 AMD RDNA2 GPU架構詳解
AMD RDNA2 GPU架構詳解
2019年,AMD 放棄了長期使用的 GCN 架構,轉而采用 RDNA。本文我們將來分析下RDNA 2,RDNA 2在RDNA 1基礎上進行了擴展,同時添加了光線追蹤支持和其他一些增強功能。
在本文中,我們可以做一些有趣的事情,并從 RDNA 2 的角度來看一些游戲。
架構
顧名思義,RDNA 2 建立在 RDNA 1 架構之上。AMD 進行了多項更改以提高效率并使硬件功能保持最新狀態,但基本的 WGP 架構仍然存在。每個 WGP 或工作組處理器都具有四個 SIMD。每個 SIMD 都有一個32寬的執行單元,用于最常見的操作。RDNA 2 獲得一些額外的點積運算指令,以幫助加速機器學習。例如,V_DOT2_F32_F16 將成對的 FP16 值相乘、相加,然后添加一個 FP32 累加器。它不像Nvidia的張量核那樣,在Nvidia中,像HMMA這樣的指令直接處理8×8矩陣。但這些指令讓RDNA 2用更少的指令來做矩陣乘法,而不是使用普通的融合乘法-加法指令。
每個 SIMD 都有 32 個寬度的執行單元用于最常見的操作,一個 128 KB 的矢量寄存器文件,并且可以跟蹤多達 16 個波面。因此,AMD 減少了 RDNA 2 可以跟蹤的波面數量,從 RDNA 1 中的 20 個。GPU 不會像高性能 CPU 那樣進行亂序執行。相反,它們保持大量線程處于運行狀態,并在線程之間切換以保持執行單元被占用以隱藏延遲。在 RDNA 2 上,SIMD 基本上有 16 路 SMT,而在 RDNA 1 上有 20 路。
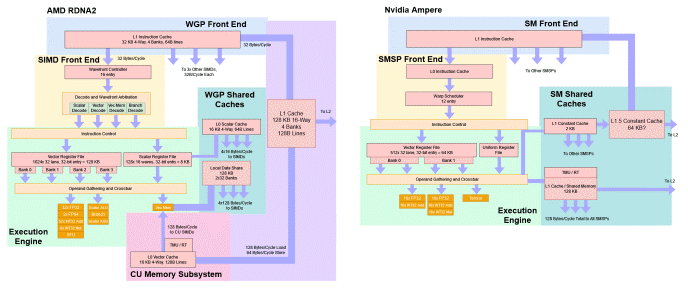
RDNA 2 架構的 WGP 和 Nvidia Ampere 的 SM 的基本草圖
這聽起來像是一種回歸(regression),但跟蹤更多的波陣面(類似于CPU線程)可能是昂貴的。線程或波面選擇邏輯必須解決與CPU調度器非常相似的問題。每個周期,每個條目都必須檢查,看它是否準備好執行了。AMD可能希望將每個周期的檢查次數從20次減少到16次,以便在更低的功率下達到更高的時鐘速度。在相同的處理節點上,RDNA 2的時鐘比它的前身要高得多,所以AMD在這方面做得很好。
RDNA 2也比安培好。盡管這兩種架構都使用基本的構建模塊(SMs或WGP),每個周期可以執行128個FP32操作,但RDNA 2 WGP可以保持64個波陣面。Ampere SM只能保持飛行中的48個warp。RDNA 2也有更多的向量寄存器文件容量,這意味著編譯器可以在不減少占用的情況下在寄存器中保存更多的數據。

這讓 RDNA 2 WGP 有更好的機會通過保持更多的工作在進行中來隱藏延遲。將其與更好的緩存相結合,每個 RDNA 2 WGP 都應該能夠比 Ampere SM 更有力。
WGP 的四個 SIMD 被組織成兩個一組,AMD 稱之為計算單元 (CU)。一個 CU 有自己的內存管道和 16 KB L0 向量緩存。在 CU 級別,AMD 增強了內存管道以添加硬件光線跟蹤加速。具體來說,紋理單元現在可以執行射線相交測試,每個周期進行四次框測試或每個周期進行一次三角形測試。盒子測試發生在 BVH 的上層,而三角測試發生在最后一層。BVH,或有界頂點層次結構,使用分而治之的方法加速光線追蹤。因為檢查場景中的每個三角形都非常昂貴,盒子測試縮小了光線穿過的區域,理想情況下 GPU 最后只檢查一組狹窄的三角形。

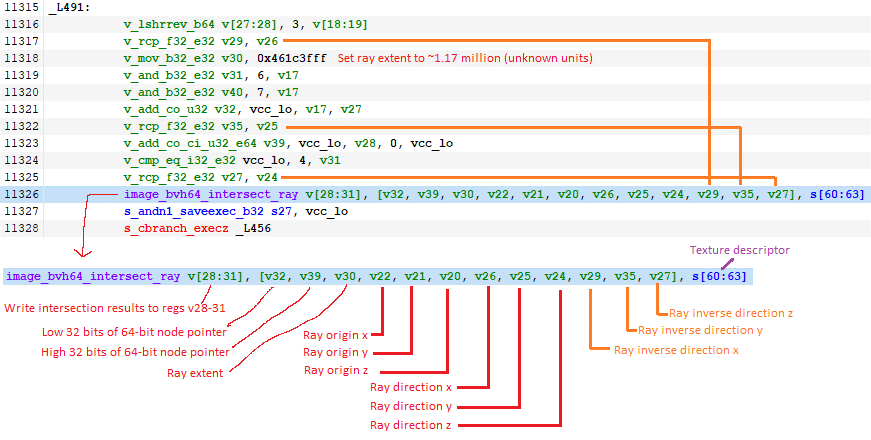
RDNA 2中引入的光線追蹤加速指令
光線追蹤加速是通過一些新的紋理指令來訪問的。顯然,這些指令實際上并沒有做傳統的紋理工作,但是紋理單元是附加這個額外功能的一個方便的地方。新的指令本身只做交集測試。常規的計算著色器代碼處理遍歷BVH。它還必須計算逆射線方向,并將其提供給紋理單元,即使紋理單元本身有足夠的信息來計算。AMD可能想要最小化支持光線追蹤的硬件成本,并且認為他們有足夠的常規著色器來解決這個問題。
緩存
除了在功能上與英偉達不相上下之外,RDNA 2還可以擴展到性能上。最高端的RDNA 1 GPU RX 5700 XT只有20個WGP。它也建立在一個251平方毫米的小芯片上,與英偉達的中端卡競爭,而不是挑戰他們的高端卡。RDNA 2的RX 6900 XT將WGP數翻了一番,并提高了時鐘速度,顯示了AMD想要挑戰英偉達最佳性能的雄心。但就像增加CPU的核心數量一樣,GPU的擴展也會產生更高的帶寬需求。英偉達選擇了耗電384位GDDR6X設置來為安培供電。AMD選擇了256位的GDDR6配置。為了避免內存帶寬瓶頸,RDNA 2獲得了額外級別的緩存。AMD將其命名為“無限緩存”,并在內部將其稱為MALL(內存連接最后一級)。
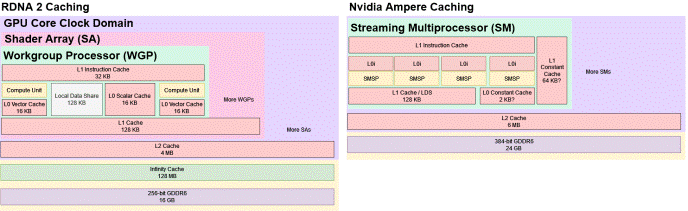
RDNA 2和英偉達Ampere的緩存層次結構的簡化草圖
MALL的名稱是有意義的,因為所有的VRAM訪問都要經過它。RDNA 2的L2也是一個由整個GPU共享的緩存,但是如果虛擬內存頁面被設置為非緩存,就可以繞過它。同步屏障也可以刷新L2以確保一致性。這些訪問可以被RDNA 2上的無限緩存捕獲,而以前的AMD GPU將從VRAM中提供服務。
因為L2應該足夠大以捕獲大量的內存訪問,無限緩存的性能并不是那么重要,AMD在一個單獨的時鐘域上運行無限緩存。這意味著它可以調得更低以節省電力。
延遲
通過延遲測試,我們可以看到AMD復雜的四級緩存系統的運行情況。我們還可以看到英偉達更簡單的兩級緩存結構。Ampere的SMs具有更大的L1緩存容量,當RDNA WGP必須從較慢的每個SA L1緩存時,可以讓SM服務請求從其第一級緩存。在較大的測試規模下,RDNA 2具有明顯的延遲優勢,特別是當測試規模溢出英偉達的L2時。
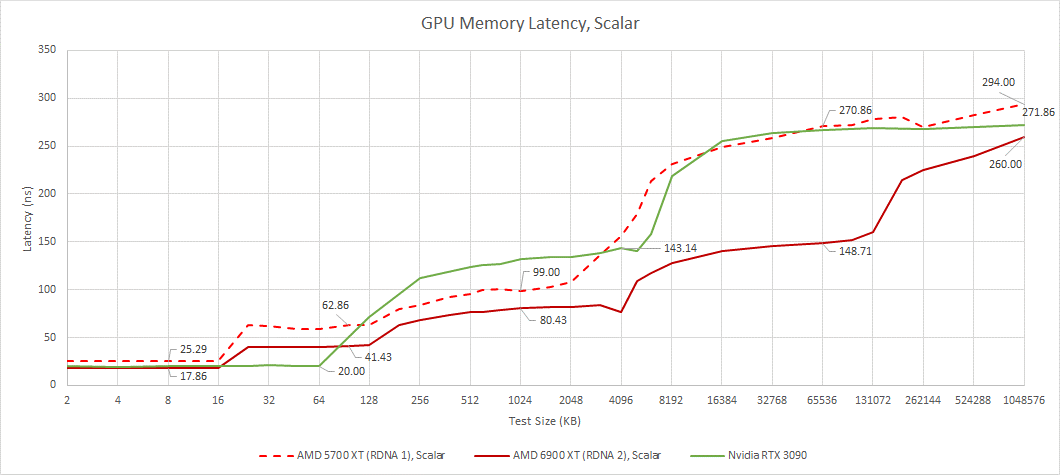
與 RDNA 1 相比,前三個緩存級別的性能提升較小,主要來自時鐘速度的提高。然后 Infinity Cache 在更大的測試規模上產生巨大影響。對于如此大的緩存,延遲非常低。作為對比,RTX 3090 的 L2 有 140 ns 的延遲,但只有 6 MB 的容量。
無限緩存延遲也值得仔細研究。AMD 的 Adrenaline Edition 軟件非常先進,可以讓用戶幾乎任意設置最大時鐘速度。我們可以使用它來查看緩存在 GPU 核心時鐘變化時的行為。
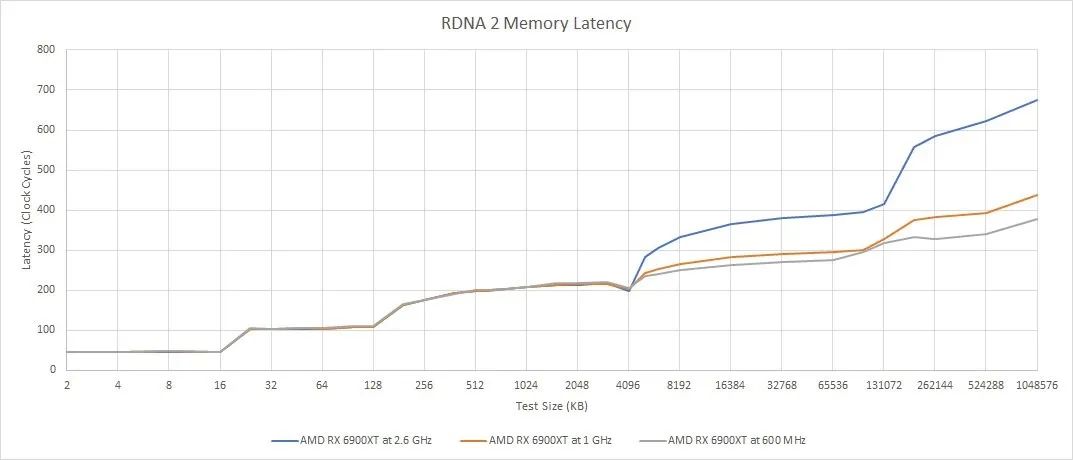
在較低的時鐘下,RDNA 2 的 WGP 從 Infinity Cache 獲取數據所需的周期更少。這可能意味著在較低時鐘下提高著色器利用率。
從矢量方面,我們看到了同樣的故事。RDNA 2 與速度更快的 RDNA 1 非常相似,帶有一個額外的巨大緩存。矢量訪問比標量訪問延遲更高。Nvidia 沒有單獨的標量內存層次結構。他們的架構確實有常量緩存,但那些是只讀的,并且比 AMD 的標量數據路徑服務的用途更有限。
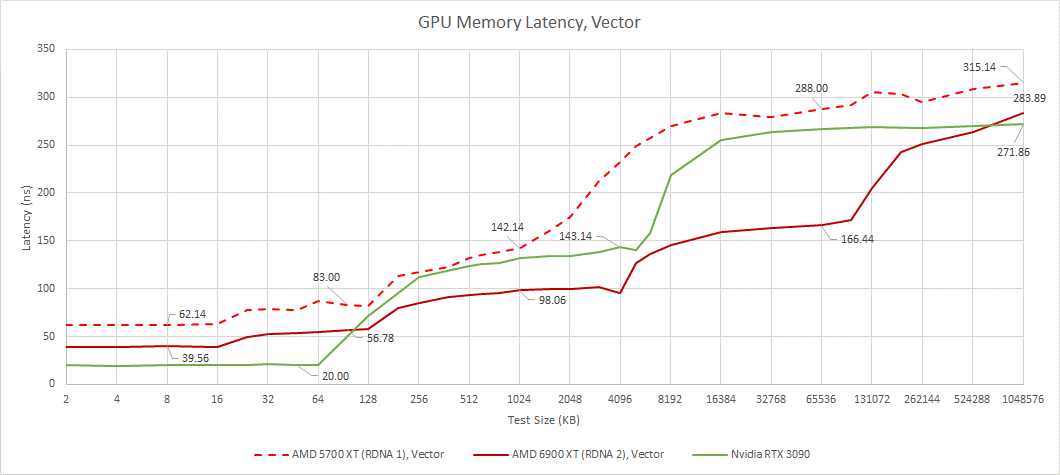
Nvidia 受益于較小測試規模的較低延遲,而 RDNA 2 在較大測試規模上保持優勢。AMD 的 L2 和 Infinity Cache 延遲看起來非常好,考慮到 RDNA 2 必須檢查比 Nvidia 更多的緩存級別。一旦我們到達 VRAM,情況就會逆轉。
帶寬
帶寬也很重要,因為 GPU 旨在并行處理大量操作。讓我們從查看單個工作組的帶寬開始。運行單個工作組將我們限制在 AMD 上的單個 WGP,或 Nvidia 架構上的 SM。這是我們可以在 CPU 上獲得的最接近單核帶寬的值。與 CPU 上的單核帶寬一樣,此類測試并不特別代表任何現實世界的工作負載。但它確實讓我們從單個計算單元的角度了解了內存層次結構。
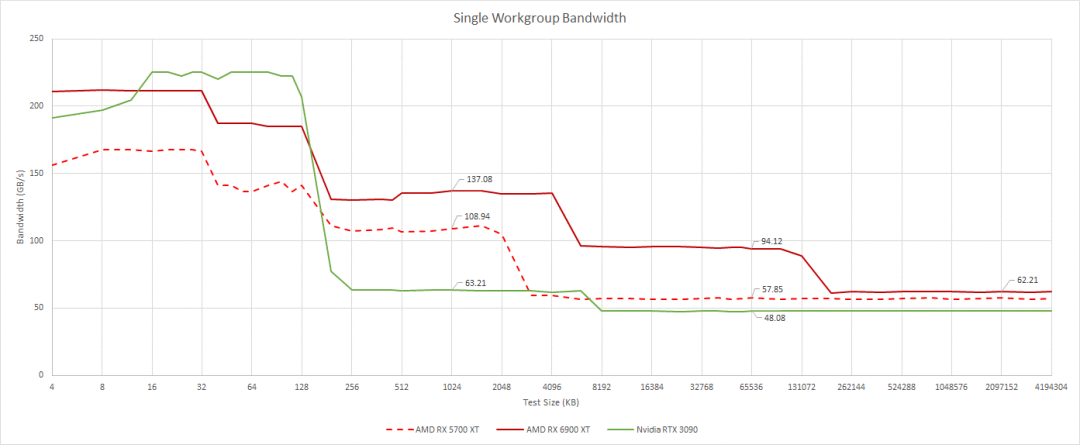
不評論第一級緩存帶寬,因為由于地址生成和邊界檢查開銷,這很難測試
通過一個WGP, RDNA 2通過高時鐘實現了非常高的緩存帶寬。這種優勢在大型測試中尤其突出,其中128 MB無限緩存發揮了作用。AMD的緩存架構比英偉達的要好得多。在低占用時,即使是無限緩存也可以提供比安培L2更多的帶寬。
隨著我們使用更多的工作組和加載更多的WGP或SMs,帶寬需求明顯上升。這對共享緩存提出了更大的要求。AMD在這方面做得很好。L2帶寬開始時非常出色,并且隨著我們加載更多WGPs而擴展得非常好。在我們開始獲得良好的帶寬之前,我們必須在Nvidia的RTX 3090上加載更多的SM。
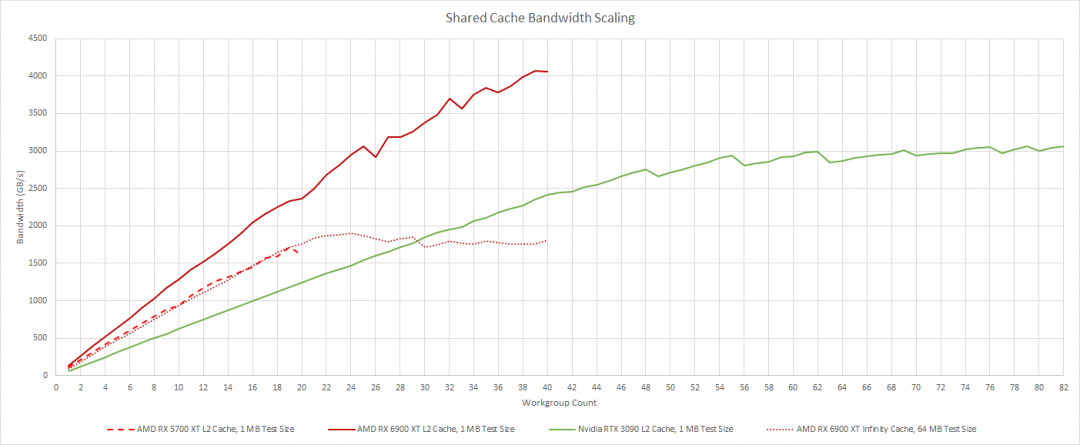
Infinity Cache 帶寬擴展也非常好,實際上與 RDNA 1 的 L2 帶寬非常接近。它無法與 Nvidia 的 3090 上的 L2 帶寬相匹配,但它不需要,因為它前面的 4 MB L2 應該可以捕獲大量訪問。到目前為止,AMD 在緩存帶寬方面看起來相當不錯。然而,VRAM 是另一回事。
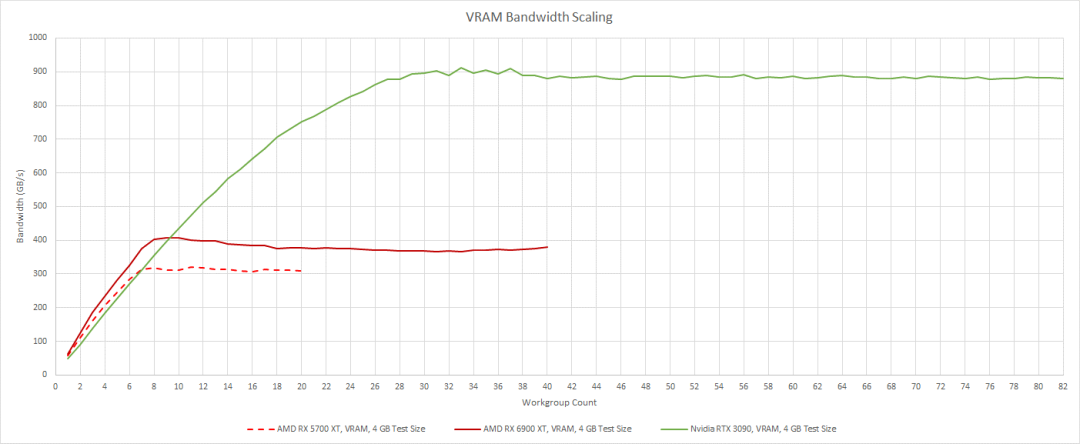
Nvidia 擁有巨大的 VRAM 帶寬優勢。對于高速緩存無法容納的大量工作負載,Ampere 耗盡 VRAM 帶寬的可能性要小得多。然而,兩代 RDNA 都更善于利用它們擁有的 VRAM 帶寬。他們不需要那么多的工作來充分利用他們的可用帶寬。
CU 和 WGP 模式
AMD RDNA 架構中的 WGP 可以在 WGP 模式和 CU 模式下運行。在 WGP 模式下,128 KB LDS 用作單個統一內存塊。WGP 中的所有四個 SIMD 都可以訪問整個 128 KB。在 CU 模式下,LDS 被分成兩個 64 KB 的一半,每個都與一對 SIMD 相關聯。
LDS延遲在兩種模式下保持相同,約為19.5 ns,即使CU模式應該簡化來自LDS的請求路由。這同樣適用于RDNA 1,它具有大約26.6 ns的LDS延遲。
LDS組織差異使我們能夠通過使用單個工作組進行測試來命中單個CU(WGP 的一半)。因為每個CU都有自己的內存管道和L0緩存,所以當我們在WGP中只使用一個CU 時,我們會看到 L0 帶寬下降。一旦我們到達 L2 之后,帶寬就不會下降。
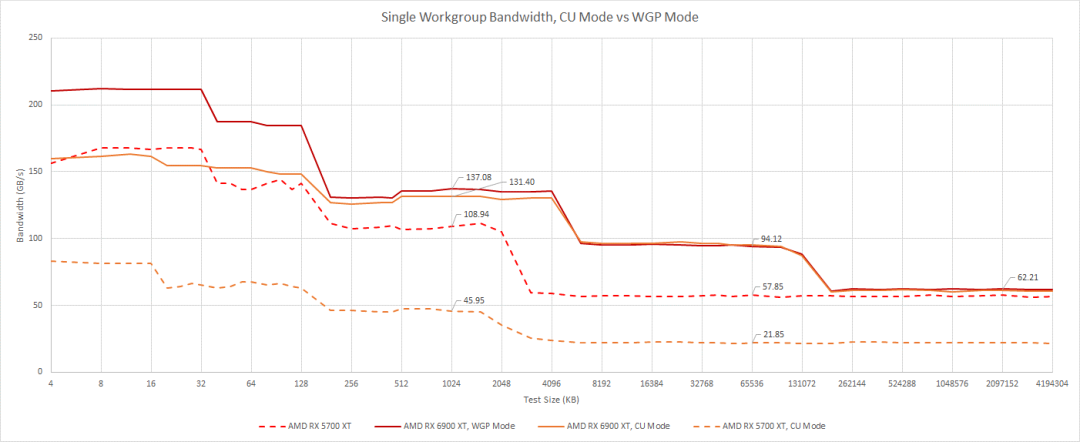
與RDNA 1相比,這是一個很大的改進,RDNA 1在緩存層次結構中看到了帶寬的顯著下降。帶寬通常取決于隊列隱藏延遲的能力,因此RDNA 2在分配隊列條目方面可能更靈活。也許L1和L2之間的一些隊列在RDNA 1中按CU分配,但在RDNA 2中按WGP分配。對于GPU工作負載,這意味著如果運行在WGP的一半中的波提前結束,RDNA 2會表現得更好。
從游戲的角度
RDNA 2 是游戲優先架構,所以讓我們看看 RX 6900 XT 在這些工作負載中必須處理什么。研究游戲也將幫助我們了解游戲工作負載是什么樣的。
賽博朋克2077,RT On
CD Projekt Red的《賽博朋克2077》是現代GPU技術的展示。它使用帶有大量光線追蹤的DirectX 12來提供豐富的圖形效果。不幸的是,這些影響可能非常嚴重。光線追蹤對性能的影響尤其大。請記住,這個游戲的數字是在GPU的最大時鐘設置為1800mhz的一致性下獲得的。3950X禁用了boost。因此,這里的數字不應被視為股票業績數字,也不應與其他系統進行比較。我們只關注顯卡在做什么工作。在這場比賽中,我們將沿著Jig Jig街向下看。
RT 相關工作占用大約 21 毫秒的幀時間。其中超過 9 毫秒用于構建 BVH,因此優化 BVH 構建時間幾乎與優化 BVH 遍歷一樣重要。為了渲染光線追蹤效果,6900 XT 必須進行 5.8 億次方框相交測試和 1.095 億次三角形相交測試。以達到的 25.9 FPS,即每秒 150 億次盒子測試和 28 億次三角測試。
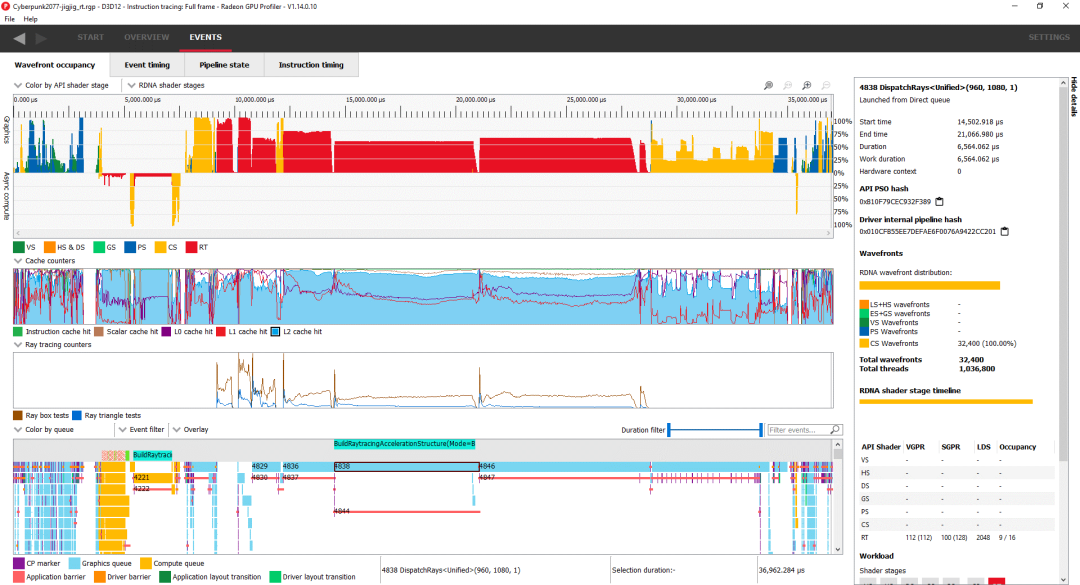
使用 Radeon GPU Profiler 檢查幀。頂視圖在渲染框架時顯示占用情況
除了光線追蹤,賽博朋克還大量使用計算。傳統的光柵化退居二線,也許顯示出尖端游戲的趨勢。因為大部分時間都花在了光線追蹤上,所以讓我們從運行時間最長的 DispatchRays 調用開始仔細看看。具體來說,讓我們看看單獨使用 7.2 毫秒的那個:
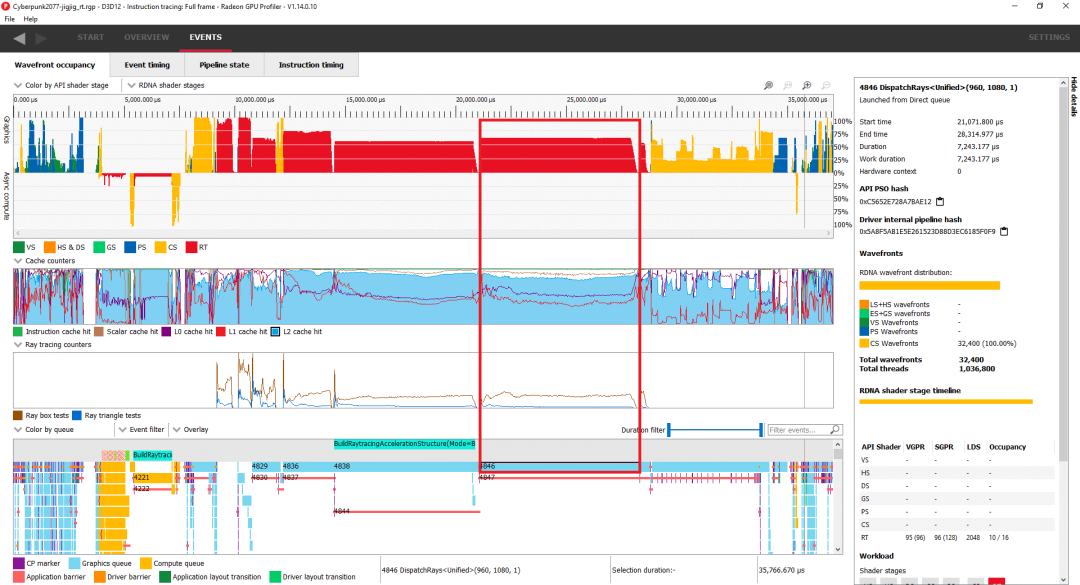
在我們正在查看的電話周圍放一個方框 在內部,RDNA 2 將光線跟蹤內核視為計算著色器。這個特定的調用啟動了 32,400 個計算波陣面。6900 XT 的 40 個 WGP 總共可以保持 2560 個波面在飛行中,所以這足以填滿整個 GPU。然而,RDNA 2 無法讓這個內核的 2560 個波面保持在飛行狀態,因為它沒有足夠的向量寄存器文件容量。與 CPU 不同,GPU 可以靈活地分配向量寄存器文件容量。為每個線程(波面)提供更多寄存器有助于防止寄存器溢出,但也會減少它可以保持運行的線程數量。
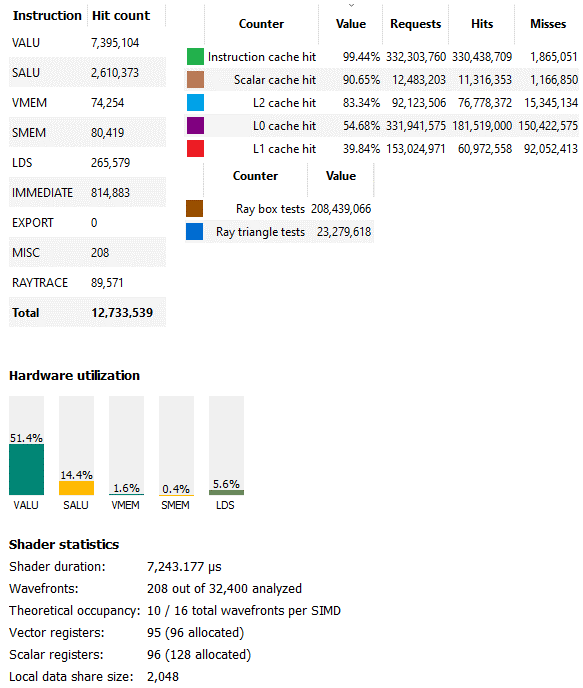
對于這個內核,編譯器選擇使用 96 個矢量寄存器,這意味著 RDNA 2 的矢量寄存器文件容量僅足以跟蹤每個 SIMD 的 10 個波面,或者整個 GPU 中的 1600 個。一方面,這意味著每個 SIMD 都無法通過在一個停頓時在波面之間切換來保持執行單元忙碌。另一方面,使用更多的寄存器可以讓編譯器暴露更多的指令級并行性。從配置文件來看,RDNA 2 花費大量時間占用受向量寄存器容量限制,因此減少 RDNA 1的最大占用看起來是合理的。
更多關于那次call的細節
在這種情況下,操作者可能做出了正確的權衡,或者至少沒有做出糟糕的決定。51%的矢量ALU使用率處于一個良好的位置。著色器沒有被充分利用。與此同時,利用率不會超過70-80%,這意味著只能使用計算方案。我們也看到少量的LDS使用。AMD使用LDS存儲BVH遍歷堆棧,使寫入和延遲敏感的讀取遠離未優化的全局內存路徑。其他光線跟蹤調用顯示了類似的硬件使用模式。
這是命中 RT 單元的著色器的基本塊。著色器必須使用三個額外的指令來計算光線方向的倒數,并將其與光線方向一起提供。三個額外的指令并不多,但這些相互指令相當昂貴,并且與更簡單的 FP32 操作相比只能以四分之一的速率執行。最重要的是,編譯器必須使用三個額外的寄存器來保存反向光線方向。我不確定這會產生多大的影響,但還有改進的余地。
不幸的是,AMD 沒有通過他們的分析工具公開 Infinity Cache 計數器。不過,我們還是可以看看前三級緩存是怎么做的。首先,L0 緩存命中率很差,略低于 55%。即使在 Bulldozer 等低于標準的實現中,CPU 通常也能看到超過 80% 的一級緩存命中率。128 KB 的中級緩存有助于捕捉其中的一些未命中,使累積的 L0+L1 命中率略低于 73%。我在這里的印象是L0和L1緩存太小了。4 MB L2 是這里的英雄,在進入更高延遲的 Infinity Cache 之前將累積命中率提高到 95.4%。
RDNA 2 的 16 KB 標量緩存實現了相對較好的命中率,剛好超過 90%,更重要的是從向量路徑卸載了一些請求。從指令方面看,L1i 的命中率超過 99%。GPU 程序的指令足跡似乎比 CPU 程序小,32 KB L1i 似乎足夠了。
BVH建筑
RGP 將幾個部分注釋為對構建BVH的BuildRaytracingAccelerationStructure的調用。如前所述,這些部分占用了很大一部分光線追蹤時間,所以讓我們也看看其中的一個。最長的一個是調用號 4838,奇怪的是它是一個 DispatchRays 調用并顯示交叉測試活動。我不確定那是什么意思,所以我將轉到第二長的那個。
調用4221對應于CmdDispatchBuildBVH,在計算隊列中運行。它的占用率很低,因為只有160個波陣面發射。這遠遠不足以填滿GPU,所以這部分可能會受到延遲的限制。同步障礙阻止GPU使用異步工作來保持執行單元繁忙。幸運的是,這部分只持續1.7毫秒。
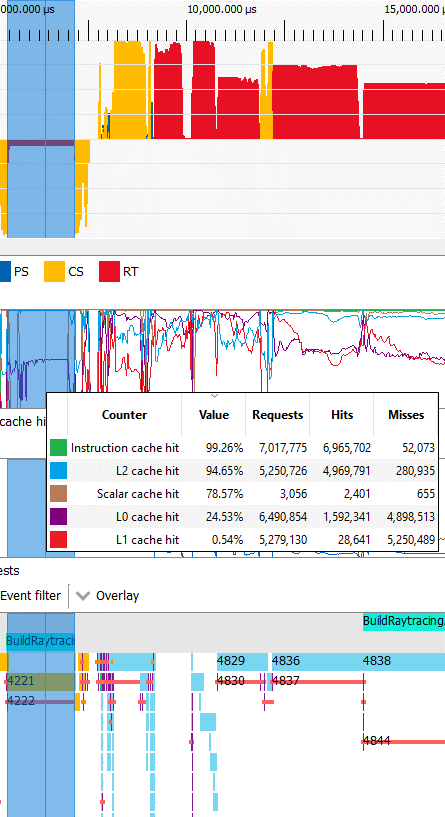
與上面介紹的光線遍歷部分不同,AMD 的驅動程序選擇在這個 BVH 構建部分使用 wave64 模式。我懷疑這是最好的選擇。wave32 模式在占用率低的情況下應該更可取,因為它允許更多的線程級并行性。但 AMD 可能有充分的理由使用 wave64,所以我將不再是一個紙上談兵的四分衛,而是轉向緩存。
和以前一樣,指令緩存命中率非常高。標量緩存沒有足夠的標量內存訪問。在向量方面,16 KB L0 的性能非常差,命中率低于 25%,而 128 KB L1 也可能不存在。RDNA 的 L2 最終服務于大部分內存流量,并且以比光線遍歷部分更極端的方式。由于占用率很低,L0/L1 緩存命中率很低,L2 延遲很可能成為構建 BVH 時的限制因素。
計算
除了光線追蹤(技術上被視為 RDNA 上的一種計算形式)之外,《賽博朋克 2077》還大量使用了計算著色器。該游戲中的非光線追蹤計算往往包含大量持續時間較短的調用,而不是一些非常繁重的調用。持續時間最長的計算調用(編號 4473)是為 wave32 模式編譯的,運行時間不到 0.7 毫秒。RDNA 2 午餐吃這個。著色器不使用大量矢量寄存器或 LDS 空間,并啟動 130,560 個波前。因此,入住率非常好。
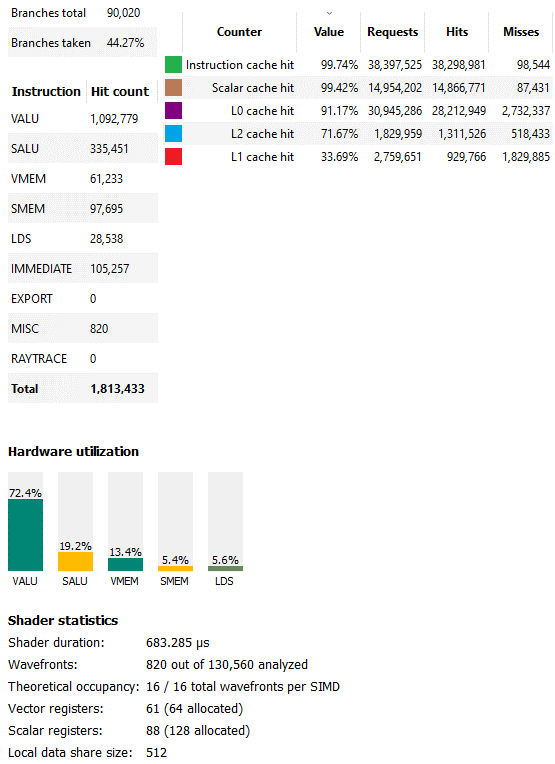
矢量ALU的利用也很好。事實上,這簡直太好了。再高一點,我們就稱這部分為有限計算。RDNA 2的標量數據路徑在卸載應用于波前的計算中起著關鍵作用。緩存命中率也有助于良好的計算利用率。大約94%的向量訪問是由L0和L1緩存提供服務的,其中大部分來自L0。L2使累積命中率超過98%。L1指令緩存和標量緩存的命中率如此之高,以至于失敗基本上是噪音。對于這個著色器,良好的緩存命中率和高占用率結合起來讓RDNA 2發光。
第二長的計算著色器(編號4884)運行了不到半毫秒,并表現出不同的特征。它使用的是wave64,并且占用被矢量寄存器文件容量限制為每個SIMD只有四個波。盡管如此,RGP仍然報告了非常好的VALU利用率。這可能是因為這個內核絕大多數由矢量ALU指令組成。沒有太多的內存訪問,而且大量的內存訪問確實會發生在標量路徑上。
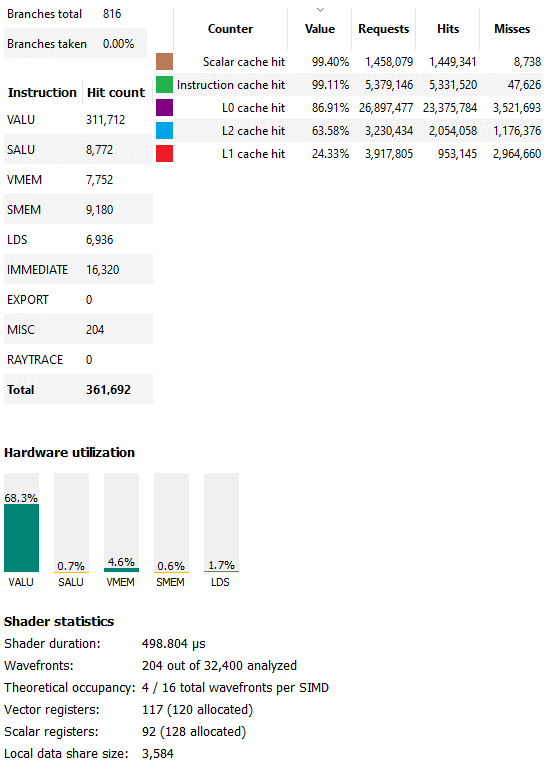
此外,這個計算著色器的分支很少,RGP 沒有選擇任何已采用的分支。GPU 上的分支非常昂貴,GPU 沒有分支預測并且必須暫停線程直到分支條件得到解決。沒有采取的分支也意味著分歧不是一個大問題。總的來說,這個著色器主要由直線 FP32 spam組成。GPU 喜歡這些東西。RDNA 2 也不例外,盡管占用率低,但硬件利用率非常好。
賽博朋克 2077,RT關閉
光線追蹤效果很酷,但Cyberpunk 2077在關閉 RT 的情況下看起來仍然非常好。如果美術師和開發人員擅長他們的工作,傳統的光柵化仍然可以渲染出令人印象深刻的場景,而 CP2077 的工作人員似乎絕對能勝任這項任務。
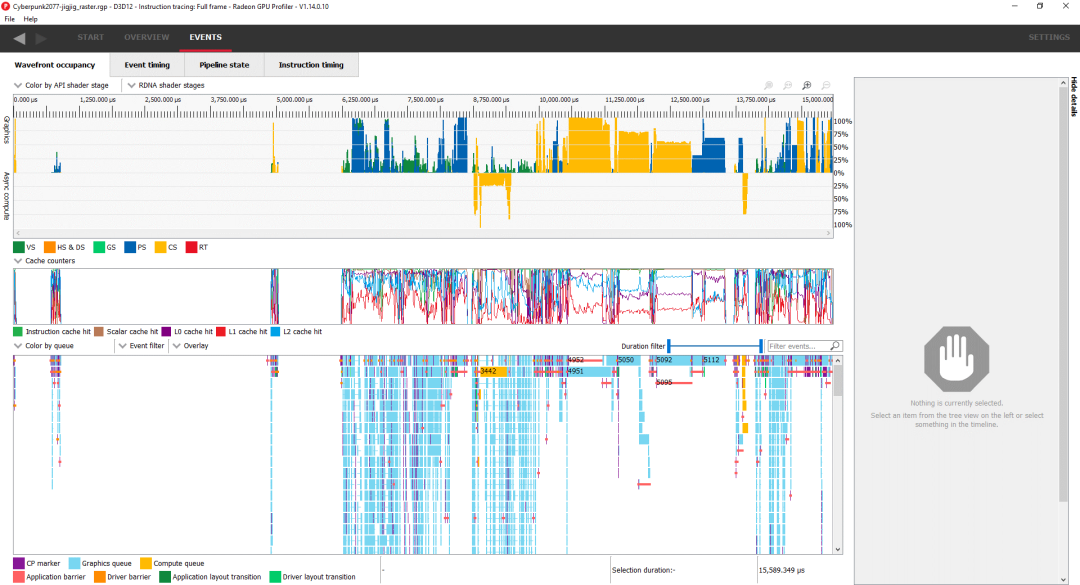
開頭附近的大量空白區域沒有 GPU 活動表明我們受 CPU 限制
如果沒有光線追蹤,傳統的頂點和像素著色器就會介入并發揮更大的作用。然而,該游戲仍然大量使用計算著色器,并且異步計算也出現了。三個持續時間最長的調用都是計算的,總結如下:
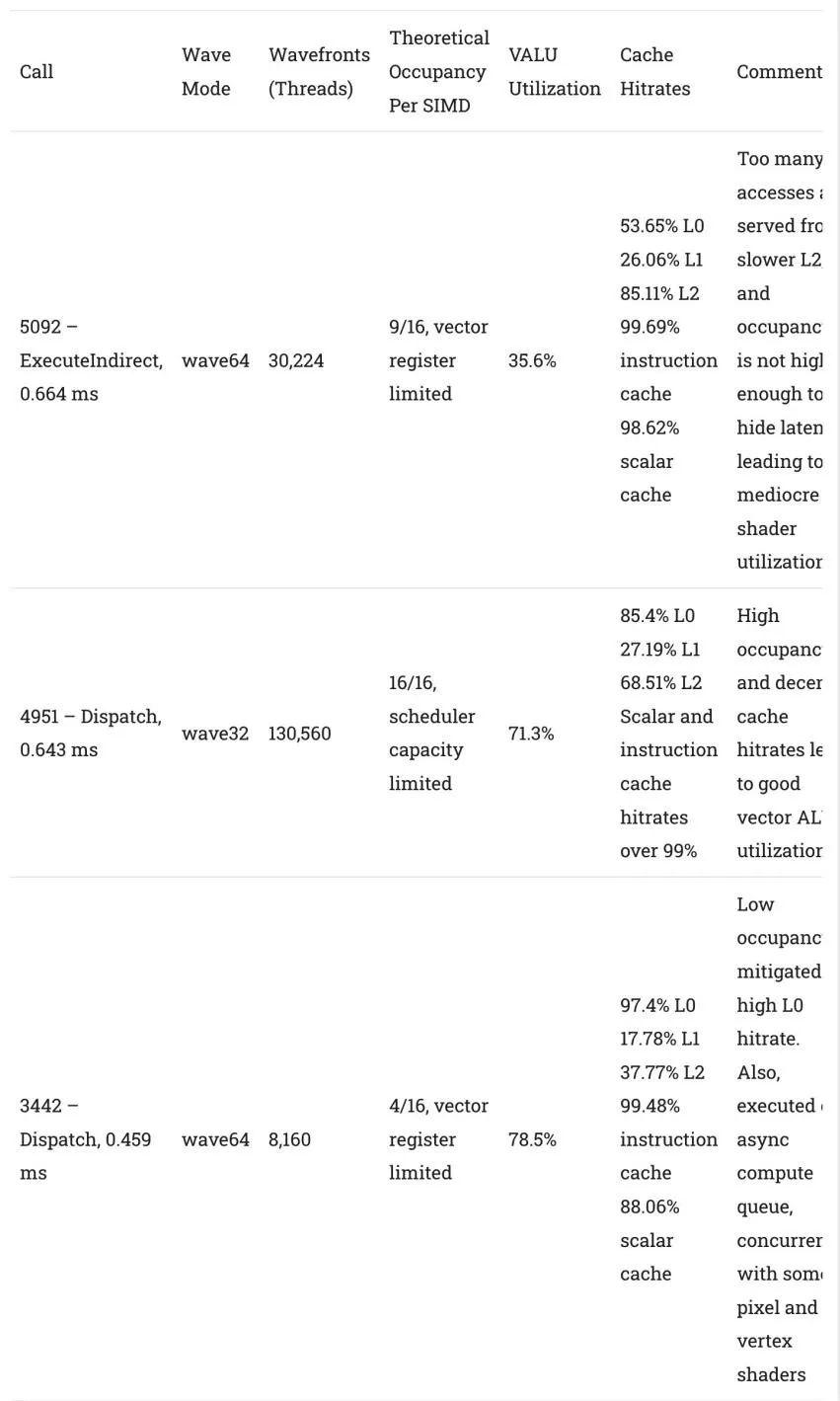
比較三個最長的GPU調用,這三個都是計算著色器
RDNA 2在這些計算內核中表現非常好,即使對于運行時間最長的內核來說,利用率處于較低的水平。矢量寄存器文件容量繼續限制架構可以利用的并行性,但這個問題并不是AMD獨有的。在緩存方面,128 KB L1通常表現不佳。我們看到256 KB的中級緩存對于cpu來說已經很普通了。GPU緩存就更難了。一次又一次,RDNA 2的L1錯過的比命中的多。我很高興AMD選擇在RDNA 3中增加L1緩存容量。好的一面是,標量緩存和指令緩存的命中率繼續保持良好。
光柵化
與光線追蹤不同,傳統的柵格化管道非常高效。光柵化可以使用簡單的計算將3D點映射到2D屏幕空間,而不是到處發送光線并觀察它們擊中了什么。然后,GPU使用固定功能硬件將工作分配到像素著色器,這些著色器決定這些像素應該是什么顏色。像以前一樣,讓我們看看CP2077中幾個最長的柵格化調用。
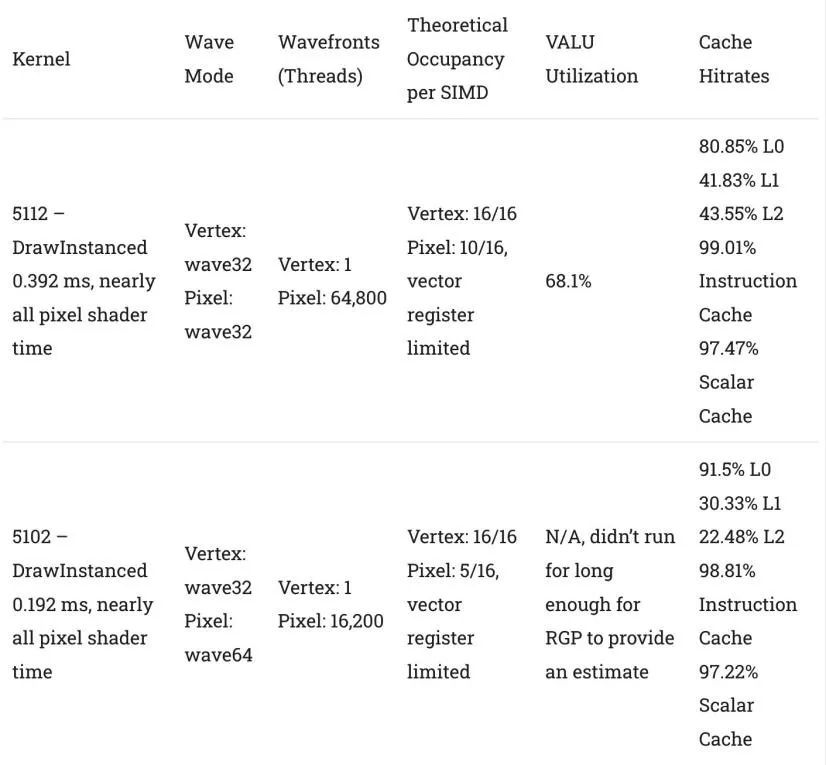
通過柵格化工作,L1緩存的顯示更加可信。hitrate仍然不是很好,但在某些情況下,它可以捕捉到足夠多的L0錯誤,以確保絕大多數請求不需要從L2或更高的地方得到滿足。這可能是一個很大的優勢,因為L1的延遲和帶寬特性比L2要好得多。
還有一組頂點著色器工作靠近幀的開始。這很難分析,因為有大量的微小呼叫,但窺探一些顯示,它們通常每次發射不到100個波陣面。從我們的延遲和帶寬縮放測試來看,RDNA 2在低占用率的情況下表現非常出色,可能比英偉達的Ampere更好地應對這些呼叫。
泰坦尼克榮譽與榮耀,Megademo 401(光柵化,4K)
擁有數百萬美元預算的大型工作室能夠制作出具有深刻故事情節和令人印象深刻的視覺效果的復雜游戲。但他們并沒有壟斷樂趣,獨立創作者用較小的預算也可以創造出沉浸式和視覺上令人驚嘆的東西。其中一個例子就是正在進行中的《泰坦尼克號榮譽與榮耀》項目,該項目專注于用3D技術重現泰坦尼克號。它使用虛幻引擎,并使用DirectX 12運行。
與許多獨立游戲一樣,開發者花在優化上的時間和資源較少。但也許是因為它還沒有經過優化,演示文稿的細節水平令人驚嘆,即使在現代GPU上也非常沉重。
在這里,我們俯視頭等艙休息室,游戲以 4K 分辨率運行,GPU/CPU 時鐘設置如前。像素著色器主導此工作負載,但計算著色器也發揮作用。異步計算使用率極低,幾乎所有調用都發生在圖形隊列上。
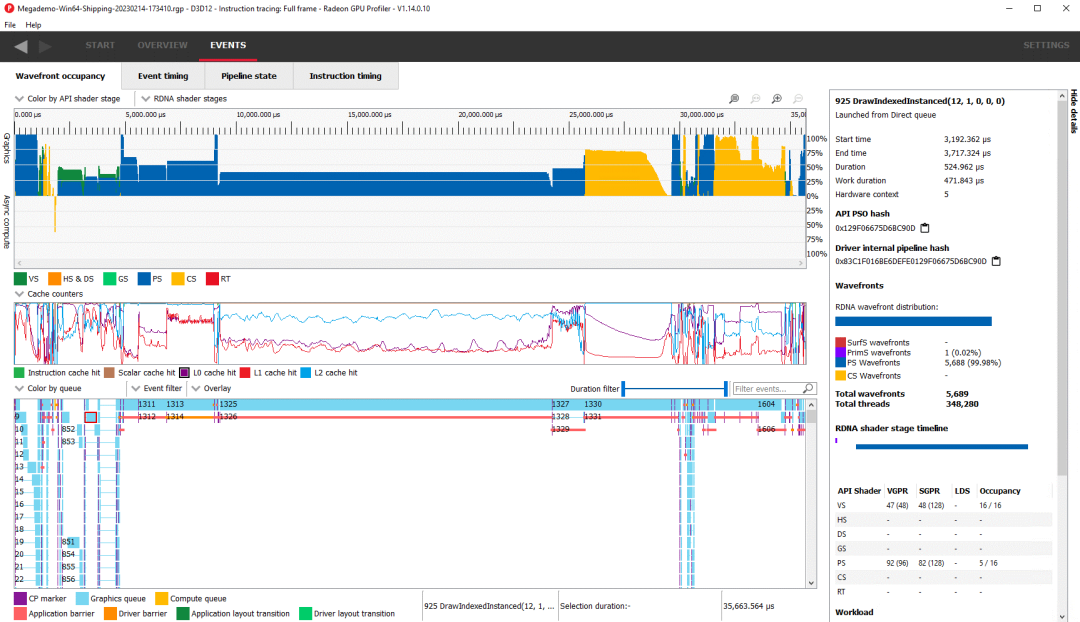
最長的調用是事件 1325,一個以 wave64 模式運行的像素著色器。它發射了 129,652 個波前,或足以覆蓋 4K 分辨率下的每個像素的波。由于向量寄存器文件的限制,占用率很低。向量 ALU 的利用率也很低,這可能是由于占用率低和緩存命中率一般。
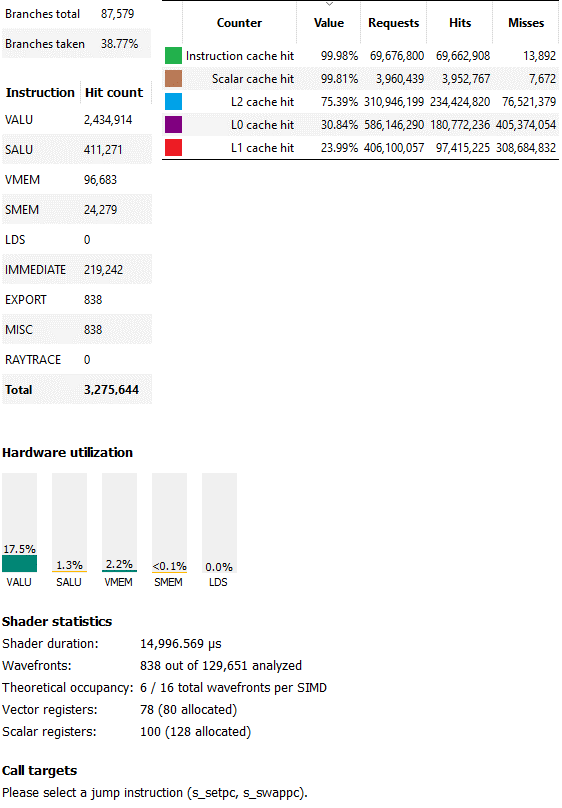
長時間運行的像素著色器的分析器統計信息
事件 1330 是第二長的調用,是一個啟動 16,320 個 wave32 波前的計算著色器。占用率再次受到向量寄存器文件的限制,但這次每個 SIMD 有 12 個波更好。著色器實現了 27.7% 的矢量 ALU 利用率,這是可以接受的,但仍然偏低。L0 命中率還不錯,為 59.69%,而 L1 命中率低得令人尷尬,只有13.11%。幸運的是,二級緩存以 99.82% 的命中率挽救了局面。計算利用率應該真的更好,因為每個 SIMD 12 個 wave 并不是很糟糕的占用率。但仔細觀察就會發現另一個問題。工作在線程之間分布不均,有些線程先于其他線程完成。
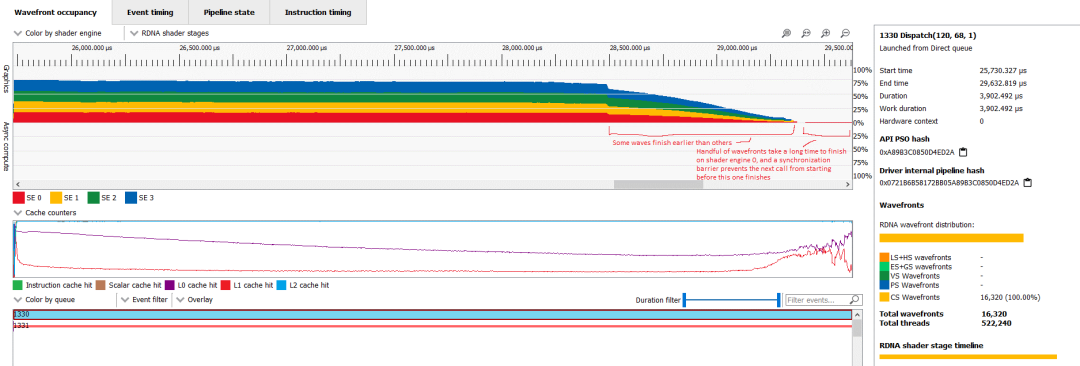
放大該計算著色器,添加注釋并將著色設置為著色器引擎
顯然,下一個調用需要計算著色器寫入的數據,因此同步屏障會阻止它執行,直到計算著色器中的所有線程都完成執行。最后,這意味著許多 6900 XT 的 WGP 處于空閑狀態或沒有足夠的線程級并行性來有效隱藏延遲。這對任何 GPU 來說都不是很好,但 RDNA 2 的高時鐘速度和在低占用率下更好的處理應該讓它比 Nvidia 的 Ampere 更好地應對。
通過 THG,我們可以看到 DirectX12 在光柵化方面的作用。它不像《賽博朋克 2077》那樣進行光線追蹤,但兩種工作負載的緩存行為驚人地相似。
槍手,熱火,PC
Gunner, HEAT, PC (GHPC) 是坦克模擬獨立游戲。它旨在準確描繪冷戰后期坦克上的火控系統和傳感器,同時比 DCS 之類的東西更容易獲得。與 THG 演示不同,GHPC 使用 Unity 引擎并運行 DirectX 11。不幸的是,AMD 的分析器不支持 DirectX 11。我使用 PIX 來分析游戲。但這一直很煩人,因為 PIX 有一個令人討厭的習慣,即它自己和它試圖分析的游戲都會崩潰。
GHPC 絕大多數使用傳統的像素和頂點著色器。我在 4K 下運行游戲,所以毫不奇怪,有很多像素著色器工作。使用計算著色器。但與上面的 DirectX 12 工作負載不同,它們所起的作用非常小。
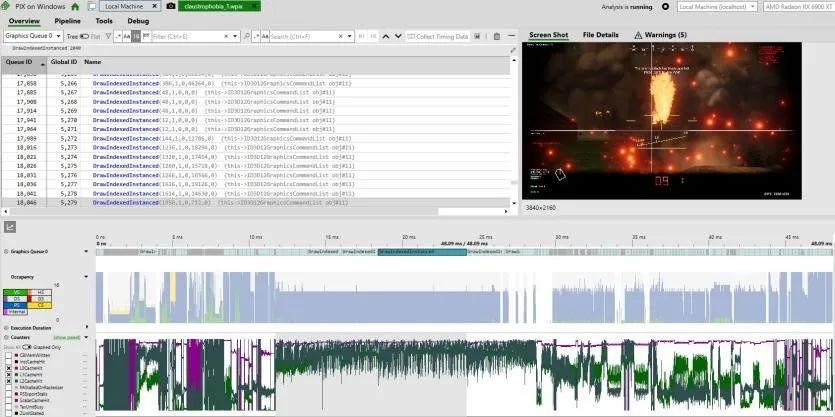
GHPC 運行時間最長的像素著色器比 THG 的緩存友好得多。我們看到超過 90% 的 L0 命中率。L1 命中率最終在 70-80% 之間非常出色,L2 命中率在 90% 以上和 60% 左右之間波動。標量和指令緩存命中率基本上是 100%。不幸的是,PIX 沒有顯示有關執行單元利用率的指標,但我希望它非常好。那是因為游戲往往會使卡產生大量熱量,即使在低于標準時鐘速度時也是如此。幸運的是,PIX 確實公開了比 RGP 多得多的計數器,因此我們可以研究光柵化管道的其他方面。
長時間運行的像素著色器受計算限制,似乎要處理繪制煙霧效果。框架早期的調用主要處理繪圖對象,如房屋和道路。因為這些調用很短,而且經常相互重疊,所以我們看到一些光柵化瓶頸出現了。“PAStalledOnRasterizer”意味著圖元組裝器生成圖元的速度快于光柵化器處理它們的速度。這可能表明光柵化器或之后的任何地方存在瓶頸。
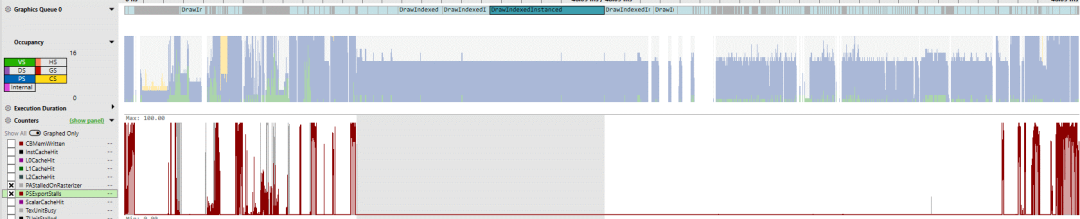
PAStalledOnRasterizer 為灰色,PSExportStalls 為紅色
另一個指標是“PSExportStalls”,它表示像素著色器程序何時計算了顏色信息,但光柵化管道中的最后階段還沒有準備好接受數據。罪魁禍首之一是Z單元,它進行深度測試以確保只顯示未被遮擋的像素。例如,如果坦克的一半位于房屋后面,則 Z 單元部分將確保房屋的像素顯示在最終幀中。如果來自許多不同對象的大量像素必須經過這種深度測試,Z 單元可能很難跟上。
但回過頭來看,最大的性能罪魁禍首肯定是煙霧和陰霾效果。繪制這些效果占用的 GPU 時間最多,并且像素著色器操作非常繁重。在這些著色器期間,紋理單元幾乎一直處于活動狀態,因此也可能存在紋理瓶頸。
緩存評論
長期以來,GPU緩存一直落后于 CPU 緩存。在 2000 年代初期,GPU 沒有通用緩存層次結構。他們確實有專門的緩沖區,但在大多數情況下,他們依賴于顯式并行和高帶寬內存設置。到 2000 年代后期,內存帶寬限制促使 GPU 采用緩存。這些往往比 CPU 緩存小得多,兩級緩存設置是常態。CPU 大約在那個時候轉向三級設置,以便通過高核心數和大型共享緩存保持性能。

曾幾何時,在 Geforce 4 時代,GPU 緩存是不切實際的。哦,時代變了……
RDNA 2 通過采用比我們在大多數 CPU 上看到的更復雜和更高容量的緩存層次結構來扭轉一切。它使用令人難以置信的四級緩存,最后一級緩存有 128 MB 的容量。相比之下,即使是 AMD 的 VCache CPU 也只有 96 MB 的末級緩存,并且使用三級緩存設置。
就像 CPU 一樣,DRAM 技術也在努力跟上 GPU 性能的提升。但與 CPU 不同的是,GPU 對延遲不太敏感,這使得這種緩存設置變得實用(延遲似乎是 L4 緩存不受 CPU 歡迎的主要原因)。很高興看到 GPU 全面發展并比 CPU 更頻繁地使用緩存。
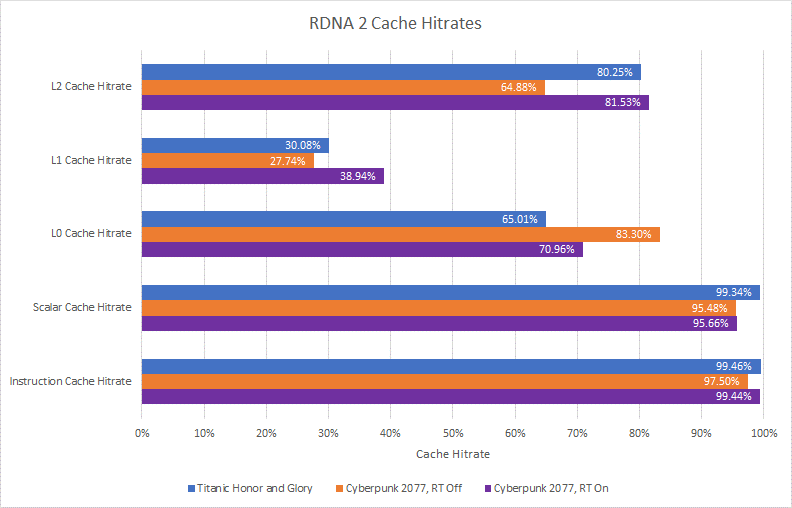
整體命中率,對于整個幀的所有訪問
但是更復雜的緩存設置不一定好。更多級別的緩存意味著您可能會檢查更多標簽的命中。如果緩存級別沒有捕獲大量內存訪問,它最終可能會延遲對數據最終來自何處的訪問。因此,RDNA 2 的 L1 緩存令人失望,與其他緩存級別相比命中率較低。它要么需要變得更大,要么應該放棄以支持更大的 L0 緩存。
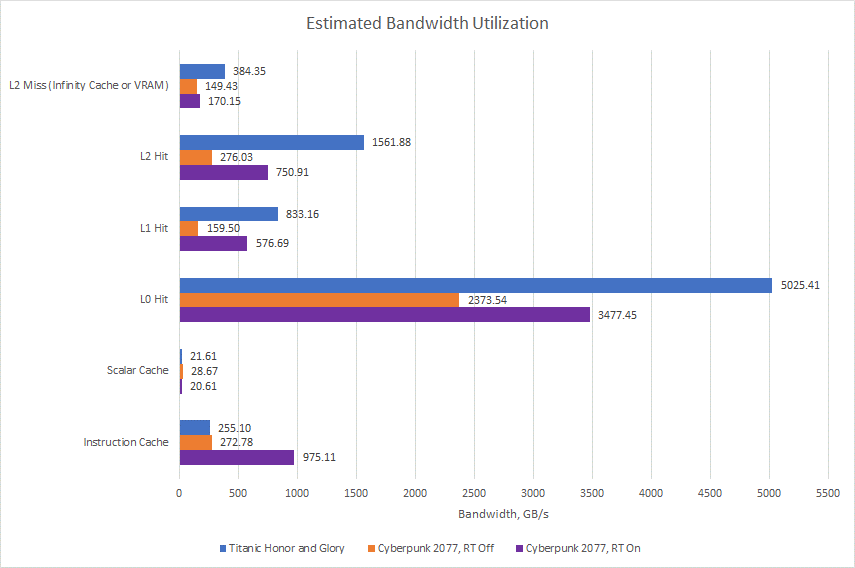
假設每個標量緩存訪問都獲得一個 64 位值。讓我們暫停片刻,欣賞 GPU 緩存必須處理的海量數據。
緩存還有助于提高帶寬,這對 GPU 來說更為重要。L1 緩存確實減少了進入 L2 的流量,但我懷疑 L2 是否需要這種幫助。AMD 的 RX 6900 XT 已經擁有大量的 L2 帶寬,甚至與 Nvidia 更大的 RTX 3090 相比也是如此。因此,L1 最終僅用于整合來自多個 WGP 的請求,從而簡化了 L2 路由。
縮小范圍,我們可以查看請求計數,乘以請求大小,然后乘以實現的幀率,以估計 GPU 從其緩存中提取了多少數據。L0 緩存每秒提供數 TB 的數據,如果我以標準時鐘運行我的 6900 XT 而不是將其限制在 1800 MHz,這個數字會更高。即使在 L2,我們也看到超過 1.5 TB/s 的帶寬需求。沒有數兆字節緩存的現代 GPU 將非常缺乏帶寬,即使我們為它提供像 Nvidia A100 上那樣的六堆棧 HBM2E 設置。
游戲趨勢
從我看過的一小部分游戲來看,計算似乎正在發揮更大的作用。計算著色器在 Cyberpunk 2077 中尤為突出,這是一款以大量預算開發的現代 AAA 游戲。我將光線追蹤視為一種計算形式。RDNA 2 將光線追蹤視為計算。我不確定 Nvidia 做了什么,但 Pascal 使用計算著色器處理光線追蹤。即使沒有光線追蹤,賽博朋克也會在傳統光柵化的同時使用大量計算。
預算較小的獨立游戲往往更強調光柵化管道,但仍會利用計算。他們這樣做的程度可能在很大程度上取決于游戲引擎,因為獨立開發者通常沒有時間從頭開始創建自己的游戲引擎。Titanic Honor and Glory 使用的 Unreal Engine 具有大量計算能力。GHPC 使用 Unity 引擎,計算量很小。雖然傳統的光柵化管道仍然非常重要,但我們可能會看到它越來越多地在新游戲中得到計算的補充。
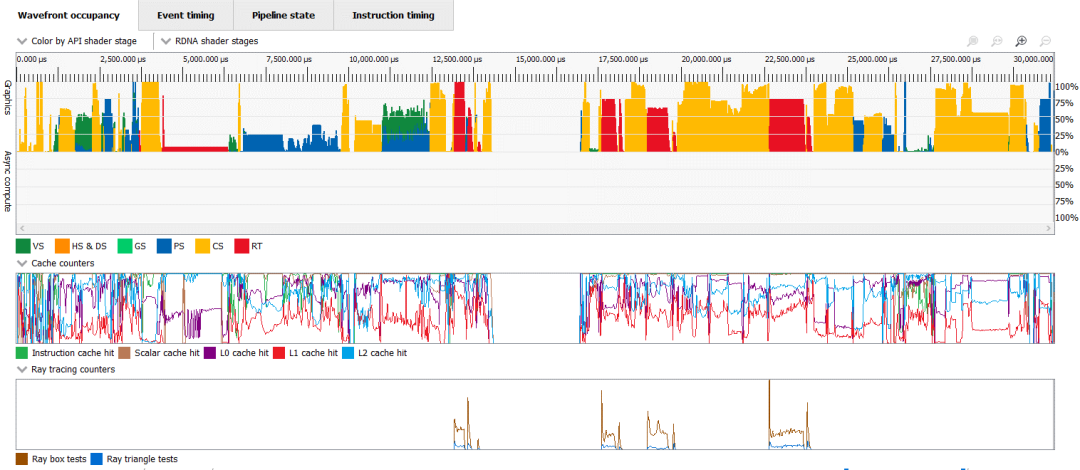
對虛幻引擎的城市演示中的幀進行分析,顯示大量使用計算和光線追蹤
因此,現代視頻卡需要具有良好的計算能力,而 RDNA 2 不會讓人失望。它可能沒有 Nvidia 的 Ampere 架構的大量 FP32 吞吐量,但它處于更好地利用其現有執行單元的有利位置。
結論
RDNA 2 對 AMD 來說是一個重要時刻。在過去十年左右的時間里,Nvidia 普遍主導著高性能 GPU 市場。AMD(和 ATI)偶爾會生產出可以與 Nvidia 的最佳產品正面交鋒的顯卡,但這種情況似乎永遠不會持續很長時間。基于 RDNA 2 的 RX 6900 XT 就是其中之一,其重要性與基于 Terascale 2 的 HD 5800 相同。Terascale 2 提供了 Nvidia Fermi 卡的大部分性能,但功耗要低得多。同樣,RDNA 2 提供了 Ampere 的大部分性能,但電源效率更高。至少部分原因在于 RDNA 2 對緩存的使用,而不是大型 GDDR6X 設置。因此,RDNA 2 代表了 GPU 緩存策略的轉折點。
該緩存設置以另一種方式使 RDNA 2 具有重要意義。它代表了 GPU 緩存策略向優先考慮一般計算性能的轉折點。濫發更多的著色器,然后構建一個巨大的 VRAM 子系統來提供它的日子似乎已經一去不復返了。這同樣適用于基于圖塊的渲染,它試圖通過優化光柵化順序來優化緩存占用空間。隨著計算變得越來越重要,基于光柵化的技巧開始產生較小的影響。與 CPU 一樣,答案似乎是更多緩存。AMD的下一代GPU架構,RDNA 3采用了類似的四級緩存子系統。Nvidia 同樣正在擺脫對巨大 VRAM 配置的依賴。Ada Lovelace大大增加了 L2 緩存容量,RTX 4090 獲得了 72 MB 的 L2。即使更大的 GDDR6X 設置或 HBM 可以提供足夠的帶寬來僅使用 4 MB 或 6 MB 的緩存,這樣的解決方案也會太耗電或太昂貴。
RDNA 2 還為 AMD 的 GPU 陣容帶來了硬件光線追蹤加速。與 Nvidia 的全力以赴的方法相反,AMD 可能試圖以最低的硬件成本獲得可接受的性能。我認為這是一個明智之舉,因為常規計算和光柵化仍然主導著很多工作負載,并且絕對不需要光線追蹤來產生良好的視覺效果。此外,即使 GPU 功率和裸片面積達到極限,未來的光線追蹤工作負載也不太可能通過當今的技術實現。那是因為我們離使用純光線追蹤渲染 AAA 標題還差得很遠,即使是有限的光線追蹤效果也會帶來如此大的性能損失,以至于 Nvidia 和 AMD 求助于使用升級技術。
但重要的是,RDNA 2 的光線追蹤實現為 AMD 提供了一些可以構建的東西。緩存設置也是如此。在為未來的成功奠定基礎方面,RDNA 2 幾乎與 RDNA 1 相似。
審核編輯 :李倩
-
amd
+關注
關注
25文章
5468瀏覽量
134169 -
gpu
+關注
關注
28文章
4740瀏覽量
128951 -
光線追蹤
+關注
關注
0文章
183瀏覽量
21479
原文標題:AMD RDNA2 GPU架構詳解
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論