源了!(我們前面講循環的時候說該算的提前算好,看到條件這里的時候我們可能要多想想了,原來不是啥都趕前面算就好啊,哈哈)

例3.3:UVM平臺中妙用uvm_report_enabled()函數作為條件來優化。
如下例,如果打印詳細級別設置為UVM_DEBUG或高于UVM_DEBUG,則觸發消息打印。

例3.4:再來一個UVM平臺中玩好條件的案例,monitor或者driver進行port傳遞時,以port的size()為條件,減少不必要的打數據包的次數。

4.連接處logic的語義顯式聲明wire,可以折疊為同一對象,加快仿真速度(RTL or TB)
這樣寫比較慢:

這樣寫比較快:

SystemVerilog中的logic類型,它可以有wire線存儲或var變量存儲,如果沒有顯式聲明,則存儲類型由仿真器根據上下文確定。
別小看這個類型,對仿真差別很大哦,如果是wire型,仿真器可以折疊為同一對象以獲得更高的仿真速度,但是變量卻不能!
因為logic類型的語義除了在input、inout之外的所有情況下全都默認為變量存儲!所以你的代碼有時候可能仿真正確,但不知道為啥比想象中的慢!
如上例子中A2.y、A2.X1.y和A2.X1.T1.y是不同的,粗體wire聲明允許將它們折疊為單個對象。(當然上例子中input本身默認為wire類型不需要顯式聲明,但是全部顯式聲明更加清楚,這個代碼風格更好)
5. 在“向量”上直接操作比操作bit更快
這樣寫比較慢:

這樣寫比較快:
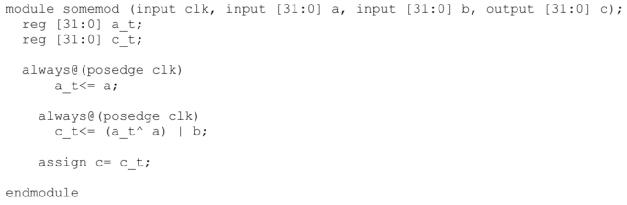
如上例32bit的a_t、c_t,可以看作32個1bit的變量組成的“向量”。對于這個“向量”直接操作會快于對其32個1bit循環操作。
順便一提,上面的反例中,除了位操作,而且效率低下的示例使用了一個generate語句,它創建了一個靜態層次結構。這樣的跨層次結構的問題,仿真器會進行優化,但是對于復雜的問題,往往不能做到很好的優化,會變成隱藏的性能問題。
6.盡量用ref,少傳遞復雜數據結構
ref會直接對目標方法的內存進行操作,這樣便節省了資源,尤其是對于很多復雜數據結構例如具有數百個字段的結構體、或具有數百個元素的隊列、動態數組、聯合數組等。其實,很多時候函數只需要擁有讀取大型數據對象的訪問權限即可,根本不會寫入它。
7.動態數據結構,不要濫用、想清楚再用
“動態數據結構”如隊列、動態數組、聯合數組是常見性能問題的來源,不要濫用。SystemVerilog和大多數具有這些類型的語言通常都是如此。
所以,盡可能使用靜態數組而不是動態數組。即使數組長度有少量變化,最好指定靜態數組稍大一些,而不是承擔動態數組的開銷(內存占用空間和垃圾收集時間)。比如可能有2--10個int型的元素,直接定義和使用“int A[10];”,或者更大點“int A[12];”來存儲元素,而不是直接定義使用動態數組“int A[ ];”來動態分配空間。
除此之外,動態數組和隊列有各自適合的場景,他們都可以完成對方的功能,但是不要隨意混用,否則都會有不好的性能。動態數組最適合查找,隨機插入/刪除操作,隊列最適合自動調整大小的前后操作,仿真器具有不同的內部表示來優化他們各自的操作,所以盡量讓他們去合適自己的“崗位”。
8.能用單個對象,不要多new
比較慢的寫法:

比較快的寫法:

低效的內存可能導致嚴重的cache miss,堆管理開銷和垃圾收集開銷,這些都可能難以通過分析發現,所以養成好的代碼習慣,例如盡量少new不必要的對象、不是必需情況下盡量少深拷貝動態對象。
9.可以考慮靜態類代替動態類
接著上一條,如果同一組類反復被分配內存和釋放內存,仿真器通過內存管理反復循環,降低了仿真時間,而如果是靜態定義的類,仿真的整體內存占用保持一致,從而執行速度會變快!
10.簡單異構數據結構能用結構體就不要用類
很多人常常有種想法認為class是基于面向對象引入的更“高級”的封裝方式,結構體好像更“low”一點,其實不然!單獨的類將需要堆管理并可能涉及垃圾收集,簡單的struct(結構體)不會,所以更快。簡單異構數據結構能用結構體就不要用類了吧。
11.接口中的“重”功能放在接口中而不是類中
這樣寫比較慢:
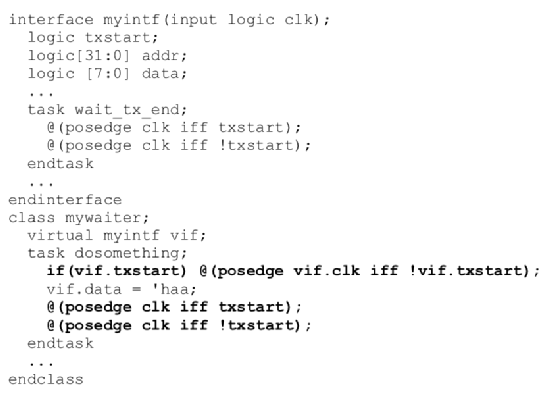
這樣寫比較快:

將接口“重”的功能放入接口而不是類中也更具仿真效率。
首先,因為功能與接口本身相關聯,可重用性更好。
其次,在接口上操作的類包含與接口相關聯的基本操作使接口的任何未來用戶都可以復制此基本代碼,但是通過virtual接口無法有效地引用它們。
12.減少動態task或者function的喚醒
SystemVerilog仿真器是由事件驅動的,它們在給定時間點運行的事件越多,運行速度越慢。SystemVerilog中最常見的進程應該就是帶有敏感信號(如clk)的always塊來,正因如此常見,這個靜態進程在所有仿真器中都進行了高度優化,但是,動態task或者function(如DPI(或任何外部)功能,虛擬類任務/功能和虛擬接口任務/功能)的副作用可能會導致仿真器禁用優化!這種情況,“坐著不如躺著”少喚醒最安全。就像前面例3.2條件的處理那樣,盡量減少他們的執行,如下

值得一提的是,除了這樣還有一種玩法可以減少執行次數:用iff,如下例子

13.對于UVM平臺中帶約束的隨機,盡量分解或簡化
這樣寫比較慢:
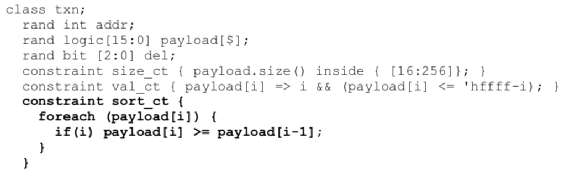
這樣寫會快很多:

在上圖反例中,循環中對其相鄰對每個數組元素設置約束,假設100個元素,就相當于必須同時求解100個約束。下面的代碼使用post_randomize,經統計,可以將運行時性能提高1000倍!
14.斷言的序列和屬性盡量避免使用局部變量
這樣寫比較慢:

這樣寫比較快:

雖然可能需要局部變量來操縱序列和屬性內部的數據,但它們在仿真過程中增加了開銷。在可能的情況下,應避免使用局部變量。
15.覆蓋率收集時,盡可能減少采樣事件
這樣寫比較慢:

這樣寫比較快:

上面第二段代碼之所以比第一段快,是因為合并使用了相同事件的采樣過程,更少的coverage采樣事件可以減少仿真時間。
所以除此之外,盡量使用特定事件觸發器而不是諸如系統時鐘之類的通用事件來采樣覆蓋率、覆蓋組共享共同表達式等手段也可以減少仿真時間。
16. 可以使用宏加快循環計算
對于如下循環代碼,reverse()函數會在大量的數據點被掉用,每次調用reverse( ) 都需要創建可能影響緩存命中的堆棧幀,仿真速度會非常慢。使用REVERSE宏,就會使仿真更快。當然宏過度使用會增加調試難度和內存消耗。

結語
正如前文所說:“專輯發文順序與提速收益無關”,本篇的提效手段,對于代碼規模不大的驗證業務,說實話并不是收益最大的提速方式,甚至有的收益難以感知,屬于“勒緊褲腰帶”的致富方式。但是“粒粒皆辛苦”,多條并用,積少成多,當驗證業務規模大的時候(除了芯片規模大之外還包括仿真數據量很大時,例如大數據量圖像視頻的壓測場景)你將獲得一個還不錯的速度收益。
審核編輯:劉清
-
Verilog
+關注
關注
28文章
1351瀏覽量
110189 -
計數器
+關注
關注
32文章
2259瀏覽量
94805 -
編譯器
+關注
關注
1文章
1638瀏覽量
49197 -
模擬器
+關注
關注
2文章
879瀏覽量
43301
原文標題:驗證仿真提速系列--SystemVerilog編碼層面提速的若干策略
文章出處:【微信號:處芯積律,微信公眾號:處芯積律】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從可綜合的RTL代碼的角度聊聊interface
[啟芯公開課] SystemVerilog for Verification
round robin 的 systemverilog 代碼
做FPGA工程師需要掌握SystemVerilog嗎?
(2)打兩拍systemverilog與VHDL編碼 精選資料分享
SystemVerilog Assertion Handbo
SystemVerilog的斷言手冊
基于OFDM和循環延遲分集的空時頻編碼策略
基于雙向MIMO中繼系統的一種預編碼策略





 工商網監
工商網監
評論