 CV迎來GPT-3時刻:Meta開源“萬物可分割AI”模型
CV迎來GPT-3時刻:Meta開源“萬物可分割AI”模型

通過單擊、交互式點擊即可分割圖像或視頻
英偉達 AI 科學家 Jim Fan 在 Twitter 上驚呼,Meta 發布的 SAM 讓計算機視覺(CV)迎來 GPT-3 時刻。更不可思議的是,模型和數據(1100萬張圖像,10億個掩碼)都已經基于 Apache 2.0 許可開源。
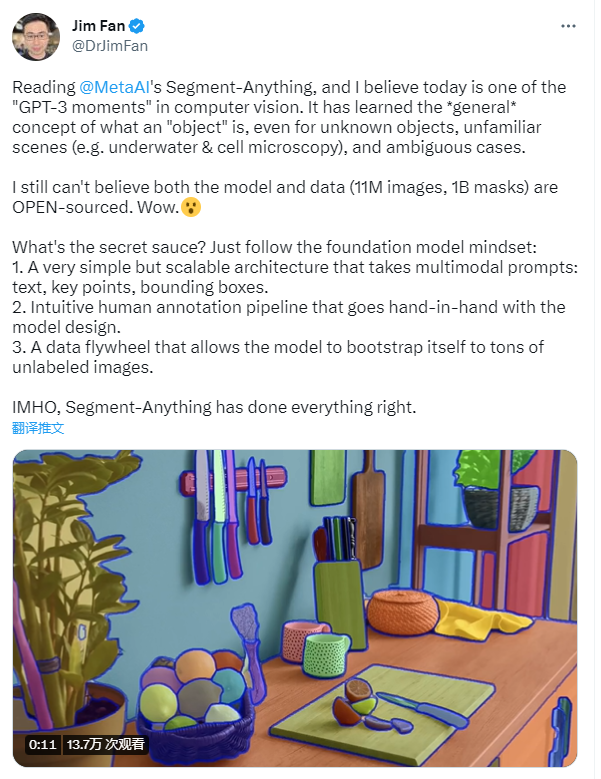
今日,Meta 發布首個可“任意圖像分割”的基礎模型 Segment-Anything Model(SAM)和最大規模的“任意分割 10 億掩碼數據集「Segment Anything 1-Billion mask dataset (SA-1B)」,將自然語言領域的 prompt 范式引入了 CV 領域,進而為 CV 基礎模型提供更廣泛的支持與深度研究。
SAM Demo:https://segment-anything.com/
開源地址:https://github.com/facebookresearch/segment-anything
論文地址:https://ai.facebook.com/research/publications/segment-anything/
SA-1B數據集:https://ai.facebook.com/datasets/segment-anything/
1. 圖片、視頻皆可分割
分割,作為 CV 領域的核心任務,被廣泛應用在科學圖像到編輯照片等應用程序員中,但是,為特定任務創建準確的分割模型通常需要技術專家進行高度專業化的工作,并且需要訪問 AI 培訓基礎設施和大量精心注釋領域內方面的數據能力。
SAM 通過 prompt 工程能力即可分割任意想分割的圖像。

截圖自SAM論文
SAM 已經學會了物體的一般概念,并且可以為任何圖像或視頻中的任何對象生成掩模,甚至包括在訓練期間沒有遇到過的對象和圖像類型。
SAM 足夠通用,可以涵蓋廣泛的用例,并且可以直接在新的圖像“領域”上使用——無論是水下照片還是細胞顯微鏡——都不需要額外的訓練(這種能力通常稱為零樣本遷移)。
之前,為了解決分割問題,一般會采用兩種分類方法:
第一種是交互式分割,可以對任何類別的對象進行分割,但需要人員通過迭代地細化掩模來指導該方法。
第二種是自動分割,允許預先定義特定對象類別(例如貓或椅子)的分割,但需要大量手動注釋的對象進行訓練(例如數千甚至數萬個已經過分割處理的貓示例),以及計算資源和技術專業知識來訓練分割模型。這兩種方法都沒有提供通用、完全自動化的分割方法。
SAM 集合了上面兩種方法,成為一個單一模型,可以輕松執行交互式分割和自動分割。
1、SAM 允許用戶通過單擊、交互式點擊或邊界框提示來分割對象;
2、當面臨關于正在分割的對象歧義時,SAM可以輸出多個有效掩碼,這是解決現實世界中分割問題所必需的重要能力;
3、SAM可以自動查找并遮罩圖像中的所有對象;
4、在預計算圖像嵌入后,SAM 可以為任何提示生成實時分割掩碼,從而允許與模型進行實時交互。
SAM 在超過 10億個掩碼組成的多樣化高質量數據集上進行訓練(作為該項目的一部分),從而使其能夠推廣到訓練期間未觀察到的新類型對象和圖像之外。這種推廣能力意味著,總體來說,從業者將不再需要收集自己的分割數據并微調用于他們用例場景中的模型。
2. SAM 背后的技術
Meta AI 團隊在官博中直言到,SAM 的研發靈感來自于自然語言和計算機視覺中的 “prompt 工程”,只需對新數據集和任務執行零樣本學習和少樣本學習即可使其能夠基于任何提示返回有效的分割掩模。其中,提示可以是前景/背景點、粗略框或掩模、自由文本或者一般情況下指示圖像中需要進行分割的任何信息。有效掩模的要求意味著即使提示不明確并且可能涉及多個對象(例如,在襯衫上的一個點既可能表示襯衫也可能表示穿著它的人),輸出應該是其中一個對象合理的掩模。這項任務用于預訓練模型,并通過提示解決通用下游分割任務。
研發人員觀察到預訓練任務和交互式數據收集對模型設計施加了特定的限制。特別是,為了使標注員能夠在實時交互中高效地進行標注,模型需要在 Web 瀏覽器上以實時方式運行于 CPU 上。雖然運行時間約束意味著質量和運行時間之間存在權衡,但他們發現,簡單的設計在實踐中產生良好的結果。
在模型設計中,圖像編碼器為圖像生成一次性嵌入,而輕量級編碼器實時將任何提示轉換為嵌入向量。然后,在輕量級解碼器中將這兩個信息源組合起來以預測分割掩模。計算出圖像嵌入后,SAM 可以在 Web 瀏覽器中僅用 50 毫秒的時間根據任何提示生成一個段落。
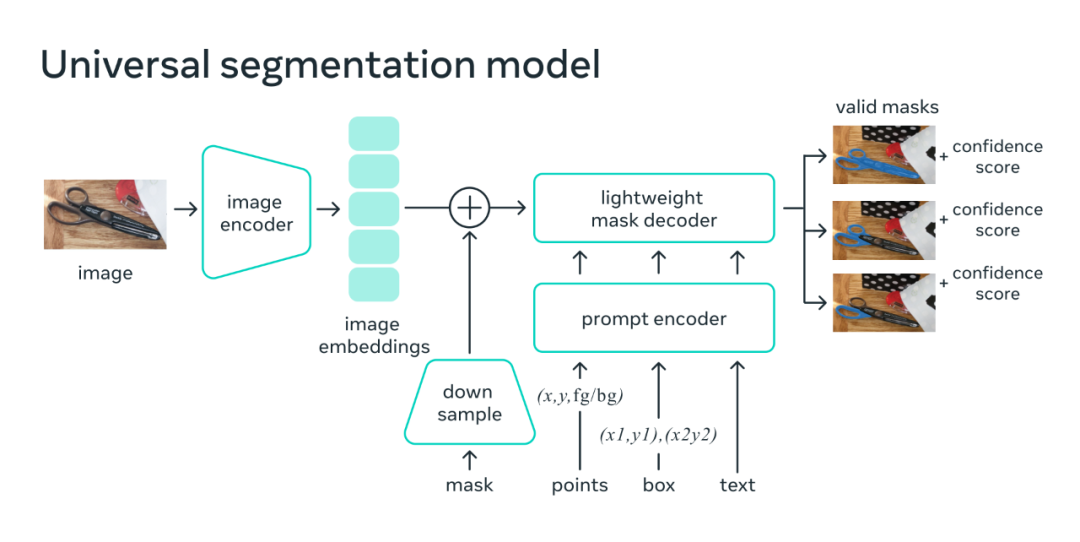
在 Web 瀏覽器中,SAM 高效地將圖像特征和一組提示嵌入映射到生成分割掩模。
3. 超 1100 萬張照片,1B+掩碼
數據集來自 SAM 收集,而在訓練起初,并無任何數據,而今天發布的數據集已是迄今為止最大的數據了。注釋員使用 SAM 交互式地注釋圖像,然后新注釋的數據反過來用于更新 SAM,彼此相互作用,重復執行此循環來改善模型和數據集。
使用 SAM 收集新分割掩碼比以往任何時候都更快,僅需約 14 秒即可交互式地注釋掩碼。相對于標記邊界框所需時間約 7 秒鐘(使用最快速度標記接口),每個掩碼標記流程只慢 2 倍左右。與之前大規模分割數據收集努力相比,該模型比 COCO 完全手動基于多邊形遮罩注釋快 6.5 倍,比先前最大的數據注釋工作快了 2 倍,并且是基于模型協助完成任務 。
盡管如此,交互式的標記掩碼依然無法擴展創建 10 億個掩碼數據庫,于是便有了用于創建 SA-1B 數據庫的“引擎”。該引擎有三個“檔位”。
在第一檔中,模型協助注釋員,相互作用;
第二檔是完全自動化的注釋與輔助注釋相結合,有助于增加收集到的掩碼的多樣性;
數據引擎的最后一個檔位是完全自動遮罩創建,進而使數據庫可以擴展。
最終,數據集在超過 1100 萬張經過許可和隱私保護的圖像上收集到了超過 11 億個分割掩模。SA-1B 比任何現有的分割數據集多 400 倍,經人類評估驗證,這些掩模具有高質量和多樣性,在某些情況下甚至可以與以前規模小得多、完全手動注釋的數據集中的掩模相媲美。
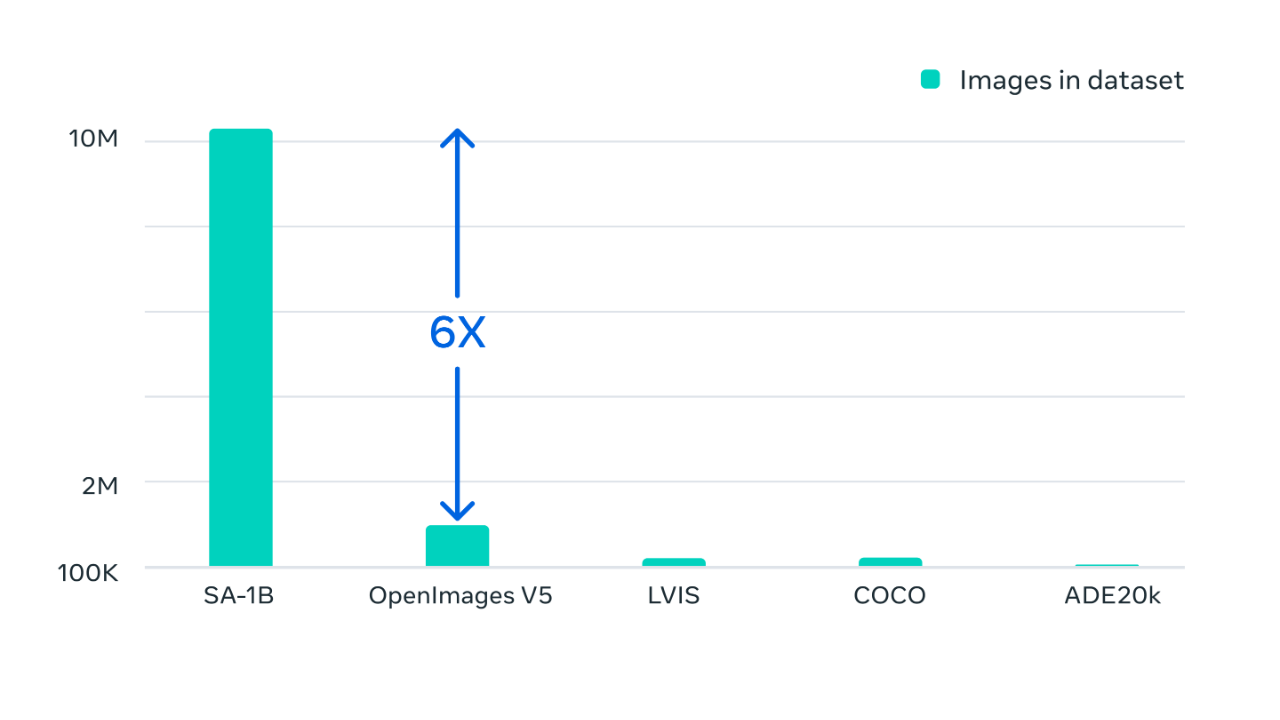
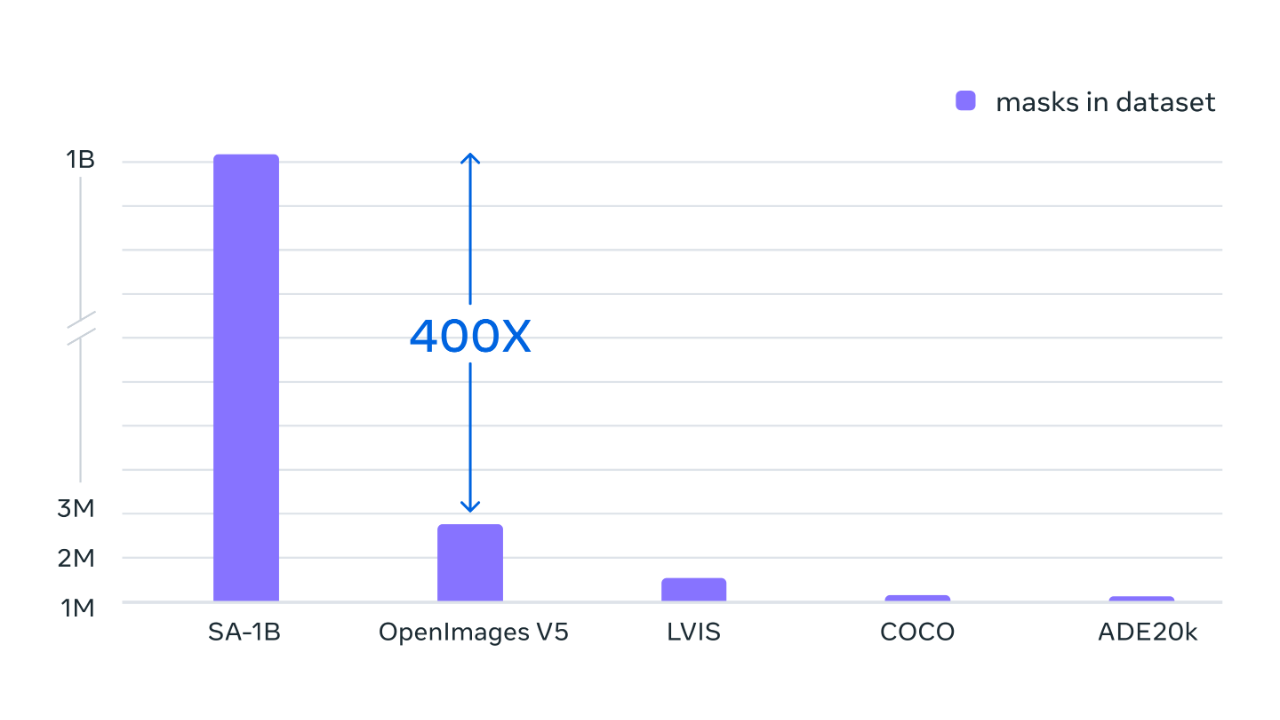
Segment Anything 是通過使用數據引擎收集數百萬張圖像和掩模進行訓練,從而得到一個超 10 億個分割掩模的數據集,這比以往任何分割數據集都大400倍。
將來,SAM 可能被用于任何需要在圖像中找到和分割任何對象的領域應用程序。
對于 AI 研究社區或其他人來說,SAM 可能更普遍理解世界、例如理解網頁視覺和文本內容等更大型 AI 系統中組件;
在 AR/VR 領域,SAM 可以根據用戶注視選擇一個對象,然后將其“提升”到 3D;
對于內容創作者來說,SAM 可以改進諸如提取碎片或視頻編輯等創意應用程序;
SAM 也可用來輔助科學領域研究,如地球上甚至空間自然現象, 例如通過定位要研究并跟蹤視頻中的動物或物體。


最后,SAM 團隊表示,通過分享他們的研究和數據集,來進一步加速分割更常見的圖像和視頻。可提示式分割模型可以作為較大系統中的組件執行分割任務。未來,通過組合系統可擴展單個模型使用,通過提示工程等技術實現可組合系統設計,進而使得比專門針對固定任務集訓練的系統能夠得更廣泛的領域應用。
審核編輯 :李倩
-
AI
+關注
關注
87文章
30896瀏覽量
269108 -
開源
+關注
關注
3文章
3349瀏覽量
42501 -
CV
+關注
關注
0文章
53瀏覽量
16861 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45993
原文標題:CV 迎來 GPT-3 時刻:Meta 開源“萬物可分割 AI ”模型
文章出處:【微信號:軟件質量報道,微信公眾號:軟件質量報道】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文解析人工智能中GPT-3 到底有多厲害?
技術與市場:AI大模型的“Linux時刻”降臨
線下活動 | 開源工作坊第2期——開源與萬物互聯
史上最大AI模型GPT-3你要開始收費了 接下去可能用不起它了

微軟獲得AI神器 GPT-3 獨家授權,引來馬斯克等業內人士怒懟
GPT-3引發公眾的遐想 能根據文字產生圖片的AI!
史上最大AI模型GPT-3強勢霸榜Github
GPT系列的“高仿” 最大可達GPT-3大小 自主訓練
谷歌開發出超過一萬億參數的語言模型,秒殺GPT-3

Eleuther AI:已經開源了復現版GPT-3的模型參數
第一篇綜述!分割一切模型(SAM)的全面調研







 工商網監
工商網監
評論