 GPT模型成功的背后用到了哪些以數據為中心的人工智能技術?
GPT模型成功的背后用到了哪些以數據為中心的人工智能技術?
人工智能(Artificial Intelligence, AI)最近取得了巨大的進展,特別是大語言模型(Large Language Models, LLMs),比如最近火爆全網的ChatGPT和GPT-4。GPT模型在各項自然語言處理任務上有著驚人的效果。至于具體有多強,這里就不再贅述了。做了這么多年AI研究好久沒這么激動過了。沒試過的朋友趕緊試一下!
正所謂「大力出奇跡」,把參數量調「大」能提高模型性能已經成為了大家的普遍共識。但是僅僅增加模型參數就夠了嗎?仔細閱讀GPT的一系列論文后就會發現,僅僅增加模型參數是不夠的。它們的成功在很大程度上還歸功于用于訓練它們的大量和高質量的數據。
在本文中,我們將從數據為中心的人工智能視角去分析一系列GPT模型(之后會用Data-centric AI以避免啰嗦)。Data-centric AI大體上可以分文三個目標:訓練數據開發(training data development)、推理數據開發(inference data development)和數據維護(data maintenance)。本文將討論GPT模型是如何實現(或者可能即將實現)這三個目標的。感興趣的讀者歡迎戳下方鏈接了解更多信息。
綜述論文:Data-centric Artificial Intelligence: A Survey
短篇介紹:Data-centric AI: Perspectives and Challenges
GitHub資源(不定期持續更新,歡迎貢獻):https://github.com/daochenzha/data-centric-AI
1
什么是大語言模型?
什么又是GPT模型?
這章將簡單介紹下大語言模型和GPT模型,對它們比較熟悉的讀者可以跳過。大語言模型指的是一類自然語言處理模型。顧名思義,大語言模型指的是比較「大」的(神經網絡)語言模型。語言模型在自然語言處理領域已經被研究過很久了,它們常常被用來根據上文來推理詞語的概率。例如,大語言模型的一個基本功能是根據上文預測缺失詞或短語的出現概率。我們常常需要用到大量的數據去訓練模型,使得模型學到普遍的規律。

通過上文來預測缺失詞示意圖
GPT模型是由OpenAI開發的一系列大語言模型,主要包括GPT-1,GPT-2,GPT-3,InstructGPT以及最近上線的ChatGPT/GPT-4。就像其他大語言模型一樣,GPT模型的架構主要基于Transformer,以文本和位置信息的向量為輸入,使用注意力機制來建模詞之間的關系。
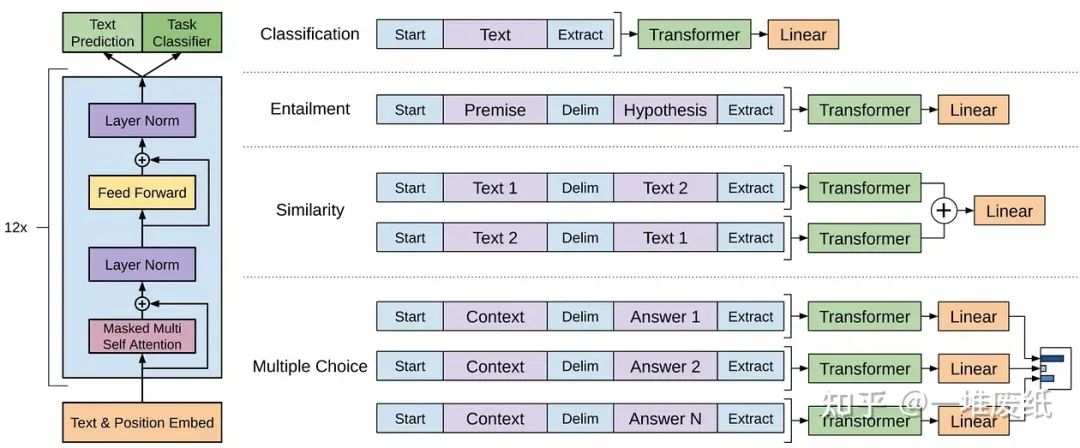
GPT-1模型的網絡結構,圖片來自原論文 https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
之后的GPT系列模型結構大體上都與GPT-1類似,主要區別在于更多參數(更多層,更多隱含層維度等等)。

GPT系列模型大小比較
2什么是Data-centric AI?
Data-centric AI是一種搭建AI系統的新理念,被@吳恩達老師大力倡導。我們這里引用下他給出的定義
Data-centric AI is the discipline of systematically engineering the data used to build an AI system.
— Andrew Ng
傳統的搭建AI模型的方法主要是去迭代模型,數據相對固定。比如,我們通常會聚焦于幾個基準數據集,然后設計各式各樣的模型去提高預測準確率。這種方式我們稱作以模型為中心(model-centric)。然而,model-centric沒有考慮到實際應用中數據可能出現的各種問題,例如不準確的標簽,數據重復和異常數據等。準確率高的模型只能確保很好地「擬合」了數據,并不一定意味著實際應用中會有很好的表現。
與model-centric不同,Data-centric更側重于提高數據的質量和數量。也就是說Data-centric AI關注的是數據本身,而模型相對固定。采用Data-centric AI的方法在實際場景中會有更大的潛力,因為數據很大程度上決定了模型能力的上限。
需要注意的是,「Data-centric」與「Data-driven」(數據驅動),是兩個根本上不同的概念。后者僅強調使用數據去指導AI系統的搭建,這仍是聚焦于開發模型而不是去改變數據。
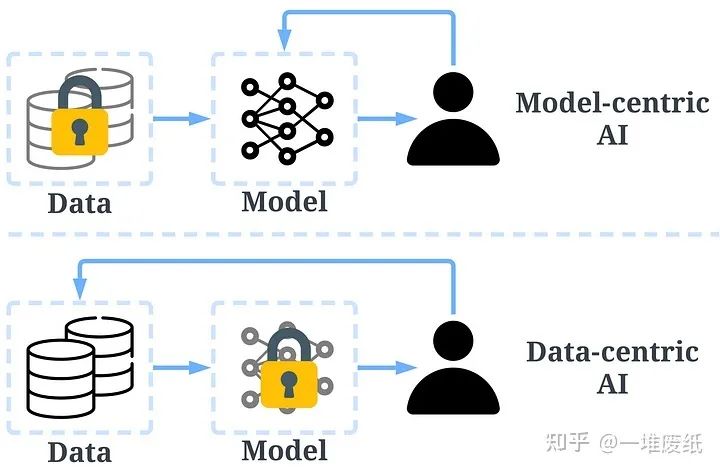
Data-centric AI和model-centric AI的區別,圖片來源于https://arxiv.org/abs/2301.04819
Data-centric AI框架包括三個目標:
訓練數據開發(training data development)旨在構建足夠數量的高質量數據,以支持機器學習模型的訓練。
推理數據開發(inference data development)旨在構建模型推理的數據,主要用于以下兩個目的:
評估模型的某種能力,比如構建對抗攻擊( Adversarial Attacks)數據以測試模型的魯棒性
解鎖模型的某種能力,比如提示工程(Prompt Engineering)
數據維護(data maintenance)旨在確保數據在動態環境中的質量和可靠性。在實際生產環境(production environment)中,我們并不是只訓練一次模型,數據和模型是需要不斷更新的。這個過程需要采取一定的措施去持續維護數據。
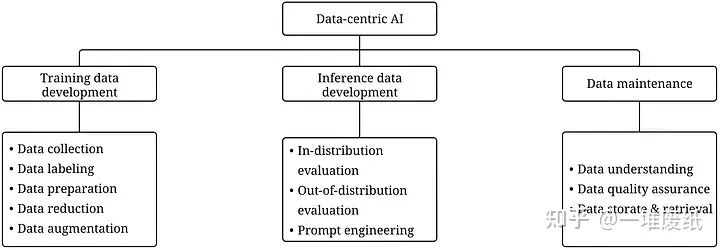
Data-centric AI框架第二層是目標,第三層是子目標,圖片來源于 https://arxiv.org/abs/2303.10158
3 為什么Data-centric AI是GPT模型取得成功的重要原因?
數月前,Yann LeCun發文稱ChatGPT在技術上并不是什么新鮮事物。的確如此,ChatGPT和GPT-4中使用的方法,比如Transformer、「從人類反饋中進行的強化學習」(Reinforcement Learning from Human Feedback,RLHF)等都不是什么新技術。即便如此,ChatGPT還是取得了以前的模型無法企及的驚人效果。那么,是什么推動了它的成功?

毋庸置疑,增加模型參數的數量對GPT模型的成功至關重要,但這只是其中的一個原因。通過詳細閱讀GPT-1、GPT-2、GPT-3、InstructGPT和ChatGPT/GPT-4論文中有關數據的描述,我們可以明顯看出OpenAI的工程師們花了極大心血去提高數據的質量和數量。以下,我們用Data-centric AI框架從三個維度進行分析。
訓練數據開發:從GPT-1到ChatGPT/GPT-4,通過更好的數據收集(data collection)、數據標注(data labeling)和數據準備(data preparation)策略,用于訓練GPT模型的數據數量和質量都得到了顯著提高。以下括號中標識了每個具體策略對應到Data-centric AI框架中的子目標。
GPT-1:訓練使用了BooksCorpus數據集。該數據集包含4629.00 MB的原始文本,涵蓋了各種類型的書籍,如冒險、奇幻和浪漫等。
用到的Data-centric AI策略:
無。
結果:
預訓練之后,在下游任務微調可以提高性能。
GPT-2:訓練使用了WebText數據集。這是OpenAI的一個內部數據集,通過從Reddit上抓取出站鏈接創建而成。
用到的Data-centric AI策略:
僅篩選并使用Reddit上至少獲得3個karma及以上的鏈接(數據收集)
用Dragnet和Newspaper這兩個工具去提取純文本(數據收集)
用了一些啟發式策略做了去重和數據清洗,具體策略論文沒有提到(數據準備)
結果:
經過篩選后,獲得了40 GB的文本(大概是GPT-1所用數據的8.6倍)。
GPT-2即便在沒有微調的情況下也能取得很不錯的效果。
GPT-3:訓練主要使用了Common Crawl,一個很大但質量不算很好的數據集。
用到的Data-centric AI策略:
訓練一個分類器來過濾掉低質量的文檔。
這里比較有意思的是,OpenAI把WebText當作標準,基于每個文檔與WebText之間的相似性來判斷質量高低(數據收集)
使用Spark的MinHashLSH對文檔進行模糊去重(數據準備)
把之前的WebText擴展下也加了進來,還加入了books corpora和Wikipedia數據(數據收集)
結果:
在對45TB的純文本進行質量過濾后,獲得了570GB的文本(僅選擇了1.27%的數據,可見對質量把控的力度很大,過濾完后的文本大約是GPT-2的14.3倍)。
訓練得到的模型比GPT-2更強了。
InstructGPT:在GPT-3之上用人類反饋去微調模型,使得模型與人類期望相符。
用到的Data-centric AI策略:
使用人類提供的答案來用有監督的方式微調模型。
OpenAI對標注人員的選擇極為嚴苛,對標注者進行了考試,最后甚至會發問卷確保標注者有比較好的體驗。
要是我的研究項目需要人工標注,能有人理我就不錯了,更別談考試和問卷(數據標注)
收集比較數據(人類對產生的答案根據好壞程度排序)來訓練一個獎勵模型,然后基于該獎勵模型使用「從人類反饋中進行的強化學習」(Reinforcement Learning from Human Feedback,RLHF)來微調(數據標注)
結果:
InstructGPT產生的結果更加真實、有更少的偏見、更符合人類的預期。
ChatGPT/GPT-4:至此,產品走向了商業化,OpenAI不再「Open」,不再披露具體細節。已知的是ChatGPT/GPT-4在很大程度上遵循了以前GPT模型的設計,并且仍然使用RLHF來調整模型(可能使用更多、更高質量的數據/標簽)。鑒于GPT-4的推理速度比ChatGPT慢很多,模型的參數數量大概率又變多了,那么也很有可能使用了一個更大的數據集。
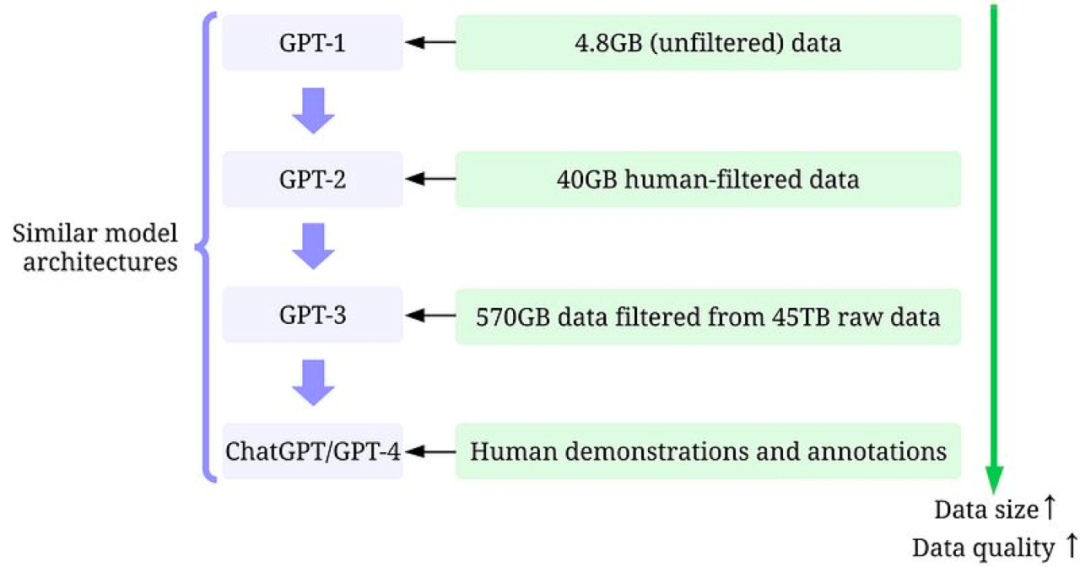
從GPT-1到ChatGPT/GPT-4,所用的訓練數據大體經歷了以下變化:小數據(小是對于OpenAI而言,對普通研究者來說也不小了)->大一點的高質量數據->更大一點的更高質量數據->高質量人類(指能通過考試的標注者)標注的高質量數據。模型設計并沒有很顯著的變化(除了參數更多以順應更多的數據),這正符合了Data-centric AI的理念。從ChatGPT/GPT-4的成功,我們可以發現,高質量的標注數據是至關重要的。在AI的任何子領域幾乎都是如此,即便是在很多傳統上的無監督任務上,標注數據也能顯著提高性能,例如弱監督異常檢測。OpenAI對數據和標簽質量的重視程度令人發指。正是這種執念造就了GPT模型的成功。這里順便給大家推薦下朋友做的可視化文本標注工具Potato,非常好用!
推理數據開發:現在的ChatGPT/GPT-4模型已經足夠強大,強大到我們只需要調整提示(推理數據)來達到各種目的,而模型則保持不變。例如,我們可以提供一段長文本,再加上特定的指令,比方說「summarize it」或者「TL;DR」,模型就能自動生成摘要。在這種新興模式下,Data-centric AI變得更為重要,以后很多AI打工人可能再也不用訓練模型了,只用做提示工程(prompt engineering)。

提示工程示例,圖片來源于https://arxiv.org/abs/2303.10158
當然,提示工程是一項具有挑戰性的任務,它很大程度上依賴于經驗。這篇綜述很好地總結了各種各樣的方法,有興趣的讀者可以繼續閱讀。與此同時,即使是語義上相似的提示,輸出也可能非常不同。在這種情況下,可能需要一些策略去降低輸出的方差,比如Soft Prompt-Based Calibration。
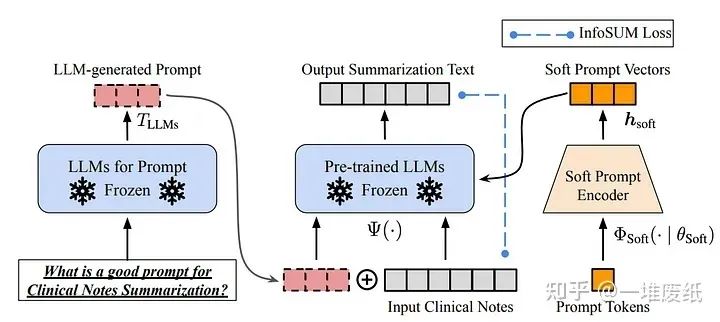
Soft prompt-based calibration,圖片來源于https://arxiv.org/abs/2303.13035v1
大語言模型的推理數據開發研究仍處于早期階段。我相信在不久的將來,很多其他任務中用到過的推理數據開發方法也會逐漸被遷移到大語言模型中,例如構建對抗攻擊(Adversarial Attacks)數據以測試模型的魯棒性。
數據維護:作為一款商業產品,ChatGPT/GPT-4一定不是僅僅訓練一次就結束了,而是會被持續更新和維護。我們在外部沒辦法知道OpenAI數據維護具體是如何進行的。因此,我們只能推測。OpenAI可能采取了如下策略:
持續數據收集:當我們使用ChatGPT/GPT-4時,我們輸入的提示和提供的反饋可以被OpenAI用來進一步提升他們的模型。在此過程中,模型開發者需要設計監測數據質量的指標和維護數據質量的策略,以收集更高質量的數據。
數據理解工具:開發各種工具來可視化和理解用戶數據可以幫助更好地理解用戶需求,并指導未來的改進方向。
高效數據處理:隨著ChatGPT/GPT-4用戶數量的迅速增長,高效的數據管理系統需要被開發,以幫助快速獲取相關數據進行訓練和測試。

ChatGPT/GPT-4 會收集用戶反饋
4 從大語言模型的成功中我們能學到什么?
大語言模型的成功可以說是顛覆性的。展望未來,我做幾個預測:
Data-centric AI變得更加重要。經過了多年的研究,模型設計已經相對比較成熟,特別是在Transformer出現之后(目前我們似乎還看不到Transformer的上限)。提高數據的數量和質量將成為未來提高AI系統能力的關鍵(或可能是唯一)途徑。此外,當模型變得足夠強大時,大多數人可能不需要再訓練模型。相反,我們只需要設計適當的推理數據(提示工程)便能從模型中獲取知識。因此,Data-centric AI的研究和開發將持續推動未來AI系統的進步。
大語言模型將為Data-centric AI提供更好的解決方案。許多繁瑣的數據相關工作目前已經可以借助大語言模型更高效地完成了。例如,ChatGPT/GPT-4已經可以編寫可以運行的代碼來處理和清洗數據了。此外,大語言模型甚至可以用于創建訓練數據。例如,最近的研究表明,使用大語言模型合成數據可以提高臨床文本挖掘模型的性能。
數據和模型的界限將變得模糊。以往,數據和模型是兩個分開的概念。但是,如今當模型足夠強大后,模型成為了一種「數據」或者說是數據的「容器」。在需要的時候,我們可以設計適當的提示語,利用大語言模型合成我們想要的數據。這些合成的數據反過來又可以用來訓練模型。這種方法的可行性在GPT-4上已經得到了一定程度的驗證。在報告中,一種被稱作rule-based reward models(RBRMs)的方法用GPT-4自己去判斷數據是否安全,這些標注的數據反過來又被用來訓練獎勵模型來微調GPT-4。有種左右手互搏的感覺了。我不經在想,之后的模型會通過這種方式實現自我進化嗎?細思極恐……
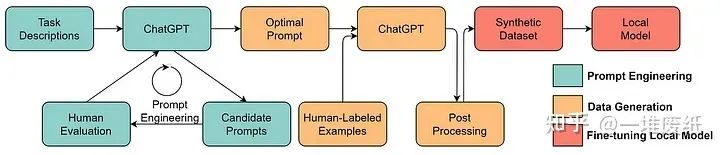
用ChatGPT來合成數據訓練下游模型,圖片來源于 https://arxiv.org/abs/2303.04360
回想起五年前,我還在糾結「如何才能提高文本分類的準確率」,多次失敗的經歷曾讓我一度懷疑自然語言處理和AI沒有半點關系。如今ChatGPT/GPT-4驚人的能力讓我提前見證了歷史!
未來AI的發展將走向何方?大語言模型的進展日新月異,經常看到一些研究自然語言處理的朋友們擔心大模型的出現會不會讓AI科研無路可走了。我認為完全不需要有這種擔心。技術永遠是不斷進步的。新技術的出現不可避免會取代舊的技術(這是進步),但同時也會催生更多新的研究方向。比如,近年來深度學習的飛速發展并沒有讓傳統機器學習的研究無路可走,相反,提供了更多的可供研究的方向。
同時,AI一個子領域的突破勢必會帶動其他子領域的蓬勃發展,這其中就有許多新的問題需要研究。比如,以ChatGPT/GPT-4為代表的大模型上的突破很可能會帶動計算機視覺的進一步提升,也會啟發很多AI驅動的應用場景,例如金融、醫療等等。無論技術如何發展,提高數據的質量和數量一定是提高AI性能的有效方法,Data-centric AI的理念將越來越重要。
那么大模型就一定是達成通用人工智能的方向嗎?我持保留態度。縱觀AI發展歷程,各個AI子領域的發展往往是螺旋上升、相互帶動的。這次大模型的成功是多個子領域的成功碰撞出的結果,例如模型設計(Transformer)、Data-centric AI(對數據質量的重視)、強化學習(RLHF)、機器學習系統(大規模集群訓練)等等,缺一不可。在大模型時代,我們在AI各個子領域依然都大有可為。比如,我認為強化學習相比大模型可能有更高的上限,因為它能自我迭代,可能不久的將來我們將見證由強化學習引領的比ChatGPT更驚艷的成果。對強化學習感興趣的讀者可以關注下我之前的文章DouZero斗地主AI深度解析,以及RLCard工具包介紹。
在這個AI發展日新月異的時代,我們需要不斷學習。我們對Data-centric AI這個領域進行了總結,希望能幫助大家快速高效地了解這個領域,相關鏈接見本文開頭。鑒于Data-centric AI是一個很大的領域,我們的總結很難面面俱到。歡迎感興趣的讀者去我們的GitHub上指正、補充。
審核編輯 :李倩
-
人工智能
+關注
關注
1792文章
47441瀏覽量
238989 -
語言模型
+關注
關注
0文章
530瀏覽量
10298 -
GPT
+關注
關注
0文章
354瀏覽量
15437
原文標題:GPT 模型成功的背后用到了哪些以數據為中心的人工智能(Data-centric AI)技術?
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論