 當前主流的AI芯片介紹
當前主流的AI芯片介紹
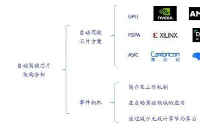
[當前主流的AI芯片主要分為三類, GPU、FPGA、ASIC 。GPU、FPGA均是前期較為成熟的芯片架構,屬于通用型芯片。ASIC屬于為AI特定場景定制的芯片。行業內已經確認CPU不適用于AI計算,但是在AI應用領域也是必不可少。

GPU方案
GPU與CPU的架構對比
CPU遵循的是 馮·諾依曼架構 ,其核心是存儲程序/數據、串行順序執行。因此CPU的架構中需要大量的空間去放置存儲單元(Cache)和控制單元(Control),相比之下計算單元(ALU)只占據了很小的一部分,所以CPU在進行大規模并行計 算方面受到限制,相對而言更擅長于處理邏輯控制。 GPU(GraphicsProcessing Unit),即圖形處理器,是 一種由大量運算單元組成的大規模并行計算架構 ,早先由CPU中分出來專門用于處理圖像并行計算數據,專為同時處理多重并行計算任務而設計。GPU中也包含基本的計算單元、控制單元和存儲單元,但GPU的架構與CPU有很大不同,其架構圖如下所示。 與CPU相比,CPU芯片空間的不到20%是ALU,而GPU芯片空間的80%以上是ALU。即GPU擁有更多的ALU用于數據并行處理。

GPU與CPU區別 ** CPU由專為順序串行處理而優化的幾個核心組成,而GPU則擁有一個由數以千計的更小、更高效的核心組成的大規模并行計算架構,這些更小的核心專為同時處理多重任務而設計。 CPU和GPU之所以大不相同,是由于其設計目標**的不同,它們分別針對了兩種不同的應用場景。CPU需要很強的通用性來處理各種不同的數據類型,同時又要邏輯判斷又會引入大量的分支跳轉和中斷的處理。這些都使得CPU的內部結構異常復雜。而GPU面對的則是類型高度統一的、相互無依賴的大規模數據和不需要被打斷的純凈的計算環境。

**GPU加速技術簡述 **
對于深度學習來說,目前硬件加速主要靠 使用圖形處理單元 。相比傳統的CPU,GPU的核心計算能力要多出幾個數量級,也更容易進行并行計算。
GPU的眾核體系結構包含幾千個流處理器,可將運算并行化執行,大幅縮短模型的運算時間。隨著NVIDIA、AMD等公司不斷推進其GPU的大規模并行架構支持,面向通用計算的GPU已成為加速并行應用程序的重要手段。 目前GPU已經發展到了較為成熟的階段。利用GPU來訓練深度神經網絡,可以充分發揮其數以千計計算核心的高效并行 計算能力,在使用海量訓練數據的場景下,所耗費的時間大幅縮短,占用的服務器也更少。如果針對適當的深度神經網絡進行合理優化,一塊GPU卡可相當于數十甚至上百臺CPU服務器的計算能力,因此GPU已經成為業界在深度學習模型訓練方面的首選解決方案。

當訓練的模型規模比較大時,可以通過數據并行的方法來加速模型的訓練,數據并行可以對訓練數據做切分,同時采用多個模型實例對多個分塊的數據同時進行訓練。在數據并行的實現中,由于是采用同樣的模型、不同的數據進行訓練,影響模型性能的瓶頸在于多CPU或多GPU間的參數交換。根據參數更新公式,需要將所有模型計算出的梯度提交到參數服務器并更新到相應參數上,**所以數據片的劃分以及與參數服務器的帶寬可能會成為限制數據并行效率的瓶頸。 ** 除了數據并行,還可以采用模型并行的方式來加速模型的訓練。模型并行是指將大的模型拆分成幾個分片,由若干個訓練單元分別持有,各個訓練單元相互協作共同完成大模型的訓練。

GPU加速計算
GPU加速計算是指同時利用圖形處理器 (GPU) 和 CPU,加快科學、分析、工程、消費和企業應用程序的運行速度。GPU加速器于2007年由NVIDIA率先推出,現已在世界各地為政府實驗室、高校、公司以及中小型企業的高能效數據中心提供支持。GPU能夠使從汽車、手機和平板電腦到無人機和機器人等平臺的應用程序加速運行。 GPU加速計算可以提供 非凡的應用程序性能 ,能將應用程序計算密集部分的工作負載轉移到GPU,同時仍由CPU運行其余程序代碼。從用戶的角度來看,應用程序的運行速度明顯加快。 GPU當前只是單純的并行矩陣的乘法和加法運算,對于神經網絡模型的構建和數據流的傳遞還是在CPU上進行。CPU與GPU的交互流程:獲取GPU信息,配置GPU id、加載神經元參數到GPU、GPU加速神經網絡計算、接收GPU計算結果。

為什么GPU在自動駕駛領域如此重要
自動駕駛技術中最重要的技術范疇之一是 深度學習 ,基于深度學習架構的人工智能如今已被廣泛應用于計算機視覺、自然語言處理、傳感器融合、目標識別、自動駕駛等汽車行業的各個領域,從自動駕駛初創企業、互聯網公司到各大OEM 廠商,都正在積極探索通過利用GPU構建神經網絡實現最終的自動駕駛。 GPU加速計算誕生后,它為企業數據提供了多核并行計算架構,支撐了以往CPU架構無法處理的數據源。根據對比,為了完成相同的深度學習訓練任務,使用GPU計算集群所需要的成本只是CPU計算集群的200分之一。

**GPU是自動駕駛與深度學習的關鍵 **
無論是讓汽車實時感知周邊實時環境,還是迅速規劃行車路線和動作,這些都需要依賴汽車大腦快速的響應,因此對計算機硬件廠商提出了巨大挑戰,自動駕駛的過程中時刻需要深度學習或者人工智能算法應對無限可能的狀況, 而人工智能、深度學習和無人駕駛的蓬勃發展,帶來了GPU計算發展的黃金時代。 GPU的另一個重要參數是 浮點計算能力 。浮點計數是利用浮動小數點的方式使用不同長度的二進制來表示一個數字,與 之對應的是定點數。在自動駕駛算法迭代時對精度要求較高,需要浮點運算支持。

FPGA方案
**FPGA芯片定義及結構 **
FPGA(Field-Programmable Gate Array),即現場可編程門陣列,它是在PAL、GAL、CPLD等可編程器件的基礎上進一步發展的產物。它是作為專用集成電路領域中的一種半定制電路而出現的,既解決了定制電路的不足,又克服了原有可編程器件門電路數有限的缺點。 FPGA芯片主要由6部分完成,分別為: 可編程輸入輸出單元、基本可編程邏輯單元、完整的時鐘管理、嵌入塊式RAM、豐富的布線資源、內嵌的底層功能單元和內嵌專用硬件模塊 。目前主流的FPGA仍是基于查找表技術的,已經遠遠超出了先前版本的基本性能,并且整合了常用功能(如RAM、時鐘管理和DSP)的硬核(ASIC型)模塊。

FPGA工作原理
由于FPGA需要被反復燒寫,它實現組合邏輯的基本結構不可能像ASIC那樣通過固定的與非門來完成,而只能采用一種易 于反復配置的結構。查找表可以很好地滿足這一要求,目前主流FPGA都采用了基于SRAM工藝的查找表結構,也有一些軍品和宇航級FPGA采用Flash或者熔絲與反熔絲工藝的查找表結構。通過燒寫文件改變查找表內容的方法來實現對FPGA的重復配置。 查找表(Look-Up-Table)簡稱為LUT,LUT本質上就是一個RAM。目前FPGA中多使用4輸入的LUT,所以每一個LUT可以看成一個有4位地址線的RAM。當用戶通過原理圖或HDL語言描述了一個邏輯電路以后,PLD/FPGA開發軟件會自動計算邏輯電路的所有可能結果,并把真值表(即結果)事先寫入RAM,這樣,每輸入一個信號進行邏輯運算就等于輸入一個地址進行查表,找出地址對應的內容,然后輸出即可。

可編程輸入/輸出單元簡稱I/O單元,是芯片與外界電路的接口部分,完成不同電氣特性下對輸入/輸出信號的驅動與匹配要求。FPGA內的I/O按組分類,每組都能夠獨立地支持不同的I/O標準。通過軟件的靈活配置,可適配不同的電氣標準與 I/O物理特性,可以調整驅動電流的大小,可以改變上、下拉電阻。目前,I/O口的頻率也越來越高,一些高端的FPGA通過DDR寄存器技術可以支持高達2Gbps的數據速率。 CLB是FPGA內的基本邏輯單元。CLB的實際數量和特性會依器件的不同而不同,但是每個CLB都包含一個可配置開關矩陣, 此矩陣由4或6個輸入、一些選型電路(多路復用器等)和觸發器組成。開關矩陣是高度靈活的,可以對其進行配置以便 處理組合邏輯、移位寄存器或RAM。在Xilinx公司的FPGA器件中,CLB由多個(一般為4個或2個)相同的Slice和附加邏輯構成。每個CLB模塊不僅可以用于實現組合邏輯、時序邏輯,還可以配置為分布式RAM和分布式ROM。

**自動駕駛的“芯”殺手 **
自動駕駛和高級駕駛輔助系統(ADAS)細分市場正在經歷蛻變,對計算和傳感器功能提出了新的復雜需求。FPGA擁有其他芯片解決方案無法比擬的獨特優勢,是滿足自動駕駛行業不斷發展變化的優良選擇。FPGA是芯片領域的一種特殊技術, 一方面能夠 通過軟件工具進行反復多次配置 ,另一方面擁 有豐富的IO接口和計算單元 。因此,FPGA能夠根據應用場景的具體需求,同時處理流水線并行和數據并行,天生具有計算性能高、延遲低、功耗小等優勢。 FPGA具備高吞吐量、高能效以及實時處理等多項優點,非常契合自動駕駛所需要的技術需求。高級輔助駕駛系統(ADAS)、 車載體驗(IVE)應用的標準和要求正在快速演變,系統設計人員關注的問題主要包括出色的靈活性和更快的開發周期,同時維持更高的性能功耗比。通過可重新編程的FPGA和不斷增多的汽車級產品相結合,支持汽車設計師滿足設計要求,在不斷變化的汽車行業中始終保持領先。

**適應性更強的平臺 ** 對于自動駕駛芯片來說真正的價值在于計算引擎的利用率,即理論性能和實際性能之間的差異。FPGA包含大量的路由鏈路以及大量的小型存儲。這些資源的組合使設計人員能夠為其計算引擎創建定制的數據饋送網絡,以獲得更高的利用水平。可編程邏輯為客戶提供了高度的靈活性,以適應ADAS和自動駕駛等新興應用領域不斷變化的需求。利用改進的接口標準、算法創新和新的傳感器技術,都需要適應性強的平臺,不僅可以支持軟件更改,還可以支持硬件更改,而這正是FPGA芯片的優勢所在。 FPGA芯片擁有 可擴展性 。可拓展的芯片改變了可編程邏輯的數量,大多采用引腳兼容的封裝。這意味著開發人員可以創建單個ECU平臺來承載低、中、高版本的ADAS功能包,并根據需要通過選擇所需的最小密度芯片來縮放成本。
差異化解決方案 ** FPGA芯片允許開發人員創建獨特的差異化處理解決方案,這些解決方案可以針對特定應用或傳感器進行優化。這對于ASSP芯片來說是無法實現的,即使是那些提供專用加速器的芯片,它們的使用方式也受到限制,而且基本上可以提供給所有競爭對手。例如Xilinx的長期客戶已經創建了只有他們可以訪問的高價值IP庫,并且這些功能可以被公司的各種產品 使用。從90nm節點開始,對于大批量汽車應用,Xilinx的芯片就已經極具成本效益,有超過1.6億顆**Xilinx芯片在該行業獲得應用。
ASIC方案
ASIC定義及特點 ** ASIC芯片可根據終端功能不同**分為TPU芯片、DPU芯片和NPU芯片等。其中, TPU為張量處理器 ,專用于機器學習。如Google于2016年5月研發針對[Tensorflow平臺的可編程AI加速器,其內部指令集在Tensorflow程序變化或更新算法時可運行。 DPU即Data Processing Unit ,可為數據中心等計算場景提供引擎。 NPU是神經網絡處理器 ,在電路層模擬人類神經元和突觸,并用深度學習指令集直接處理大規模電子神經元和突觸數據。 ASIC有全定制和半定制兩種設計方式。全定制依靠巨大的人力時間成本投入以完全自主的方式完成整個集成電路的設計流程,雖然比半定制的ASIC更為靈活性能更好,但它的開發效率與半定制相比甚為低下。

**性能提升明顯 ** ASIC芯片非常適合人工智能的應用場景。 例如英偉達首款專門為深度學習從零開始設計的芯片Tesla P100數據處理速度 是其2014年推出GPU系列的12倍。谷歌為機器學習定制的芯片TPU將硬件性能提升至相當于當前芯片按摩爾定律發展 7 年后的水平。正如CPU改變了當年龐大的計算機一樣,人工智能ASIC芯片也將大幅改變如今AI硬件設備的面貌。如大 名鼎鼎的AlphaGo使用了約170個圖形處理器(GPU)和1200個中央處理器(CPU),這些設備需要占用一個機房,還要配備大功率的空調,以及多名專家進行系統維護。而如果全部使用專用芯片,極大可能只需要一個普通收納盒大小的空間,且功耗也會大幅降低。 ASIC技術路線是有限開放,芯片公司需要面向與駕駛相關的主流網絡、模型、算子進行開發。 在相同性能下,芯片的面積更小、成本更低、功耗更低。ASIC技術路線未來的潛力會很大,選擇ASIC路線并不意味著要對不同車型開發不同的ASIC,或進行不同的驗證。因為不同車型需要實現的功能大致相同,而且芯片面對模型和算子進行有限開放,算法快速迭代不會影響到芯片對上層功能的支持。車廠與芯片設計公司合作,進行差異化定制,或是更好的選擇。因為即使是進行差異化的定制,芯片內部50%的部分也是通用的。芯片設計公司可以在原有版本的基礎上進行差異化設計,實現部分差異功能。
**主流架構方案對比:三種主流架構 **
FPGA是在PAL、GAL等可編程器件的基礎上進一步發展的產物。它是作為專用集成電路領域中的一種半定制電路而出現的,既解決了定制電路的不足,又克服了原有可編程器件門電路數有限的缺點。
**優點:可以無限次編程,延時性比較低,同時擁有流水線并行和數據并行、實時性最強、靈活性最高。缺點:開發難度大、只適合定點運算、價格比較昂貴。 ** 圖形處理器 (GPU) ,又稱顯示核心、視覺處理器、顯示芯片,是一種專門在個人電腦、工作站、游戲機和一些移動設備(如平板、手機等)上做圖像和圖形相關運算工作的微處理器。
**優點:提供了多核并行計算的基礎結構,且核心數非 常多,可以支撐大量數據的并行計算,擁有更高的浮點運算能力。缺點:管理控制能力(最弱),功耗(最高)。
** ASIC ,即專用集成電路,指應特定用戶要求和特定電子系統的需要而設計、制造的集成電路。目前用CPLD(復雜可編程 邏輯器件)和FPGA(現場可編程邏輯陣列)來進行ASIC設計是最為流行的方式之一。優點:它作為集成電路技術與特定用 戶的整機或系統技術緊密結合的產物,與通用集成電路相比具有體積更小、重量更輕、功耗更低、可靠性提高、性能提高、保密性增強、成本降低等優點。缺點:靈活性不夠,成本比FPGA貴。
隨著ADAS、自動駕駛技術的興起,以及軟件定義汽車的逐步深入,智能汽車對于計算能力和海量數據處理能力等的需求暴增,傳統汽車的芯片“堆疊”方案已經無法滿足自動駕駛的算力需求。芯片最終是為車企的車載計算平臺服務的,在 “軟件定義汽車”的情況下,解決智能駕駛系統計算平臺的支撐問題,無法只通過芯片算力堆疊來實現。
芯片是軟件的舞臺,衡量芯片優劣的標準,要看芯片之上的軟件能否最大化地發揮作用,算力和軟件之間需要有效匹配。兩款相同算力的芯片比較,能讓軟件運行得更高效的芯片才是“好芯片”。決定算力真實值最主要因素是內存( SRAM和 DRAM)帶寬,還有實際運行頻率(即供電電壓或溫度),以及算法的batch尺寸。
單顆芯片算力TOPS是關鍵指標,但并非唯一,自動駕駛是一個復雜系統,需要車路云邊協同。所以它的較量除了芯還有軟硬協同還有平臺以及工具鏈等等。芯片算力的無限膨脹和硬件預埋不會是未來的趨勢,硬件也需要匹配實際。高背后是高功耗和低利用率的問題。
事件相機簡介
**簡介及工作機制 ** 事件相機的靈感來自人眼和動物的視覺,也有人稱之為硅視網膜。 生物的視覺只針 對有變化的區域才敏感,事件相機就是捕捉事件的產生或者變化的產生。
、
在傳統的視覺領域,相機傳回的信息是同步的,所謂同步,就是在某一時刻t,相機會進行曝光,把這一時刻所有的像素填在一個矩陣里回傳,產生一張照片。一張照 片上所有的像素都對應著同一時刻。至于視頻,不過是很多幀的圖片,相鄰圖片間 的時間間隔可大可小,這便是幀率(frame rate),也稱為時延(time latency)** 。事件相機類似于人類的大腦和眼睛,跳過不相關的背景,直接感知一個場景的核心, 創建純事件而非數據。 ** 事件相機的工作機制是,當某個像素所處位置的亮度發生變化達到一定閾值時,相機就會回傳一個上述格式的事件,其中前兩項為事件的像素坐標,第三項為事件發 生的時間戳,最后一項取值為極性(polarity)0、1(或者-1、1),代表亮度是由低到高還是由高到低。
就這樣,在整個相機視野內,只要有一個像素值變化,就會回傳一個事件,這些所有的事件都是異步發生的(再小的時間間隔也不可能完全同時),所以事件的時間 戳均不相同,由于回傳簡單,所以和傳統相機相比,它具有低時延的特性,可以捕獲很短時間間隔內的像素變化,延遲是微秒級的。
**在自動駕駛領域的應用 ** 當今自動駕駛領域所運用的視覺識別算法,基本上都基于卷積神經網絡,視覺算法的運算本質上是一次次的卷積運算。這種計算并不復雜,本質上只涉及到加減乘除,也就是一種乘積累加運算。但這種簡單運算在卷積神經網絡中是大量存在的,這就對處理器的性能提出了很高的要求。 以ResNet-152為例,這是一個152層的卷積神經網絡,它處理一張224*224大小的圖像所需的計算量大約是226億次,如果 這個網絡要處理一個1080P的30幀的攝像頭,他所需要的算力則高達每秒33萬億次,十分龐大。
**通過減少無效計算節約算力 **
自動駕駛領域99%的視覺數據在AI處理中是無用的背景。例如檢測鬼探頭,變化的區域是很小一部分,但傳統的視覺處理 仍然要處理99%的沒有出現變化的背景區域,這不僅浪費了大量的算力,也浪費了時間。亦或者像在沙礫里有顆鉆石,AI芯片和傳統相機需要識別每一顆沙粒,篩選出鉆石,但人類只需要看一眼就能檢測到鉆石,AI芯片和傳統相機耗費的時 間是人類的100倍或1000倍。 除了冗余信息減少和幾乎沒有延遲的優點外,事件相機的優點還有由于低時延,在拍攝高速物體時,傳統相機由于會有 一段曝光時間會發生模糊,而事件相機則幾乎不會。此外事件相機擁有真正的高動態范圍,由于事件相機的特質,在光強較強或較弱的環境下,傳統相機均會“失明”,但像素變化仍然存在,所以事件相機仍能看清眼前的東西。]()
-
asic
+關注
關注
34文章
1205瀏覽量
120600 -
cpu
+關注
關注
68文章
10888瀏覽量
212370 -
gpu
+關注
關注
28文章
4760瀏覽量
129128
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論