 “中國的ChatGPT”真的要來了嗎?
“中國的ChatGPT”真的要來了嗎?
席卷全球的新風口
OpenAI去年發布了聊天機器人模型ChatGPT,它能夠理解和生成人類語言,并在許多自然語言處理任務中表現非常出色。據統計,上線僅兩個月,ChatGPT活躍用戶已經超億,打破了由TikTok創造的9個月實現億級用戶注冊的紀錄,引起了各行各業人們的強烈關注。就連埃隆·馬斯克也忍不住發推表示,ChatGPT厲害得嚇人,我們距離危險而強大的AI不遠了。當然,在一頓痛批ChatGPT之后,馬斯克也準備親自下場,成立研究實驗室,開發ChatGPT的競品。
類ChatGPT模型的開發與應用,在國內也迅速成為資本市場關注、創業者紛紛入場的賽道。阿里、百度等互聯網大廠,科大訊飛等語音類AI企業,以及眾多創業者都希望乘著最新的風口迅速“起飛”。創業者大軍中不乏像前美團聯合創始人王慧文、出門問問CEO李志飛、搜狗前CEO王小川、前京東技術掌門人周伯文等行業大佬。開發出“中國的ChatGPT”儼然成了國內科技圈“All in”的方向。
然而,我們真的能迅速見到一個“中國的ChatGPT”嗎?誰又能拔下頭籌,成為這個細分賽道的領頭羊呢?
這個眾多大佬都擠進來“淘金”的賽道,一定不是簡簡單單就能搞定的。
OpenAI的GPT“家族”
在深入了解開發出比肩ChatGPT的模型需要面臨哪些挑戰之前,讓我們先看下ChatGPT所屬的GPT模型家族都有哪些成員。
GPT-1發布于2018年6月,包含117M個參數。這是第一個采用基于Transformer的模型架構進行預訓練的模型。它在語言模型和單詞類比任務上表現出色。
GPT-2發布于2019年2月,包含1.5B個參數。這個模型在自然語言生成任務上表現出色,可以生成高質量的文章、新聞報道和詩歌等文本。
GPT-3發布于2020年6月,包含175B個參數。具有出色的通用性和創造性,可以在各種 NLP任務上表現出色,包括文本生成、問答、機器翻譯等任務。
到這就結束了?完全不是。
在GPT-3系列模型(注意,是一系列模型哦)發布之后,OpenAI繼續基于原始的GPT-3進行了不斷地完善。我們熟知的InstructGPT和ChatGPT實際的內部代號是text-davinci-003 175B和text-chat-davinci-002-20221122,是基于GPT-3.5的改良版。
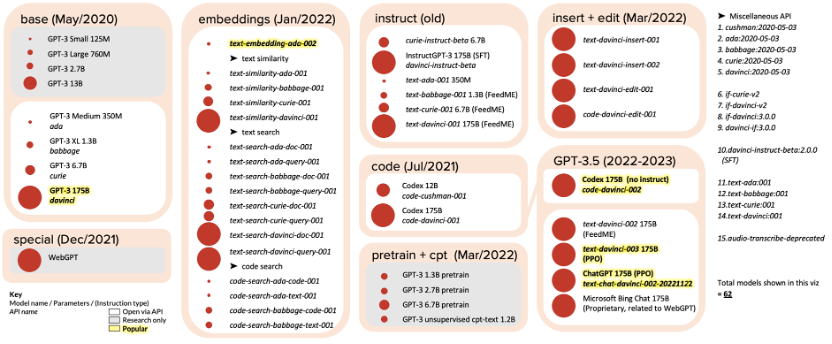
圖:GPT-3模型家族,圖片來源:https://lifearchitect.ai/chatgpt/
在InstructGPT的訓練中,OpenAI的研究員引入了RLHF(Reinforcement Learning from Human Feedback,人類反饋強化學習)機制。這一訓練范式增強了人類對模型輸出結果的調節,并且對結果進行了更具理解性的排序。在此基礎上,ChatGPT還引入了“無害化”機制,防止模型生成不符合規范或倫理的答案。
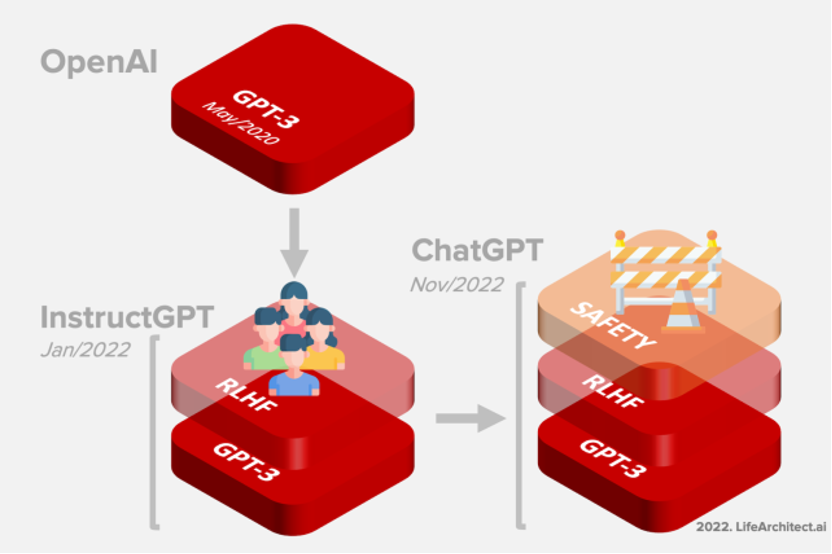
圖:GPT-3、InstructGPT、ChatGPT的“進化路線”
圖片來源:https://lifearchitect.ai/chatgpt/
不難看出,ChatGPT的出圈,與OpenAI多年的技術積累是分不開的。國內廠商想要開發出像ChatGPT一樣優秀的模型,也絕不是簡單依靠拉一波投資,雇一批算法研究員就能馬上實現的。
“中國的ChatGPT”面臨的挑戰
首先,在資金投入方面,在當前的技術水平下,訓練一個與ChatGPT這樣的大型語言模型相當的模型需要數百萬美元的投入。在發布ChatGPT之前,OpenAI可查的融資額已超過20億美元,也是如此龐大的投資才使OpenAI擁有了多年技術積累。反觀絕大多數近期入局的國內企業,即便擁有足夠的資金與人員,也大都很難在短期追上OpenAI的步伐。
我們不禁想問,如果要在國內開發出一個類ChatGPT模型,到底會面臨哪些技術挑戰呢?
為了能了解到最最準確的答案,我們請教了ChatGPT“本人”
1、數據量:需要大量的數據集來進行訓練。這些數據集需要是大規模的、多樣化的、真實的,并且要涵蓋各種不同的語言和語境。這需要花費大量的時間和資源來收集、整理和標注。
2、計算能力:需要非常強大的計算資源。這些模型需要在大規模的數據集上進行訓練,并且需要進行大量的參數優化和調整。這些計算需要高性能的計算機和高效的分布式計算框架。
3、 算法優化:需要對算法進行不斷的優化和改進。這包括優化網絡結構、調整超參數、使用更好的優化算法等。這需要對深度學習算法有深入的了解和經驗。
可以發現,這是一個涉及到多個領域和技術的復雜系統工程。只有同時在底層的基礎設施、針對性優化和大模型技術積淀都達到一定水平的情況下,才能夠研發出高質量的模型,并應用于各種場景中。
讓我們詳細看看這三類技術挑戰具體都意味著什么。
數據量
我們經常聽到“有多少數據,就有多少智能”,數據對于模型訓練的重要性不言而喻。類ChatGPT模型的訓練,更需要超大規模的,經過清洗的數據。以GPT-3的訓練為例,需要300B tokens的數據。大家如果對這個數字不敏感的話,可以參考整個英文的維基百科的數據量,只有“相對可憐”的3B tokens,是訓練GPT-3所需的百分之一。并且,要訓練出類ChatGPT模型,勢必需要數倍于當年訓練GPT-3的數據量的中文語料數據,這對于大部分企業或科研機構來說都是難以翻越的大山。有效的中文數據量,一定程度上決定了模型性能的上限。
計算能力
類ChatGPT模型的訓練,除了需要非常多的訓練數據外,也離不開龐大的算力支撐。根據北京智源人工智能研究院公布的數據,使用300B tokens的數據訓練175B參數規模(與GPT-3規模相同)的模型,如果使用96臺通過200Gb IB網卡互聯的DGX-A100節點,需要約50天。要是使用更大規模的訓練數據集,訓練時長還會進一步增加。
對于計算集群來說,不僅需要能夠提供海量的算力資源,還需要具備高速網絡和高容量存儲,以便支持大規模的數據訪問和模型傳輸。整套基礎設施,連同軟件平臺,還需要結合集群的拓撲結構針對分布式訓練進行優化,通過調整并行策略等方式,提升硬件利用率與通訊效率,縮短整體訓練時間。
算法優化
算法優化和模型的訓練效率和效果息息相關。每一個算法研究員,都希望模型在訓練過程中快速收斂,這恰恰也是算法研究人員經驗與企業長年技術積累的體現。通常情況下,在訓練的過程中需要不斷調整學習率、批量大小、層數等超參數,或使用自動調參的技巧和經驗,才能快速、穩定的實現模型收斂。就像中餐大廚們用“少許、適量”的調料制作美味佳肴一樣,里面包含著的是大廚們幾十年的手藝,不是一朝一夕就能被批量復制的。
前途是光明的,道路是曲折的
想必,這是最適合送給現在想要開發出“中國的ChatGPT”的各路大佬們的一句話了。為規避未來的技術風險,不少廠商、科研機構也開始探索在自研算力服務平臺上訓練的可行性。北京智源人工智能研究院作為國內頂尖的人工智能領域研究機構,早早就探索了使用自研算力服務平臺的可能性。同樣是使用300B tokens的數據訓練175B參數規模的模型,通過曙光提供的算力服務,訓練周期只需29.10天,在節點規模接近的情況下,訓練效率是其他算力平臺的300%。
基于自研算力服務平臺進行訓練,不可避免的會帶來更多的移植與調優工作。曙光智算強大的硬件與算法優化團隊,在集群、并行策略、算子、工具包等方面的優化上與智源開展了深入的合作。首先,為保證程序能夠正常運行,需要完成包括DeepSpeed/Megatron/Colossal-AI/apex等必要組件的適配工作。其次,程序系統順利調度通常也需要調整調整操作系統配置及tcp協議參數等。訓練的優化工作則主要包含以下三個方面:
算子層面:使用算子融合/算子優化等技術,深度挖掘硬件性能,提升硬件使用率;
策略層面:采用模型并行、數據并行、流水線并行、Zero等多級并行策略,實現超大規模訓練;
集群層面:針對硬件的拓撲結構,對分布式訓練通信、并行分組配比等進行定制優化,提升訓練擴展比。
通過一系列的優化方法,最終也證明了我們可以在自研算力服務平臺上,以能夠對標國際水平的效率實現大模型的開發工作,這無疑為“中國的ChatGPT”的開發工作喂了一顆定心丸。希望在不久的將來,我們可以看到真正在自研算力平臺上訓練的,能與ChatGPT比肩的中文模型。
前途一定是光明的。
審核編輯 :李倩
-
模型
+關注
關注
1文章
3286瀏覽量
49007 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
7886
原文標題:“中國的ChatGPT”真的要來了嗎?
文章出處:【微信號:sugoncn,微信公眾號:中科曙光】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT新增實時搜索與高級語音功能
怎樣搭建基于 ChatGPT 的聊天系統
華納云:ChatGPT 登陸 Windows
用launch pad燒錄chatgpt_demo項目會有api key報錯的原因?
車路云協同,這次它真的來了嗎?

降價潮背后:大模型落地門檻真的降了嗎?

使用espbox lite進行chatgpt_demo的燒錄報錯是什么原因?
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了
iOS版ChatGPT支持首選語言設置中文
李開復:中國須獨立研發ChatGPT?
OpenAI的AI搜索也要來了,但我們需要這么多AI搜索么





 工商網監
工商網監
評論