 【AI周報20230317】 OpenAI公布GPT-4、國內存在哪些算力瓶頸
【AI周報20230317】 OpenAI公布GPT-4、國內存在哪些算力瓶頸
嵌入式 AI
AI 簡報 20230317 期
1. AI服務器市場規模持續增加,國內存在哪些算力瓶頸?
原文:
https://mp.weixin.qq.com/s/v04vZCBxNzfCUDTy_8iSoA
近年來,在全球數字化、智能化的浪潮下,智能手機、自動駕駛、數據中心、圖像識別等應用推動 AI服務器市場迅速成長。根據 IDC 數據,2021 年全球 AI 服務器市場規模已達到 145 億美元,并預計 2025 年將超過 260 億美元。
近段時間ChatGPT概念的火熱,更是對算力基礎設施的需求起到了帶動作用。寧暢副總裁兼CTO趙雷此前在接受媒體采訪的時候表示,ChatGP的訓練和部署,都需要大量智能計算數據存儲以及傳輸資源,計算機基礎設施、算力等上游技術將因此受益。
ChatGPT有著多達1750億個模型參數。在算力方面,GPT-3.5在訓練階段消耗的總算力約3640PF-days。在應用時,ChatGPT仍然需要大算力的服務器支持。ChatGPT的持續爆火也為AIGC帶來全新增量,行業對AI模型訓練所需要的算力支持提出了更高要求。
寧暢是一家集研發、生產、部署、運維一體的服務器廠商,及IT系統解決方案提供商。該公司早早就開始著重發力于人工智能服務器和液冷服務器。趙雷表示,公司目前在用的、在研的人工智能和液冷服務器,包括明年還將推出的浸沒液冷服務器,剛好跟上算力高速增長的市場需求。公司隨時準備著為客戶提供合適的高算力產品和解決方案。
在人工智能服務器方面,寧暢已經推出多款產品,包括X620 G50、X660 G45、X640 G40、X620 G40。X620 G50適用于機器學習、AI推理、云計算、高性能計算等場景;660 G45是專門為深度學習訓練開發的高性能計算平臺;X640 G40是兼備訓練與推理功能的全能型GPU服務器;X620 G40性能提升的同時支持PCIe 4.0高速總線技術,完美支持NVIDIA各類最新型GPU加速服務,是最為理想的AI推理平臺。
在液冷服務器方面,寧暢推出了三款冷板式液冷服務器,包括產品B5000 G4 LP、X660 G45 LP、R620 G40 LP,范圍覆蓋了高密度、通用機架以及人工智能服務器產品,可滿足科學計算、AI訓練、云計算等眾多IT應用場景,可滿足用戶不同需求。
作為服務器廠商需要給下游互聯網客戶提供怎樣的產品和服務呢?對于服務器廠商來說,不只是要提供服務器硬件或者基礎設施,還要有對應的服務能力。
從服務層面來看,在用戶現場會關注什么呢,比如說核心業務,會關注業務的在線率,不管服務器壞不壞,整個業務的運行是要有彈性的、靈活的,不會給客戶造成影響的。就以百度、微信這些業務為例,大家幾乎不會看到微信不能用了,或者百度搜索不反饋結果了。
趙雷表示,對于服務器廠商來說,要做的是在服務層面能夠快速響應,不管是采用現場備件模式,機房備機模式,還是駐場人員巡檢的模式,都需要做到24小時的快速響應。這是純粹的服務方面,也就是說,在互聯網搭建業務連續性良好的基礎上,服務器廠商能夠將故障和快速維修的能力做到極致,有效地支撐客戶的前端應用。
從產品層面來看,對于每個硬件子系統在設計研發過程中,都需要從易維修和低故障角度去思考如何將產品做得更好。寧暢在這方面做了很多工作:首先,現在冷卻方式是影響故障率比較重要的因素,因為溫度太高故障率就會高,寧暢的精密風冷和液冷的方式,能夠有效地降低芯片和對應組件的故障率。
其次,其精密六維減震模式,能夠有效提升硬盤的性能,降低故障率;接著是,采用DAE的散熱器,從散熱的維度有效降低光模塊的故障率。同時CPU、GPU的液冷可以有效降低CPU、GPU的故障率;通過內存的漏斗,內存的故障篩選或者在線隔離技術,有效地降低內存的故障率;另外還在板卡走線、機箱結構方面進行了優化設計。
此外還有整機BMC易管理特性,趙雷認為,任何東西不可能不壞,有毛病是不可避免的,壞了以后,如何快速通知客戶或者維護人員維修時關鍵。BMC有一個完善的通知機制,郵件自動通知、SMP遠程告警、IPMI告警等。寧暢按照互聯網客戶的需求定制,將其融入整個機房的運維系統,出現故障以后可以第一時間通知去維修。
雖然目前國內有不少優秀的服務器、云廠商等,不過整體來看,國內的算力仍然存在瓶頸,比如,總體算力不夠,算力的分布不平均。部分客戶算力過剩,部分客戶算力不足。或者A時間算力過剩,B時間算力不足,這是算力協調的問題。
短期來看這個問題要靠云技術解決,長期來看是要提供過剩的算力。也就是說,需要云技術去平衡協調算力不均勻的問題,還需要提供算力、算力效率等。
再比如算力成本高的問題,雖然目前每單位算力單價下降了,但是過去幾年服務器的平均售價一直上漲。趙雷認為,可能算力類型單一,不太能夠有效地支撐高速增長的模式,可能要有各種各樣不同類型的算力。比如ChatGPT,是不是可以做針對GPT模型專門的ASIC。算力的應用類型越窄,它的效率就會越高,越通用,效率就越低。
整體而言,過去幾年在全球數字化、智能化浪潮下,市場對算力的需求不斷增加。ChatGP的出現更是讓行業對算力提出了新的要求。國內服務器廠商在對人工智能行業提供算力支持方面已經有所準備。不過從目前的情況來看,國內在算力方面仍然存在一些瓶頸,比如算力分布不均勻,成本高等問題。后續還需業界共同去探討解決。
2. PyTorch 2.0正式版發布!一行代碼提速2倍,100%向后兼容
原文:
https://mp.weixin.qq.com/s/wC0Oixd3hSnH75DsPDTC-g
去年12月,PyTorch基金會在PyTorch Conference 2022上發布了PyTorch 2.0的第一個預覽版本。
跟先前1.0版本相比,2.0有了顛覆式的變化。在PyTorch 2.0中,最大的改進是torch.compile。
新的編譯器比以前PyTorch 1.0中默認的「eager mode」所提供的即時生成代碼的速度快得多,讓PyTorch性能進一步提升。

除了2.0之外,還發布了一系列PyTorch域庫的beta更新,包括那些在樹中的庫,以及包括 TorchAudio、TorchVision和TorchText在內的獨立庫。TorchX的更新也同時發布,可以提供社區支持模式。
-torch.compile是PyTorch 2.0的主要API,它包裝并返回編譯后的模型,torch.compile是一個完全附加(和可選)的特性,因此2.0版本是100%向后兼容的。
-作為torch.compile的基礎技術,帶有Nvidia和AMD GPU的TorchInductor將依賴OpenAI Triton深度學習編譯器來生成高性能代碼,并隱藏低級硬件細節。OpenAI Triton生成的內核實現的性能,與手寫內核和cublas等專門的cuda庫相當。
-Accelerated Transformers引入了對訓練和推理的高性能支持,使用自定義內核架構實現縮放點積注意力 (SPDA)。API與torch.compile () 集成,模型開發人員也可以通過調用新的scaled_dot_product_attention () 運算符,直接使用縮放的點積注意力內核。
-Metal Performance Shaders (MPS) 后端在Mac平臺上提供GPU加速的PyTorch訓練,并增加了對前60個最常用操作的支持,覆蓋了300多個操作符。
-Amazon AWS優化了基于AWS Graviton3的C7g實例上的PyTorch CPU推理。與之前的版本相比,PyTorch 2.0提高了Graviton的推理性能,包括對Resnet50和Bert的改進。
-跨TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch和TorchInductor的新原型功能和技術。
3. OpenAI公布GPT-4:可在考試中超過90%的人類
原文:
https://mp.weixin.qq.com/s/YYZNYOUItGW18xAWk7In8Q
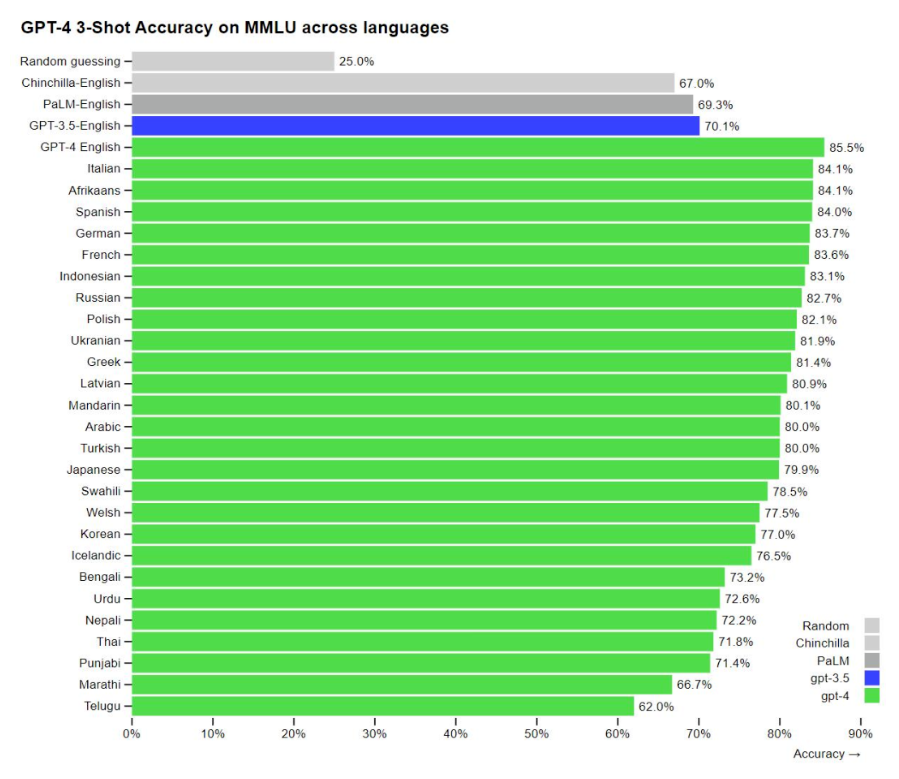
當地時間周二(3月14日),人工智能研究公司OpenAI公布了其大型語言模型的最新版本——GPT-4.該公司表示,GPT-4在許多專業測試中表現出超過絕大多數人類的水平。
OpenAI表示,我們已經創建了GPT-4,這是OpenAI在深度學習規模化方面的最新里程碑。GPT-4是一個大型的多模型模型(接受圖像和文本輸入、輸出文本),雖然在許多現實場景中不如人類聰明,但在各種專業和學術基準測試中表現出人類水平的性能。
看起來,現在的 GPT 已經不會在計算上胡言亂語了:

還是個物理題:

GPT-4 看懂了法語題目,并完整解答:

GPT-4 可以理解一張照片里「有什么不對勁的地方」:

OpenAI于2020年發布了GPT(生成型預訓練變換模型)-3(生成型預訓練變換模型),并將其與GPT-3.5分別用于創建Dall-E和聊天機器人ChatGPT,這兩款產品極大地吸引了公眾的關注,并刺激其他科技公司更積極地追求人工智能(AI)。OpenAI周二表示,在內部評估中,相較于GPT-3.5,GPT-4產生正確回應的可能性要高出40%。而且GPT-4是多模態的,同時支持文本和圖像輸入功能。
OpenAI稱,GPT-4比以前的版本“更大”,這意味著其已經在更多的數據上進行了訓練,并且在模型文件中有更多的權重,這使得它的運行成本更高。
據OpenAI介紹,在某些情況下,GPT-4比之前的GPT-3.5版本有了巨大改進,新模型將產生更少的錯誤答案,更少地偏離談話軌道,更少地談論禁忌話題,甚至在許多標準化測試中比人類表現得更好。
例如,GPT-4在模擬律師資格考試的成績在考生中排名前10%左右,在SAT閱讀考試中排名前7%左右,在SAT數學考試中排名前11%左右。
OpenAI表示,雖然兩個版本在日常對話中看起來很相似,但當任務復雜到一定程度時,差異就表現出來了,GPT-4更可靠、更有創造力,能夠處理更微妙的指令。
不過,OpenAI也警告稱,GPT-4還不完美,在許多情況下,它的能力不如人類。該公司表示:“GPT-4仍有許多已知的局限性,我們正在努力解決,比如社會偏見、幻覺和對抗性提示。”
OpenAI透露,摩根士丹利正在使用GPT-4來組織數據,而電子支付公司Stripe正在測試GPT-4是否有助于打擊欺詐。其他客戶還包括語言學習公司Duolingo、Khan Academy和冰島政府。
OpenAI合作伙伴微軟周二表示,新版必應搜索引擎將使用GPT-4。
4. 物理學家狂喜的AI工具開源了!靠實驗數據直接發現物理公式,筆記本就能跑
原文:
https://mp.weixin.qq.com/s/0eGiiWdKUyQcg54azY5evg
一個讓物理學家狂喜的AI工具,在GitHub上開源了!它名叫Φ-SO ,能直接從數據中找到隱藏的規律,而且一步到位,直接給出對應公式。
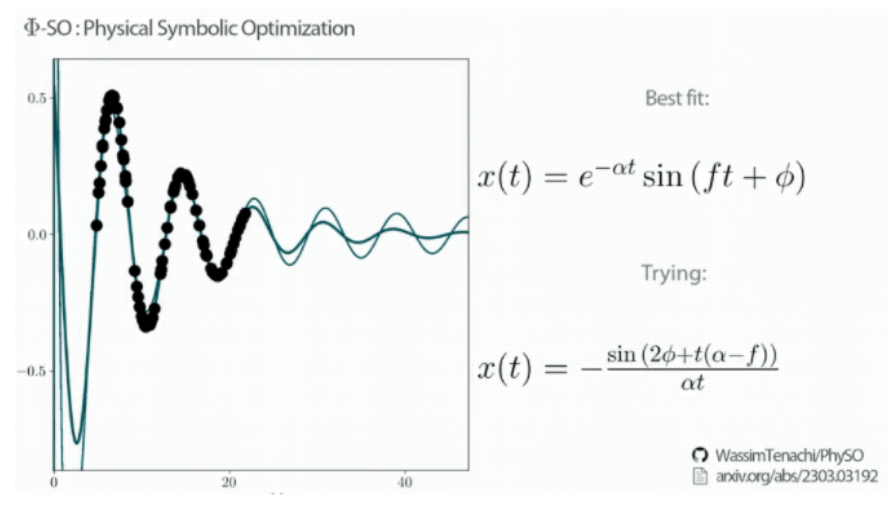
整個過程也不需要動用超算,一臺筆記本大概4個小時就能搞定愛因斯坦的質能方程。

這項成果來自德國斯特拉斯堡大學與澳大利亞聯邦科學與工業研究組織Data61部門,據論文一作透露,研究用了1.5年時間,受到學術界廣泛關注。代碼一經開源,漲星也是飛快。
除了物理學者直呼Amazing之外,還有其他學科研究者趕來探討,能不能把同款方法遷移到他們的領域。
強化學習+物理條件約束
Φ-SO背后的技術被叫做“深度符號回歸”,使用循環神經網絡(RNN)+強化學習實現。
首先將前一個符號和上下文信息輸入給RNN,預測出后一個符號的概率分布,重復此步驟,可以生成出大量表達式。
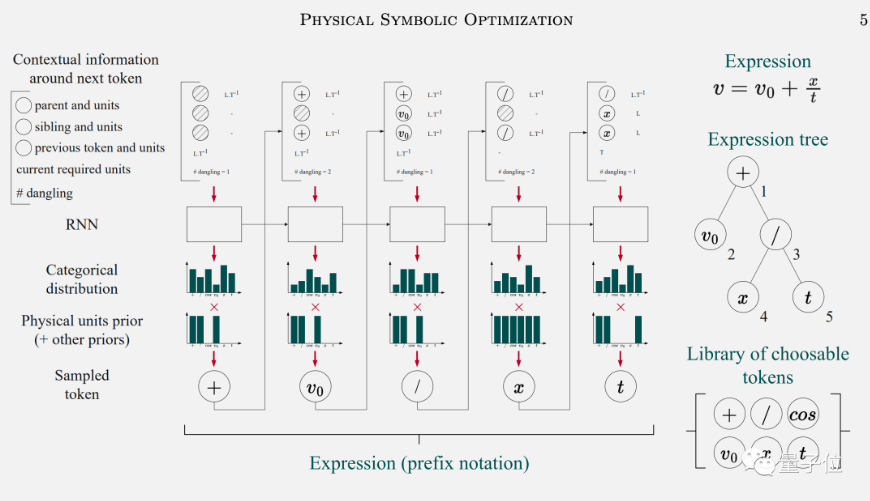
同時將物理條件作為先驗知識納入學習過程中,避免AI搞出沒有實際含義的公式,可以大大減少搜索空間。
再引入強化學習,讓AI學會生成與原始數據擬合最好的公式。
與強化學習用來下棋、操控機器人等不同,在符號回歸任務上只需要關心如何找到最佳的那個公式,而不關心神經網絡的平均表現。
于是強化學習的規則被設計成,只對找出前5%的候選公式做獎勵,找出另外95%也不做懲罰,鼓勵模型充分探索搜索空間。
研究團隊用阻尼諧振子解析表達式、愛因斯坦能量公式,牛頓的萬有引力公式等經典公式來做實驗。
Φ-SO都能100%的從數據中還原這些公式,并且以上方法缺一不可。研究團隊在最后表示,雖然算法本身還有一定改進空間,不過他們的首要任務已經改成用新工具去發現未知的物理規律去了。
讀到這,小編有一個不成熟的想法….
5. 擴散模型大殺器 ControlNet 解析
原文:
https://mp.weixin.qq.com/s/_7su0EX-eBbeyV0V8o3cLg
標題:Adding Conditional Control to Text-to-Image Diffusion Models
作者:Lvmin Zhang, Maneesh Agrawala
原文鏈接:
https://arxiv.org/pdf/2302.05543.pdf
代碼鏈接:
https://github.com/lllyasviel/ControlNet
大型文本到圖像模型的存在讓人們意識到人工智能的巨大潛力,這些模型可以通過用戶輸入簡短的描述性提示來生成視覺上吸引人的圖像。然而,對于一些長期存在、具有明確問題表述的任務(例如圖像處理),我們可能會有一些問題需要回答。這些問題包括:這種基于提示的控制是否滿足我們的需求?在特定任務中,這些大型模型能否應用于促進這些特定任務?我們應該建立什么樣的框架來處理廣泛的問題條件和用戶控制?在特定任務中,大型模型能否保留從數十億張圖片中獲得的優勢和能力?為了回答這些問題,作者們調查了各種圖像處理應用,并得出了三個發現。第一個發現是,在特定任務領域中可用的數據規模并不總是與通用圖像-文本領域中相同。第二個發現是,對于一些特定任務,需要更加精細的控制和指導,而不僅僅是簡單的提示。第三個發現是,在特定任務中,大型模型可能會面臨過擬合和泛化能力不足等問題。為了解決這些問題,作者們提出了一種名為ControlNet的框架,該框架可以根據用戶提供的提示和控制來生成高質量的圖像,并且可以在特定任務中進行微調以提高性能。
與之相關的主要工作有HyperNetwork和Stable Diffusion。HyperNetwork是一種用于訓練神經網絡的方法,它可以通過一個小型的神經網絡來影響一個更大的神經網絡的權重。HyperNetwork已經在圖像生成等領域取得了成功,并且已經有多篇相關論文發表。另外,Stable Diffusion是一種用于圖像生成和編輯的技術,它可以通過擴散過程來生成高質量、多樣化的圖像,并且可以通過附加小型神經網絡來改變其藝術風格。ControlNet和HyperNetwork之間的相似之處在于它們都可以影響神經網絡的行為,從而實現特定任務的目標。具體來說,HyperNetwork使用一個小型的神經網絡來影響一個更大的神經網絡的權重,從而改變其行為。而ControlNet則是將大型圖像擴散模型中的權重克隆到一個“可訓練副本”和一個“鎖定副本”中,其中鎖定副本保留了從數十億張圖像中學習到的網絡能力,而可訓練副本則在特定數據集上進行訓練以學習條件控制。此外,它們在影響神經網絡行為方面的共同點是它們都使用了小型神經網絡來對大型神經網絡進行控制。這種方法可以使得大型神經網絡更加靈活和適應性強,并且可以根據不同任務和條件進行調整和優化。ControlNet與其他相關工作之間的優勢主要體現在以下幾個方面:
-
控制方式不同:ControlNet通過控制神經網絡中的輸入條件來影響其行為,而其他相關工作則可能采用不同的控制方式,例如直接修改權重或者使用外部約束等。
-
可解釋性更強:ControlNet可以通過可視化輸入條件和輸出結果之間的關系來解釋其行為,從而更好地理解神經網絡的內部機制。這對于一些需要可解釋性的任務非常重要。
-
適應性更強:ControlNet可以根據不同任務和條件進行調整和優化,從而使得神經網絡更加靈活和適應性強。這對于一些復雜、多變的任務非常重要。
-
訓練效果更好:ControlNet可以通過使用鎖定副本來保留從數十億張圖像中學習到的網絡能力,并將其與可訓練副本進行結合來進行訓練。這種方法可以使得訓練效果更好,并且可以避免過擬合等問題。
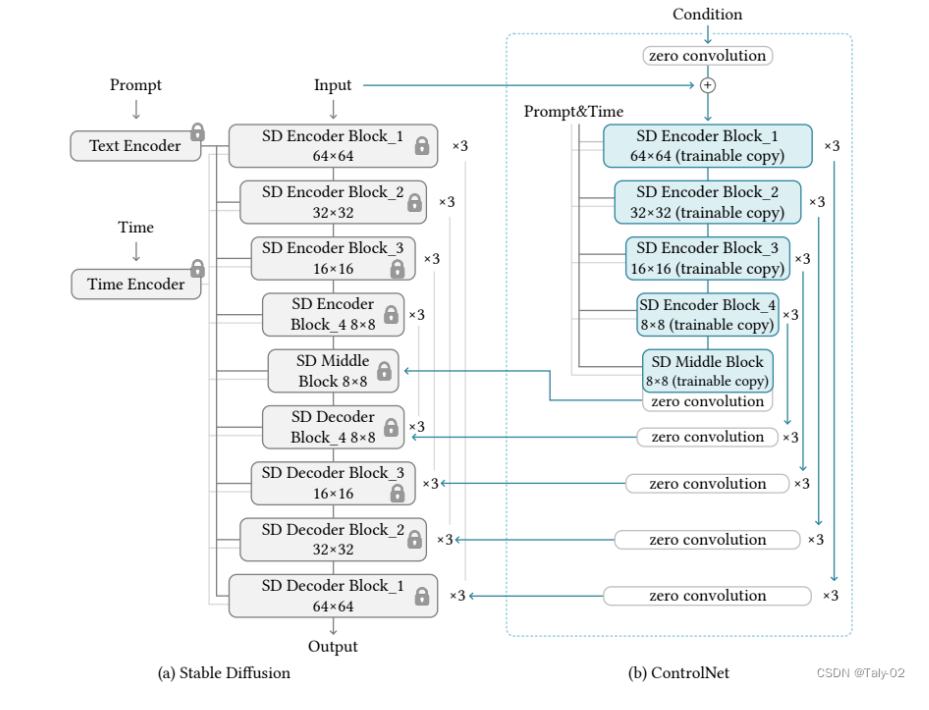
我們盡量少用公式進行表達,主要的技術細節和設定可以參考論文。ControlNet是一種神經網絡架構,可以通過特定任務的條件來增強預訓練的圖像擴散模型。該方法包括幾個關鍵組件,包括預訓練模型的“可訓練副本”和“鎖定副本”,以及一組輸入條件,可以用來控制輸出。整個過程可以概括如下:
-
克隆預訓練模型:ControlNet首先創建了預訓練圖像擴散模型的兩個副本,其中一個是“鎖定”的,不能被修改,而另一個是“可訓練”的,可以在特定任務上進行微調。ControlNet使用了一種稱為“權重共享”的技術,該技術可以將預訓練模型的權重復制到兩個不同的神經網絡中。這樣,在微調可訓練副本時,鎖定副本仍然保留著從預訓練中學到的通用知識,并且可以提供更好的初始狀態。需要注意的是,在克隆預訓練模型之前,需要先選擇一個適合特定任務的預訓練模型,并對其進行必要的調整和優化。這樣才能確保克隆出來的模型能夠更好地適應特定任務,并取得更好的效果。
-
定義輸入條件:ControlNet然后定義了一組輸入條件,可以用來控制模型的輸出。這些條件可能包括顏色方案、對象類別或其他特定任務參數。該技術可以將輸入條件與預訓練模型進行連接,并將其作為額外的輸入信息傳遞給神經網絡。這樣,在微調可訓練副本時,神經網絡可以根據這些輸入條件來調整輸出結果,并更好地適應特定任務。需要注意的是,在定義輸入條件之前,需要先確定哪些參數對于特定任務是最重要的,并選擇合適的方式來表示這些參數。例如,在圖像分類任務中,可能需要考慮對象類別、顏色和紋理等因素,并選擇合適的方式來表示它們。同時,還需要確保這些輸入條件能夠被有效地傳遞給神經網絡,并且不會對模型性能產生負面影響。
-
訓練可訓練副本:ControlNet然后使用反向傳播和其他標準訓練技術,在特定數據集上對可訓練副本進行訓練。很自然的就是一個標準的神經網絡訓練流程。訓練可訓練副本之前,需要先選擇一個適合特定任務的預訓練模型,并將其克隆為可訓練副本。同時還需要確定哪些輸入條件對于特定任務是最重要的,并將其與預訓練模型進行連接。
-
合并輸出:最后,ControlNet將兩個模型副本的輸出組合起來,產生一個最終結果,既包含從預訓練中學到的通用知識,也包含從微調中學到的特定知識。
這種方法自然是要看可視化展示的:
總的來說,ControlNet是一種新穎的神經網絡架構,可以通過微調預訓練模型來適應特定任務,并在多個基準數據集上取得了非常好的性能表現。該方法使用條件控制技術將輸入條件與預訓練模型進行連接,并將其作為額外的輸入信息傳遞給神經網絡,從而幫助神經網絡更好地理解輸入條件,并取得更好的效果。同時,ControlNet還探討了不同因素對其性能的影響,例如不同輸入條件、不同預訓練模型和不同微調策略等。實驗結果表明,在多個基準數據集上,ControlNet都取得了非常好的性能表現,并且在圖像分類、圖像生成和圖像檢索等任務中也有廣泛應用。因此,我們相信ControlNet是一種非常有前景和實用價值的神經網絡架構,并且在未來會有更廣泛的應用。
6. CVPR 2023|EMA-VFI: 基于幀間注意力提取運動和外觀信息的高效視頻插幀
https://mp.weixin.qq.com/s/w7xCUBedykOmI9Bq6lQ4Ow
論文鏈接:
https://arxiv.org/abs/2303.00440
代碼鏈接:
https://github.com/MCG-NJU/EMA-VFI
1. 研究動機
視頻插幀(Video Frame Interpolation, VFI)任務的目標是給定連續的兩幀,生成這兩幀之間的固定時刻的幀或者任意時刻的幀。顧名思義,VFI最直接的用途就是用來提高幀率,經常和視頻超分方法用來同時提升視頻的空間和時間上的分辨率。VFI和其他常見的視頻修復任務(如視頻超分、視頻去噪等)最大的不同就是VFI任務要生成原本不存在的幀,而其他視頻修復任務要修復一張原本存在的幀,這樣的不同也讓插幀任務的設計思路無法直接借鑒視頻復原方法的思路。
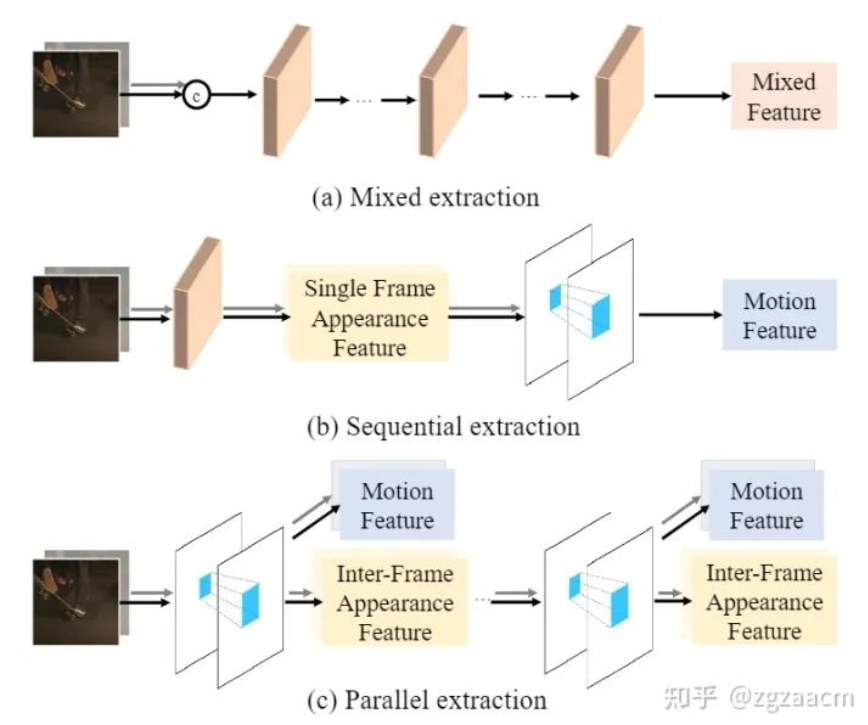
為了生成兩幀之間的某一幀,從直覺上理解,VFI算法首先需要建模兩幀之間的運動關系,然后將兩幀中對應區域的外觀信息依靠建立好的運動關系匯聚到要生成的幀上。因此,設計高效地提取兩幀之間的運動信息和外觀信息的方法對于一個好的VFI算法來說是至關重要的。經過充分調研,我們發現目前VFI算法提取這兩種信息的方式可以分為兩類,如圖1。
第一種范式(如圖1中的(a)),也是最常見的一類設計,直接將兩幀按通道拼在一起,經過重復的網絡模塊提取出特征,這個特征既用來建模運動也用來表征外觀,我們在此將這樣的提取范式稱為混合提取(mixed extraction)。盡管混合提取范式設計十分簡潔,但因為要隱式地提取兩種信息,往往對特征提取模塊的設計和容量都有較高的要求。同時,因為沒有顯示的運動信息,也無法直接得到任意時刻運動建模所需的運動信息,這種范式限制了任意時刻插幀的能力。
第二種范式(如圖1中的(b)),采用了串行提取兩種信息的思路,首先先提取每一幀的單獨的外觀信息,再利用兩者的外觀信息提取運動信息。這種提取范式需要針對每一種信息單獨設計提取模塊,往往會引入額外計算開銷,并且無法像混合提取范式一樣只需堆疊相同的模塊就可以提升性能。同時,這樣得到的外觀特征沒有很好地進行幀間信息的交互,而這種交互對于生成中間幀是至關重要的。
這里我們提出了疑問:是否存在能夠同時顯式地提取兩種信息,且設計簡潔有效的范式呢?如圖1中的(c),我們希望設計一個模塊,能夠同時顯式地提取運動信息和兩幀之間交互過的外觀信息,并且可以像混合提取范式一樣只需通過控制模塊的個數和容量來控制性能。
2. 方法介紹
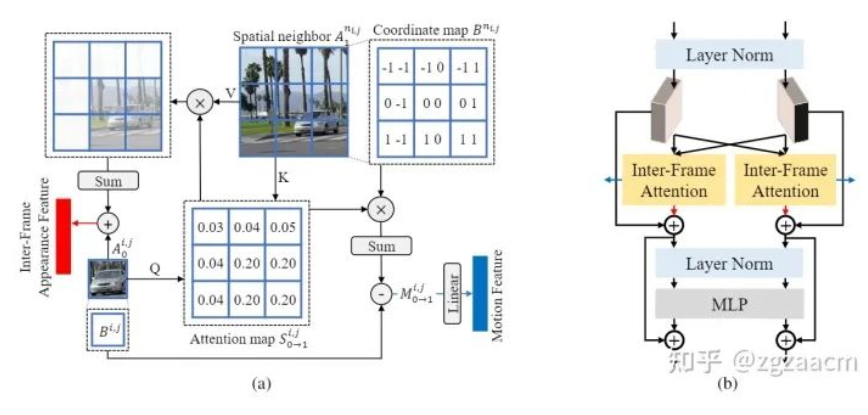
利用幀間注意力(Inter-Frame Attention, IFA)提取兩種特征
在本文中,我們提出利用幀間的注意力機制來同時提取運動信息和兩幀之間的交互過的外觀信息。具體來說,如圖2中的(a),對于當前幀中的任何一個區域,我們將其作為注意力機制中的查詢(query),并將其在另一幀的空間上的相鄰的所有區域作為鍵和值(key&value)來推導出代表其當前區域與另一幀相鄰區域的注意力圖。隨后,該注意力圖被用來匯總鄰居的外觀特征,并和當前區域的外觀特征進行聚合,從而得到同一個區域在兩幀不同位置的外觀信息的聚合特征(Inter-Frame Appearance Feature)。此外,注意力圖也被用來對另一幀的相鄰區域的位移進行加權,以獲得當前區域從當前幀到相鄰幀的近似運動向量(Motion Vector),并經過一個線性層得到兩幀之間的運動特征。
這樣,通過一次注意力操作,我們通過注意力圖的復用同時獨立的提取出了兩種特征。值得注意的是,這樣得到的外觀特征沒有混淆位置信息,所以可以進一步在此基礎上提取新的外觀信息和運動信息。遵循目前主流的結構設計思路,我們將幀間注意力機制放在了Transformer的結構中,如圖2中的(b)。這樣的設計讓我們只需要改變特征的通道數和Transformer block的個數就能控制提取的兩種特征的質量和多樣性。(具體細節請參考原文)
3. 實驗結果
關于固定插幀(生成兩幀之間的中間幀)的性能比較如圖5:
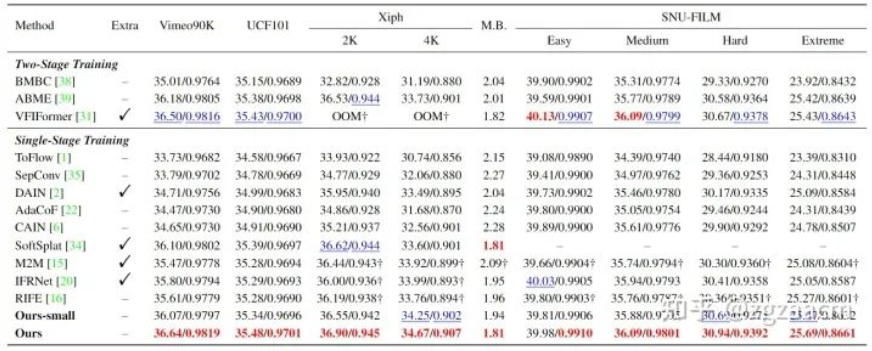
關于任意時刻插幀的性能比較如圖6:
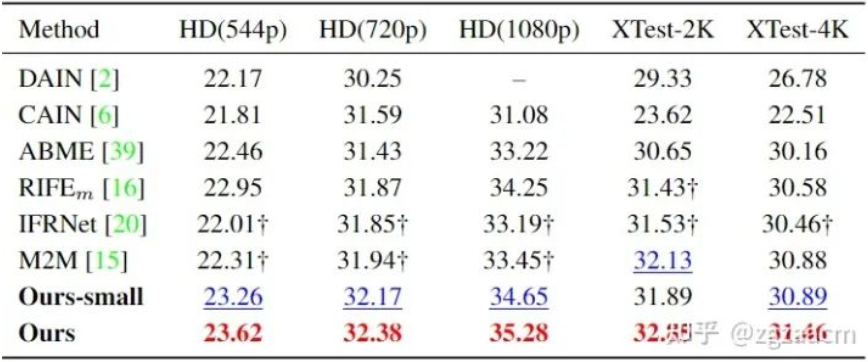
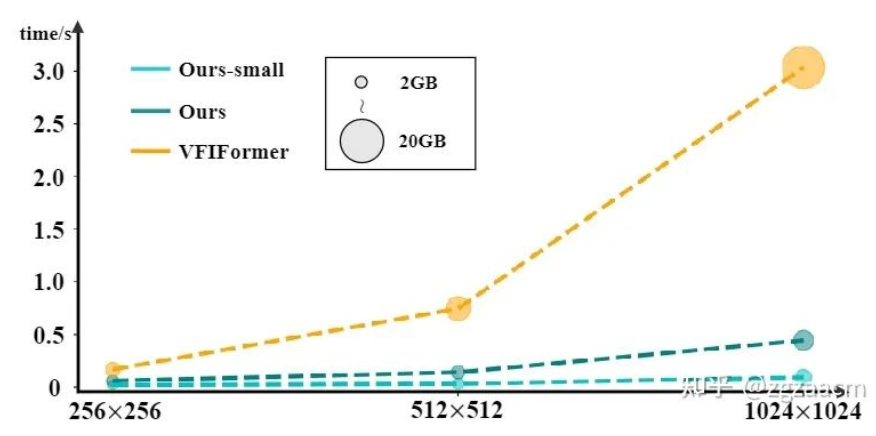
可以從結果看出來我們提出方法在兩個子任務的不同數據集上都有較大的性能提升。圖7是和之前SOTA方法VFIFormer的運行速度和占用內存的比較,我們的方法隨著輸入尺寸的增大,計算開銷有了成倍的減少:
4. 局限&未來展望
雖然我們提出的方法已經取得了不小的改進,但仍有一些局限性值得探索。首先,盡管混合CNN和Transformer的設計可以減輕計算開銷,但它也限制了在的高分辨率外觀特征下利用IFA進行運動信息的提取。其次,我們的方法的輸入僅限于兩個連續的幀,這導致無法利用來自多個連續幀的信息。在未來的工作中,我們會嘗試在不引入過多計算開銷的情況下將我們的方法擴展到多幀的輸入。同時,因為我們提出的能夠同時提取運動和外觀信息的IFA模塊對于視頻的不同任務都是通用的,我們也將研究如何將幀間注意應用于其他同樣需要這兩類信息的領域,如動作識別和動作檢測。
7. 模型訓練過程中,混合精度訓練穩定性解決方案
原文:
https://mp.weixin.qq.com/s/9qfyncdq_UfiKGM73ekthQ
混合精度已經成為訓練大型深度學習模型的必要條件,但也帶來了許多挑戰。將模型參數和梯度轉換為較低精度數據類型(如FP16)可以加快訓練速度,但也會帶來數值穩定性的問題。使用進行FP16 訓練梯度更容易溢出或不足,導致優化器計算不精確,以及產生累加器超出數據類型范圍的等問題。
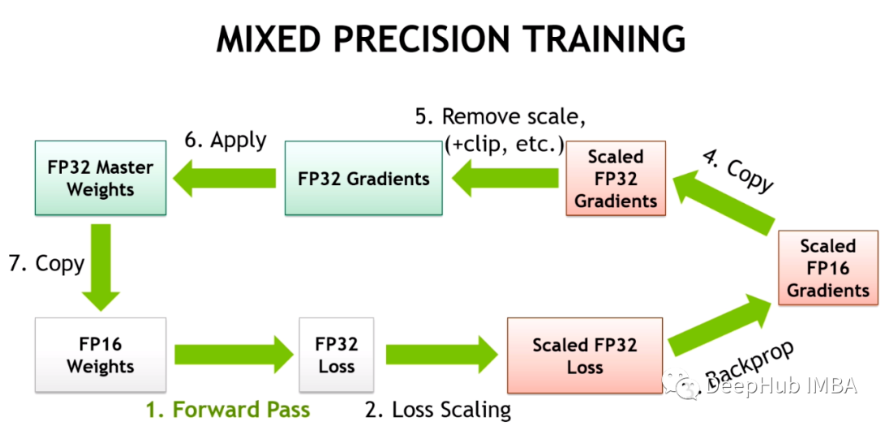
在這篇文章中,我們將討論混合精確訓練的數值穩定性問題。為了處理數值上的不穩定性,大型訓練工作經常會被擱置數天,會導致項目的延期。所以我們可以引入Tensor Collection Hook來監控訓練期間的梯度條件,這樣可以更好地理解模型的內部狀態,更快地識別數值不穩定性。在早期訓練階段了解模型的內部狀態可以判斷模型在后期訓練中是否容易出現不穩定是非常好的辦法,如果能夠在訓練的頭幾個小時就能識別出梯度不穩定性,可以幫助我們提升很大的效率。所以本文提供了一系列值得關注的警告,以及數值不穩定性的補救措施。
混合精度訓練
隨著深度學習繼續向更大的基礎模型發展。像GPT和T5這樣的大型語言模型現在主導著NLP,在CV中對比模型(如CLIP)的泛化效果優于傳統的監督模型。特別是CLIP的學習文本嵌入意味著它可以執行超過過去CV模型能力的零樣本和少樣本推理,訓練這些模型都是一個挑戰。
這些大型的模型通常涉及深度transformers網絡,包括視覺和文本,并且包含數十億個參數。GPT3有1750億個參數,CLIP則是在數百tb的圖像上進行訓練的。模型和數據的大小意味著模型需要在大型GPU集群上進行數周甚至數月的訓練。為了加速訓練減少所需gpu的數量,模型通常以混合精度進行訓練。
混合精確訓練將一些訓練操作放在FP16中,而不是FP32。在FP16中進行的操作需要更少的內存,并且在現代gpu上可以比FP32的處理速度快8倍。盡管在FP16中訓練的大多數模型精度較低,但由于過度的參數化它們沒有顯示出任何的性能下降。
隨著英偉達在Volta架構中引入Tensor Cores,低精度浮點加速訓練更加快速。因為深度學習模型有很多參數,任何一個參數的確切值通常都不重要。通過用16位而不是32位來表示數字,可以一次性在Tensor Core寄存器中擬合更多參數,增加每個操作的并行性。
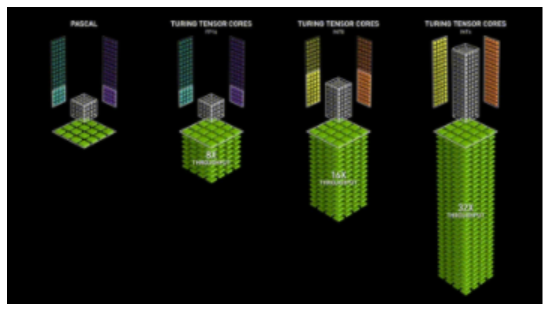
但FP16的訓練是存在挑戰性的。因為FP16不能表示絕對值大于65,504或小于5.96e-8的數字。深度學習框架例如如PyTorch帶有內置工具來處理FP16的限制(梯度縮放和自動混合精度)。但即使進行了這些安全檢查,由于參數或梯度超出可用范圍而導致大型訓練工作失敗的情況也很常見。深度學習的一些組件在FP32中發揮得很好,但是例如BN通常需要非常細粒度的調整,在FP16的限制下會導致數值不穩定,或者不能產生足夠的精度使模型正確收斂。這意味著模型并不能盲目地轉換為FP16。
所以深度學習框架使用自動混合精度(AMP),它通過一個預先定義的FP16訓練安全操作列表。AMP只轉換模型中被認為安全的部分,同時將需要更高精度的操作保留在FP32中。另外在混合精度訓練中模型中通過給一些接近于零梯度(低于FP16的最小范圍)的損失乘以一定數值來獲得更大的梯度,然后在應用優化器更新模型權重時將按比例向下調整來解決梯度過小的問題,這種方法被稱為梯度縮放。
下面是PyTorch中一個典型的AMP訓練循環示例。

梯度縮放器scaler會將損失乘以一個可變的量。如果在梯度中觀察到nan,則將倍數降低一半,直到nan消失,然后在沒有出現nan的情況下,默認每2000步逐漸增加倍數。這樣會保持梯度在FP16范圍內,同時也防止梯度變為零。
訓練不穩定的案例
盡管框架都盡了最大的努力,但PyTorch和TensorFlow中內置的工具都不能阻止在FP16中出現的數值不穩定情況。
在HuggingFace的T5實現中,即使在訓練之后模型變體也會產生INF值。在非常深的T5模型中,注意力值會在層上累積,最終達到FP16范圍之外,這會導致值無窮大,比如在BN層中出現nan。他們是通過將INF值改為在FP16的最大值解決了這個問題,并且發現這對推斷的影響可以忽略不計。
另一個常見問題是ADAM優化器的限制。作為一個小更新,ADAM使用梯度的第一和第二矩的移動平均來適應模型中每個參數的學習率。
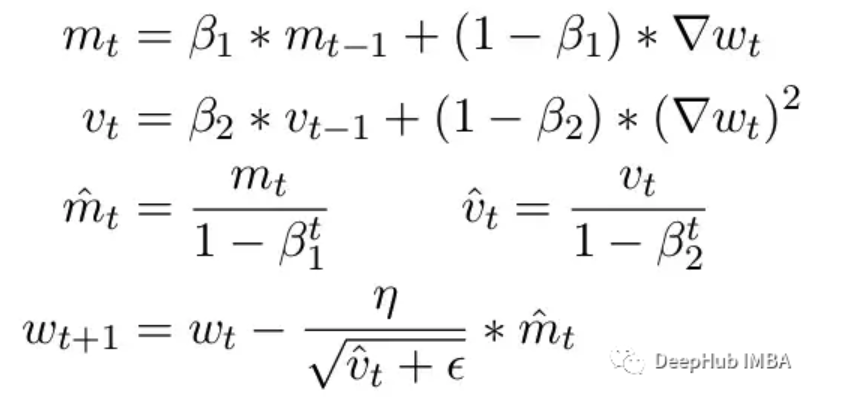
這里Beta1 和 Beta2 是每個時刻的移動平均參數,通常分別設置為 .9 和 .999。用 beta 參數除以步數的冪消除了更新中的初始偏差。在更新步驟中,向二階矩參數添加一個小的 epsilon 以避免被零除產生錯誤。epsilon 的典型默認值是 1e-8。但 FP16 的最小值為 5.96e-8。這意味著如果二階矩太小,更新將除以零。所以在 PyTorch 中為了訓練不會發散,更新將跳過該步驟的更改。但問題仍然存在尤其是在 Beta2=.999 的情況下,任何小于 5.96e-8 的梯度都可能會在較長時間內停止參數的權重更新,優化器會進入不穩定狀態。
ADAM的優點是通過使用這兩個矩,可以調整每個參數的學習率。對于較慢的學習參數,可以加快學習速度,而對于快速學習參數,可以減慢學習速度。但如果對多個步驟的梯度計算為零,即使是很小的正值也會導致模型在學習率有時間向下調整之前發散。
另外PyTorch目前還一個問題,在使用混合精度時自動將epsilon更改為1e-7,這可以幫助防止梯度移回正值時發散。但是這樣做會帶來一個新的問題,當我們知道梯度在相同的范圍內時,增加ε會降低了優化器適應學習率的能力。所以盲目的增加epsilon也不能解決由于零梯度而導致訓練停滯的情況。
關于這一主題,還有非常多需要注意和學習的地方,感興趣的小伙伴可以點擊查看原文。
8. YOLOv7默默更新Anchor-Free,無痛再漲1.4個mAP!
原文:
https://mp.weixin.qq.com/s/z-lx-yYvI5kFKdLfbDoSOA
YOLOv7-u6分支的實現是基于Yolov5和Yolov6進行的。并在此基礎上開發了Anchor-Free方法。所有安裝、數據準備和使用與Yolov5相同,大家可以酌情嘗試,如果電費不要錢,那就不要猶豫了!!!
先看原始的YOLOv7的精度
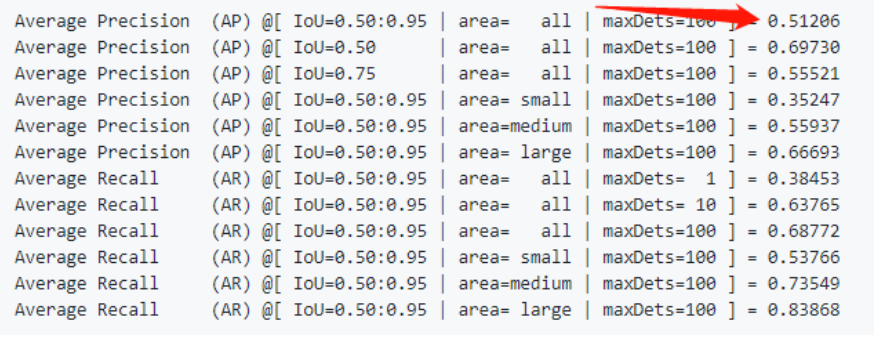
當時原始版本就是無敵的存在,YOLOv7的base版本就有51.2的精度了!!!
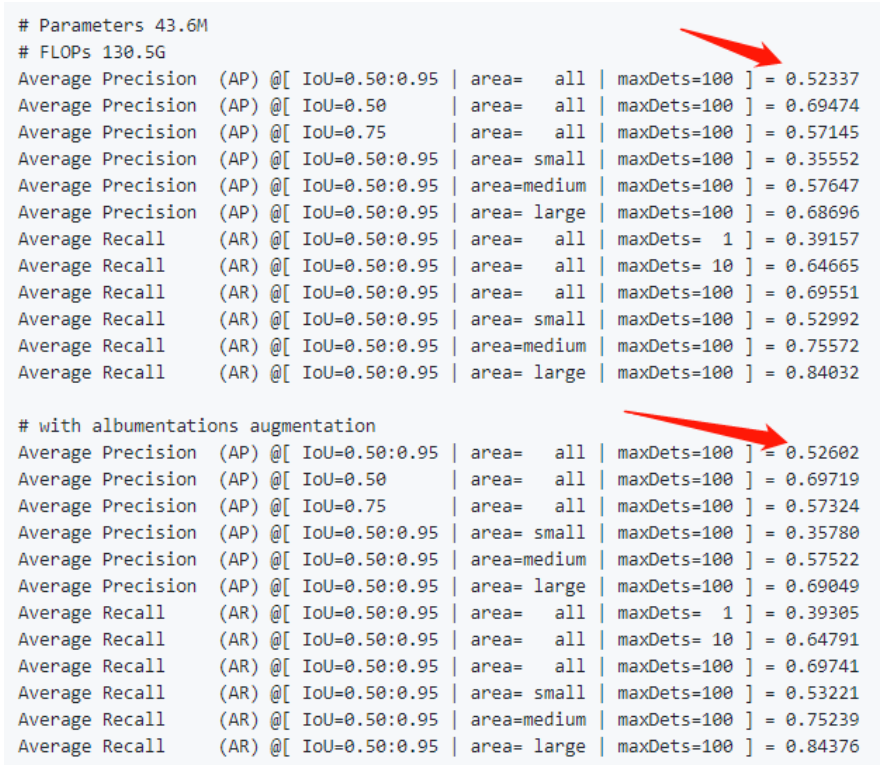
再看原作復現的Anchor-Free版本,相對于原始版本的51.2的精度,分別提升了1.1個點和1.4個點(使用了albumentation數據增強),可以看出還是很給力的結構。
架構改進部分
其實,關于復現的YOLOv7-u6(Anchor-Free),Backbone和Neck部分是沒有發生變化的,下面看一下Head部分的變化。
1、YOLOv7的Anchor-Base Head
通過下圖的YAML知道,YOLOv7的head使用了重參結構,并且也加入了隱藏知識Trick的加入。

2、YOLOv7的Anchor-Free Head
去除了RepConv卷積,使用了最為基本的Conv模塊,同時檢測頭換為了YOLOv6的Head形式,同時加入了IDetect的隱藏知識Implicit層思想。
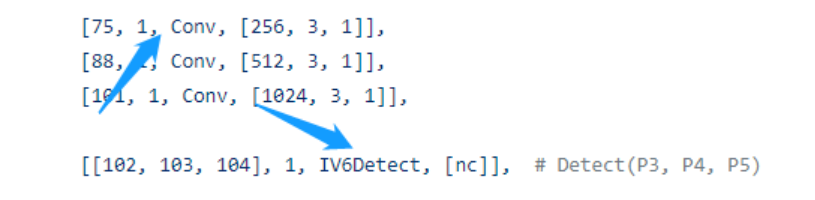
3、IV6Detect的實現如下
classIV6Detect(nn.Module):
dynamic=False#forcegridreconstruction
export=False#exportmode
shape=None
anchors=torch.empty(0)#init
strides=torch.empty(0)#init
def__init__(self,nc=80,ch=(),inplace=True):#detectionlayer
super().__init__()
self.nc=nc#numberofclasses
self.nl=len(ch)#numberofdetectionlayers
self.reg_max=16
self.no=nc+self.reg_max*4#numberofoutputsperanchor
self.inplace=inplace#useinplaceops(e.g.sliceassignment)
self.stride=torch.zeros(self.nl)#stridescomputedduringbuild
c2,c3=max(ch[0]//4,16),max(ch[0],self.no-4)#channels
self.cv2=nn.ModuleList(
nn.Sequential(Conv(x,c2,3),Conv(c2,c2,3),nn.Conv2d(c2,4*self.reg_max,1))forxinch)
self.cv3=nn.ModuleList(
nn.Sequential(Conv(x,c3,3),Conv(c3,c3,3),nn.Conv2d(c3,self.nc,1))forxinch)
#DFL層
self.dfl=DFL(self.reg_max)
#Implicit層
self.ia2=nn.ModuleList(ImplicitA(x)forxinch)
self.ia3=nn.ModuleList(ImplicitA(x)forxinch)
self.im2=nn.ModuleList(ImplicitM(4*self.reg_max)for_inch)
self.im3=nn.ModuleList(ImplicitM(self.nc)for_inch)
defforward(self,x):
shape=x[0].shape#BCHW
foriinrange(self.nl):
x[i]=torch.cat((self.im2[i](self.cv2[i](self.ia2[i](x[i]))),self.im3[i](self.cv3[i](self.ia3[i](x[i])))),1)
box,cls=torch.cat([xi.view(shape[0],self.no,-1)forxiinx],2).split((self.reg_max*4,self.nc),1)
ifself.training:
returnx,box,cls
elifself.dynamicorself.shape!=shape:
self.anchors,self.strides=(x.transpose(0,1)forxinmake_anchors(x,self.stride,0.5))
self.shape=shape
dbox=dist2bbox(self.dfl(box),self.anchors.unsqueeze(0),xywh=True,dim=1)*self.strides
y=torch.cat((dbox,cls.sigmoid()),1)
returnyifself.exportelse(y,(x,box,cls))
defbias_init(self):
m=self#self.model[-1]#Detect()module
fora,b,sinzip(m.cv2,m.cv3,m.stride):#from
a[-1].bias.data[:]=1.0#box
b[-1].bias.data[:m.nc]=math.log(5/m.nc/(640/s)**2)
關于損失函數與樣本匹配的穿搭
一句話吧,其實就是YOLOv8本來的樣子,也可能YOLOv8是原來YOLOv7-u6本來的樣子。使用了TaskAligned Assigner,BCE Loss、CIOU Loss以及DFL Loss。可以說是標準搭配了!!!關于損失函數與樣本匹配的穿搭
classComputeLoss:
def__init__(self,model,use_dfl=True):
device=next(model.parameters()).device#getmodeldevice
h=model.hyp#hyperparameters
#Definecriteria
#分類損失
BCEcls=nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]],device=device),reduction='none')
#Classlabelsmoothinghttps://arxiv.org/pdf/1902.04103.pdfeqn3
self.cp,self.cn=smooth_BCE(eps=h.get("label_smoothing",0.0))#positive,negativeBCEtargets
#Focalloss
g=h["fl_gamma"]#focallossgamma
ifg>0:
BCEcls=FocalLoss(BCEcls,g)
m=de_parallel(model).model[-1]#Detect()module
self.balance={3:[4.0,1.0,0.4]}.get(m.nl,[4.0,1.0,0.25,0.06,0.02])#P3-P7
self.BCEcls=BCEcls
self.hyp=h
self.stride=m.stride#modelstrides
self.nc=m.nc#numberofclasses
self.nl=m.nl#numberoflayers
self.device=device
#正負樣本匹配
self.assigner=TaskAlignedAssigner(topk=int(os.getenv('YOLOM',10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA',0.5)),
beta=float(os.getenv('YOLOB',6.0)))
#回歸損失函數
self.bbox_loss=BboxLoss(m.reg_max-1,use_dfl=use_dfl).to(device)
self.proj=torch.arange(m.reg_max).float().to(device)#/120.0
self.use_dfl=use_dfl
———————End———————
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!
你也可以把文章轉給學校老師等相關人員,讓RT-Thread可以惠及更多的開發者
-
RT-Thread
+關注
關注
31文章
1300瀏覽量
40264
原文標題:【AI周報20230317】 OpenAI公布GPT-4、國內存在哪些算力瓶頸
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
芯片、模型生態分散,無問芯穹、沐曦、壁仞談國產算力瓶頸破局之道

OpenAI揭秘CriticGPT:GPT自進化新篇章,RLHF助力突破人類能力邊界
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯
OpenAI API Key獲取:開發人員申請GPT-4 API Key教程
國內直聯使用ChatGPT 4.0 API Key使用和多模態GPT4o API調用開發教程!

開發者如何調用OpenAI的GPT-4o API以及價格詳情指南





 工商網監
工商網監
評論