") OpenVINO? 中用于推理優(yōu)化的自適應(yīng)參數(shù)選擇功能介紹
OpenVINO? 中用于推理優(yōu)化的自適應(yīng)參數(shù)選擇功能介紹
本文簡介
當(dāng)你使用 AI 模型進(jìn)行推理時,往往需要設(shè)置一些參數(shù)與選項,相應(yīng)地,OpenVINO 工具套件為此提供了一些自動設(shè)定參數(shù)選項的功能。本文主要介紹 OpenVINO中與模型推理相關(guān)的3個功能,它們分別是:
用于 input 數(shù)據(jù)足夠多時,提供最大 throughput 的 Auto-batching 功能;
用于自動選擇設(shè)備進(jìn)行推理的 Auto Plugin 功能;
以及用于滿足特定模型動態(tài)輸入的 Dynamic Shape 功能。
本文將逐一介紹這三個實用的功能,并在文末給出這三功能的優(yōu)缺點總結(jié)對比。
功能介紹
Auto-batching
Auto-batching 設(shè)計目的是讓開發(fā)者利用最少的代碼去實現(xiàn)使用英特爾顯卡做模型推理的數(shù)據(jù)吞吐量最大化。在沒有設(shè)定 input 以及沒有限制范圍的情況下,它會按照集成顯卡或者是獨(dú)立顯卡能承受的最大吞吐量去設(shè)定推理線程數(shù)。如果應(yīng)用程序有大量的輸入數(shù)據(jù)且以高頻率連續(xù)提交推理請求,推薦使用 Auto-batching 功能。
該功能通過幾行代碼實現(xiàn)了最多推理線程的響應(yīng),同時也不會對原先的示例代碼造成影響。如果在推理設(shè)備設(shè)置中,將“device“參數(shù)設(shè)置為:“BATCH:GPU“ 該功能將會被激活。例如,在 benchmark_app 應(yīng)用使用 Auto-batching 的方式如下:
$benchmark_app -hint none -d BATCH:GPU -m ‘path to your favorite model’
向右滑動查看完整代碼
另外一種方法是:在 GPU 推理時,選擇性能模式為”THROUGHPUT”,該功能將會被自動觸發(fā)。所以在示例代碼中添加如下兩行,即可在 GPU 進(jìn)行推理時,啟動 Auto-batching 功能:
config = {"PERFORMANCE_HINT": "THROUGHPUT"} compiled_model = core.compile_model(model, "GPU", config)
向右滑動查看完整代碼
無論是通過設(shè)置 BATCH:GPU,還是選擇”THROUGHPUT”的推理模式,推理的 batch size 值都會自動進(jìn)行選取。選取的方式是查詢當(dāng)前設(shè)備的 ov::optimal_batch_size 屬性并且通過模型拓?fù)浣Y(jié)構(gòu)的輸入端獲取 batch size 的值作為模型推理的 batch size 值。
接下來,是使用 Benchmark APP 做的對比實驗:
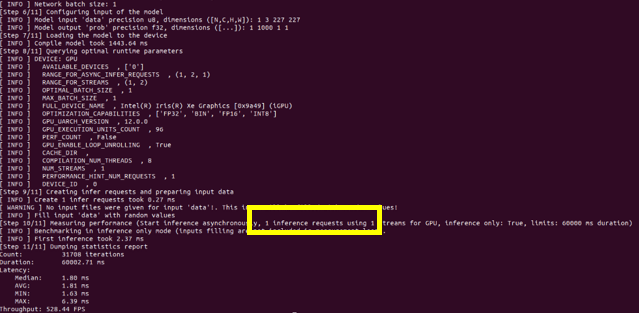
圖1:Disable Auto-batching
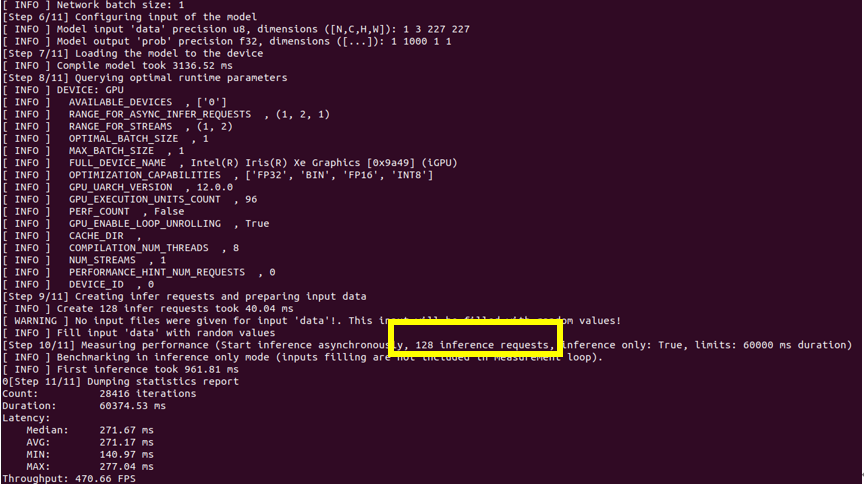
圖2:Enable Auto-batching
通過對比 Auto-batching 功能開閉的推理結(jié)果圖,可以看到當(dāng)此功能開啟的時候:即使推理設(shè)備選擇的是集成顯卡,推理線程數(shù)仍舊被推上了128個,說明此功能確實會嘗試使用當(dāng)前狀態(tài)下壓力最大的推理線程數(shù),來達(dá)到推理最大的吞吐量。但是結(jié)果是當(dāng)推理性能有限的集成顯卡啟動了128個線程的時候,整體的 throughput 的數(shù)值比單推理線程的 throughput 要低一些,所以當(dāng)硬件推理性能有限時,需要對推理線程數(shù)進(jìn)行限定。同樣,在 Auto-batching 中限定推理線程有兩種方式分別為,設(shè)置 BATCH: GPU (4)或設(shè)置 ov::num_requests 參數(shù)可以將推理線程設(shè)為4:
auto compiled_model = core.compile_model(model, "GPU", ov::THROUGHPUT), ov::num_requests(4));
向右滑動查看完整代碼
Auto-batching 中內(nèi)置了 Auto_batch_timeout 參數(shù),該參數(shù)用于監(jiān)測輸入數(shù)據(jù)送達(dá)的時延,初始值為1000,表示若1000毫秒后無數(shù)據(jù)輸入則提示推理超時。注意,如果推理頻率較低,或者根據(jù) Auto_batch_timeout 參數(shù)發(fā)現(xiàn)推理超時,可以手動關(guān)閉 Auto-batching:
// disabling the automatic batching auto compiled_model = core.compile_model(model, "GPU", ov::THROUGHPUT), ov::allow_auto_batching(false));
向右滑動查看完整代碼
AUTO Plugin
在 OpenVINO 工具套件的推理插件(Plugin)選擇上,除了常規(guī)的 CPU,iGPU,Myriad,您還可以選擇使用 AUTO Plugin。開發(fā)者通過它快速部署 AI 示例用于實驗,且不用考慮推理設(shè)備的選擇就能獲得一個不錯的推理性能。不需要指定設(shè)備,它會自動配置推理硬件,當(dāng)有多個設(shè)備時,它也會自動聯(lián)合調(diào)用多個硬件進(jìn)行推理。
AUTO Plugin 的工作流程是:首先,檢測當(dāng)前環(huán)境下所有的可用設(shè)備,之后根據(jù)預(yù)制的硬件選擇規(guī)則,選擇相應(yīng)的推理設(shè)備,并且優(yōu)化推理的整體配置,最后執(zhí)行 AI 推理。AUTO Plugin 對于推理設(shè)備選擇遵循以下的規(guī)則:
dGPU (e.g. Intel Iris Xe MAX) ->
iGPU (e.g. Intel UHD Graphics 620 (iGPU)) ->
Intel Movidius Myriad X VPU(e.g. Intel Neural Compute Stick 2 (Intel NCS2)) ->
Intel CPU (e.g. Intel Core i7-1165G7)
#常規(guī)用法: compiled_model = core.compile_model(model=model, device_name="AUTO") #您可以限定設(shè)備使用AUTO Plugin: compiled_model = core.compile_model(model=model, device_name="AUTO:GPU,CPU") #您也可以剔除使用AUTO Plugin的設(shè)備: compiled_model = core.compile_model(model=model, device_name="AUTO:-CPU")
向右滑動查看完整代碼
AUTO Plugin 內(nèi)置有三個模式可供選擇:
1.THROUGHPUT
默認(rèn)模式。該模式優(yōu)先考慮高吞吐量,在延遲和功率之間進(jìn)行平衡,最適合于涉及多個任務(wù)的推理,例如推理視頻源或大量圖像。注:此模式只會對 CPU 與 GPU 進(jìn)行調(diào)用。若該模式下調(diào)用GPU進(jìn)行推理,將會自動觸發(fā)“Auto-batching“功能。
compiled_model = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"THROUGHPUT"})
向右滑動查看完整代碼
2.LATENCY
此選項優(yōu)先考慮低延遲,為每個推理任務(wù)提供比較短的響應(yīng)時間。它對于需要對單個輸入圖像進(jìn)行推斷的任務(wù)(例如超聲掃描圖像的醫(yī)學(xué)分析)。此外,它還適用于實時或接近實時應(yīng)用的任務(wù),例如工業(yè)機(jī)器人對其環(huán)境中動作的響應(yīng)或自動駕駛車輛的避障。注:此模式只會對 CPU 與 GPU 進(jìn)行調(diào)用。
compiled_modecompiled_model = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"LATENCY"})compiled_mode = core.compile_model(model, "AUTO", ov:: CUMULATIVE_THROUGHPUT)); l = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"LATENCY"})
向右滑動查看完整代碼
3.CUMULATIVE_THROUGHPUT
CUMULTIVE_THROUGHPUT 模式允許同時在多個設(shè)備上運(yùn)行推理以獲得更高的吞吐量。
使用 CUMULTIVE_THROUGHPUT 模式時,AUTO Plugin 將網(wǎng)絡(luò)模型加載到候選列表中的所有可用設(shè)備,然后根據(jù)默認(rèn)的優(yōu)先級載入設(shè)備運(yùn)行推理。
compiled_mode = core.compile_model(model, "AUTO", ov:: CUMULATIVE_THROUGHPUT));
向右滑動查看完整代碼
注意:如果指定了沒有任何設(shè)備名稱的 AUTO,并且系統(tǒng)有兩個以上的 GPU 設(shè)備,則 AUTO 將從設(shè)備候選列表中刪除 CPU,以保持 GPU 以滿容量運(yùn)行。如果指定了設(shè)備優(yōu)先級,AUTO 將根據(jù)優(yōu)先級在設(shè)備上運(yùn)行推理請求。
Dynamic Shape
模型的動態(tài)輸入對于某些領(lǐng)域十分重要,比如說在自然語言處理(NLP)中就需要實時對語句進(jìn)行分割,所以模型的輸入是實時變化的,又比如在圖像識別中,分割塊的形狀大小也會根據(jù)目標(biāo)的大小實時變動。對于分割之后的圖像來說,進(jìn)行 resize 操作往往會破壞它的特征屬性,導(dǎo)致在后期推理中造成推理準(zhǔn)確性降低。動態(tài)形狀輸入功能的引入使得一些基于圖像識別的模型,運(yùn)行結(jié)果的準(zhǔn)確度提高。使用 Dynamic Shape 功能能夠更好地保留圖像的特征,根據(jù)輸入圖像的大小,動態(tài)調(diào)節(jié)模型輸入,最終模型推理的準(zhǔn)確率獲得了提升。
在2022.1以前的 OpenVINO 版本中,使用 WPOD-NET (GitHub - sergiomsilva/alpr-unconstrained: License Plate Detection and Recognition in Unconstrained Scenarios):
地址(復(fù)制到瀏覽器打開)
https://github.com/sergiomsilva/alpr-unconstrained
模型進(jìn)行車牌識別,如果出現(xiàn)動態(tài)形態(tài)輸入的話,在 MO 轉(zhuǎn)換時就會報錯,必須強(qiáng)制轉(zhuǎn)成靜態(tài)輸入,例如:
python3 $INTEL_OPENVINO_DIR/deployment_tools/model_optimizer/mo_tf. py --data_type=FP32 --saved_model_dir=./data/lpdetector/tf2/models/saved_model/ --model_name=wpod-net -- reverse_input_channels --input_shape [1,416,416,3] -- output_dir=./data/lpdetector/tf2/models/saved_model/FP32_416
向右滑動查看完整代碼
這會導(dǎo)致該模型在特定的例子下識別精度降低:
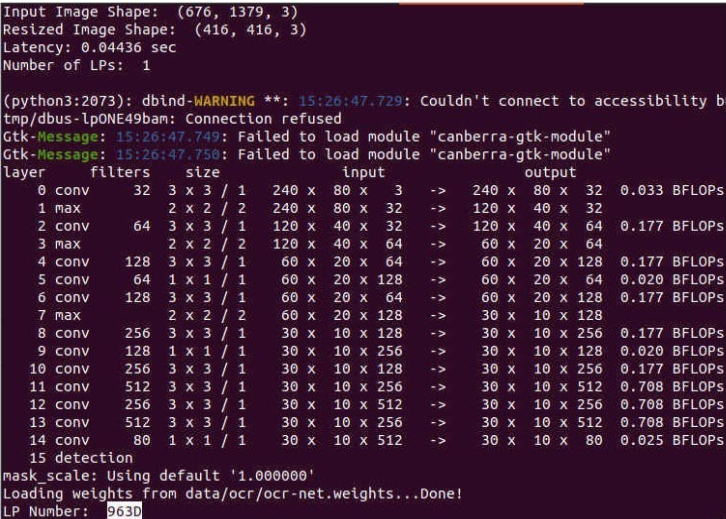

圖例:輸入圖像Resize 為固定尺寸后進(jìn)行模型推理
由于模型被強(qiáng)制轉(zhuǎn)成了靜態(tài)輸入,可以很明顯的發(fā)現(xiàn)輸入的圖像被被強(qiáng)制Resize到了(416,416),圖像分割的錯誤,最后導(dǎo)致了最后車牌識別的結(jié)果是不正確的。
在2022.1以后的 OpenVINO 版本中,MO 支持了 Dynamic Shape 的功能,故使用新版本 OpenVINO 工具套件中的模型優(yōu)化器進(jìn)行模型轉(zhuǎn)換:
mo --saved_model_dir ./data/lpdetector/tf2/models/saved_model/ -- output_dir ./data/lpdetector/tf2/models/FP32/
向右滑動查看完整代碼
在生成的 xml 文件中,可以開到 input shape 被識別為動態(tài)輸入,動態(tài)參數(shù)以“?”或“-1”進(jìn)行顯示:
向右滑動查看完整代碼
使用包含動態(tài)輸入的模型進(jìn)行試驗,實驗結(jié)果如下:
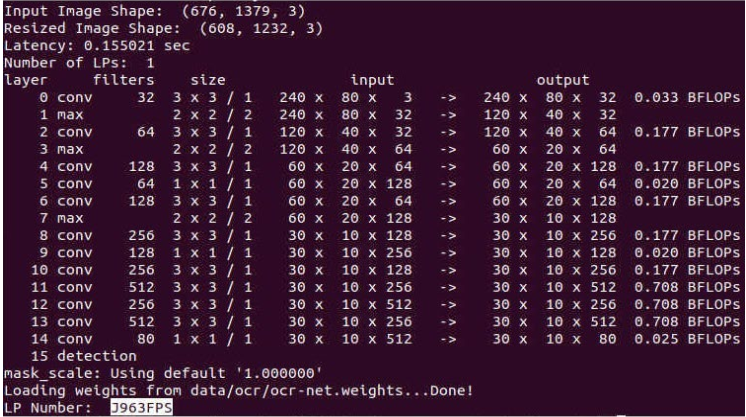


圖例:模型使用動態(tài)輸入進(jìn)行推理
通過 WPOD-NET 的內(nèi)置算法,計算得到合適的 Resize 長和寬(1232x608),將圖片 Resize 至1232x608,分割到的車牌是清晰完整且最終車牌號碼識別是正確的。
模型的動態(tài)輸入在這個例子中顯得十分重要,因為動態(tài)輸入的支持使得模型推理識別的精度更加準(zhǔn)確了。如果模型優(yōu)化器沒有識別到模型的動態(tài)輸入?yún)?shù),您可以在代碼中手動指定 Dynamic Shape:
core = ov.Core() model = core.read_model("model.xml") # Set one static dimension (= 1) and another dynamic dimension (= Dimension()) model.reshape([1, ov.Dimension()])
向右滑動查看完整代碼
您也可以指定動態(tài)輸入的動態(tài)范圍:
# Both dimensions are dynamic, first has a size within 1..10 and the second has a size within 8..512 model.reshape([ov.Dimension(1, 10), ov.Dimension(8, 512)])
向右滑動查看完整代碼
由于您的輸入圖像是動態(tài)的,所以說您在初始化 input tensor 的時候,根據(jù)需要進(jìn)行設(shè)定,您可以手動對每一個推理 tensor 進(jìn)行指定:
# Get the tensor, shape is not initialized input_tensor = infer_request.get_input_tensor() # Set shape is required input_tensor.shape = [1, 128] input_tensor.shape = [1, 200]
向右滑動查看完整代碼
當(dāng)然,也可以通過模型的 input layer 進(jìn)行指定:
input_tensor = np.expand_dims(image_resized, 0) results = compiled_model.infer_new_request({0: input_tensor})
向右滑動查看完整代碼
總結(jié)
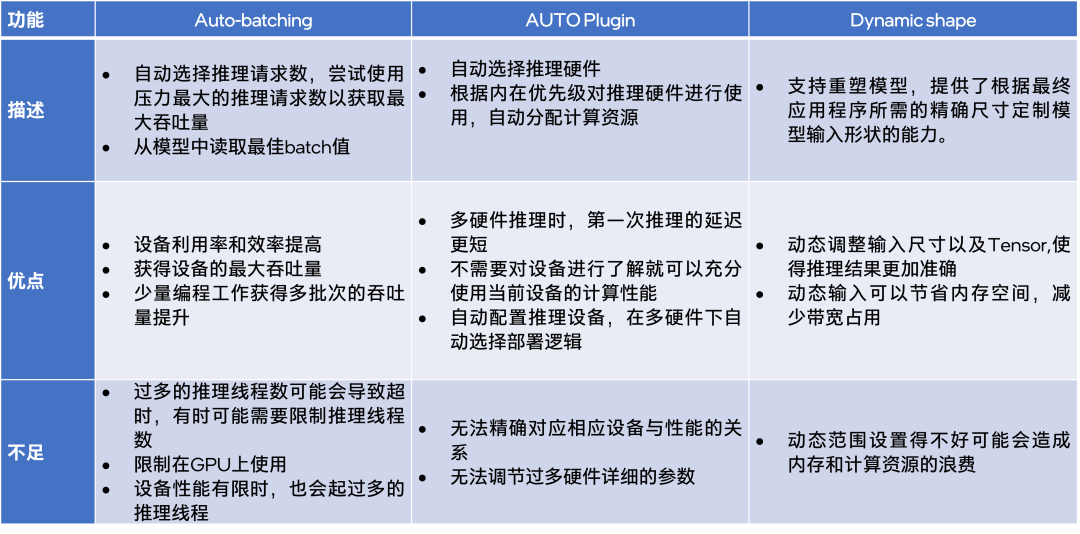
針對不同模型推理場景下, Auto-batching 能夠自動給予設(shè)備最大壓力達(dá)到最大吞吐量;AUTO Plugin 能夠自動選擇推理設(shè)備;Dynamic shape 能供根據(jù)輸入圖像動態(tài)調(diào)整模型的 input shape 大小。這些功能都依據(jù)開發(fā)者的需求,在進(jìn)行模型推理時,幫助住開發(fā)者自動完成相應(yīng)的配置,對開發(fā) OpenVINO 的示例應(yīng)用進(jìn)行輔助。
不過這些功能在使用時,也有一些注意事項需要知曉,請您在使用這些功能之前,了解每個功能的局限性以及每個功能正確的用法。
OpenVINO 工具套件下載地址:
https://www.intel.cn/content/www/cn/zh/developer/tools/openvino-toolkit/download.html
OpenVINO 使用文檔:
https://docs.openvino.ai/latest/
審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
31294瀏覽量
269655 -
模型
+關(guān)注
關(guān)注
1文章
3279瀏覽量
48976 -
線程
+關(guān)注
關(guān)注
0文章
505瀏覽量
19715
原文標(biāo)題:OpenVINO? 中用于推理優(yōu)化的自適應(yīng)參數(shù)選擇功能介紹 | 開發(fā)者實戰(zhàn)
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何在自己的固件中增加wifi自適應(yīng)性相關(guān)功能,以通過wifi自適應(yīng)認(rèn)證測試?
基于粒子群算法的自適應(yīng)LMS濾波器設(shè)計及可重構(gòu)硬件實現(xiàn)
自適應(yīng)逆變電源的設(shè)計與實現(xiàn)
有什么方法可以優(yōu)化自適應(yīng)轉(zhuǎn)向大燈系統(tǒng)的設(shè)計嗎?
基于遺傳優(yōu)化和模糊推理PID參數(shù)及MATLAB仿真
基于反饋的自適應(yīng)參考幀選擇的率失真優(yōu)化分析
自適應(yīng)神經(jīng)模糊推理系統(tǒng)(ANFIS)及其仿真
自適應(yīng)粒子群優(yōu)化分?jǐn)?shù)階PID控制器的參數(shù)整定
一種新的自適應(yīng)變異粒子群優(yōu)化算法在PMSM參數(shù)辨識中的應(yīng)用
自動變步長BLMS自適應(yīng)均衡的優(yōu)化實現(xiàn)
自適應(yīng)系統(tǒng)決策:一種模型驅(qū)動的方法
基于自適應(yīng)動態(tài)規(guī)劃的SVC自適應(yīng)優(yōu)化控制策略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論