 人工智能快速發展趨勢下,中國該如何應對?
人工智能快速發展趨勢下,中國該如何應對?
文心一言 | 機器學習 | ChatGPT
近日,隨著ChatGPT-4和百度的文心一言的出臺,人工智能技術得到迅猛發展。人工智能(AI)是一種模擬人類智能的技術,它可以通過學習和自我改進來執行各種任務。ChatGPT是一種基于AI的聊天機器人,它可以與人類進行自然語言交互,回答問題和提供信息。
人工智能是通過模擬人類大腦的方式來工作的。它使用算法和數據來學習和自我改進,以便更好地執行任務。人工智能可以分為弱人工智能和強人工智能。弱人工智能是指只能執行特定任務的AI,例如語音識別或圖像識別。強人工智能是指可以像人類一樣思考和決策的AI。
2023年政府工作報告指出“過去五年極不尋常、極不平凡,我們經受了世界變局加快演變、新冠疫情沖擊、國內經濟下行等多重考驗,經濟社會發展取得舉世矚目的重大成就。”聚焦到科技領域,“全社會研發經費投入強度從2.1%提高到2.5%以上,科技進步貢獻率提高到60%以上。科技創新成果豐碩,人工智能領域的創新成果也不斷涌現。”
縱覽人工智能產業近年發展,雖然一定程度上突破了深度學習等各類算法革新、技術產品化落地、應用場景打磨、市場教育等難點;但如今也仍需致力解決可信、業務持續、盈利、部署的投資回報率等商業化卡點。
聚焦于2022年,這一歷史上極為重要一年中我國AI產業參與者的特征表現、探討AI產業在我國經濟發展中的價值與地位、洞察各技術賽道參與者的發展路徑與產業進階突破點。

人工智能產業發展環境演變
一、人工智能參與社會建設的千行百業——價值性、通用性、效率化為產業發展戰略方向
人工智能已成為推動產業發展的主流趨勢,其產品形態和應用邊界不斷拓寬,包括軟件服務、云服務、硬件基礎設施等形式,應用場景涵蓋消費、制造業、互聯網、金融、元宇宙和數字孿生等領域。據艾瑞預測,到2022年,我國人工智能產業規模將達到1958億元,同時,人工智能產學研界在通用大模型、行業大模型等方向上取得了一定突破,促進技術通用性和效率化生產。AI技術的商業價值塑造、通用性提升和效率化應用是其助力產業發展、社會進步和自身造血的關鍵。
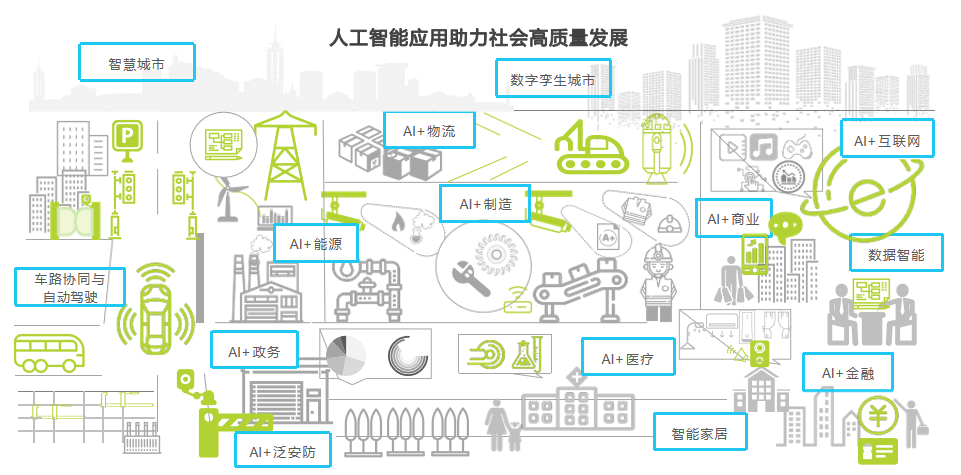
二、企業積極部署AI戰略以實現業務增長——對AI應用的比率及數量持續走高; AI提升營收能力進步
縱觀近五年來的AI技術商業落地發展脈絡,產品及服務提供商圍繞技術深耕、場景創新、商業價值創造、精細化服務不斷努力;需求側企業也在從單點試驗、數據積累到戰略改革的發展路線上,與AI技術逐漸深度綁定。AI成為企業數字化、智能化改革的重要抓手,也是各行業領軍企業打造營收護城河的重要方向。
麥肯錫2022年對企業應用AI技術的調研表明:相較于2017年的20%,2022年企業至少在一個業務領域采用AI技術的比率增加了一倍多,達到50%;應用的AI產品數量也從2018年的平均1.9個增加到2022年的3.8個。除了應用數量上的提升,AI產生的商業價值也不斷增長,企業部署AI的動力顯著。
埃森哲商業研究院針對中國250家領先企業的調研顯示,2018-2021年,企業營收中“由AI推動的份額”平均增加了一倍,預計到2024年將進一步增加至36%。落地AI應用對企業業務運營的商業價值與戰略意義越來越明確。
三、城市算腦建設推動區域發展與產業升級——各地加速布局區域智算中心,夯實AI算力基礎設施
基于對支撐AI應用及研發的智能算力需求擴大、以及全國算力樞紐一體化和“東數西算”的工程建設方向。近兩年來,各地對人工智能計算/超算中心(智算中心)的關注度和投資增多。智算中心是指基于最新AI理論,采用領先的AI計算架構,提供AI應用所需算力服務、數據服務和算法服務的公共算力新型基礎設施。目前,我國有超過30個城市建設或提出建設智算中心,其中已有近10個城市的智算中心投入運營,為當地各行業領域提供算力支撐。智算中心建設對區域經濟發展和產業升級有明顯推動作用,同時可提高城市治理智能化水平和城市競爭力。從政府投資角度看,智算中心產業發展尚處于初期階段,建設、運營、應用推廣與生態建設、節能環保要求等投入較大,需結合地方財政能力合理評估,根據實際需求適度超前部署機柜。
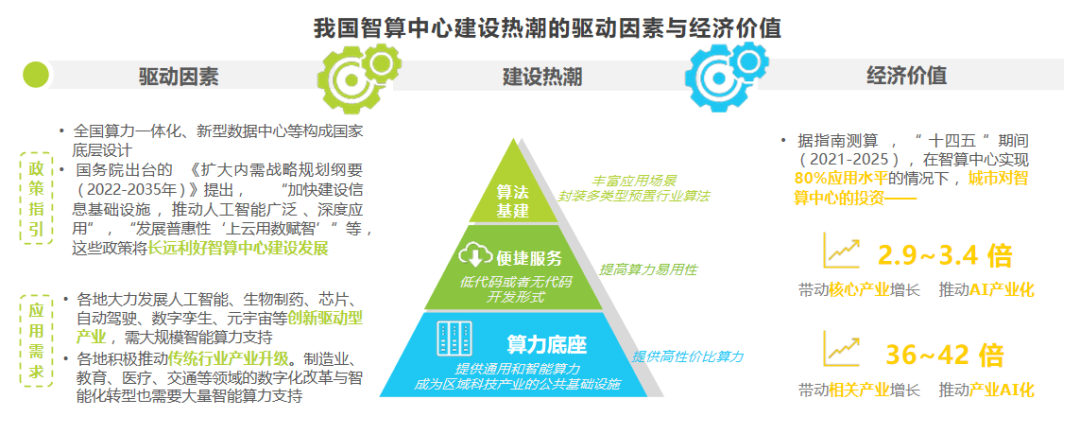
四、政策引導解決AI重大應用和產業化問題——著力打造人工智能重大場景,形成可復制推廣的標桿應用
盡管我國在數據、算力、算法及模型的基礎層資源與研究積累日益豐富,為開展下游人工智能場景創新應用打下了堅實基礎,但在應用場景上仍存在“對場景創新認識不到位,重大場景系統設計不足,場景機會開放程度不夠,場景創新生態不完善”等問題。為此,2022年,我國陸續出臺一系列指導意見及通知,持續加強對人工智能場景創新工作的統籌指導,規范與加強人工智能應用建設,實現AI與實體產業經濟的深度融合。其中,政策引導是解決AI重大應用和產業化問題的重要手段之一。著力打造人工智能重大場景,形成可復制推廣的標桿應用,是政策引導的重要方向之一。通過政策引導,加強對人工智能場景創新工作的統籌指導,規范與加強人工智能應用建設,將有助于實現AI與實體產業經濟的深度融合。
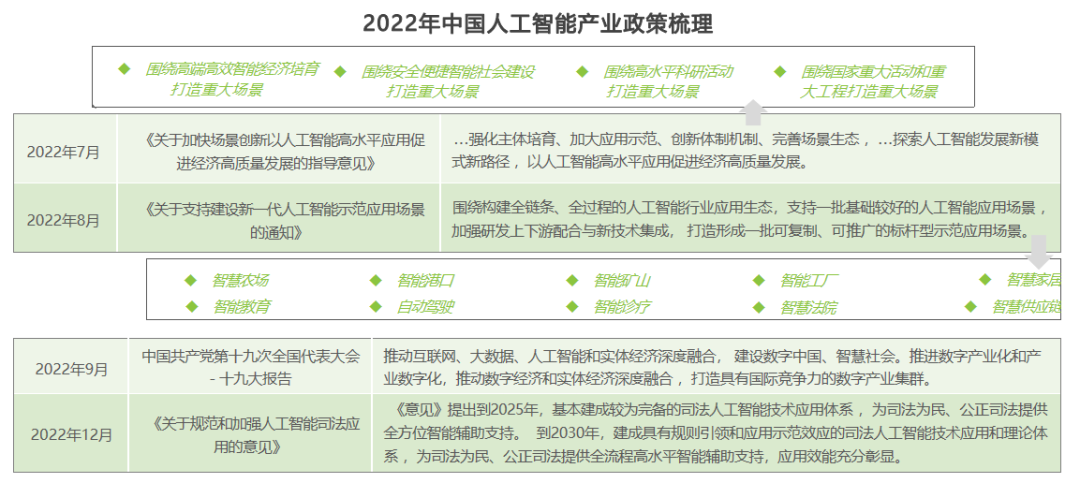
五、科技倫理治理持續引導AI “向善”——全球AI倫理治理邁入法治時代,我國積極倡導框架規范
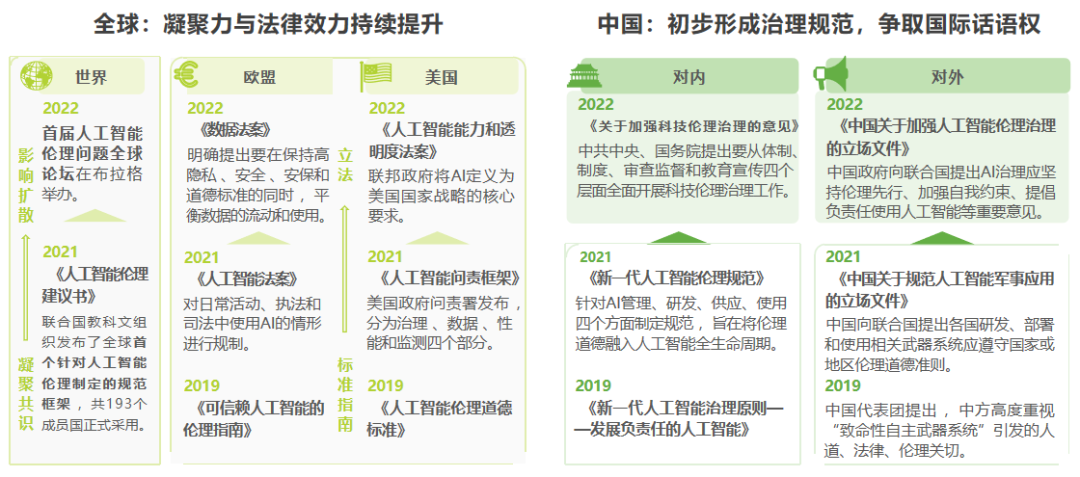
隨著人工智能與社會產業的融合應用,其帶來的安全、法律和倫理方面的風險不容忽視。2022年,科技倫理治理的約束力和影響力持續提升。從全球范圍來看,主要發達國家和地區的人工智能倫理治理從政策建議正式進入法律范疇,相關立法逐步完善,國際組織也在凝聚共識的基礎上,啟動大規模深入研討。而在中國,在吸取發達國家治理經驗和思路的基礎上,2022年首次將人工智能倫理治理上升到國家政策層面,提出科技倫理治理的原則和行動方案,具體治理舉措將會不斷細化和完善。同時,我國也在科技倫理問題上通過國際組織積極表態,增強國際影響力和話語權,防止在科技倫理問題上陷入被動。
六、人工智能產業投資熱度仍在——融資向中后期過渡,視覺賽道上市浪潮涌動
人工智能產業一直是投資市場的熱門領域,而最近的數據顯示,這一趨勢仍在持續。統計數據顯示,Pre-A~A+輪人工智能產業創投輪次數量最多,但整體而言,Pre-B~B輪+及以后輪次的人工智能產業創投數量逐漸成長,資本流向穩定發展企業,融資逐漸向中后期過渡。此外,視覺賽道上市浪潮也在涌動,商湯科技、格靈深瞳、云從科技、創新奇智等企業都已實現上市目標。雖然2022年我國人工智能產業資本市場投資金額整體縮水,但投資標的更加豐富,孵化出AIGC、元宇宙、虛擬數字人等新投資賽道,認知與決策智能類企業也吸引更多關注,智能機器人、自動駕駛兩類無人系統是融資的熱門賽道。
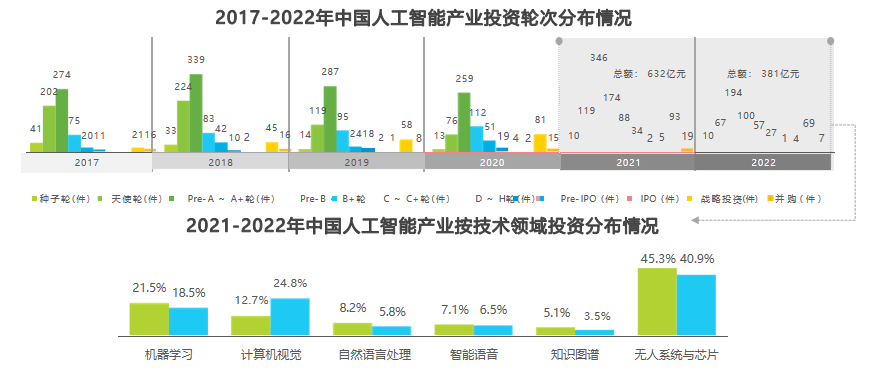
七、區域與獨角獸企業融資分布特點——北上廣與江浙地帶融資密度高;獨角獸企業聚集于自動駕駛、醫療、工業、芯片賽道
從區域分布看,統計時間內融資事件集中分布于北上廣、江浙地帶。北京的融資事件密度最高,融資事件數量占全國的31.1%。除北上廣、江浙地帶以外區域融資密度較低且分散,相應融資事件數量占全國不超過10%。這可能是因為北上廣、江浙地帶人工智能人才密集、具備產業園區進行產學研成果轉化、風投機構密布等因素,為孵化創投項目提供了有利條件。
從獨角獸企業融資情況看,統計時間內獨角獸企業占比6.7%,但對應的融資金額比例高達32.3%。獨角獸融資事件集中分布于自動駕駛、醫療、工業、芯片行業賽道,分別孵化出L3及以上智能駕駛解決方案、AIDD藥物研發服務、工業機器人、云端大規模訓練或端側推理芯片等產品或服務。隨著市場資金向獨角獸企業持續流入,AI產業未來或將逐步出現一批明星上市企業。
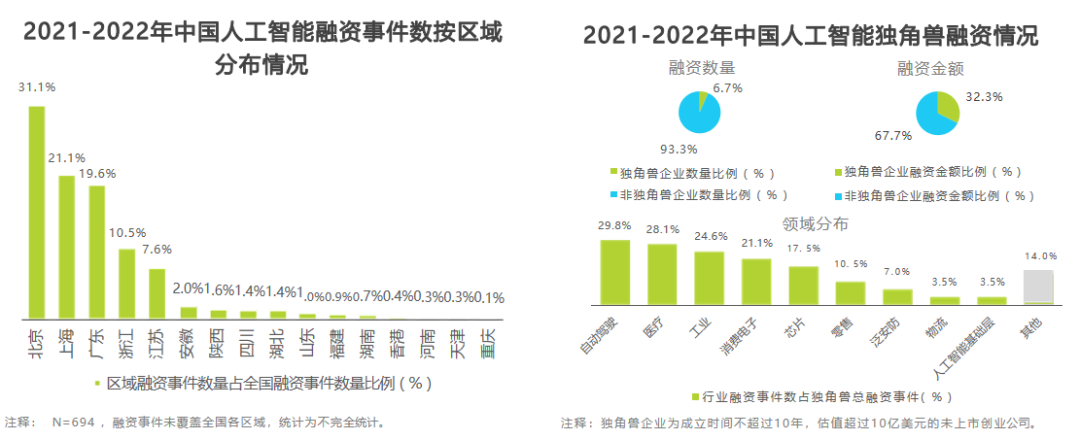
八、人工智能產業市場規模——2022年市場平穩向好,市場規模近2000億元
根據艾瑞的定義,我國人工智能產業規模涵蓋AI應用軟件、硬件及服務,主要包括AI芯片、智能機器人(商用)、AI基礎數據服務、面向AI的數據治理、計算機視覺、智能語音與人機交互、機器學習、知識圖譜和自然語言處理等核心產業。預計到2022年,中國人工智能產業規模將達到1958億元,年增長率為7.8%,整體平穩向好。2022年的業務增長主要依靠智算中心建設以及大模型訓練等應用需求拉動的AI芯片市場、無接觸服務需求拉動的智能機器人及對話式AI市場,除此之外的增長動力將在第三章詳細闡述。目前,中國大型企業基本都已在持續規劃投入實施人工智能項目,未來隨著中小型企業的普遍嘗試和大型企業的穩健部署,在AI成為數字經濟時代核心生產力的背景下,AI芯片、自動駕駛及車聯網視覺解決方案、智能機器人、智能制造、決策智能應用等細分領域增長強勁。預計到2027年,人工智能產業整體規模可達6122億元,2022-2027年的相關CAGR為25.6%。
人工智能的底層基礎
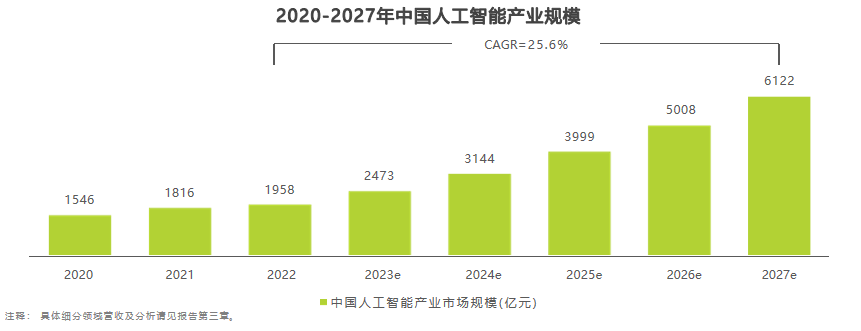
一、AI芯片
1、AI芯片針對機器學習算法設計開發,廣泛應用于云、邊、端各類場景
AI芯片(AI Chip)是一種專門用于處理人工智能相關的計算任務的芯片。它的架構是專門為人工智能算法和應用進行優化的,能夠高效地處理大量結構化和非結構化數據。AI芯片能夠高效地支持視覺、語音、自然語言處理等智能處理任務。目前,AI芯片主要分為GPU、FPGA、TPU、IPU、DPU、NPU等類型。AI芯片廣泛應用于云端、邊緣端、終端等各種場景。云端AI芯片具有高性能特征,終端AI芯片具有低功耗和高能效特性,而邊緣端AI芯片的性能介于云端和終端之間。
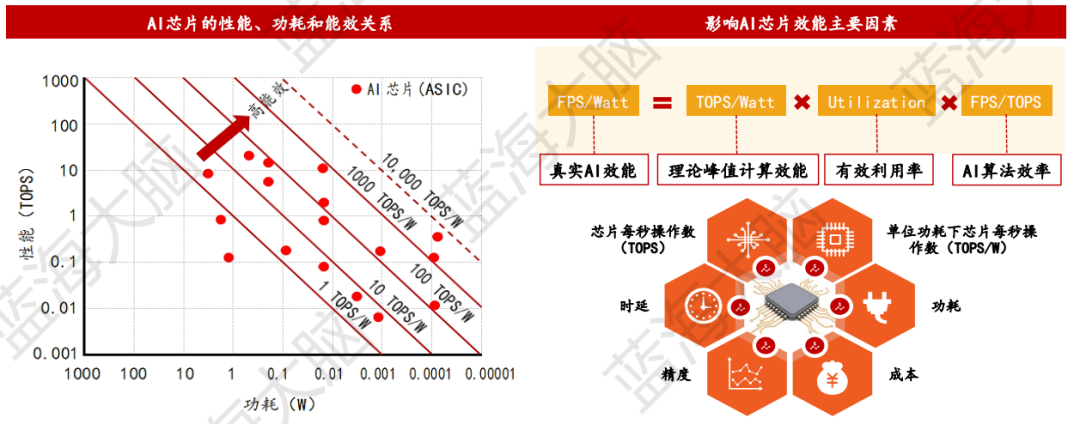
2、AI芯片性能指標評價評價AI芯片性能需重點關注TOPS/W、時延、功耗等相關指標
目前,評價AI芯片性能的指標主要包括TOPS、TOPS/W、時延、成本、功耗、可擴展性、精度、適用性、吞吐量和熱管理等。其中,TOPS/W是用于度量在1W功耗的情況下,芯片能進行多少萬億次操作的關鍵指標。近年來,MIT、Nvidia等研發人員開發了專門的芯片軟件評價工具,如Accelergy(評估芯片架構級能耗)和Timeloop(評估芯片運算執行情況),對于AI芯片的性能做出了系統、全面評價。此外,MLPerf是由來自學術界、研究實驗室和相關行業的AI領導者組成的聯盟,旨在“構建公平和有用的基準測試”,可用于衡量深度學習軟件框架、AI芯片和云平臺性能。
3、AI芯片:云端場景數據中心
1)GPU具備矩陣和大規模并行計算優勢,適合數據中心場景
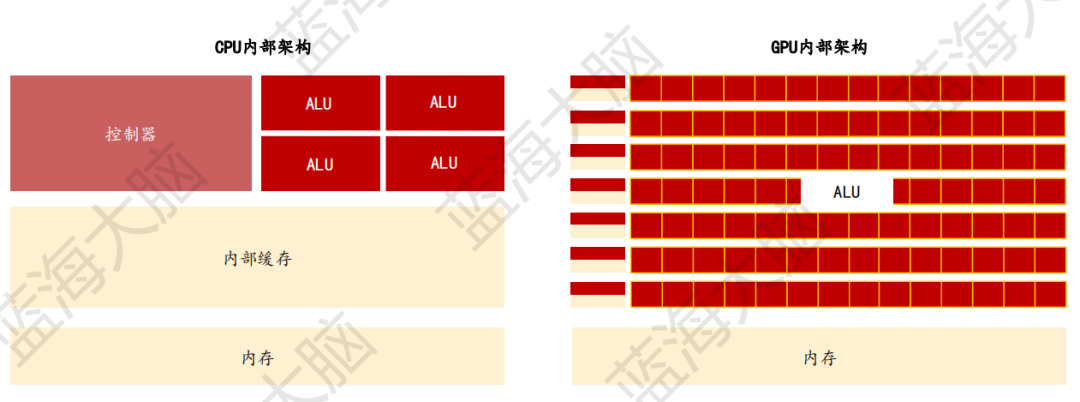
CPU是一種通用處理器,它由控制單元(負責指令讀取和指令譯碼)、存儲單元(包括CPU片內緩存和寄存器)以及運算單元(ALU約占20%CPU空間)三個主要模塊組成。然而,由于成本、功耗、技術難度和算力瓶頸等問題的限制,目前還沒有出現適用于AI高算力要求的主流CPU產品。
相比之下,GPU是一種由大量核心組成的大規模并行計算架構,它具有較多的運算單元(ALU)和較少的緩存(cache),是專門為同時處理多重任務而設計的芯片。GPU擁有良好的矩陣計算能力和并行計算優勢,能夠滿足深度學習等AI算法的處理需求,因此成為主流云端AI芯片。
2)張量計算單元是GPU進行深度學習運算的核心組成部分
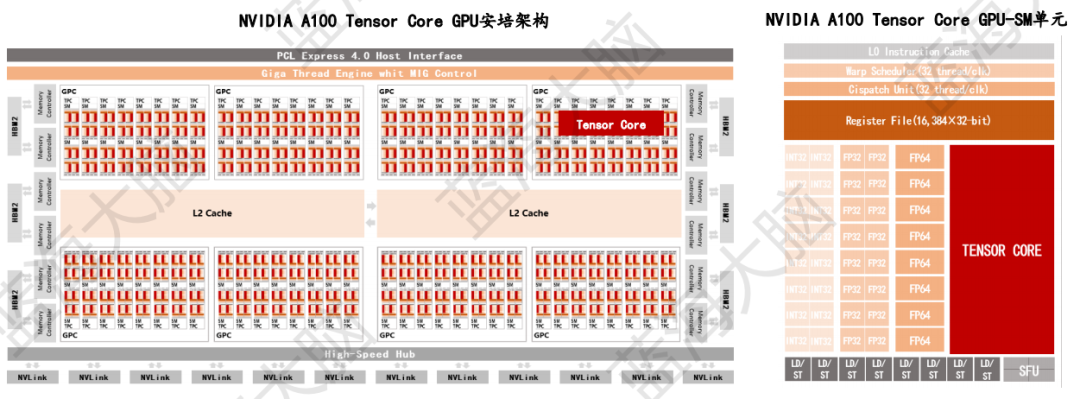
英偉達A100芯片是一種并發多核處理器,由多個SM單元(Streaming Multiprocessors,流式多處理器)構成。不同的SM單元共享L2 Cache存儲資源,以便進行數據訪問。該芯片采用安培架構,擁有128個SM核,其中SM結構是芯片架構升級的核心。此外,英偉達GPU架構中還設置了Tensor Core,這是專為深度學習矩陣運算設計的張量計算單元,也是英偉達GPU系列深度學習運算加速的核心。Tensor Core主要處理大型矩陣運算,執行一種專門的矩陣數學運算,適用于深度學習和某些類型的高性能計算。其功能是執行融合乘法和加法的運算,其中兩個4*4 FP16矩陣相乘,然后將結果添加到4*4 FP32或FP64矩陣中,最終輸出新的4*4 FP32或FP64矩陣。
4、邊緣端場景—AIoT。邊緣端集成AI芯片可以實現本地化數據的實時處理
AIoT是一種融合了人工智能和物聯網技術的新型智能化系統,它可以實現萬物智聯,涉及到安防、移動互聯網等多種場景。在智慧安防方面,由于終端攝像頭每天產生大量的視頻數據,若全部回傳到云數據中心將會對網絡帶寬和數據中心資源造成極大占用。為了解決這個問題,可以在終端加裝AI芯片,實現數據本地化實時處理,即僅將經過結構化處理、關鍵信息提取后帶有關鍵信息的數據回傳云端,從而大大降低網絡傳輸帶寬壓力。目前,主流解決方案是在前端攝像頭設備內集成AI芯片,在邊緣端采用智能服務器級產品,后端在邊緣服務器中集成智能推理芯片。為了推動這項技術的發展,國內外企業正在加大對邊緣端AI視覺處理芯片的研發和投入,相關芯片產品如英偉達Jetson AGX Xavier、地平線旭日3、華為海思Hi3559A V100等。

5、終端場景—智能駕駛。隨著智能駕駛等級的提高,技術不斷迭代促使車用AI芯片性能逐步增強
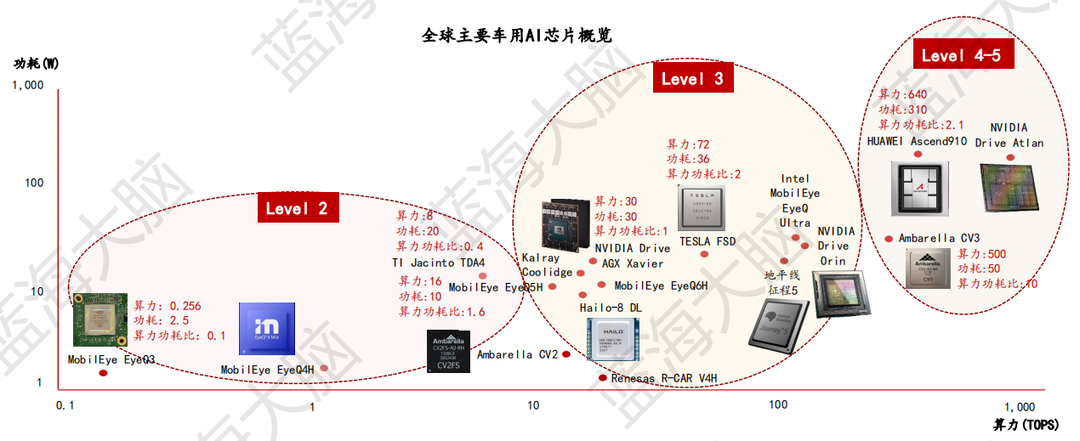
SAE(國際自動機工程師學會)將自動駕駛分為六個級別,從L0(非自動化)到L5(完全自動化)。每一級別需要強大的算力進行實時分析、處理大量數據和執行復雜的邏輯運算,對計算能力有著極高的要求。L1(駕駛員輔助)和L2(部分自動化)需要的計算能力相對較低,而L3(有條件自動化)需要約250TOPS的計算能力,L4(高度自動化)需要超過500TOPS,L5(全場景自動駕駛)需要超過1,000TOPS。隨著芯片設計和制造工藝的提高,車用AI芯片正朝著高算力、低功耗的方向發展。
6、終端場景—智能駕駛。預計到2025年,全球車用AI芯片市場規模將突破17億美元
隨著汽車控制方式逐漸由機械式轉向電子式,每輛汽車對車用AI芯片需求提升,帶動車用AI芯片長期發展。據市場研究機構Yole預測,到2025年,全球車用AI芯片產量將達到67.19億顆,市場規模將達到17.76億美元,年復合增速分別達到99.28%和59.27%。此外,車用AI芯片逐漸往高能效方向發展。例如,英特爾計劃于2022年推出EyeQ Ultra自動駕駛汽車芯片,該芯片基于經過驗證的Mobileye EyeQ架構而打造,含有8個PMA、16個VMP、24個MPC、2個CNN Accelerator視覺處理單元(VPU),通過優化算力和效能以達到176TOPS,可滿足L4自動駕駛場景。該產品將于2023年底供貨,預計在2025年全面實現車規級量產。

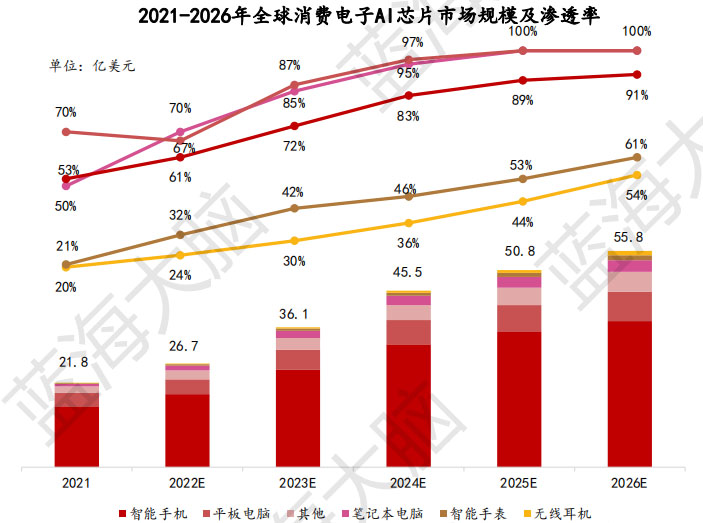
7、終端場景—消費電子。2026年全球消費電子AI芯片市場規模將突破55億美元
AI芯片在圖像識別、語音識別和快速建立用戶畫像等方面具有重要作用。根 據Yole預測,2026年全球消費電子AI芯片市場規模將達到55.8億美元,其中筆記本電腦、平板電腦和智能手機AI芯片滲透率將分別達到100%、100%和91%, 未來全球消費電子AI芯片市場規模和滲透率呈現逐步增長態勢。
二、深度學習開源框架
深度學習開源框架是一種標準接口、特性庫和工具包,用于設計、訓練和驗證AI算法模型。它們集成了數據調用、算法封裝和計算資源的使用,是AI開發的重要工具。目前,國際上廣泛使用的深度學習開源框架包括Google TensorFlow、Facebook PyTorch、Amazon MXNet和微軟CNTK等。在中國,也有一些深度學習開源框架,如百度PaddlePaddle、華為MindSpore等。這些框架已經初步應用于工業、服務業等場景,服務200余萬開發者。

三、數據服務以AI訓練與調優為目的,涉及數據采集、標注與質檢等環節
人工智能數據服務是指提供數據庫設計、數據采集、數據清洗、數據標注和數據質檢等服務,以滿足客戶的需求。這個服務流程是圍繞客戶需求展開的,最終產出的產品是數據集和數據資源定制服務,為AI模型訓練提供可靠、可用的數據。隨著短視頻、直播、社交電商等應用的快速興起,全球數據量也在快速增長。根據IDC的預測,全球數據量將從2015年的9ZB增加到2025年的175ZB,這為人工智能技術的持續迭代提供了重要的底層基礎。

四、云計算服務顯著降低人工智能算法開發成本,縮短產品開發周期
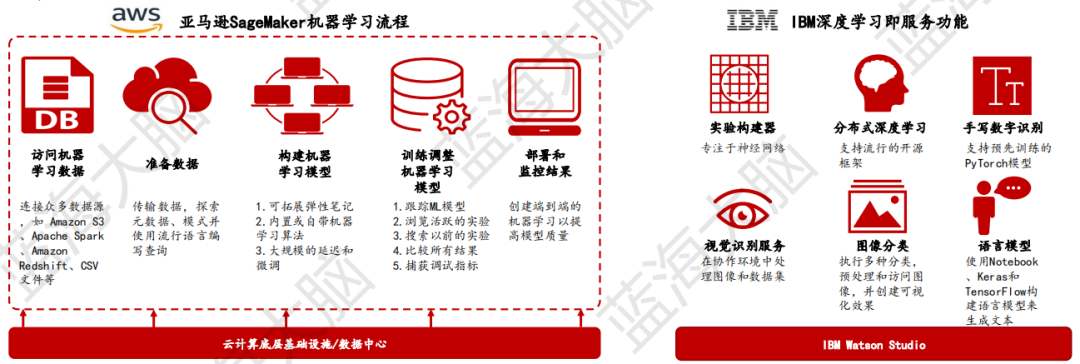
由于人工智能的開發和應用對于算力和數據有較大需求,云計算服務可以為開發者提供智能服務器集群等強大算力設施的租用。同時,云計算服務還可以直接提供已經訓練好的人工智能功能模塊等產品,通過多元化的服務模式,降低開發者的開發成本和產品開發周期,為客戶提供AI賦能。
例如,亞馬遜SageMaker可以提供圖片/圖像分析、語音處理、自然語言理解等相關服務。使用者無需了解參數和算法即可實現功能的應用。隨著底層技術的發展,IBM推出深度學習即服務(DLaaS),借助此項服務用戶可以使用主流框架來訓練神經網絡,如TensorFlow、PyTorch及Caffe。用戶無需購買和維護成本高昂的硬件,每一個云計算處理單元都遵循簡單易用的原則而設置,無需用戶對基礎設施進行管理。用戶可以根據支持的深度學習框架、神經網絡模型、訓練數據、成本約束等條件進行挑選,然后DLaaS服務會幫助完成其余的事情,提供交互式、可迭代的訓練體驗。
人工智能的核心技術
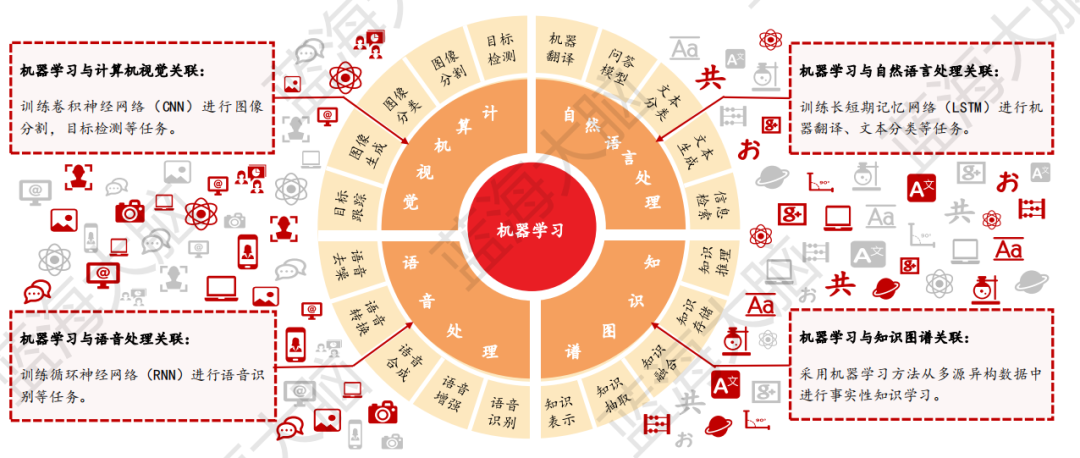
機器學習作為人工智能技術的核心,近年來實現了明顯的突破。它與計算機視覺、自然語言處理、語音處理和知識圖譜等關鍵技術緊密結合,相關機器學習算法主要應用于圖像分類、語音識別、文本分類等相關場景中。這些應用場景的不斷發展和完善,不僅提升了人工智能技術的整體應用效果,也使得人工智能技術在金融、醫療、交通等各領域實現了廣泛的應用。
一、機器學習
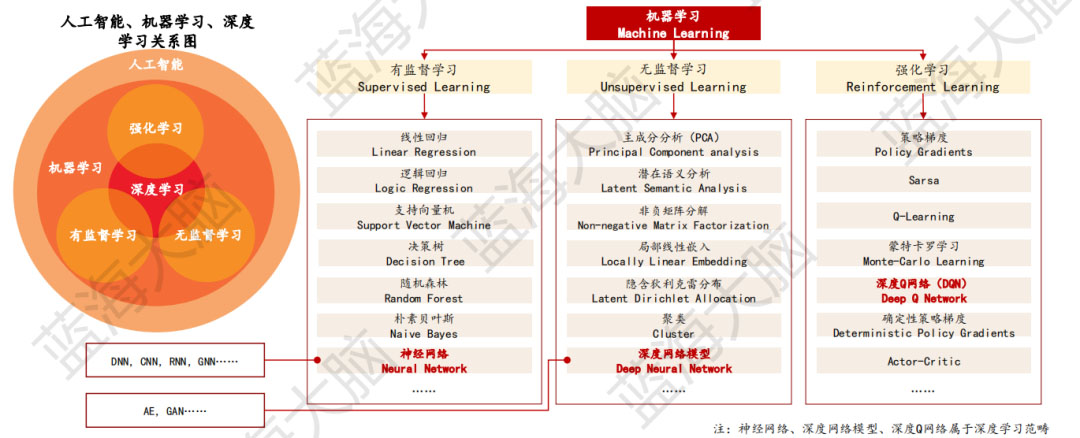
機器學習是實現人工智能的核心方法,專門研究計算機如何模擬/實現生物體的學習行為,獲取新的知識技能,利用經驗來改善特定算法的性能。根據學習范式的不同,機器學習可劃分為有監督學習、無監督學習、強化學習三類。有監督學習是指通過給計算機提供標注數據,讓計算機學習如何將輸入映射到輸出的過程。無監督學習則是指在沒有標注數據的情況下,讓計算機自行學習數據的特征和結構。強化學習則是通過讓計算機在與環境的交互中不斷試錯,從而學習如何最大化獎勵的過程。深度學習是機器學習算法的一種,具有多層神經網絡結構,其在圖像識別、語音處理等領域取得了劃時代的成果。
1、有監督學習:從有標注訓練數據中推導出預測函數
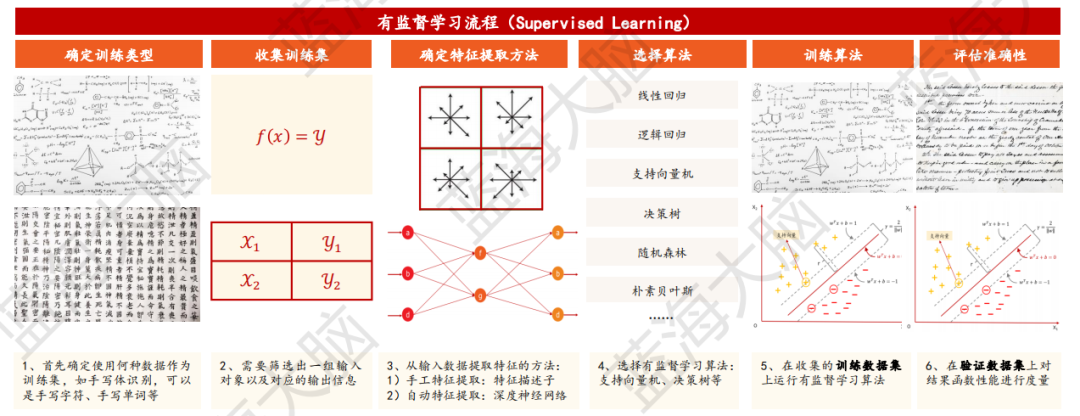
有監督學習是機器學習任務的一種類型,其目的是從給定的訓練數據集中學習出一個函數(模型參數),以便在新的數據到來時,能夠根據該函數預測結果。訓練集中包括輸入和輸出,也稱為特征和目標,其中目標是由人工標注的。有監督學習的過程一般包括確定訓練類型、收集訓練集、確定特征提取方法、選擇算法、訓練算法、評估準確性六個環節。通過已有的訓練樣本去訓練得到一個最優模型,再利用該模型將所有的輸入映射為相應的輸出,從而實現分類目的。
1)邏輯回歸
邏輯回歸是一種用于學習某事件發生概率的算法,它可以對某個事件的發生或不發生進行二元分類。邏輯回歸使用 Sigmoid 函數來輸出結果,其輸出結果的范圍在 [0,1] 之間。邏輯回歸的主要目標是發現特征與特定結果可能性之間的聯系。例如,我們可以使用邏輯回歸來根據學習時長來預測學生是否通過考試,其中響應變量為“通過”和“未通過”考試。

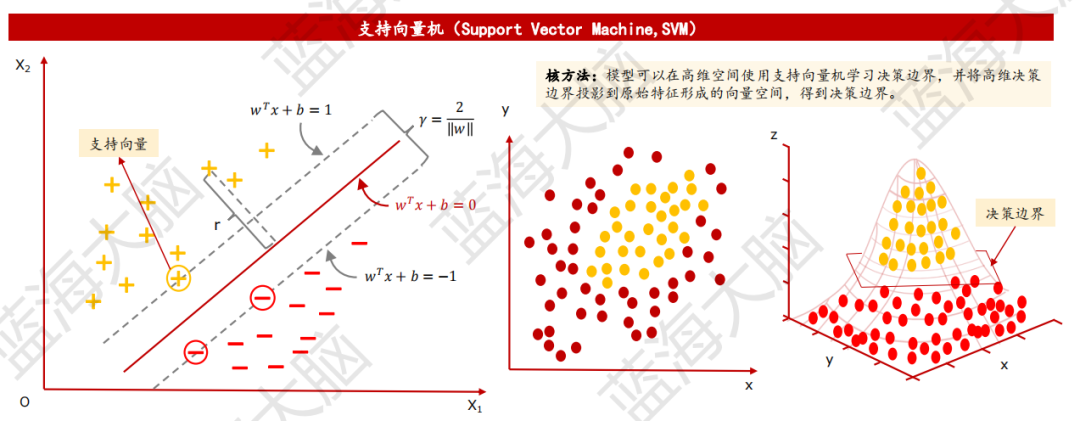
2)支持向量機:以間隔最大化為基準學習遠離數據的決策邊界
支持向量機(Support Vector Machine,SVM)是一種基于間隔最大化的決策邊界算法。其主要目的是學習一個盡可能遠離數據的決策邊界,以確保分類的準確性。在SVM中,支持向量是決策邊界的重要數據點,其位置對于分類結果具有重要的影響。
當訓練樣本線性可分時,SVM采用硬間隔最大化的方法學習線性可分支持向量機;當訓練樣本近似線性可分時,SVM采用軟間隔最大化的方法學習線性支持向量機。在解決線性不可分問題時,SVM引入核函數,將數據映射到另一個特征空間,然后進行線性回歸。通過采用核方法的支持向量機,原本線性不可分的數據在特征空間內變為線性可分,從而實現了分類的準確性。
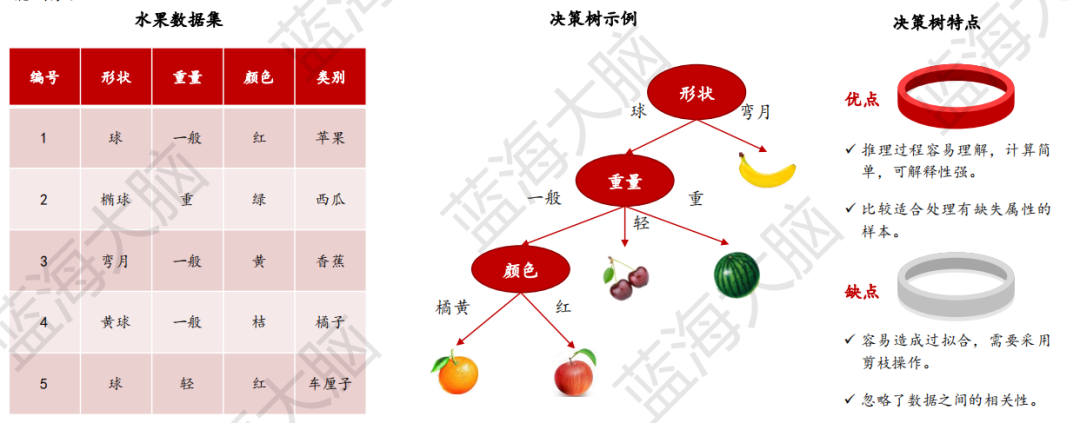
3)決策樹:以樹結構形式表達的預測分析模型
決策樹是一種樹狀結構,用于對數據進行劃分。它通過一系列決策(選擇)來劃分數據,類似于針對一系列問題進行選擇。一棵決策樹通常包含一個根節點、若干個內部節點和若干個葉節點。每個內部節點表示一個屬性上的測試,每個分支代表一個測試輸出,每個葉節點代表一種類別。
決策樹的生成是一個遞歸過程。在決策樹基本算法中,有三種情況會導致遞歸返回:
當前節點包含的樣本全屬于同一類別,無需劃分。
當前屬性集為空或是所有樣本在所有屬性上取值相同,無法劃分。
當前節點包含的樣本集合為空,不能劃分。
這些情況都是決策樹生成過程中的終止條件。
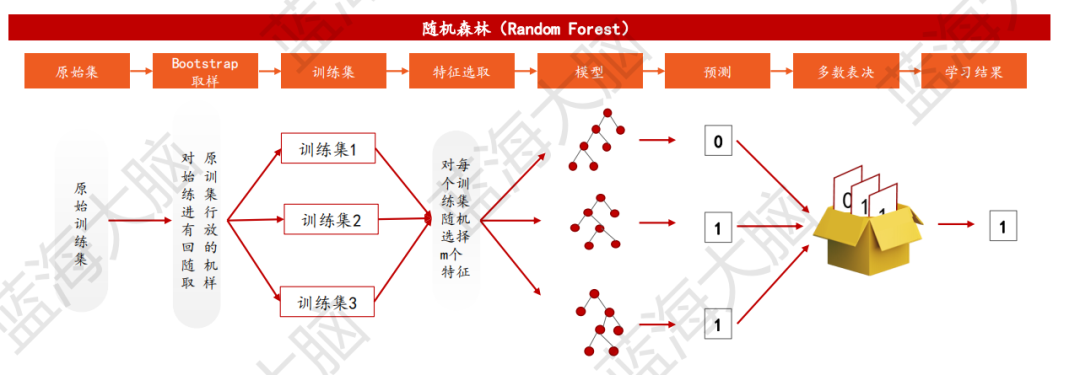
4)隨機森林:利用多決策樹模型,提高模型預測精度
隨機森林是一種分類器,它利用多棵決策樹對樣本進行訓練和預測。在隨機森林算法中,每個決策樹的輸出被收集起來,通過多數表決的方式得到最終的分類結果。這種方法類似于找人商量事情,不只聽一個人的意見,而是在聽取多人意見后綜合判斷。隨機森林的每棵樹都是通過以下步驟生成的:
從訓練集中隨機且有放回地抽取N個訓練樣本,作為該樹的訓練集,重復K次,生成K組訓練樣本集;
從M個特征中隨機選取m個特征,其中m<
利用m個特征實現每棵樹最大程度的生長,并且沒有剪枝過程。
這種方法可以有效地避免過擬合問題,并且在處理大型數據集時表現良好。
5)樸素貝葉斯是常用于自然語言分類問題的算法
樸素貝葉斯是一種基于概率進行預測的算法,主要用于分類問題。在實踐中,它被廣泛應用于文本分類和垃圾郵件判定等自然語言處理領域。具體來說,該算法通過計算數據為某個標簽的概率,將其分類為概率值最大的標簽。例如,假設訓練數據類別為電影(包括那部讓人感動的電影名作重映、華麗的動作電影首映和復映的名作感動了世界),訓練數據類別為宇宙(包括沙塵暴籠罩著火星、火星探測終于重新開始和VR中看到的火星沙塵暴讓人感動),而驗證數據為“復映的動作電影名作讓人感動”。在這種情況下,樸素貝葉斯算法將通過計算“復映的動作電影名作讓人感動”屬于電影或宇宙的概率,來判斷該數據屬于哪個類別。以下為樸素貝葉斯算法過程:
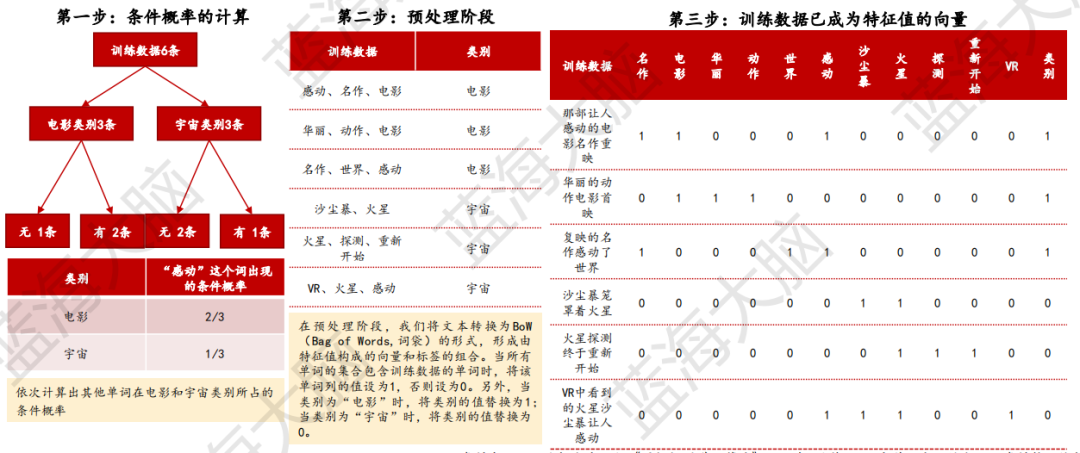
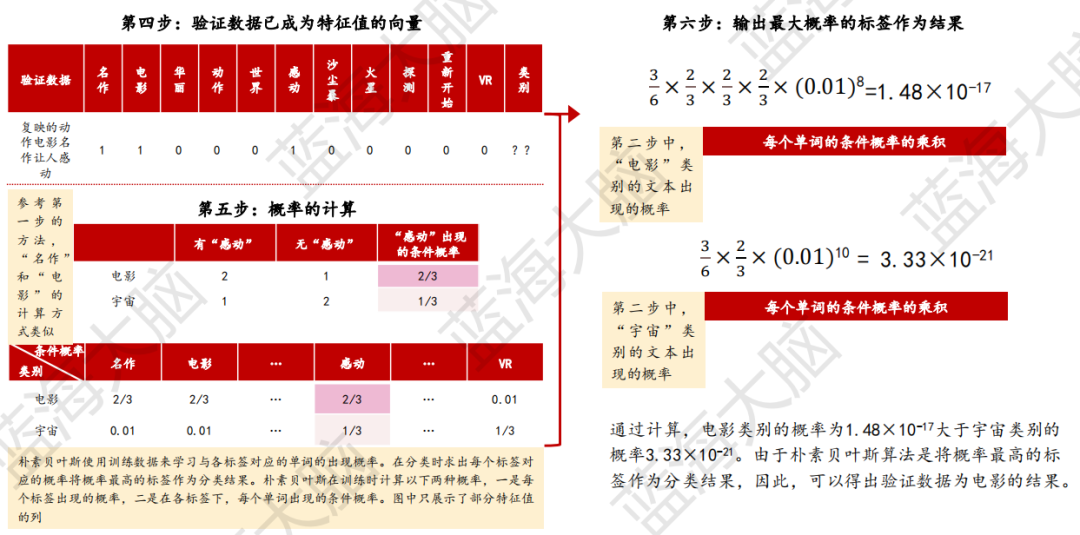
2、無監督學習:對無標簽樣本進行學習揭示數據內在規律
無監督學習是一種機器學習方法,其主要目的是在沒有標記的訓練數據的情況下生成模型。這種方法通常用于缺乏足夠的先驗知識難以進行人工標注類別或進行人工類別標注成本高的情況下。無監督學習的目標是通過對無標簽樣本的學習來揭示數據的內在特性及規律。該方法主要涉及聚類和降維問題。聚類問題包括K-means聚類、概念聚類、模糊聚類等算法,其目標是為數據點分組,使得不同聚類中的數據點不相似,同一聚類中的數據點則是相似的。降維問題主要是主成分分析、線性判別分析、多維尺度分析等算法,其中主成分分析將數據中存在的空間重映射成一個更加緊湊的空間,此種變換后的維度比原來維度更小。無監督學習適用于發現異常數據、用戶類別劃分、推薦系統等場景。
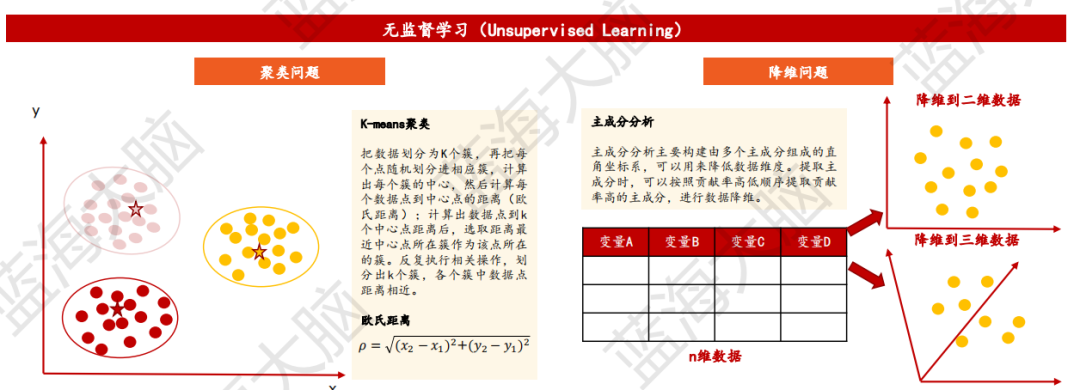
1)策略梯度:有效處理高維及連續動作空間問題
策略梯度(Policy Gradient,PG)是一種基于策略優化的強化學習算法。在強化學習中,機器通過判斷在特定狀態下采取不同動作所得環境回報大小來評價采取該動作的優劣。PG的核心思想是,當一個動作的環境回報較大時,增加其被選擇的概率;反之,減少該動作被選擇的概率。每個動作選擇概率由神經網絡決定,以參數化神經網絡表示策略
審核編輯黃宇
-
芯片
+關注
關注
455文章
50816瀏覽量
423627 -
AI
+關注
關注
87文章
30896瀏覽量
269088 -
人工智能
+關注
關注
1791文章
47279瀏覽量
238499 -
機器學習
+關注
關注
66文章
8418瀏覽量
132635 -
深度學習
+關注
關注
73文章
5503瀏覽量
121162
發布評論請先 登錄
相關推薦
2016年,十大關于人工智能與機器人的發展趨勢
官方推薦2019第二十二屆中國人工智能產業博覽會
人工智能語音芯片行業的發展趨勢如何?
人工智能和機器學習技術在2021年的五個發展趨勢
目前人工智能教育研究最深入最經典的白皮書:德勤《全球人工智能發展白皮書2019》精選資料分享
人工智能芯片是人工智能發展的
人工智能行業應用及產業發展趨勢詳解






 工商網監
工商網監
評論