 如何應用Anomalib在數據集不平衡的情況下檢測缺陷 ?
如何應用Anomalib在數據集不平衡的情況下檢測缺陷 ?
質量控制和質量保證是任何企業保持卓越聲譽、提升客戶體驗的關鍵環節。例如,在制造業中,通過檢測生產線上的異常情況,企業可以確保只有最優質的產品能夠出廠。而在醫療行業,通過醫學成像及早發現異常有助于醫生對患者進行準確診斷。
以上場景中的任何差錯都會導致嚴重后果。正因如此,許多行業開始告別易受主觀因素影響而出錯的人工檢查和維護,轉而引入日新月異的計算機視覺和深度學習技術,實施自動化異常檢測。
如要真正增強質量控制和質量保證,人工智能必須利用數據量豐富且平衡的數據集。雖然如今有大量良好的數據樣本,但有時不足以幫助工業和醫療行業做出準確和有效的預測。此外,大規模制造和工業自動化的發展帶來了產能的躍升,質檢人員越來越難以處理數量龐大的產品。
克服數據集挑戰
基于監督式學習的方法利用足夠的注釋異常樣本,通常可用于實現令人滿意的異常檢測結果。但如果數據集是缺乏異常類別代表性樣本的不平衡數據集,結果會怎樣?當缺陷可以是任何類型的形狀時,您如何定義異常的邊界?
解決這些問題的一個方法是無監督異常檢測,它幾乎不需要標注。無監督異常檢測在訓練階段完全依賴正常樣本,可以通過與所學的正常數據分布進行比較來識別異常樣本。
開源的端到端異常檢測庫 Anomalib 便是一種基于無監督異常檢測算法的開源庫,它提供了可根據特定用例和要求定制的先進異常檢測算法。
Anomalib 在制造業中的應用
讓我們看一個具有彩色立方體的生產線示例(圖 1)。

圖 1.使用教育機器人進行基于 Anomalib 的缺陷檢測。
我們要檢測出任何有缺陷的彩色立方體,并防止它們進入生產線。為此,需要安裝一個攝像頭來監測彩色立方體的狀況,然后由監控器對機械臂進行操作(圖 2)。

圖 2.運行 Anomalib 模型推理的教育機器人。
對于這種場景下的異常檢測,我們沒有可用于在邊緣訓練模型的硬件加速器。我們也不能假設已經為邊緣訓練收集了數千幅圖像、尤其是有缺陷的圖像。此外,預計不會像真實的制造場景一樣,存在大量缺陷已知的情況。
鑒于這些初始條件,我們的一個目標是在邊緣實現更快的訓練速度,并進行高精確和高效的異常檢測。有一點需要記住,即如果有任何外部條件變化 - 如照明、攝像頭或異常情況,我們將不得不重新訓練模型。因此,進行不太費事的重新訓練是有必要的。最后,為了確保模型在真實的制造用例中發揮作用,我們必須保證使用異常檢測模型獲得精確的推理結果。
借助內容廣泛的 Anomalib 庫,我們可以設計、實施和部署無監督異常檢測模型,覆蓋從數據收集到邊緣應用在內的流程,從而滿足我們的所有要求。
Anomalib 的工作原理
Anomalib 庫提供了能夠計算圖像上異常情況的算法,以及通過訓練、評估、測試、基準測試和超參數優化來運行這些算法的工具。模塊已經提供了可用于自定義算法的算法設計和工具。
在圖 3 中,我們展示了Anomalib 是由工具、組件以及模塊這幾部分組成的,其中,我們把部署作為工具和模塊的一部分,想表明這部分也包含在該庫的范圍內。
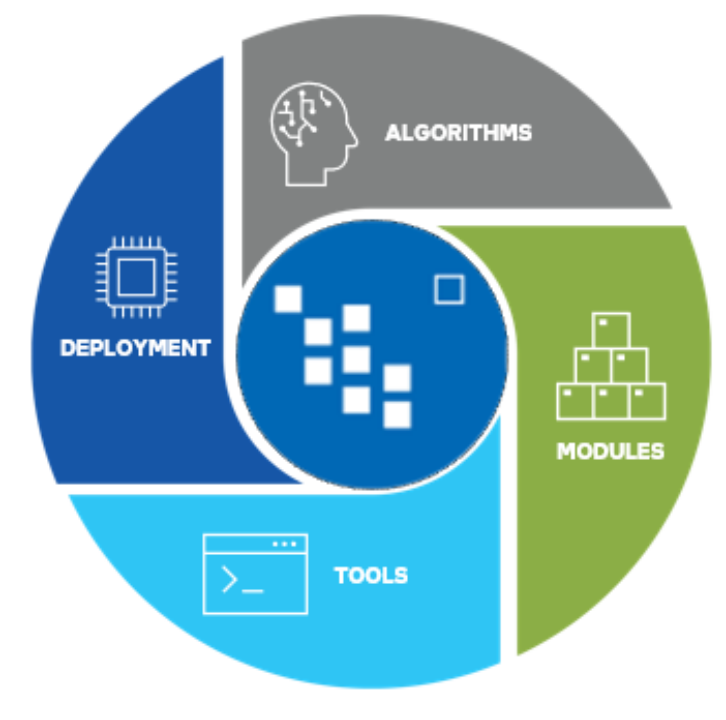
圖 3.Anomalib 的工具、組件和模塊。
圖 4 詳細展示了從訓練到部署的工作流程概覽圖。我們已使用 PyTorch Lighting 進行訓練和測試,并使用 ONNX 和 OpenVINO進行優化;TensorFlow、PyTorch 和 OpenVINO 可用于部署。
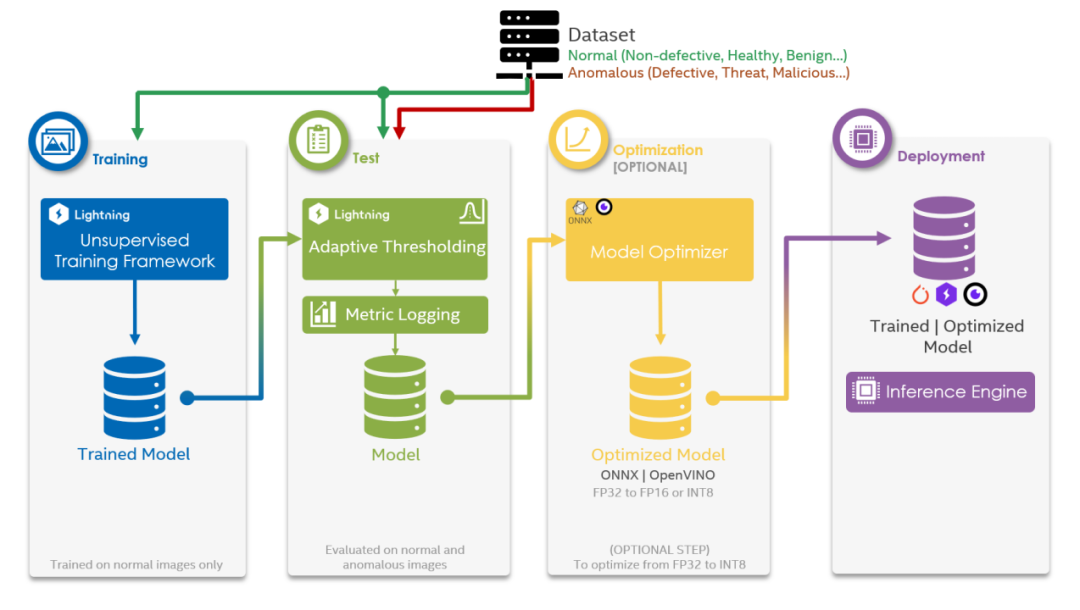
圖4.從訓練到部署的工作流程概覽圖。
審核編輯:劉清
-
機器人
+關注
關注
211文章
28476瀏覽量
207414 -
加速器
+關注
關注
2文章
801瀏覽量
37919 -
數據集
+關注
關注
4文章
1208瀏覽量
24727 -
pytorch
+關注
關注
2文章
808瀏覽量
13246
原文標題:如何應用Anomalib在數據集不平衡的情況下檢測缺陷 ?-- 上篇
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何理解矢量測量中“平衡”與“不平衡
三相不平衡對變壓器及用電設備的影響
三相不平衡的原因、危害以及解決措施
三相不平衡治理裝置的應用優勢
怎么解決變頻器電流不平衡的問題
當機器學習中遇到類不平衡,該怎么辦?





 工商網監
工商網監
評論