 小白如何入門機器學習?
小白如何入門機器學習?
從五個方面帶你入門機器學習:什么是機器學習?工作流程是什么?機器學習算法有哪些?模型評估學習以及Azure機器學習模型搭建實驗。
1什么是機器學習
機器學習是從數據中自動分析獲得模型,并利用模型對未知數據進行預測。
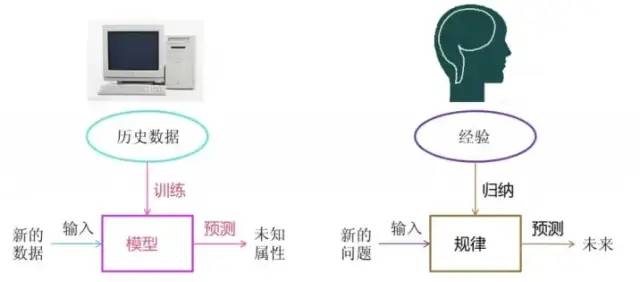
2機器學習工作流程
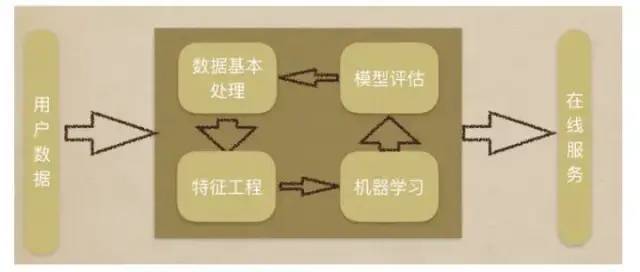
-
1.獲取數據
-
2.數據基本處理
-
3.特征工程
-
4.機器學習(模型訓練)
-
5.模型評估
結果達到要求,上線服務
沒有達到要求,重新上面步驟
2.1獲取到的數據集介紹
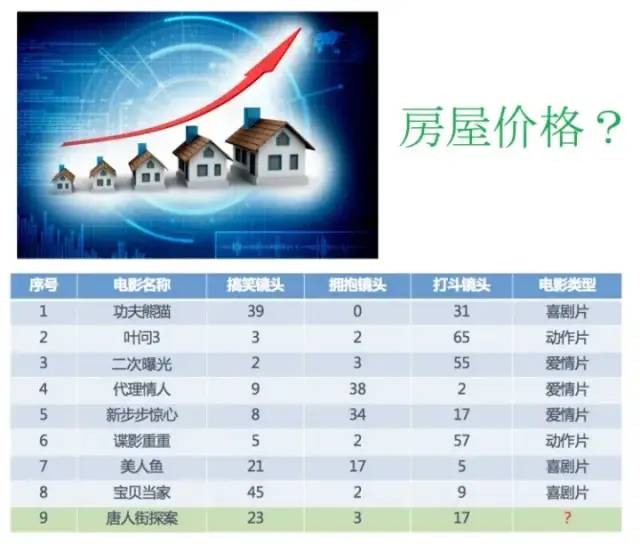
數據簡介
在數據集中一般:
-
一行數據我們稱為一個樣本
-
一列數據我們成為一個特征
-
有些數據有目標值(標簽值),有些數據沒有目標值(如上表中,電影類型就是這個數據集的目標值)
數據類型構成:
-
數據類型一:特征值+目標值(目標值是連續的和離散的)
-
數據類型二:只有特征值,沒有目標值
數據分割:
機器學習一般的數據集會劃分為兩個部分:
-
訓練數據:用于訓練,構建模型
-
測試數據:在模型檢驗時使用,用于評估模型是否有效
劃分比例:
-
訓練集:70% 80% 75%
-
測試集:30% 20% 25%
2.2數據基本處理
即對數據進行缺失值、去除異常值等處理
2.3特征工程
2.3.1什么是特征工程
特征工程是使用專業背景知識和技巧處理數據,使得特征能在機器學習算法上發揮更好的作用的過程。
-
意義:會直接影響機器學習的效果
2.3.2 為什么需要特征工程(Feature Engineering)
機器學習領域的大神Andrew Ng(吳恩達)老師說“Coming up with features is difficult, time-consuming, requires expert knowledge.
“Applied machine learning” is basically feature engineering. ”
注:業界廣泛流傳:數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。
2.3.3 特征工程包含內容
-
特征提取
-
特征預處理
-
特征降維
2.3.4 各概念具體解釋
-
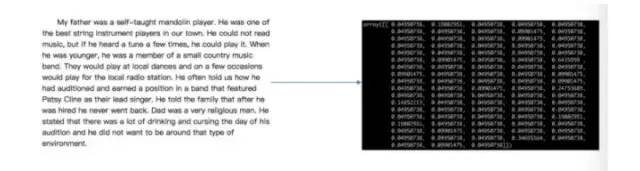
特征提取
將任意數據(如文本或圖像)轉換為可用于機器學習的數字特征
-
特征預處理
通過一些轉換函數將特征數據轉換成更加適合算法模型的特征數據過程
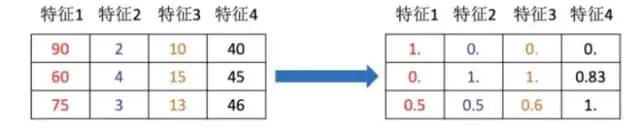
-
特征降維
指在某些限定條件下,降低隨機變量(特征)個數,得到一組“不相關”主變量的過程
2.4 機器學習
選擇合適的算法對模型進行訓練
2.5 模型評估
對訓練好的模型進行評估
3 機器學習算法分類
根據數據集組成不同,可以把機器學習算法分為:
-
監督學習
-
無監督學習
-
半監督學習
-
強化學習
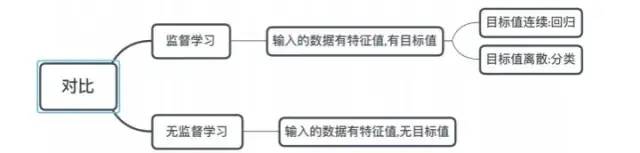
3.1 監督學習
定義:
輸入數據是由輸入特征值和目標值所組成。函數的輸出可以是一個連續的值(稱為回歸),或是輸出是有限個離散值(稱作分類)。
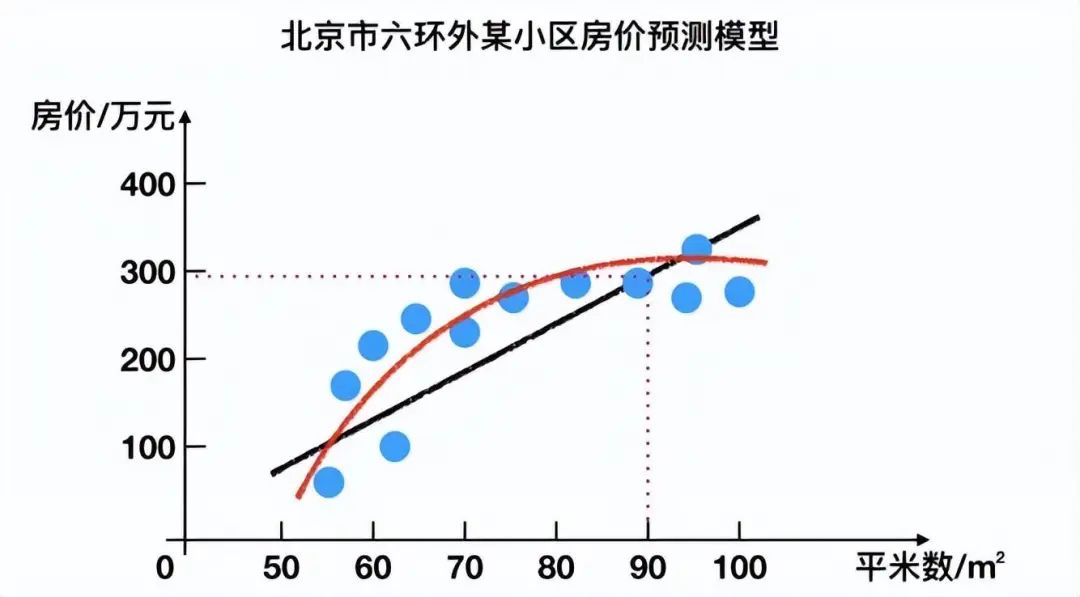
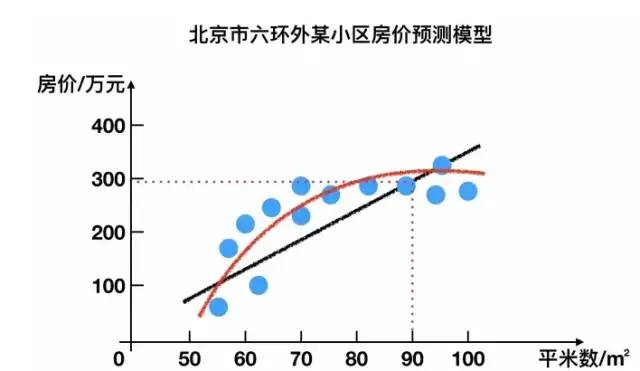
3.1.1 回歸問題
例如:預測房價,根據樣本集擬合出一條連續曲線。
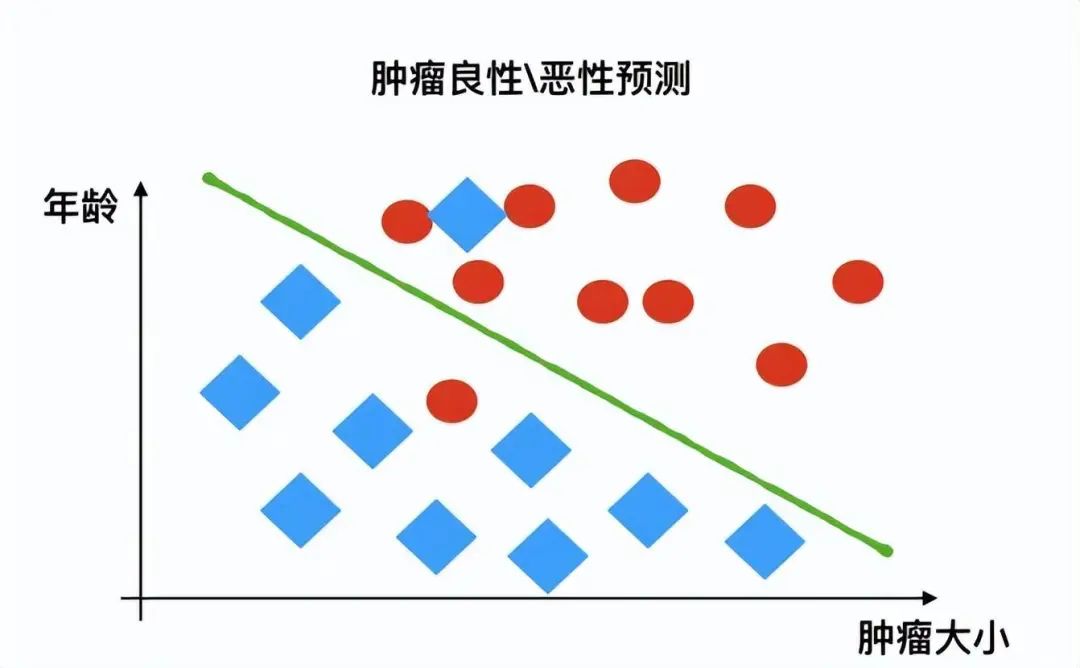
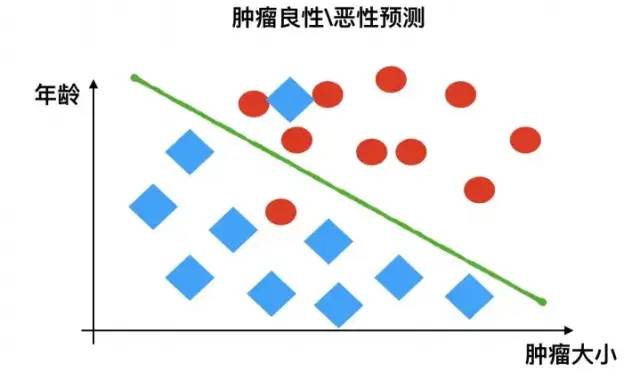
3.1.2 分類問題
例如:根據腫瘤特征判斷良性還是惡性,得到的是結果是“良性”或者“惡性”,是離散的。
3.2 無監督學習
定義:
輸入數據是由輸入特征值組成,沒有目標值
-
輸入數據沒有被標記,也沒有確定的結果。樣本數據類別未知;
-
需要根據樣本間的相似性對樣本集進行類別劃分。
舉例:

有監督,無監督算法對比:
3.3 半監督學習
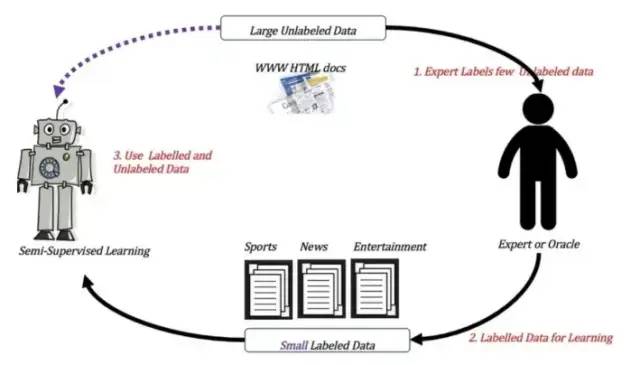
定義:訓練集同時包含有標記樣本數據和未標記樣本數據。
舉例:
-
監督學習訓練方式:
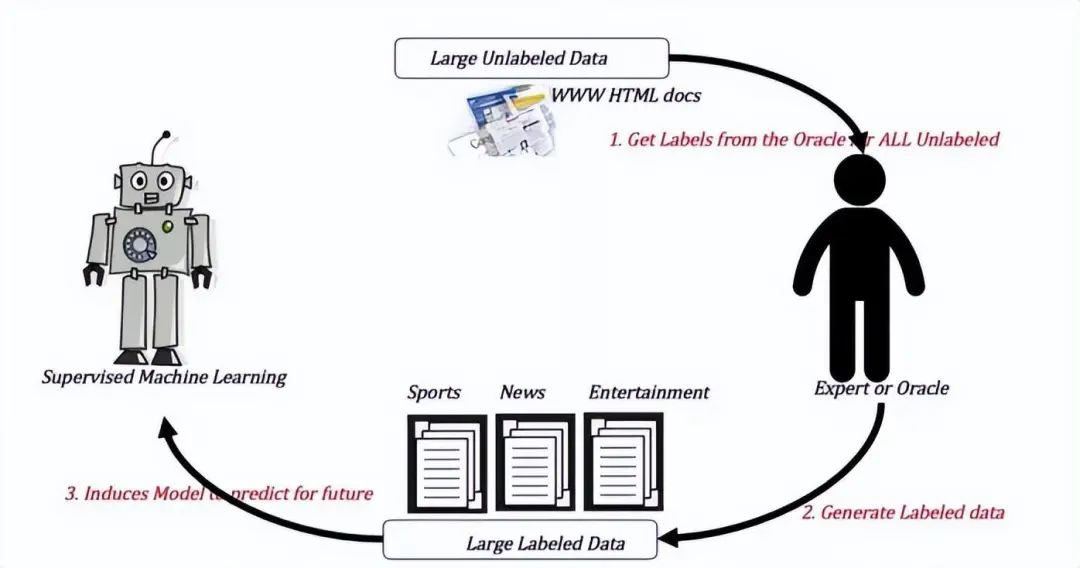
-
半監督學習訓練方式
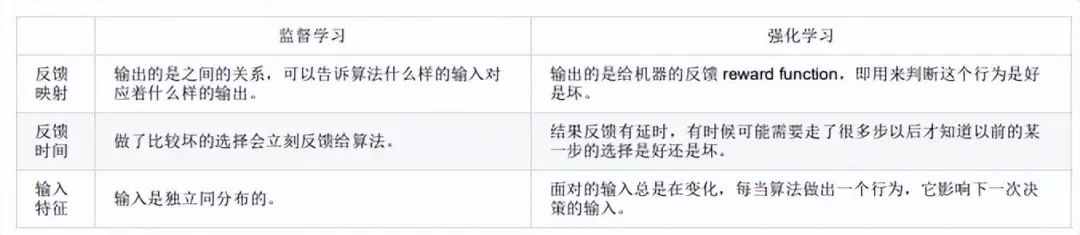
3.4 強化學習
定義:實質是make decisions 問題,即自動進行決策,并且可以做連續決策。
舉例:小孩想要走路,但在這之前,他需要先站起來,站起來之后還要保持平衡,接下來還要先邁出一條腿,是左腿還是右腿,邁出一步后還要邁出下一步。
小孩就是 agent,他試圖通過采取行動(即行走)來操縱環境(行走的表面),并且從一個狀態轉變到另一個狀態(即他走的每一步),當他
完成任務的子任務(即走了幾步)時,孩子得到獎勵(給巧克力吃),并且當他不能走路時,就不會給巧克力。
主要包含五個元素:agent, action, reward, environment, observation;
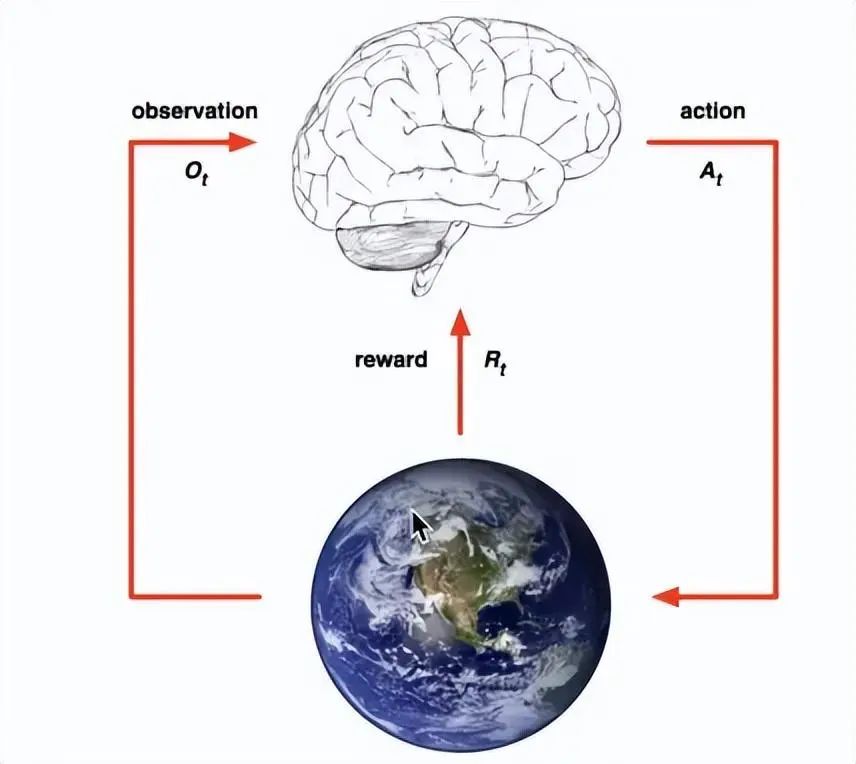
強化學習的目標就是獲得最多的累計獎勵。
監督學習和強化學習的對比:
拓展概念:什么是獨立同分布:
獨立同分布概念
拓展閱讀:Alphago進化史 漫畫告訴你Zero為什么這么牛:
Alphago進化史 漫畫告訴你Zero為什么這么牛
4 模型評估
4.1分類模型評估
準確率
-
預測正確的數占樣本總數的比例。
其他評價指標:精確率、召回率、F1-score、AUC指標等
4.2回歸模型評估
均方根誤差(Root Mean Squared Error,RMSE)
-
RMSE是一個衡量回歸模型誤差率的常用公式。不過,它僅能比較誤差是相同單位的模型。
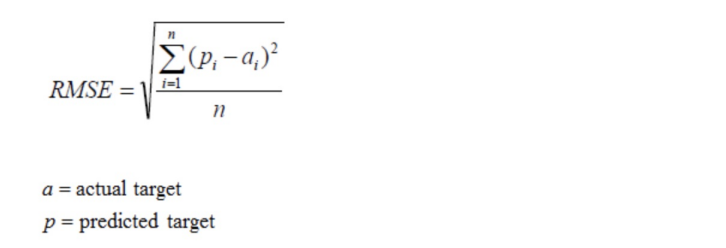
舉例:
假設上面的房價預測,只有五個樣本,對應的
真實值為:100,120,125,230,400
預測值為:105,119,120,230,410
那么使用均方根誤差求解得
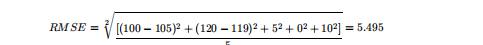
其他評價指標:相對平方誤差(Relative Squared Error,RSE)、平均絕對誤差(Mean Absolute Error,MAE)、相對絕對誤差 (Relative Absolute Error,RAE)
4.3擬合
模型評估用于評價訓練好的的模型的表現效果,其表現效果大致可以分為兩類:過擬合、欠擬合。
在訓練過程中,你可能會遇到如下問題:
訓練數據訓練的很好啊,誤差也不大,為什么在測試集上面有問題呢?
當算法在某個數據集當中出現這種情況,可能就出現了擬合問題。
4.3.1 欠擬合
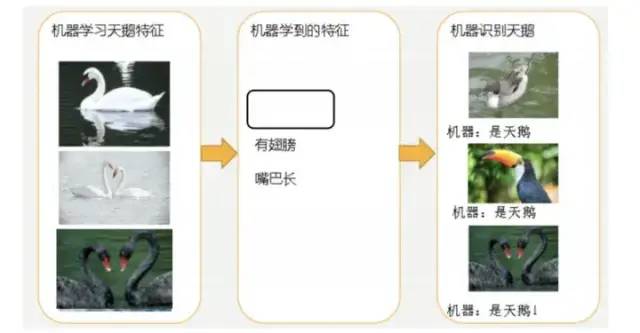
因為機器學習到的天鵝特征太少了,導致區分標準太粗糙,不能準確識別出天鵝。
欠擬合(under-fitting):模型學習的太過粗糙,連訓練集中的樣本數據特征關系都沒有學出來。
4.3.2 過擬合
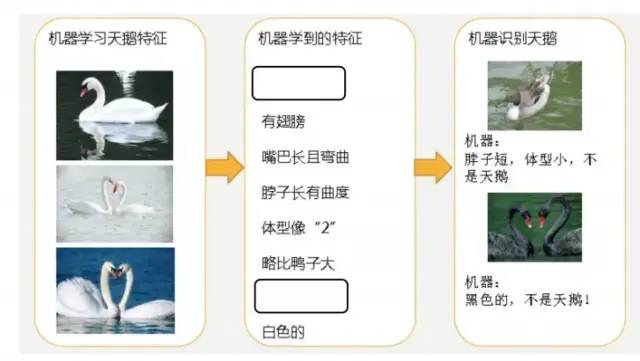
機器已經基本能區別天鵝和其他動物了。然后,很不巧已有的天鵝圖片全是白天鵝的,于是機器經過學習后,會認為天鵝的羽毛都是白的,以后看到羽毛是黑的天鵝就會認為那不是天鵝。
過擬合(over-fitting):所建的機器學習模型或者是深度學習模型在訓練樣本中表現得過于優越,導致在測試數據集中表現不佳.
-
上問題解答:
訓練數據訓練的很好啊,誤差也不大,為什么在測試集上面有問題呢?
5Azure機器學習模型搭建實驗
Azure平臺簡介
Azure Machine Learning(簡稱“AML”)是微軟在其公有云Azure上推出的基于Web使用的一項機器學習服務,機器學習屬人工智能的一個分支,它技術借助算法讓電腦對大量流動數據集進行識別。這種方式能夠通過歷史數據來預測未來事件和行為,其實現方式明顯優于傳統的商業智能形式。
微軟的目標是簡化使用機器學習的過程,以便于開發人員、業務分析師和數據科學家進行廣泛、便捷地應用。
這款服務的目的在于“將機器學習動力與云計算的簡單性相結合”。
AML目前在微軟的Global Azure云服務平臺提供服務,用戶可以通過站點:
https://studio.azureml.net/申請免費試用。

-
Azure機器學習實驗
實驗目的:了解機器學習從數據到建模并最終評估預測的整個流程。
審核編輯 :李倩
-
數據
+關注
關注
8文章
7104瀏覽量
89297 -
模型
+關注
關注
1文章
3279瀏覽量
48976 -
機器學習
+關注
關注
66文章
8428瀏覽量
132845
原文標題:小白如何入門機器學習?
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論