") GTC 2023看點:深度學(xué)習(xí)系統(tǒng)Colossal-AI試圖解決什么問題
GTC 2023看點:深度學(xué)習(xí)系統(tǒng)Colossal-AI試圖解決什么問題
在GTC 2023 | NVIDIA開發(fā)者大會上,加州伯克利數(shù)學(xué)與計算機科學(xué)的教授向我們介紹了關(guān)于深度學(xué)習(xí)系統(tǒng)Colossal-AI的相關(guān)內(nèi)容。
深度學(xué)習(xí)系統(tǒng)Colossal-AI使用戶能夠以大幅降低成本的方式最大限度地提高AI訓(xùn)練和推理的效率。它集成了高效的多維并行、異構(gòu)內(nèi)存管理、自適應(yīng)任務(wù)調(diào)度等先進技術(shù)。
Colossal-AI將更好地了解大型模型訓(xùn)練和推理背后的并行性和內(nèi)存優(yōu)化技術(shù),學(xué)習(xí)深度學(xué)習(xí)系統(tǒng)的實際應(yīng)用(包括自然語言處理、計算機視覺、生物信息學(xué)等),并能夠為未來的大型 AI 模型時代做出貢獻。
Colossal-AI系統(tǒng)試圖解決什么問題呢?
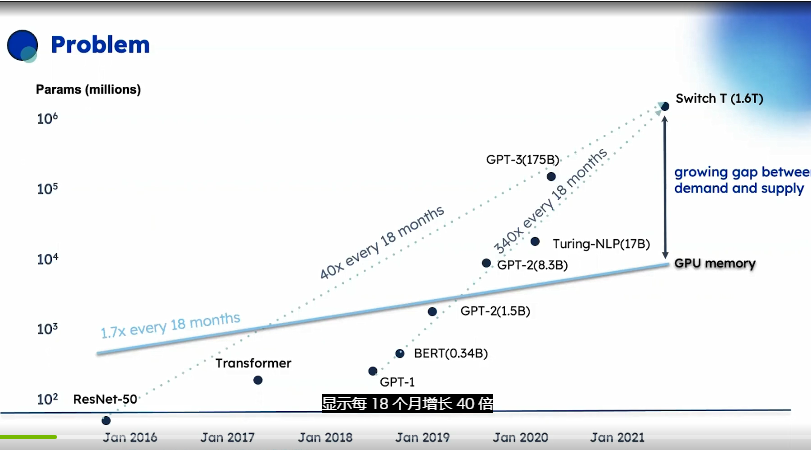
主流AI模型大小增長的圖表,它顯示了AI模型在短短幾年內(nèi)增長的速度,每18個月增長40倍,這超過了摩爾定律在其具盛時期的最佳表現(xiàn)。
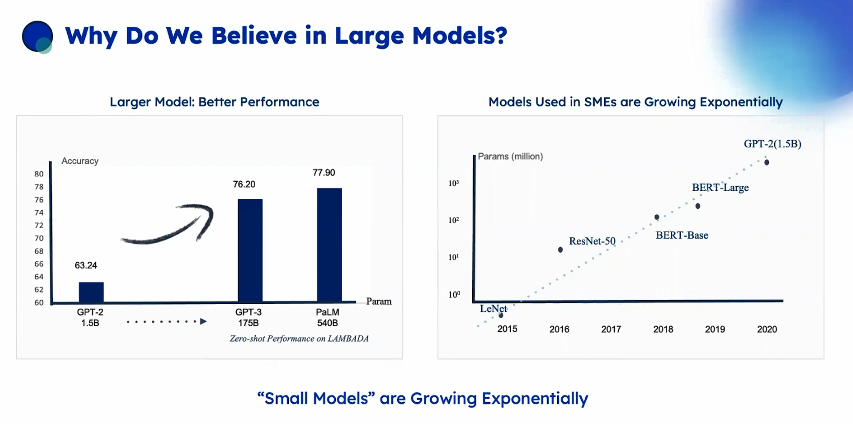
小型和中型企業(yè)( SMEs )在盡可能地在采用它們,Colossal-Al系統(tǒng)在2026年時可以幫你節(jié)省的成本的估計訓(xùn)練175B參數(shù)GPT-3模型,利用所有這些硬件特性和變化,估計訓(xùn)練成本從300降至73000美元,約為41倍。
強調(diào)大規(guī)模并行是必不可少的,使用單個A 100 GPU訓(xùn)練具有540B參數(shù)的Pal M語言模型的時間和成本,需要300年并且花費920萬美元。
隨著新數(shù)據(jù)的不斷出現(xiàn),他們需要反復(fù)的新訓(xùn)練以避免像2019年的GPT-2一樣無法識別COVID-19等概念。
訓(xùn)練完成之后,僅使用模型進行推理也是項挑戰(zhàn),因為模型的大小需要并行技術(shù),單個服務(wù)器的內(nèi)存可能無法容納大模型。除了設(shè)備成本之外,還有人力成本支付需要解決所有這些問題的專家團隊,這就限制了一些公司特別是無法承受這些團隊的中小企業(yè)使用這些大型模型。
因此Colossal-AI的作用出現(xiàn)了:
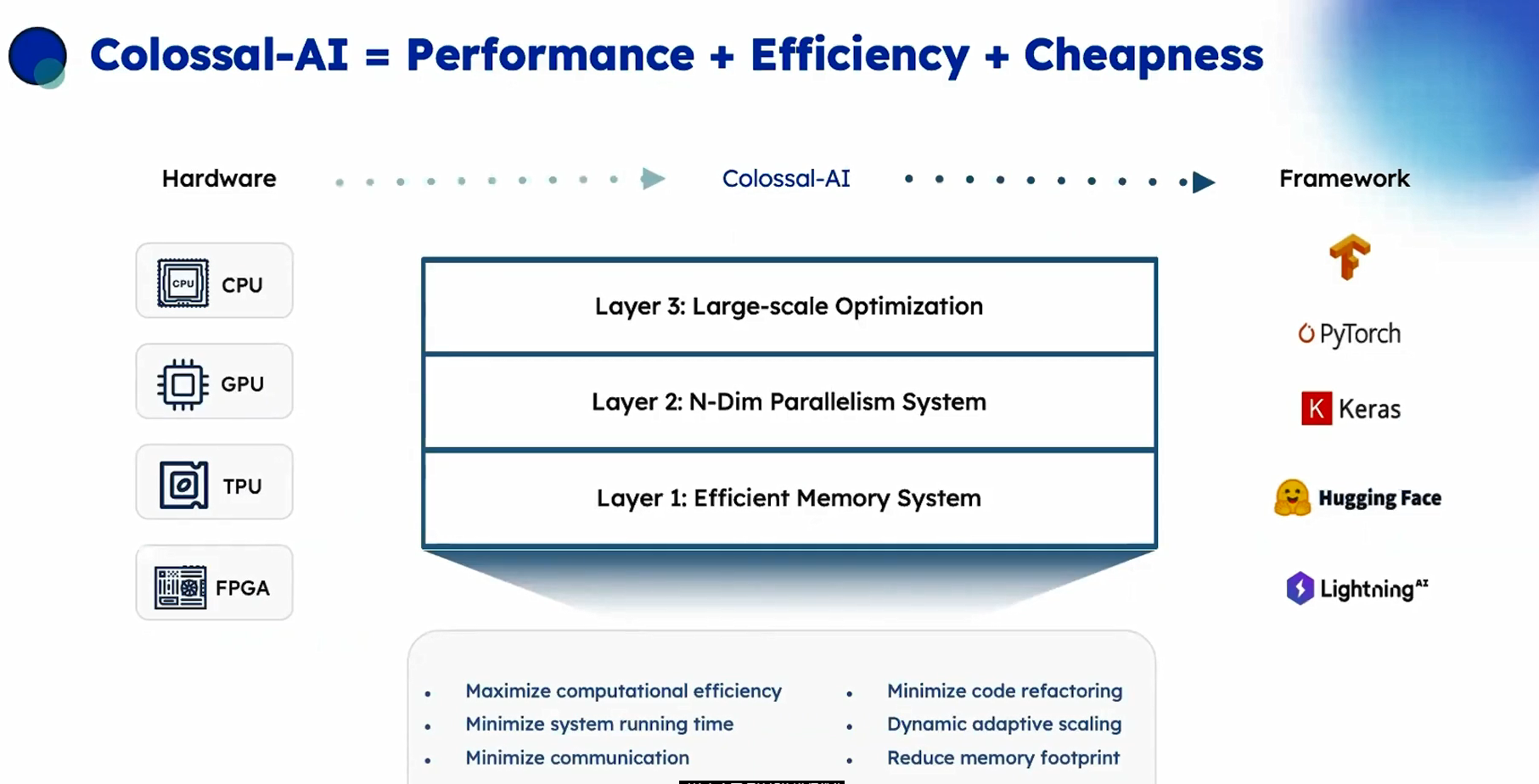
對特定底層硬件架構(gòu)進行優(yōu)化,左側(cè)(硬件層)可以是CPU、 GPU、TPU或FPGAl,右側(cè)是你的用于AI模型編寫的框架,如TensorFlow、 Py Torch或其他框架。Colossal-AI可以高效地將大模型部署到目標架構(gòu),實現(xiàn)底部顯示的所有目標,最小化運行時間,最小化通信(移動數(shù)據(jù))在當前架構(gòu)是最昂貴的操作,最小化用戶需要改動代碼的數(shù)量,即重構(gòu)。使模型能夠動態(tài)地適應(yīng)機器的規(guī)模變化,并減少內(nèi)存占用,一邊能運行大模型。
Colossal-AI提供了三個層次:
高效的內(nèi)存系統(tǒng),可最大程度利用可用內(nèi)存。
多維并行,即如何最好地將復(fù)雜的模型映射到可用的硬件上,以最大程度地使并行處理并最小化通信。
大規(guī)模優(yōu)化,也就是如何自動調(diào)整影響準確度收斂的眾多超參數(shù),因為這些值通常取決子如何進行并行處理。
因此Colossal-AI的目標是將復(fù)雜且相互作用的決策從用戶角度隱藏起來,并自動完成所有操作。
編輯:黃飛
-
英偉達
+關(guān)注
關(guān)注
22文章
3778瀏覽量
91177 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5504瀏覽量
121213 -
gtc
+關(guān)注
關(guān)注
0文章
73瀏覽量
4430
發(fā)布評論請先 登錄
相關(guān)推薦
AI干貨補給站 | 深度學(xué)習(xí)與機器視覺的融合探索

GPU深度學(xué)習(xí)應(yīng)用案例
AI大模型與深度學(xué)習(xí)的關(guān)系
NVIDIA推出全新深度學(xué)習(xí)框架fVDB
深度學(xué)習(xí)中的時間序列分類方法
基于AI深度學(xué)習(xí)的缺陷檢測系統(tǒng)
人工智能、機器學(xué)習(xí)和深度學(xué)習(xí)是什么
泰禾智能攜AI智選深度學(xué)習(xí)系列新品亮相臨沂花生展
深度解析深度學(xué)習(xí)下的語義SLAM

與NVIDIA深度參與GTC,向量數(shù)據(jù)庫大廠Zilliz與全球頂尖開發(fā)者共迎AI變革時刻
FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈鶪PU
英偉達GTC大會將開幕 黃仁勛將帶你《見證AI的變革時刻》
潞晨科技Colossal-AI與浪潮信息AIStation完成兼容性互認證
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發(fā)效率提升10倍





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論