") 深入理解語(yǔ)言模型的突顯能力
深入理解語(yǔ)言模型的突顯能力
上周轉(zhuǎn)發(fā)了符堯大佬拆解GPT3起源的文章,收到了很多好評(píng),同時(shí)也讓我們開(kāi)始思考:
- 是否只有大模型能訓(xùn)出ChatGPT?
- 小模型+精調(diào) vs 大模型+提示詞,哪個(gè)更好?Prompt已經(jīng)火了一年多,然而真正在生產(chǎn)中應(yīng)用的還是少數(shù),我們是否真的面臨范式轉(zhuǎn)變?
- 如果真需要大模型,得多大?
正好的是,符堯在ChatGPT出來(lái)之前就寫過(guò)一篇深度分析大模型能力的文章,于是在我們的共同努力下把該文翻譯成了中文,希望可以解答大家對(duì)大模型的一些困惑。
英文原版:https://franxyao.github.io/blog.html
作者: 符堯 ,yao.fu@ed.ac.uk,愛(ài)丁堡大學(xué) (University of Edinburgh) 博士生,本科畢業(yè)于北京大學(xué)
與 Tushar Khot ,彭昊 在艾倫人工智能研究院 (Allen Institute for AI) 共同完成英文原稿
與 李如寐 (美團(tuán)NLP中心)共同翻譯為中文
感謝 Aristo teammates , Jingfeng Yang , 和 Yi Tay 的討論與建議。
請(qǐng)同時(shí)參考CoT ^[1]^ 團(tuán)隊(duì)的博客。
轉(zhuǎn)發(fā)請(qǐng)?jiān)谖恼碌拈_(kāi)頭標(biāo)明出處、作者,而不是在結(jié)尾列一行小字
正文
最近,人們對(duì)大型語(yǔ)言模型所展示的強(qiáng)大能力(例如思維鏈 ^[2]^ 、便簽本 ^[3]^ )產(chǎn)生了極大的興趣,并開(kāi)展了許多工作。我們將之統(tǒng)稱為大模型的突現(xiàn)能力 ^[4]^ ,這些能力可能只存在于大型模型中,而不存在于較小的模型中,因此稱為“突現(xiàn)”。其中許多能力都非常令人印象深刻,比如復(fù)雜推理、知識(shí)推理和分布外魯棒性,我們將在后面詳細(xì)討論。值得注意的是,這些能力很接近 NLP 社區(qū)幾十年來(lái)一直尋求的能力,因此代表了一種潛在的研究范式轉(zhuǎn)變,即從微調(diào)小模型到使用大模型進(jìn)行上下文學(xué)習(xí)。對(duì)于先行者來(lái)說(shuō),范式轉(zhuǎn)變可能是很顯然的。然而,出于科學(xué)的嚴(yán)謹(jǐn)性, 我們確實(shí)需要非常明確的理由來(lái)說(shuō)明為什么人們應(yīng)該轉(zhuǎn)向大型語(yǔ)言模型,即使這些模型昂貴、難以使用,并且效果可能一般 。在本文中,我們將仔細(xì)研究這些能力是什么,大型語(yǔ)言模型可以提供什么,以及它們?cè)诟鼜V泛的 NLP/ML 任務(wù)中的潛在優(yōu)勢(shì)是什么。
前提 :我們假設(shè)讀者具備以下知識(shí):
- 預(yù)訓(xùn)練、精調(diào)、提示(普通從業(yè)者應(yīng)具備的自然語(yǔ)言處理/深度學(xué)習(xí)能力)
- 思維鏈提示、便簽本(普通從業(yè)者可能不太了解,但不影響閱讀)
存在于大模型而非小模型的突現(xiàn)能力
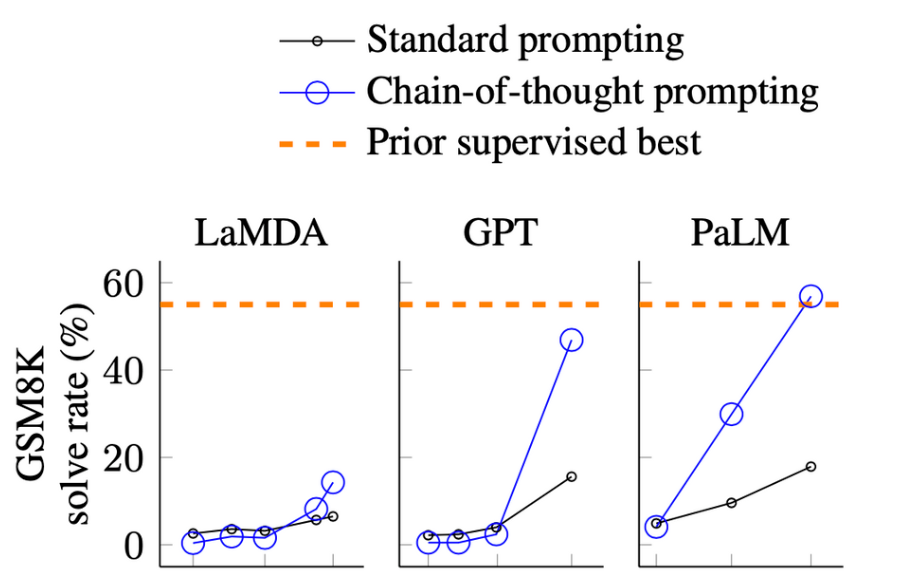
圖片來(lái)自于 Wei. et. al. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models。X軸為模型尺寸。GSM8K是是一個(gè)小學(xué)水平的數(shù)學(xué)問(wèn)題集。
在以上的效果圖中,我們可以觀察到模型的表現(xiàn):
- 當(dāng)尺寸相對(duì)小的時(shí)候提升并不大
- 當(dāng)模型變大時(shí)有很明顯的提升
這從根本上說(shuō)明,某些能力可能不存在于小模型中,而是在大模型中獲得的。
有很多種突現(xiàn)能力,比如 Wei 等人在 2022年 ^[5]^ 所梳理的。有些能力很有意思,但我們?cè)诒疚牟粫?huì)討論,比如last latter concatenation,我們認(rèn)為這是Python而不是語(yǔ)言模型要做的任務(wù);或者3位數(shù)加法,我們認(rèn)為這是計(jì)算器而不是語(yǔ)言模型要做的事。
在本文中,我們主要對(duì)以下能力感興趣:
- NLP 社區(qū)近幾年都關(guān)注但還沒(méi)實(shí)現(xiàn)的能力
- 之前的 NLP 模型很難達(dá)到的能力
- 源自于人類語(yǔ)言最深層的本質(zhì)的能力
- 可能達(dá)到人類智力的最高水平的能力
突現(xiàn)能力的三個(gè)典型例子
很多有意思的能力都可以歸到上文提到的類別里,在它們之中,我們主要討論以下三種典型能力:
- 復(fù)雜推理
- 知識(shí)推理
- 分布外魯棒性
接下來(lái)讓我們一個(gè)個(gè)詳細(xì)討論。
復(fù)雜推理
下面是一個(gè)GSM8K數(shù)據(jù)集中,用提示詞顯著超過(guò)精調(diào)的例子:
問(wèn)題:
克萊兒每天早飯都用 3 顆蛋做蛋卷,她 4 周會(huì)吃掉多少打雞蛋?
克萊兒每天早飯都用3顆蛋做蛋卷。
一周有 7 天。
所以她一周會(huì)吃 3 * 7 = 21 顆蛋。
她4周會(huì)吃掉 4 * 21 = 84 顆蛋。
一打里面是 12 顆蛋。
所以 84 / 12 = 7。
答案是7。
雖然這道題對(duì)于10歲的孩子來(lái)說(shuō)很容易,但對(duì)語(yǔ)言模型來(lái)說(shuō)卻很難,主要是由于數(shù)學(xué)和語(yǔ)言混合在一起。
GSM8K 最初由 OpenAI 于 2021 年 10 月 ^[6]^ 提出。當(dāng)時(shí)他們用第一版GPT3在全部訓(xùn)練集上進(jìn)行了精調(diào),準(zhǔn)確率約為 35% 。這個(gè)結(jié)果讓作者相當(dāng)悲觀,因?yàn)樗麄兊慕Y(jié)果顯示了語(yǔ)言模型的縮放規(guī)律:隨著模型大小呈指數(shù)增長(zhǎng),性能呈線性增長(zhǎng)(我之后會(huì)討論)。因此,他們?cè)诘?4.1 節(jié)中思考:
“175B 模型似乎需要至少額外兩個(gè)數(shù)量級(jí)的訓(xùn)練數(shù)據(jù)才能達(dá)到 80% 的求解率。 ”
三個(gè)月后,即 2022 年 1 月,Wei 等人 ^[7]^ 基于 540B PaLM 模型,僅使用了8個(gè)思維鏈提示示例便將準(zhǔn)確率提高到56.6% (無(wú)需將訓(xùn)練集增加兩個(gè)數(shù)量級(jí))。之后在 2022 年 3 月 ,Wang 等人 ^[8]^ 基于相同的 540B PaLM 模型,通過(guò)多數(shù)投票的方法將準(zhǔn)確率提高到 74.4% 。當(dāng)前的 SOTA 來(lái)自我自己在 AI2 的工作(Fu et. al. Nov 2022 ^[9]^ ),我們通過(guò)使用復(fù)雜的思維鏈在 175B Codex 上實(shí)現(xiàn)了 82.9% 的準(zhǔn)確率。從以上進(jìn)展可以看到,技術(shù)進(jìn)步確實(shí)呈指數(shù)級(jí)增長(zhǎng)。
思維鏈提示是一個(gè)展示模型隨著規(guī)模突現(xiàn)出能力的典型例子:
- 從突現(xiàn)能力來(lái)看 :盡管不需要 17500B,但模型大小確實(shí)要大于 100B ,才能使思維鏈的效果大于的僅有回答提示。所以這種能力只存在于大型模型中。
- 從 效果來(lái)看 :思想鏈提示的性能明顯優(yōu)于其之前的精調(diào)方法(目前還沒(méi)有能公平對(duì)比提示詞和微調(diào)的工作。但當(dāng)思維鏈被提出的時(shí)候,盡管他們對(duì)于提示和精調(diào)的比較可能是不公平的,但確實(shí)比精調(diào)效果要好)。
- 從標(biāo)注效率上來(lái)看 :思維鏈提示只需要 8 個(gè)示例的注釋,而微調(diào)需要完整的訓(xùn)練集。
有些同學(xué)可能會(huì)認(rèn)為模型能做小學(xué)數(shù)學(xué)代表不了什么(從某種意義上說(shuō),他們確實(shí)沒(méi)有那么酷)。但 GSM8K 只是一個(gè)開(kāi)始,最近的工作已經(jīng)把前沿問(wèn)題推向了高中 ^[10]^ 、大學(xué) ^[11]^ ,甚至是國(guó)際數(shù)學(xué)奧林匹克問(wèn)題 ^[12]^ 。現(xiàn)在更酷了嗎?
知識(shí)推理
下一個(gè)例子是需要知識(shí)的推理能力(例如問(wèn)答和常識(shí)推理)。在這種情況下, 對(duì)大型模型進(jìn)行提示不一定優(yōu)于精調(diào)小型模型 (哪個(gè)模型更好還有待觀察)。但是 這個(gè)情況下的注釋效率被放大了 ,因?yàn)椋?/p>
- 在許多數(shù)據(jù)集中,為了獲得所需的背景/常識(shí)知識(shí),(以前很小的)模型需要一個(gè)外部語(yǔ)料庫(kù)/知識(shí)圖譜來(lái)檢索 ^[13]^ ,或者需要通過(guò)多任務(wù)學(xué)習(xí)在增強(qiáng) ^[14]^ 的數(shù)據(jù)上進(jìn)行訓(xùn)練
- 對(duì)于大型語(yǔ)言模型,可以直接去掉檢索器 ^[15]^ ,僅依賴模型的內(nèi)部知識(shí) ^[16]^ ,且無(wú)需精調(diào)

圖片來(lái)自于 Yu et. al. 2022. 以前的 SOTA 模型需要從外部知識(shí)源中檢索。GPT-3 的性能與以前的模型相當(dāng)/優(yōu)于以前的模型,且無(wú)需檢索。
如表中所示,與數(shù)學(xué)題的例子不同,GPT-3 并沒(méi)有明顯優(yōu)于之前的精調(diào)模型。但它不需要從外部文檔中檢索,本身就包含了知識(shí)(雖然這些知識(shí)可能過(guò)時(shí)或者不可信,但選擇哪種可信知識(shí)源超出了本文的討論范圍)。
為了理解這些結(jié)果的重要性,我們可以回顧一下歷史:NLP 社區(qū)從一開(kāi)始就面臨著如何有效編碼知識(shí)的挑戰(zhàn)。人們一直在不斷探究把知識(shí)保存在模型外部或者內(nèi)部的方法。上世紀(jì)九十年代以來(lái),人們一直試圖將語(yǔ)言和世界的規(guī)則記錄到一個(gè)巨大的圖書館中,將知識(shí)存儲(chǔ)在模型之外。但這是十分困難的,畢竟我們無(wú)法窮舉所有規(guī)則。因此,研究人員開(kāi)始構(gòu)建特定領(lǐng)域的知識(shí)庫(kù),來(lái)存儲(chǔ)非結(jié)構(gòu)化文本、半結(jié)構(gòu)化(如維基百科)或完全結(jié)構(gòu)化(如知識(shí)圖譜)等形式的知識(shí)。通常, 結(jié)構(gòu)化知識(shí)很難構(gòu)建 (因?yàn)橐O(shè)計(jì)知識(shí)的結(jié)構(gòu)體系), 但易于推理 (因?yàn)橛畜w系結(jié)構(gòu)), 非結(jié)構(gòu)化知識(shí)易于構(gòu)建 (直接存起來(lái)就行), 但很難用于推理 (沒(méi)有體系結(jié)構(gòu))。然而,語(yǔ)言模型提供了一種新的方法,可以輕松地從非結(jié)構(gòu)化文本中提取知識(shí),并在不需要預(yù)定義模式的情況下有效地根據(jù)知識(shí)進(jìn)行推理。下表為優(yōu)缺點(diǎn)對(duì)比:
| 構(gòu)建 | 推理 | |
|---|---|---|
| 結(jié)構(gòu)化知識(shí) | 難構(gòu)建,需要設(shè)計(jì)體系結(jié)構(gòu)并解析 | 容易推理,有用的結(jié)構(gòu)已經(jīng)定義好了 |
| 非結(jié)構(gòu)化知識(shí) | 容易構(gòu)建,只存儲(chǔ)文本即可 | 難推理,需要抽取有用的結(jié)構(gòu) |
| 語(yǔ)言模型 | 容易構(gòu)建,在非結(jié)構(gòu)化文本上訓(xùn)練 | 容易推理,使用提示詞即可 |
分布外魯棒性
我們討論的第三種能力是分布外的魯棒性。在 2018 年至 2022 年期間,NLP、CV 和通用機(jī)器學(xué)習(xí)領(lǐng)域有大量關(guān)于分布偏移/對(duì)抗魯棒性/組合生成的研究,人們發(fā)現(xiàn)當(dāng)測(cè)試集分布與訓(xùn)練分布不同時(shí),模型的行為性能可能會(huì)顯著下降。然而,在大型語(yǔ)言模型的上下文學(xué)習(xí)中似乎并非如此。Si 等人在2022年的研究顯示 ^[17]^ :

數(shù)據(jù)來(lái)自于 Si et. al. 2022. 雖然 GPT-3 在同分布設(shè)置下比 RoBERTa 要差,但在非同分布設(shè)置下優(yōu)于 RoBERTa,性能下降明顯更小。
同樣,在此實(shí)驗(yàn)中,同分布情況下基于提示詞的 GPT-3 的效果并沒(méi)有精調(diào)后的 RoBERTa要好。但它在三個(gè)其他分布(領(lǐng)域切換、噪聲和對(duì)抗性擾動(dòng))中優(yōu)于 RoBERTa,這意味著 GPT3 更加魯棒。
此外,即使存在分布偏移,好的提示詞所帶來(lái)的泛化性能依舊會(huì)繼續(xù)保持。比如:

圖片來(lái)自于 Fu et. al. 2022. 即使測(cè)試分布與訓(xùn)練分布不同,復(fù)雜提示也始終比簡(jiǎn)單提示的表現(xiàn)更好。
Fu 等人2022年 ^[18]^ 的研究顯示,輸入提示越復(fù)雜,模型的性能就越好。這種趨勢(shì)在分布轉(zhuǎn)移的情況下也會(huì)繼續(xù)保持:無(wú)論測(cè)試分布與原分布不同、來(lái)自于噪聲分布,或者是從另一個(gè)分布轉(zhuǎn)移而來(lái)的,復(fù)雜提示始終優(yōu)于簡(jiǎn)單提示。
到目前為止的總結(jié)
在上文中,我討論了只有大型模型才有的三種突現(xiàn)能力。它們是:
- 復(fù)雜推理,大型模型在沒(méi)有使用全部訓(xùn)練數(shù)據(jù)的情況下便顯著優(yōu)于以前的小型模型。
- 知識(shí)推理,大型模型可能沒(méi)有小模型效果好,但大模型不需要額外的知識(shí)來(lái)源(知識(shí)可能很昂貴,或者很難從非結(jié)構(gòu)化數(shù)據(jù)中抽取)。
- 分布外魯棒性,這是之前進(jìn)行模型精調(diào)時(shí)需要努力解決的問(wèn)題。大型模型雖然在同分布情況下的效果不如以前的方法,但非同分布情況下的泛化性能卻好得多。
突現(xiàn)能力推翻比例定律
鑒于上文列出的優(yōu)點(diǎn),大家可能會(huì)開(kāi)始覺(jué)得大型語(yǔ)言模型確實(shí)很好了。在進(jìn)一步討論之前,讓我們?cè)倩仡櫼幌轮暗墓ぷ鳎蜁?huì)發(fā)現(xiàn)一個(gè)很奇怪的問(wèn)題: GPT-3 在 2020 年就發(fā)布了,但為什么直到現(xiàn)在我們才發(fā)現(xiàn)并開(kāi)始思考范式的轉(zhuǎn)變 ?
這個(gè)問(wèn)題的答案就藏在兩種曲線中:對(duì)數(shù)線性曲線和相變曲線。如下圖:

左圖: 比例定律. 當(dāng)模型大小呈指數(shù)增長(zhǎng)時(shí),相應(yīng)的模型性能呈線性增長(zhǎng)。右圖: 當(dāng)模型尺寸達(dá)到一定規(guī)模時(shí),會(huì)出現(xiàn)突現(xiàn)能力,讓性能急劇增加。
最初,(OpenAI)的研究者認(rèn)為語(yǔ)言模型的性能與模型尺寸的關(guān)系可以通過(guò)對(duì)數(shù)線性曲線預(yù)測(cè),即模型尺寸呈指數(shù)增長(zhǎng)時(shí),性能會(huì)隨之線性增加。這種現(xiàn)象被稱為語(yǔ)言模型的縮放定律,正如 Kaplan 等人在2020年 ^[19]^ 最初的GPT3文章 ^[20]^ 中討論的那樣。重要的是,在那個(gè)階段,即便最大的 GPT-3 在有提示的情況下也不能勝過(guò)小模型精調(diào)。所以當(dāng)時(shí)并沒(méi)有必要去使用昂貴的大模型(即使提示詞的標(biāo)注效率很高)。直到2021年,Cobbe 等人 ^[21]^ 發(fā)現(xiàn)縮放定律同樣適用于精調(diào)。這是一個(gè)有點(diǎn)悲觀的發(fā)現(xiàn),因?yàn)樗馕吨?我們可能被鎖定在模型規(guī)模上 ——雖然模型架構(gòu)優(yōu)化可能會(huì)在一定程度上提高模型性能,但效果仍會(huì)被鎖定在一個(gè)區(qū)間內(nèi)(對(duì)應(yīng)模型規(guī)模),很難有更顯著的突破。
在縮放定律的掌控下(2020年到2021),由于GPT-3無(wú)法勝過(guò)精調(diào) T5-11B,同時(shí)T5-11B微調(diào)已經(jīng)很麻煩了,所以NLP社區(qū)的關(guān)注點(diǎn)更多的是研究更小的模型或者高效參數(shù)適應(yīng)。Prefix tuning ^[22]^ 就是提示和適應(yīng)交叉的一個(gè)例子,后來(lái)由 He 等人在 2021 ^[23]^ 統(tǒng)一。當(dāng)時(shí)的邏輯很簡(jiǎn)單:如果精調(diào)效果更好,我們就應(yīng)該在高效參數(shù)適應(yīng)上多下功夫;如果提示詞的方法更好,我們應(yīng)該在訓(xùn)練大型語(yǔ)言模型上投入更多精力。
之后在 2022 年 1 月,思維鏈的工作被放出來(lái)了。正如作者所展示的那樣,思維鏈提示在性能-比例曲線中表現(xiàn)出明顯的 相變 。當(dāng)模型尺寸足夠大時(shí),性能會(huì)顯著提高并明顯超越比例曲線。
當(dāng)使用思維鏈進(jìn)行提示時(shí),大模型在復(fù)雜推理上的表現(xiàn)明顯優(yōu)于微調(diào),在知識(shí)推理上的表現(xiàn)也很有競(jìng)爭(zhēng)力,并且分布魯棒性也存在一定的潛力。要達(dá)到這樣的效果只需要8個(gè)左右的示例,這就是為什么范式可能會(huì)轉(zhuǎn)變的原因。
范式轉(zhuǎn)變意味著什么?
范式轉(zhuǎn)變究竟意味著什么?下面我們給出精調(diào)和提示詞方法的對(duì)比:

提示詞的好處很明顯:我們不再需要繁瑣的數(shù)據(jù)標(biāo)注和在全量數(shù)據(jù)上進(jìn)行精調(diào),只需要編寫提示詞并獲得滿足要求的結(jié)果,這比精調(diào)要快很多。
另外要注意的兩點(diǎn)是:
上下文學(xué)習(xí)是監(jiān)督學(xué)習(xí)嗎?
- 坦白講,我不確定。
- 相似之處在于,上下文學(xué)習(xí)也需要像訓(xùn)練數(shù)據(jù)一樣的示例
- 不同之處在于,上下文學(xué)習(xí)的泛化行為并不同于監(jiān)督學(xué)習(xí),這使得之前的泛化理論(例如 Rademancher Complexity 或 Neural Tangent Kernel)均不適用。
上下文學(xué)習(xí)真的比監(jiān)督學(xué)習(xí)效果要好嗎?
- 答案還未知。
- 大多數(shù)提示詞和精調(diào)的對(duì)比都只比了 提示詞+大模型 vs 精調(diào)+小模型,但公平的對(duì)比應(yīng)該是 提示詞+大模型 vs 精調(diào)+大模型,且對(duì)比時(shí)的基座模型應(yīng)該一樣。所以在最初的思維鏈文章中,如果 Wei 等人要說(shuō)明提示詞好于精調(diào),他們應(yīng)該對(duì)比精調(diào)后的PaLM,而不是GPT3。
- 我的假設(shè)是:精調(diào)可以提高分布內(nèi)的性能,但會(huì)損害分布外的魯棒性。提示詞在分布變化的場(chǎng)景中表現(xiàn)更好,但在同分布場(chǎng)景下不如精調(diào)。
- 如果假設(shè)是真的,那么一個(gè)值得研究的問(wèn)題就是如何在不犧牲其上下文學(xué)習(xí)能力的情況下進(jìn)行精調(diào)
- 注意分布外精調(diào)的效果同樣會(huì)隨著模型尺寸變化 。比如 Yang 等人在2022年的工作中,第四張表就顯示,Bart-based的分布外泛化能力會(huì)下降,但Bart-large則提升。對(duì)于大模型,當(dāng)測(cè)試集的分布和訓(xùn)練集相差不大時(shí),同分布的精調(diào)效果也應(yīng)該會(huì)提升。
再回顧一下前文提到的的邏輯:如果精調(diào)更好,我們應(yīng)該努力研究如何進(jìn)行參數(shù)高效的優(yōu)化;如果提示詞更好,我們應(yīng)該努力去訓(xùn)練更好的大型語(yǔ)言模型。
所以,盡管我們相信大型語(yǔ)言模型有巨大的潛力,仍然沒(méi)有確鑿的證據(jù)表明精調(diào)和提示詞哪種方法更好,因此我們不確定范式是否真的應(yīng)該轉(zhuǎn)變、或應(yīng)該轉(zhuǎn)變到什么程度。仔細(xì)比較這兩種范式,使我們對(duì)未來(lái)有一個(gè)清晰的認(rèn)識(shí),是非常有意義的。我們將更多討論留到下一篇文章。
模型應(yīng)該多大才夠?
兩個(gè)數(shù)字:62B 和 175B。
- 模型至少需要62B,使思維鏈的效果才能大于標(biāo)準(zhǔn)的提示詞方法。
- 模型至少需要175B(GPT3的尺寸),思維鏈的效果才能大于精調(diào)小模型(T5 11B)的效果。
62B這個(gè)數(shù)字來(lái)自于 Chung 等人 2022 年工作的第五張表 ^[24]^ :

對(duì)于所有小于62B的模型,直接用提示詞都好于思維鏈 。第一個(gè)用思維鏈更好的模型是 Flan-cont-PaLM 62B 在BBH上的結(jié)果。540B的模型使用思維鏈會(huì)在更多任務(wù)上得到好的效果,但也不是全部任務(wù)都好于精調(diào)。另外,理想的尺寸可以小于 540B,在 Suzgun 等人2022年 ^[25]^ 的工作中,作者展示了175B的 InstructGPT 和 175B的 Codex 使用思維鏈都好于直接用提示詞。綜合以上結(jié)果,我們得到了63B和175B兩個(gè)數(shù)字。所以,如果想要參與這場(chǎng)游戲,首先要有一個(gè)大于平均尺寸的模型。
不過(guò),還有其他大型模型在思維鏈下的表現(xiàn)差了很多,甚至不能學(xué)到思維鏈,比如 OPT、BLOOM 和 GPT-3 的第一個(gè)版本。他們的尺寸都是175B。這就引出了我們下一個(gè)要討論的問(wèn)題。
規(guī)模是唯一的因素嗎?
不是。
規(guī)模是一個(gè)必要但不充分的因素。有些模型足夠大(比如 OPT 和 BLOOM,都是 175B),但并不能做思維鏈。
有兩種模型可以做思維鏈 (TODO: add discussions about UL2):
- GPT3系列的模型,包括 text-davinci-002 和 code-davinci-002 (Codex)。 這是僅有的兩個(gè)具有強(qiáng)大突現(xiàn)能力并可公開(kāi)訪問(wèn)的模型 。
- 除了以上兩個(gè)模型,其他GPT3模型,包括原來(lái)的GPT3,text-davinci-001,以及其他更小的GPT-3模型,都不能做思維鏈。
- 當(dāng)說(shuō)“能做思維鏈”時(shí),我們是指使用思維鏈方法的效果比直接用提示詞、精調(diào)T5-11B效果更好。
- 另外要注意的是,code-davinci-002 在語(yǔ)言任務(wù)上的性能始終優(yōu)于 text-davinci-002。這個(gè)觀察非常有趣且耐人尋味。這表明 基于代碼數(shù)據(jù)訓(xùn)練的語(yǔ)言模型可以勝過(guò)根據(jù)語(yǔ)言訓(xùn)練的語(yǔ)言模型 。目前為止我們還不知道是為什么。
- PaLM系列模型,包括 PaLM、U-PaLM、Flan-PaLM 和 Minerva。這些模型目前還未開(kāi)放訪問(wèn)(此處@谷歌,快開(kāi)源吧)。
為什么會(huì)有突現(xiàn)能力目前還不清楚,但我們找出了一下可能產(chǎn)生突現(xiàn)能力的因素:
- 指令精調(diào):GPT-3 text-davinci-002 就是用指令+強(qiáng)化學(xué)習(xí)精調(diào) ^[26]^ 的產(chǎn)物。在這之前,text-davinci-001 做思維鏈的效果并不好。同時(shí)PaLM ^[27]^ 在經(jīng)過(guò)指令精調(diào) ^[28]^ 后的效果也有提升。
- 在代碼上精調(diào):Codex code-davinci-002 是在代碼上進(jìn)行精調(diào)的,它的效果持續(xù)好于 text-davinci-002。PaLM 也在代碼上進(jìn)行了調(diào)整。從表面上看,代碼與語(yǔ)言關(guān)系不大,但似乎起了很大作用,我們會(huì)在之后的文章進(jìn)行討論。
- 用思維鏈精調(diào):在 text-davinci-002 發(fā)布時(shí),谷歌已經(jīng)發(fā)布 PaLM 3 個(gè)月了。所以 OpenAI 應(yīng)該看到了思維鏈相關(guān)的工作。還有一些工作表明^[29]^ ^[30]^ ,直接用思維鏈數(shù)據(jù)進(jìn)行精調(diào)可以激發(fā)模型的思維鏈能力。
然而,所有這些因素在現(xiàn)階段都是推測(cè)。揭示如何訓(xùn)練才能讓模型產(chǎn)生突現(xiàn)能力是非常有意義的,我們將更多討論留到下一篇文章
總結(jié)
在本文中,我們仔細(xì)研究了語(yǔ)言模型的突現(xiàn)能力。我們強(qiáng)調(diào)了復(fù)雜推理、知識(shí)推理和分布外魯棒性的重要性和其中存在的機(jī)會(huì)。突現(xiàn)能力是非常令人興奮的,因?yàn)樗鼈兛梢猿奖壤桑⒃诒壤€中表現(xiàn)出相變。我們?cè)敿?xì)討論了研究范式是否會(huì)真的從精調(diào)轉(zhuǎn)向上下文學(xué)習(xí),但我們目前還沒(méi)有確切答案,因?yàn)榫{(diào)和上下文學(xué)習(xí)在分布內(nèi)、分布外場(chǎng)景下的效果仍有待對(duì)比。最后,我們討論了產(chǎn)生突現(xiàn)能力的三個(gè)潛在因素:指令精調(diào)、代碼精調(diào)和思維鏈精調(diào)。非常歡迎大家提出建議和討論。
另外我們還提到了兩個(gè)尚未討論的有趣問(wèn)題:
- 我們是否能公平對(duì)比精調(diào)和上下文學(xué)習(xí)的效果?
- 我們是如何訓(xùn)練大模型,才能讓模型具備突現(xiàn)能力、思維鏈能力?
對(duì)于這兩個(gè)問(wèn)題,我們會(huì)在之后的文章中進(jìn)行討論。
中英對(duì)照表
| 英文 | 中文 | 釋義 |
|---|---|---|
| Emergent Ability | 突現(xiàn)能力 | 小模型沒(méi)有,只在模型大到一定程度才會(huì)出現(xiàn)的能力 |
| Prompt | 提示詞 | 把 prompt 輸入給大模型,大模型給出 completion |
| In-Context Learning | 上下文學(xué)習(xí) | 在 prompt 里面寫幾個(gè)例子,模型就可以照著這些例子做生成 |
| Chain-of-Thought | 思維鏈 | 在寫 prompt 的時(shí)候,不僅給出結(jié)果,還要一步一步地寫結(jié)果是怎么推出來(lái)的 |
| Scaling Laws | 縮放法則 | 模型的效果的線性增長(zhǎng)要求模型的大小指數(shù)增長(zhǎng) |
| Parameter-efficient Adaptation | 高效參數(shù)適應(yīng) | 在固定住大模型參數(shù)的情況下,增加少量的新參數(shù)進(jìn)行精調(diào) |
| Distribution Shift | 分布轉(zhuǎn)換 | 在一種數(shù)據(jù)分布上進(jìn)行訓(xùn)練,在另一種數(shù)據(jù)分布上測(cè)試 |
| Instruction Tuning | 指令精調(diào) | 用 instruction 來(lái) fine-tune 大模型 |
| Code Tuning | 在代碼上微調(diào) | 用代碼來(lái) fine-tune 大模型 |
參考資料
[1]https://www.yitay.net/blog/emergence-and-scaling: https://www.jasonwei.net/blog/emergence
[2]Wei et. al. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models: https://arxiv.org/abs/2201.11903
[3]便簽本: https://lingo.csail.mit.edu/blog/arithmetic_gpt3/
[4]Wei et. al. 2022. Emergent Abilities of Large Language Models: https://arxiv.org/abs/2206.07682
[5]Wei et. al. 2022. Emergent Abilities of Large Language Models: https://arxiv.org/abs/2206.07682
[6]Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems: https://arxiv.org/abs/2110.14168
[7]Wei et. al. 2022. Chain of Thought Prompting Elicits Reasoning in Large Language Models: https://arxiv.org/abs/2201.11903
[8]Wang et. al. 2022. Self-Consistency Improves Chain of Thought Reasoning in Language Models: https://arxiv.org/abs/2203.11171
[9]Fu et. al. 2022. Complexity-Based Prompting for Multi-step Reasoning: https://arxiv.org/abs/2210.00720
[10]Chung et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
[11]Lewkowycz et. al. 2022. Minerva: Solving Quantitative Reasoning Problems with Language Models: https://arxiv.org/abs/2206.14858
[12]Jiang et. al. 2022. Draft, Sketch, and Prove: Guiding Formal Theorem Provers with Informal Proofs: https://arxiv.org/abs/2210.12283
[13]Xu et. al. 2021. Fusing Context Into Knowledge Graph for Commonsense Question Answering: https://aclanthology.org/2021.findings-acl.102.pdf
[14]Khashabi et. al. 2020. UnifiedQA: Crossing Format Boundaries With a Single QA System: https://aclanthology.org/2020.findings-emnlp.171
[15]Yu et. al. 2022. Generate rather than Retrieve: Large Language Models are Strong Context Generators: http://arxiv.org/abs/2209.10063
[16]Jung et. al. 2022. Maieutic Prompting: Logically Consistent Reasoning with Recursive Explanations: https://arxiv.org/abs/2205.11822
[17]Si et. al. 2022. Prompting GPT-3 to be Reliable. : https://arxiv.org/abs/2210.09150
[18]Fu et. al. 2022. Complexity-based Prompting for Multi-Step Reasoning: https://arxiv.org/abs/2210.00720
[19]Kaplan et. al. 2020. Scaling Laws for Neural Language Models: https://arxiv.org/abs/2001.08361
[20]Brown et. al. 2020. Language Models are Few-Shot Learners.: https://arxiv.org/abs/2005.14165
[21]Cobbe et. al. 2021. Training Verifiers to Solve Math Word Problems: https://arxiv.org/abs/2110.14168
[22]Li and Liang. 2021. Prefix-Tuning: Optimizing Continuous Prompts for Generation: https://aclanthology.org/2021.acl-long.353.pdf
[23]He et. al. 2021. Towards a Unified View of Parameter-Efficient Transfer Learning: https://arxiv.org/abs/2110.04366
[24]Chung et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
[25]Suzgun et. al. 2022. Challenging BIG-Bench tasks and whether chain-of-thought can solve them: https://arxiv.org/abs/2210.09261
[26]Ouyang et. al. 2022. Training language models to follow instructions with human feedback: https://arxiv.org/abs/2203.02155
[27]Chowdhery et. al. 2022. PaLM: Scaling Language Modeling with Pathways: https://arxiv.org/abs/2204.02311
[28]Chung. et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
[29]Huang et. al. 2022. Large Language Models Can Self-Improve: https://arxiv.org/abs/2210.11610
[30]Chung. et. al. 2022. Scaling Instruction-Finetuned Language Models: https://arxiv.org/abs/2210.11416
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
524瀏覽量
10277 -
nlp
+關(guān)注
關(guān)注
1文章
488瀏覽量
22038 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1561瀏覽量
7674
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深入理解和實(shí)現(xiàn)RTOS_連載
深入理解和實(shí)現(xiàn)RTOS_連載
51單片機(jī)C語(yǔ)言講義(譚浩強(qiáng))以及深入理解C指針
深入理解STM32
對(duì)棧的深入理解
為什么要深入理解棧
STM32編程:是時(shí)候深入理解棧了<一>






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論