") PyTorch 2.0正式版發(fā)布!
PyTorch 2.0正式版發(fā)布!
【導(dǎo)讀】PyTorch 2.0正式發(fā)布。
PyTorch 2.0正式版終于來(lái)了!

去年12月,PyTorch基金會(huì)在PyTorch Conference 2022上發(fā)布了PyTorch 2.0的第一個(gè)預(yù)覽版本。
跟先前1.0版本相比,2.0有了顛覆式的變化。在PyTorch 2.0中,最大的改進(jìn)是torch.compile。
新的編譯器比以前PyTorch 1.0中默認(rèn)的「eager mode」所提供的即時(shí)生成代碼的速度快得多,讓PyTorch性能進(jìn)一步提升。

除了2.0之外,還發(fā)布了一系列PyTorch域庫(kù)的beta更新,包括那些在樹(shù)中的庫(kù),以及包括 TorchAudio、TorchVision和TorchText在內(nèi)的獨(dú)立庫(kù)。TorchX的更新也同時(shí)發(fā)布,可以提供社區(qū)支持模式。

亮點(diǎn)總結(jié)
-torch.compile是PyTorch 2.0的主要API,它包裝并返回編譯后的模型,torch.compile是一個(gè)完全附加(和可選)的特性,因此2.0版本是100%向后兼容的。
-作為torch.compile的基礎(chǔ)技術(shù),帶有Nvidia和AMD GPU的TorchInductor將依賴OpenAI Triton深度學(xué)習(xí)編譯器來(lái)生成高性能代碼,并隱藏低級(jí)硬件細(xì)節(jié)。OpenAI Triton生成的內(nèi)核實(shí)現(xiàn)的性能,與手寫(xiě)內(nèi)核和cublas等專(zhuān)門(mén)的cuda庫(kù)相當(dāng)。
-Accelerated Transformers引入了對(duì)訓(xùn)練和推理的高性能支持,使用自定義內(nèi)核架構(gòu)實(shí)現(xiàn)縮放點(diǎn)積注意力 (SPDA)。API與torch.compile () 集成,模型開(kāi)發(fā)人員也可以通過(guò)調(diào)用新的scaled_dot_product_attention () 運(yùn)算符,直接使用縮放的點(diǎn)積注意力內(nèi)核。
-Metal Performance Shaders (MPS) 后端在Mac平臺(tái)上提供GPU加速的PyTorch訓(xùn)練,并增加了對(duì)前60個(gè)最常用操作的支持,覆蓋了300多個(gè)操作符。
-Amazon AWS優(yōu)化了基于AWS Graviton3的C7g實(shí)例上的PyTorch CPU推理。與之前的版本相比,PyTorch 2.0提高了Graviton的推理性能,包括對(duì)Resnet50和Bert的改進(jìn)。
-跨TensorParallel、DTensor、2D parallel、TorchDynamo、AOTAutograd、PrimTorch和TorchInductor的新原型功能和技術(shù)。

編譯,還是編譯!
PyTorch 2.0的最新編譯器技術(shù)包括:TorchDynamo、AOTAutograd、PrimTorch和TorchInductor。所有這些都是用Python開(kāi)發(fā)的,而不是C++(Python與之兼容)。
并且還支持dynamic shape,無(wú)需重新編譯就能發(fā)送不同大小的向量,靈活且易學(xué)。
TorchDynamo
它可以借助Python Frame Evaluation Hooks,安全地獲取PyTorch程序,這項(xiàng)重大創(chuàng)新是PyTorch過(guò)去 5 年來(lái)在安全圖結(jié)構(gòu)捕獲 (safe graph capture) 方面的研發(fā)成果匯總。
AOTAutograd
重載PyTorch autograd engine,作為一個(gè) tracing autodiff,用于生成超前的backward trace。
PrimTorch
將 2000+ PyTorch 算子歸納為約 250 個(gè) primitive operator 閉集 (closed set),開(kāi)發(fā)者可以針對(duì)這些算子構(gòu)建一個(gè)完整的 PyTorch 后端。PrimTorch 大大簡(jiǎn)化了編寫(xiě) PyTorch 功能或后端的流程。
4. TorchInductor
TorchInductor一個(gè)深度學(xué)習(xí)編譯器,可以為多個(gè)加速器和后端生成 fast code。對(duì)于 NVIDIA GPU,它使用 OpenAI Triton 作為關(guān)鍵構(gòu)建模塊。
PyTorch基金會(huì)稱(chēng),2.0的推出會(huì)推動(dòng)「從C++回到Python」,并補(bǔ)充說(shuō)這是PyTorch的一個(gè)實(shí)質(zhì)性的新方向。
「從第一天起,我們就知道「eager execution」的性能限制。2017年7月,我們開(kāi)始了第一個(gè)研究項(xiàng)目,為PyTorch開(kāi)發(fā)一個(gè)編譯器。編譯器需要使PyTorch程序快速運(yùn)行,但不能以PyTorch的體驗(yàn)為代價(jià),還要保留靈活易用性,這樣的話可以支持研究人員在不同探索階段使用動(dòng)態(tài)的模型和程序。」
當(dāng)然了,非編譯的「eager mode」使用動(dòng)態(tài)即時(shí)代碼生成器,在2.0中仍然可用。開(kāi)發(fā)者可以使用porch.compile命令迅速升級(jí)到編譯模式,只需要增加一行代碼。
用戶可以看到2.0的編譯時(shí)間比1.0提高43%。
這個(gè)數(shù)據(jù)來(lái)自PyTorch基金會(huì)在Nvidia A100 GPU上使用PyTorch 2.0對(duì)163個(gè)開(kāi)源模型進(jìn)行的基準(zhǔn)測(cè)試,其中包括包括圖像分類(lèi)、目標(biāo)檢測(cè)、圖像生成等任務(wù),以及各種 NLP 任務(wù)。
這些Benchmark分為三類(lèi):HuggingFace Tranformers、TIMM和TorchBench。
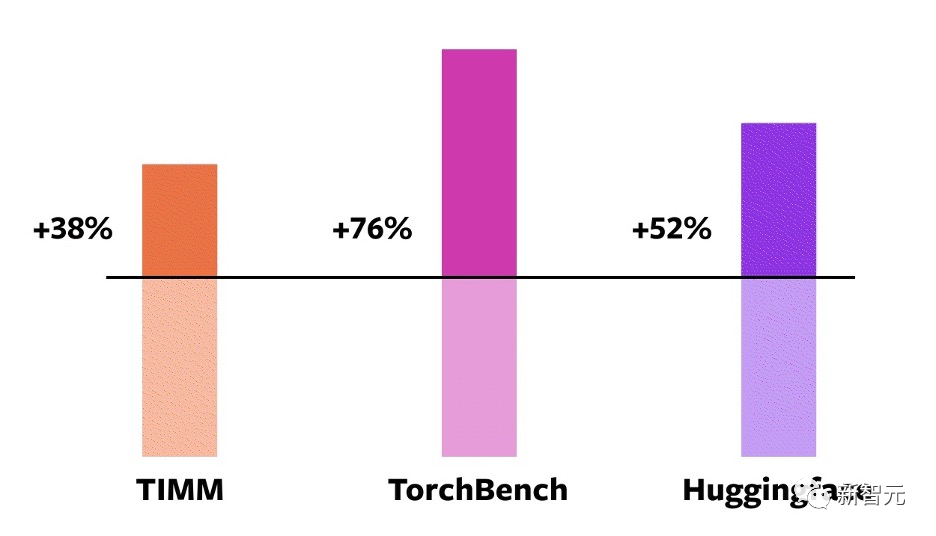
NVIDIA A100 GPU eager mode torch.compile 針對(duì)不同模型的提速表現(xiàn)
據(jù)PyTorch基金會(huì)稱(chēng),新編譯器在使用Float32精度模式時(shí)運(yùn)行速度提高了21%,在使用自動(dòng)混合精度(AMP)模式時(shí)運(yùn)行速度提高了51%。
在這163個(gè)模型中,torch.compile可以在93%模型上正常運(yùn)行。
「在PyTorch 2.x的路線圖中,我們希望在性能和可擴(kuò)展性方面讓編譯模式越走越遠(yuǎn)。有一些工作還沒(méi)有開(kāi)始。有些工作因?yàn)閹挷粔蚨k法落地。」
訓(xùn)練LLM提速2倍
此外,性能是PyTorch 2.0的另一個(gè)主要重點(diǎn),也是開(kāi)發(fā)人員一直不吝于宣傳的一個(gè)重點(diǎn)。
事實(shí)上,新功能的亮點(diǎn)之一是Accelerated Transformers,之前被稱(chēng)為Better Transformers。
另外,PyTorch 2.0正式版包含了一個(gè)新的高性能PyTorch TransformAPI實(shí)現(xiàn)。
PyTorch項(xiàng)目的一個(gè)目標(biāo),是讓最先進(jìn)的transformer模型的訓(xùn)練和部署更加容易、快速。
Transformers是幫助實(shí)現(xiàn)現(xiàn)代生成式人工智能時(shí)代的基礎(chǔ)技術(shù),包括GPT-3以及GPT-4這樣的OpenAI模型。
在PyTorch 2.0 Accelerated Transformers中,使用了自定義內(nèi)核架構(gòu)的方法(也被稱(chēng)為縮放點(diǎn)積注意力SDPA),為訓(xùn)練和推理提供高性能的支持。
由于有多種類(lèi)型的硬件可以支持Transformers,PyTorch 2.0可以支持多個(gè)SDPA定制內(nèi)核。更進(jìn)一步,PyTorch集成了自定義內(nèi)核選擇邏輯,將為給定的模型和硬件類(lèi)型挑選最高性能的內(nèi)核。
加速的影響非同小可,因?yàn)樗兄谑归_(kāi)發(fā)人員比以前的PyTorch迭代更快地訓(xùn)練模型。
新版本能夠?qū)崿F(xiàn)對(duì)訓(xùn)練和推理的高性能支持,使用定制的內(nèi)核架構(gòu)來(lái)處理縮放點(diǎn)積注意力(SPDA) ,擴(kuò)展了推理的快速路徑架構(gòu)。
與fastpath架構(gòu)類(lèi)似,定制內(nèi)核完全集成到PyTorch TransformerAPI中--因此,使用本地Transformer和MultiHeadAttention API將使用戶能夠:
-看到速度明顯提升;
-支持更多的用例,包括使用交叉注意的模型、Transformer解碼器和訓(xùn)練模型;
-繼續(xù)將快速路徑推理用于固定和可變序列長(zhǎng)度的變形器編碼器和自注意力機(jī)制的用例。
為了充分利用不同的硬件模型和Transformer用例,支持多個(gè)SDPA自定義內(nèi)核,自定義內(nèi)核選擇邏輯將為特定模型和硬件類(lèi)型挑選最高性能的內(nèi)核。
除了現(xiàn)有的Transformer API,開(kāi)發(fā)者還可以通過(guò)調(diào)用新的scaled_dot_product_attention()操作符直接使用縮放點(diǎn)積注意力關(guān)注內(nèi)核,加速PyTorch 2 Transformers與torch.compile()集成。
為了在使用模型的同時(shí),還能獲得PT2編譯的額外加速(用于推理或訓(xùn)練),可以使用model = torch.compile(model)對(duì)模型進(jìn)行預(yù)處理。
目前,已經(jīng)使用自定義內(nèi)核和torch.compile()的組合,在訓(xùn)練Transformer模型,特別是使用加速的PyTorch 2 Transformer的大型語(yǔ)言模型方面取得實(shí)質(zhì)性加速提升。
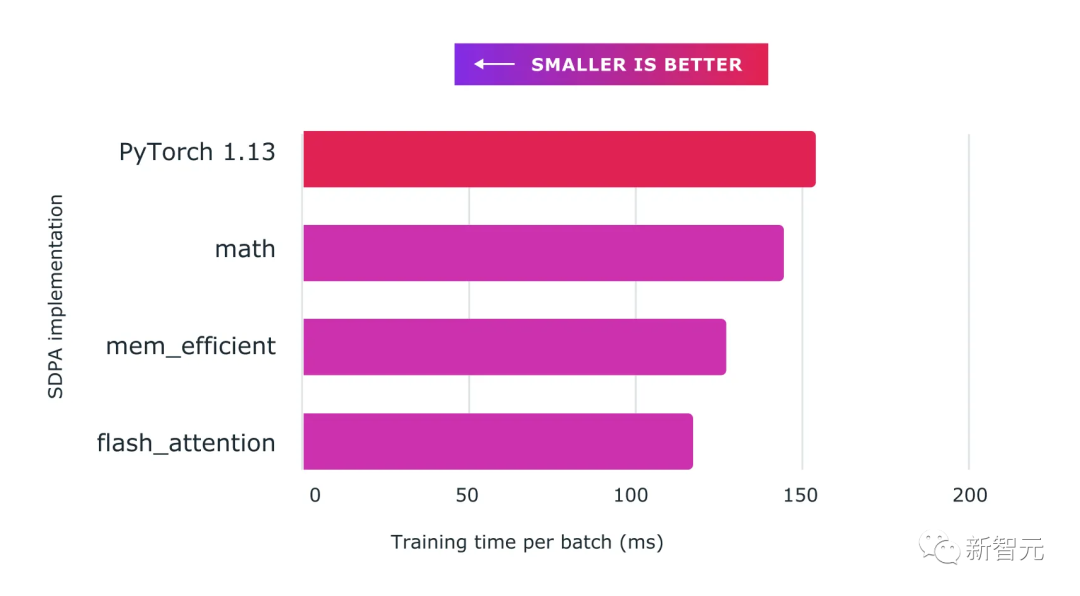
使用自定義內(nèi)核和 torch.compile來(lái)提供對(duì)大型語(yǔ)言模型訓(xùn)練顯著加速
HuggingFace Transformers的主要維護(hù)者Sylvain Gugger在PyTorch項(xiàng)目發(fā)表的一份聲明中寫(xiě)道「只需添加一行代碼,PyTorch 2.0就能在訓(xùn)練Transformers模型時(shí)提供1.5倍至2.0倍的速度。這是自混合精度訓(xùn)練推出以來(lái)最令人興奮的事情!」
PyTorch和谷歌的TensorFlow是兩個(gè)最流行的深度學(xué)習(xí)框架。世界上有數(shù)千家機(jī)構(gòu)正在使用PyTorch開(kāi)發(fā)深度學(xué)習(xí)應(yīng)用程序,而且它的使用量正在不斷增加。
PyTorch 2.0的推出將有助于加速深度學(xué)習(xí)和人工智能應(yīng)用的發(fā)展,Lightning AI的首席技術(shù)官和PyTorch Lightning的主要維護(hù)者之一Luca Antiga表示:
「PyTorch 2.0 體現(xiàn)了深度學(xué)習(xí)框架的未來(lái)。不需要用戶干預(yù)即可捕獲PyTorch 程序,開(kāi)箱即用的程序生成,以及巨大的設(shè)備加速,這種可能性為人工智能開(kāi)發(fā)人員打開(kāi)了一個(gè)全新的維度。」
審核編輯 :李倩
-
人工智能
+關(guān)注
關(guān)注
1792文章
47500瀏覽量
239221 -
代碼
+關(guān)注
關(guān)注
30文章
4808瀏覽量
68815 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13283
原文標(biāo)題:PyTorch 2.0正式版發(fā)布!一行代碼提速2倍,100%向后兼容
文章出處:【微信號(hào):CVSCHOOL,微信公眾號(hào):OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Altium Designer 18.0.9正式版發(fā)布!!!
蘋(píng)果今天發(fā)布Safari 5.1.4正式版
IOS10.3正式版發(fā)布,更新有驚喜
蘋(píng)果iOS11.3正式版發(fā)布_iOS11.3正式版只為新iPad而來(lái)
Linux 4.18 正式版將延期發(fā)布
谷歌發(fā)布Android 9 Pie正式版
GeForce 445.75版顯卡驅(qū)動(dòng)發(fā)布 可第一時(shí)間體驗(yàn)DLSS 2.0游戲的快感
DLC發(fā)布了植物燈V2.0標(biāo)準(zhǔn)的正式版,并將于2021年3月21日開(kāi)始實(shí)施
聯(lián)想宣布將發(fā)布正式版BIOS
PyTorch 2.5.1: Bugs修復(fù)版發(fā)布






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論