 基于Python的簡便易用的數據接口
基于Python的簡便易用的數據接口
數據從哪里來呢?我們可以通過網絡爬蟲來爬取數據,但是這個還是需要耗費一定時間的。
這時候就會有朋友說了,有沒有現成的數據呢?當然有了,今天就給大家分享一個基于 Python 的、簡便易用的數據接口,可能包含我們想要的各種各樣的數據。
簡介
這個庫的名字叫 GoPUP,GitHub 主頁是:https://github.com/justinzm/gopup
這其實是一個基于公開 API 的數據接口庫,這個庫封裝了各種各樣的方法,比如通過 wx_hot_list 這個方法我們就可以獲取實時的微信熱門文章榜單。
基本使用
下面我們來簡單介紹下它的使用方法,首先是安裝,使用 pip3 即可:
pip3installgopup
因為這個庫會不斷升級,如果要升級的話大家可以運行如下命令:
pip3install-Ugopup
安裝完畢之后就可以開始使用了,其實使用起來還是非常簡單的。
比如這里我們以「微博指數」為例來說明下用法,官方文檔見 http://doc.gopup.cn/#/data/index_data?id=微博指數數據
-
接口: weibo_index
-
目標地址: https://data.weibo.com/index/newindex
-
描述: 獲取指定 詞語 的微博指數
-
輸入參數
| 名稱 | 類型 | 必須 | 描述 |
|---|---|---|---|
| word | str | Y | 關鍵詞 |
| time_type | str | Y | time_type="1hour"; 1hour, 1day, 1month, 3month 選其一. |
- 輸出參數
| 名稱 | 類型 | 默認顯示 | 描述 |
|---|---|---|---|
| date | datetime | Y | 日期-索引 |
| index | float | Y | 指數 |
大家可以看到,這個接口的目標地址實際上就是一個公開 API,然后我們只需要輸入對應的詞語和時間段,就可以輸出對應的指數結果。
接口用法如下:
importgopupasgp
df_index=gp.weibo_index(word="疫情",time_type="3month")
print(df_index)
這里我們先導入了 gopup 庫,然后調用了它的 weibo_index 方法,傳入關鍵詞和時間段,這里我們查詢的是最近三個月的疫情對應的微博指數,也就對應這個詞在微博的熱度。
運行結果如下:
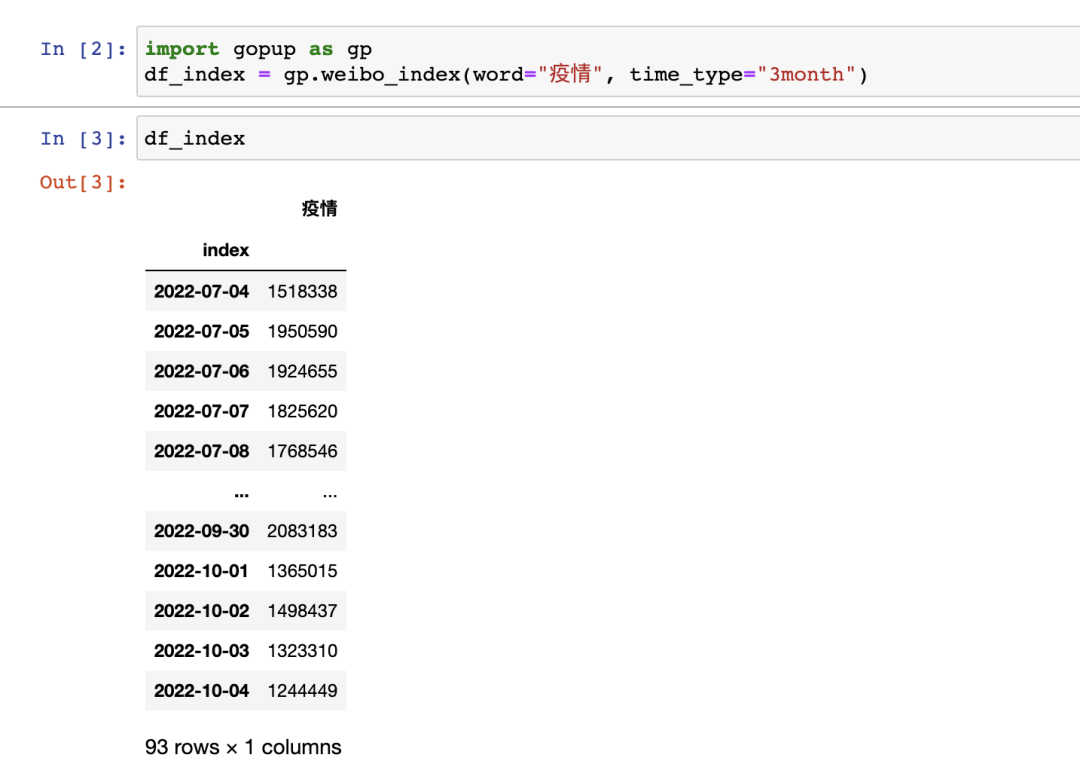
疫情
index
2022-07-041518338
2022-07-051950590
2022-07-061924655
2022-07-071825620
2022-07-081768546
......
2022-09-302083183
2022-10-011365015
2022-10-021498437
2022-10-031323310
2022-10-041244449
[93rowsx1columns]
可以看到輸出的實際上是 Pandas 的 DataFrame 數據結構,如果我們用 Jupyter 運行的話可能更直觀一些。
安裝并運行 Jupyter
pip3installjupyter
jupyternotebook
運行類似的代碼,結果如下:
我們還可以進一步將其轉化為可視化圖表:
importmatplotlib.pyplotasplt
plt.figure(figsize=(15,5))
plt.title("微博「疫情」熱度走勢圖")
plt.xlabel("時間")
plt.ylabel("指數")
plt.plot(df_index.index,df_index['疫情'],'-',label="指數")
plt.legend()
plt.grid()
plt.show()
結果如下:
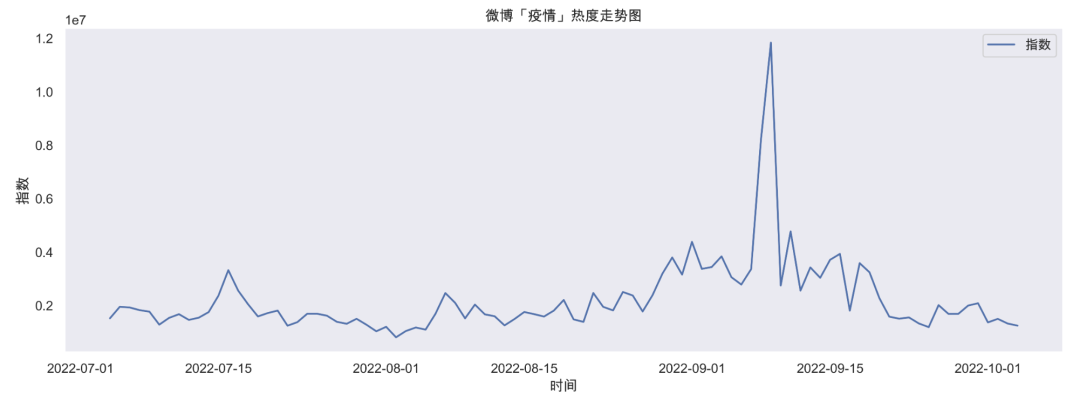
這樣通過簡單的幾行代碼我們就可以輕松將某個詞的熱度走勢可視化出來了,繪制成折線圖之后,熱度走勢一目了然。
更多數據
當然上面僅僅是冰山一角,GoPUP 集成了各種公開 API,就像個爬蟲一樣給各種 API 提供了封裝,數據可謂是應有盡有。
根據 GoPUP 的簡介,這里面的數據包括這些類別:
-
指數數據:微博指數數據,百度指數數據,百度搜索數據,百度資訊指數,百度媒體指數,百度需求圖譜,百度人群畫像年齡分布,百度人群畫像性別分布,百度人群畫像興趣分布;
-
算數數據:算數指數數據,算數相關性分析,算數地域分析,算數城市分析,算數年齡分析,算數性別分析,算數用戶閱讀興趣分類,谷歌指數數據,谷歌指數數據,谷歌事實查證;
-
宏觀數據:中國宏觀數據,中國宏觀杠桿率數據,貨幣匯率數據;
-
利率數據:Shibor數據,Shibor報價數據,Shibor均值數據,LPR數據;
-
公司數據:千里馬公司,獨角獸公司,倒閉公司,商業特許經營公司;
-
信息數據:新聞聯播文字稿;
-
生活數據:中國油價數據,汽柴油歷史調價信息,調價日的地區油價歷史數據;
-
詩詞數據:唐代詩人,唐詩數據;
-
影視數據:實時電影票房數據,單日電影票房數據,單日影院票房數據,實時電視劇播映指數,實時綜藝播映指數,藝人商業價值,藝人流量價值;
-
全國高校數據:全國普通高等學校名單,全國成人高等學校名單,全國高等學校詳情數據;
-
疫情數據:網易疫情數據,丁香園疫情數據……
當然這個庫也在不斷更新,更多詳細的內容大家可以到官方文檔了解下:http://doc.gopup.cn/#/README
有了這些數據,我們做數據分析和可視化就不用再去寫爬蟲啦,直接拿來用就好了,簡直不要太方便!
好了,關于 GoPUP 就介紹這么多了,大家可以來試試看吧
審核編輯 :李倩
-
API
+關注
關注
2文章
1501瀏覽量
62017 -
數據分析
+關注
關注
2文章
1449瀏覽量
34059 -
爬蟲
+關注
關注
0文章
82瀏覽量
6880
原文標題:有了這個庫,這些爬蟲都不用親自寫了!
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
專業python web編程工具
三種提高Python代碼性能的簡便方法
TekVPITM新型探頭接口提供了杰出的通用性和簡便易用性
SPB TV:面向iPhone最簡便易用的移動電視應用
Python的幾個自然語言處理工具介紹
python串口接收數據

Python編程用于數據科學和機器學習
Danfo.js提供高性能、直觀易用的數據結構,支持結構化數據的操作和處理
詳談Python的數據模型和對象模型





 工商網監
工商網監
評論