") PyTorch入門-1
PyTorch入門-1
1.為什么選擇PyTorch
1)簡潔:追求更少封裝,避免重復(fù)造輪子
2)速度:靈活性不以速度為代價
3)易用:語法優(yōu)雅,簡單易學(xué)
4)資源:社區(qū)豐富,維護(hù)及時
2.基礎(chǔ)入門
1)安裝(pip install torch)
2)創(chuàng)建tensor(PyTorch重要的數(shù)據(jù)結(jié)構(gòu))
3)自動求導(dǎo)
import numpy as np
import torch
#創(chuàng)建3行4列tensor,設(shè)置自動求導(dǎo)
x = torch.randn(3,4,requires_grad=True)
#輸出結(jié)構(gòu)
x

#初始化b
b = torch.randn(3,4,requires_grad=True)
#計算t
t = x + b
#求和
y = t.sum()
#反向傳播計算
y.backward()
#輸出b梯度
b.grad

實戰(zhàn)一個例子(計算過程如下):
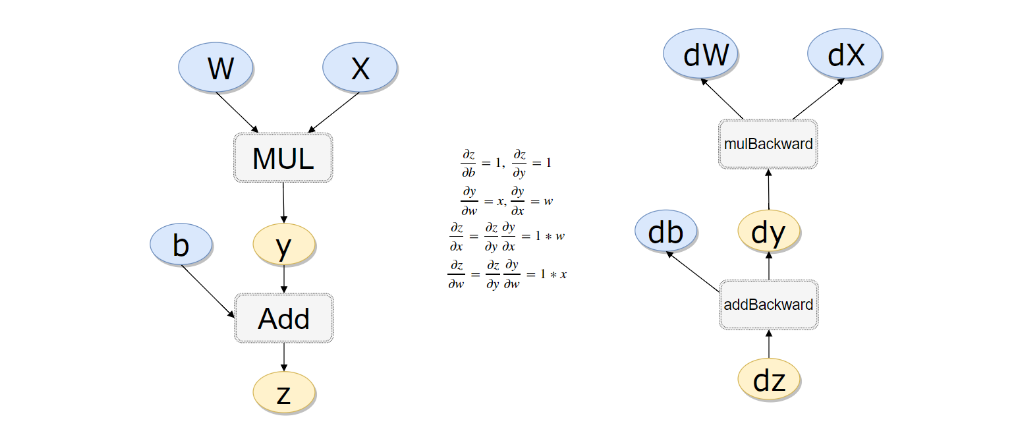
#計算流程
x = torch.rand(1)
b = torch.rand(1, requires_grad = True)
w = torch.rand(1, requires_grad = True)
y = w * x
z = y + b
#如果不清空會累加起來
z.backward(retain_graph=True)
#w梯度
w.grad

#b梯度
b.grad

3.搭建線性回歸模型
1)構(gòu)造數(shù)據(jù)
2)初始化參數(shù)
3)前向傳播
4)模型訓(xùn)練
5)預(yù)測結(jié)果
6)保存模型
#初始化x值
x_values = [i for i in range(11)]
#轉(zhuǎn)換為ndarray
x_train = np.array(x_values, dtype=np.float32)
#維度轉(zhuǎn)換
x_train = x_train.reshape(-1, 1)
#查看形狀,(11,1)
x_train.shape
#計算y值
y_values = [2*i + 1 for i in x_values]
#轉(zhuǎn)換為ndarray
y_train = np.array(y_values, dtype=np.float32)
#維度轉(zhuǎn)換
y_train = y_train.reshape(-1, 1)
#查看形狀,(11,1)
y_train.shape
import torch
import torch.nn as nn
#線性回歸模型(本質(zhì)是一個不加激活函數(shù)的全連接層)
class LinearRegressionModel(nn.Module):
#初始化參數(shù)
def __init__(self, input_dim, output_dim):
super(LinearRegressionModel, self).__init__()
self.linear = nn.Linear(input_dim, output_dim)
#前向傳播
def forward(self, x):
out = self.linear(x)
return out
#輸入維度
input_dim = 1
#輸出維度
output_dim = 1
#初始化模型
model = LinearRegressionModel(input_dim, output_dim)
#輪數(shù)
epochs = 1000
#學(xué)習(xí)率
learning_rate = 0.01
#隨機(jī)梯度下降算法
optimizer = torch.optim.SGD(model.parameters(),
lr=learning_rate)
#定義均方損失函數(shù)
criterion = nn.MSELoss()
#遍歷每一輪(這里使用CPU進(jìn)行訓(xùn)練,建議使用GPU速度快)
for epoch in range(epochs):
#計算輪數(shù)
epoch += 1
#注意轉(zhuǎn)換成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
#梯度要清零每一次迭代
optimizer.zero_grad()
#前向傳播
outputs = model(inputs)
#計算損失
loss = criterion(outputs, labels)
#返向傳播
loss.backward()
#更新權(quán)重參數(shù)
optimizer.step()
#每50輪輸出損失值
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))

#預(yù)測訓(xùn)練數(shù)據(jù)集
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
#輸出結(jié)果,跟我們真實y值幾乎沒有差別
predicted

#保存模型
torch.save(model.state_dict(), 'model.pkl')
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
速度
+關(guān)注
關(guān)注
1文章
33瀏覽量
15599 -
資源
+關(guān)注
關(guān)注
0文章
59瀏覽量
17785 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13225
發(fā)布評論請先 登錄
相關(guān)推薦
如何往星光2板子里裝pytorch?
如題,想先gpu版本的pytorch只安裝cpu版本的pytorch,pytorch官網(wǎng)提供了基于conda和pip兩種安裝方式。因為咱是risc架構(gòu)沒對應(yīng)的conda,而使用pip安裝提示也沒有
發(fā)表于 09-12 06:30
Pytorch入門教程與范例
的深度學(xué)習(xí)框架。 對于系統(tǒng)學(xué)習(xí) pytorch,官方提供了非常好的入門教程?,同時還提供了面向深度學(xué)習(xí)的示例,同時熱心網(wǎng)友分享了更簡潔的示例。 1. overview 不同于 theano
發(fā)表于 11-15 17:50
?5413次閱讀
PyTorch官網(wǎng)教程PyTorch深度學(xué)習(xí):60分鐘快速入門中文翻譯版
“PyTorch 深度學(xué)習(xí):60分鐘快速入門”為 PyTorch 官網(wǎng)教程,網(wǎng)上已經(jīng)有部分翻譯作品,隨著PyTorch1.0 版本的公布,這個教程有較大的代碼改動,本人對教程進(jìn)行重新翻
基于PyTorch的深度學(xué)習(xí)入門教程之PyTorch的安裝和配置
神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),并且運用各種深度學(xué)習(xí)算法訓(xùn)練網(wǎng)絡(luò)參數(shù),進(jìn)而解決各種任務(wù)。 本文從PyTorch環(huán)境配置開始。PyTorch是一種Python接口的深度學(xué)習(xí)框架,使用靈活,學(xué)習(xí)方便。還有其他主流的深度學(xué)習(xí)框架,例如Caffe,TensorFlow,CNTK等等,各有千秋。筆者
基于PyTorch的深度學(xué)習(xí)入門教程之PyTorch簡單知識
本文參考PyTorch官網(wǎng)的教程,分為五個基本模塊來介紹PyTorch。為了避免文章過長,這五個模塊分別在五篇博文中介紹。 Part1:PyTorch簡單知識 Part2:
基于PyTorch的深度學(xué)習(xí)入門教程之PyTorch的自動梯度計算
本文參考PyTorch官網(wǎng)的教程,分為五個基本模塊來介紹PyTorch。為了避免文章過長,這五個模塊分別在五篇博文中介紹。 Part1:PyTorch簡單知識 Part2:
基于PyTorch的深度學(xué)習(xí)入門教程之使用PyTorch構(gòu)建一個神經(jīng)網(wǎng)絡(luò)
? ? ? ? 前言 本文參考PyTorch官網(wǎng)的教程,分為五個基本模塊來介紹PyTorch。為了避免文章過長,這五個模塊分別在五篇博文中介紹。 Part1:PyTorch簡單知識 P
基于PyTorch的深度學(xué)習(xí)入門教程之DataParallel使用多GPU
前言 本文參考PyTorch官網(wǎng)的教程,分為五個基本模塊來介紹PyTorch。為了避免文章過長,這五個模塊分別在五篇博文中介紹。 Part1:PyTorch簡單知識 Part2:
基于PyTorch的深度學(xué)習(xí)入門教程之PyTorch重點綜合實踐
前言 PyTorch提供了兩個主要特性: (1) 一個n維的Tensor,與numpy相似但是支持GPU運算。 (2) 搭建和訓(xùn)練神經(jīng)網(wǎng)絡(luò)的自動微分功能。 我們將會使用一個全連接的ReLU網(wǎng)絡(luò)作為
深度學(xué)習(xí)框架pytorch入門與實踐
深度學(xué)習(xí)框架pytorch入門與實踐 深度學(xué)習(xí)是機(jī)器學(xué)習(xí)中的一個分支,它使用多層神經(jīng)網(wǎng)絡(luò)對大量數(shù)據(jù)進(jìn)行學(xué)習(xí),以實現(xiàn)人工智能的目標(biāo)。在實現(xiàn)深度學(xué)習(xí)的過程中,選擇一個適用的開發(fā)框架是非常關(guān)鍵





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論