 【AI簡報20230407期】 MLPref放榜!大模型時代算力領域“潛力股”浮出水面、CV或迎來GPT-3時刻
【AI簡報20230407期】 MLPref放榜!大模型時代算力領域“潛力股”浮出水面、CV或迎來GPT-3時刻
嵌入式 AI
AI 簡報 20230407 期
1. MLPref放榜!大模型時代算力領域“潛力股”浮出水面:梅開二度拿下世界第一,今年獲雙料冠軍
原文:https://mp.weixin.qq.com/s/KJCIjhqClBzcqfi-qtJp-A
后ChatGPT時代下的大模型“算力難”問題,“快、好、省”的解法,又來了一個。
就在今天,享有“AI界奧運會”之稱的全球權威AI基準評測MLPerf Inference v3.0,公布了最新結果——
來自中國的AI芯片公司,墨芯人工智能(下文簡稱“墨芯”),在最激烈的ResNet50模型比拼中奪冠!

而且在此成績背后,墨芯給大模型時代下的智能算力問題,提供了一個非常具有價值的方向——
它奪冠所憑借的稀疏計算,堪稱是大模型時代最不容忽視的算力“潛力股”。
不僅如此,墨芯此次還是斬獲了開放任務分區“雙料冠軍”的那種:
-
墨芯S40計算卡,以127,375 FPS,獲得單卡算力全球第一;
-
墨芯S30計算卡,以383,520 FPS算力,獲整機4卡算力全球第一。
而且墨芯靠著這套打法,在制程方面更是用首顆稀疏計算芯片12nm的Antoum?打敗了4nm。
不得不提的是,這次對于墨芯而言,還是“梅開二度”;因為它在上一屆MLPerf,憑借S30同樣是拿下了冠軍。
在與GPT-3參數相當的開源LLM——1760億參數的BLOOM上,4張墨芯S30計算卡在僅采用中低倍稀疏率的情況下,就能實現25 tokens/s的內容生成速度,超過8張A100。
那么稀疏計算為什么對大模型有這般良效?
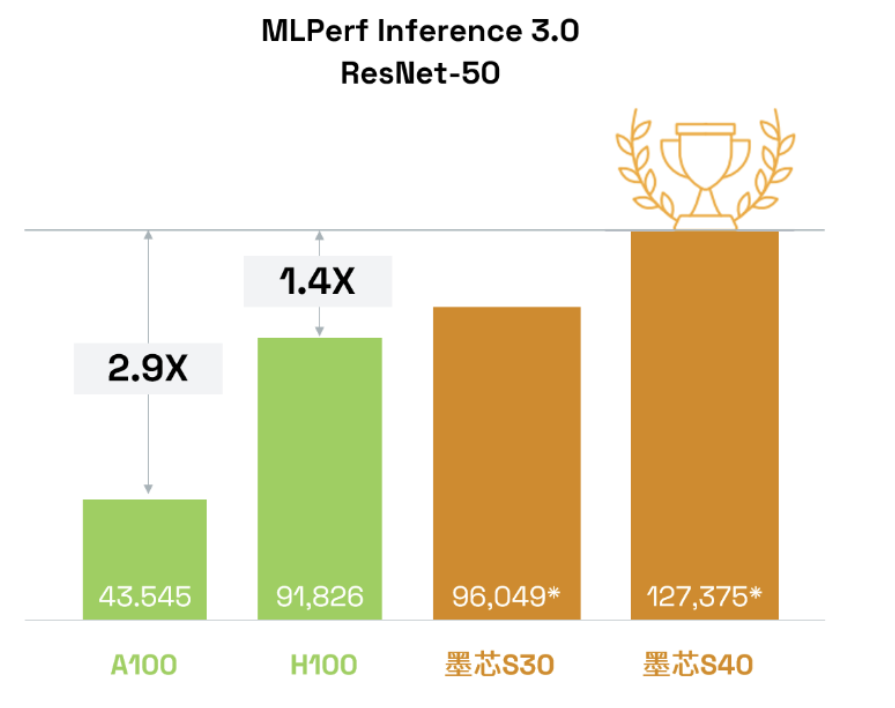
算力紀錄再度被刷新
我們不妨先來看下,墨芯所刷新的紀錄到底是怎樣的一個水平。
以墨芯S40為例,在MLPerf數據中心的圖像任務主流模型ResNet-50上,且在相同數據集、相同精度條件下,算力達127,375 FPS。
這個“分數”是老牌玩家英偉達H100、A100的1.4倍和2.9倍!
為什么稀疏計算會成為正解?
簡單理解,稀疏化就是一種聰明的數據處理和模型壓縮方式,它讓神經網絡在計算時,能夠僅啟用所需的神經元。
而稀疏計算就是將原有AI計算的大量矩陣運算中,含有零元素或無效元素的部分剔除,以加快計算速度,由此也能進一步降低模型訓練成本。
自從Transformers掀起大模型浪潮后,稀疏計算也成為了大廠關注的重點方向。
2021年,谷歌研究和OpenAI就罕見合作論文《Sparse is Enough in Scaling Transformers》,力證稀疏計算能為大模型帶來數十倍加速。
而更早以前,2017年OpenAI就發布了稀疏計算內核,實現了在同等計算開銷的情況下,能計算更深的神經網絡。

谷歌這幾年也密集發布了稀疏計算方面的多項工作,包括Pathways、PaLM、MoE、GLaM等。
其中Pathways架構是稀疏計算領域的一項重要工作。谷歌在當初發布時將其稱為“下一代人工智能架構”,其技術博客由谷歌大腦負責人Jeff Dean親自操刀撰寫。
由此可見谷歌對Pathways架構及稀疏計算的重視。
其核心原理在于稀疏計算,即在執行任務時僅稀疏激活模型的特定部分,計算真正有用的元素。
并且在該架構發布沒幾天后,谷歌就跟進了稀疏計算領域的另一項重要工作:發布基于Pathways架構的5400億參數大模型PaLM。
之后,谷歌還提出了首個多模態稀疏化模型LIMoE,它在降低模型計算量上的優勢非常突出。
因為采用了稀疏計算,可以實現執行一次任務只調用模型中的一個子模型,那么這次任務的成本將會和標準Transformer差不多。比如LIMoE-H/14總共有5.6B參數,但是通過稀疏化,它只會使用每個token的675M參數。
就在今年ChatGPT大火后,稀疏化GPT方法也被提出,能夠實現不降低模型效果的情況下,將大模型權重降低一半。
除了在算法架構方面以外,硬件計算側對于稀疏化的關注也在提升。
比如英偉達就在其Ampere架構中首次支持2倍稀疏計算。
Ampere架構為英偉達A 100帶來了第三代Tensor Core核心,使其可以充分利用網絡權值下的細粒度稀疏化優勢。
相較于稠密數學計算(dense math),能夠在不犧牲深度學習矩陣乘法累加任務精度的情況下,將最大吞吐量提高了2倍。
以上大廠的動作,無疑都印證了稀疏計算會是大模型時代下AI計算的有效解之一。
由此也就不難理解,為什么墨芯會押中稀疏計算這一方向,并取得最新戰績。
一方面是很早洞察到了行業的發展趨勢;另一方面也是自身快速準確做出了定位和判斷。
墨芯創始人兼CEO王維表示,他們從2018、2019年就看到了稀疏計算給AI計算帶來了數量級上的性能提升。
與此同時,Transformers開啟了大模型時代,讓AI從1.0時代步入2.0,推動了AI在應用場景、算力需求等方面的改變。
尤其是算力方面,王維認為已經產生了質變:
“小模型時代,用場景數據訓練小模型,研發和部署周期短,對算力的需求主要是通用性、易用性。到了大模型時代,大模型主要基于Transformers模型架構,更追求計算速度和算力成本。”
而做稀疏計算,不只是墨芯一家想到了,前面提到英偉達也在推進這方面進展,不過王維表示,這對于GPU公司而言可能是“意外收獲”,但如果專注稀疏計算的話,需要做的是十倍甚至百倍加速。
因此,墨芯選擇的路線是從算法提升上升到軟硬協同層面。
2022年,墨芯發布首顆高稀疏倍率芯片Antoum?,能夠支持32倍稀疏,大幅降低大模型所需的計算量。
墨芯在MLPerf中開放分區的提交結果刷新記錄,也是對這一路線的進一步印證。
據透露,不僅在MLPerf上表現出色,墨芯的產品商業落地上也進展迅速。
墨芯AI計算卡發布數月就已實現量產,在互聯網等領域成單落地。ChatGPT走紅后墨芯也收到大量客戶問詢,了解稀疏計算在大模型上的算力優勢與潛力。
如今,ChatGPT開啟新一輪AI浪潮,大模型領域開啟競速賽、算力需求空前暴增。
如微軟為訓練ChatGPT打造了一臺超算——由上萬張英偉達A100芯片打造,甚至專門為此調整了服務器架構,只為給ChatGPT和新必應AI提供更好的算力。還在Azure的60多個數據中心部署了幾十萬張GPU,用于ChatGPT的推理。
畢竟,只有充足的算力支持,才能推動模型更快迭代升級。
怪不得行業內有聲音說,這輪趨勢,英偉達當屬最大幕后贏家。
但與此同時,摩爾定律式微也是事實,單純堆硬件已經無法滿足當下算力需求,由此這也推動了算力行業迎來更新一輪機遇和變革。可以看到,近兩年并行計算等加速方案愈發火熱,這就是已經發生的變化。
而ChatGPT的火熱,無疑加速了這一變革。在真實需求的推動下,算力領域硬件軟件創新突破也會更快發生,模型會重新定義算法,算法會重新定義芯片。
2. CV不存在了?Meta發布「分割一切」AI 模型,CV或迎來GPT-3時刻
原文:https://mp.weixin.qq.com/s/-LWG3rOz60VWiwdYG3iaWQ
這下 CV 是真不存在了。< 快跑 >」這是知乎網友對于一篇 Meta 新論文的評價。
如標題所述,這篇論文只做了一件事情:(零樣本)分割一切。類似 GPT-4 已經做到的「回答一切」。
除了2.0之外,還發布了一系列PyTorch域庫的beta更新,包括那些在樹中的庫,以及包括 TorchAudio、TorchVision和TorchText在內的獨立庫。TorchX的更新也同時發布,可以提供社區支持模式。

Meta 表示,這是第一個致力于圖像分割的基礎模型。自此,CV 也走上了「做一個統一某個(某些?全部?)任務的全能模型」的道路。
在此之前,分割作為計算機視覺的核心任務,已經得到廣泛應用。但是,為特定任務創建準確的分割模型通常需要技術專家進行高度專業化的工作,此外,該項任務還需要大量的領域標注數據,種種因素限制了圖像分割的進一步發展。
Meta 在論文中發布的新模型名叫 Segment Anything Model (SAM) 。他們在博客中介紹說,「SAM 已經學會了關于物體的一般概念,并且它可以為任何圖像或視頻中的任何物體生成 mask,甚至包括在訓練過程中沒有遇到過的物體和圖像類型。SAM 足夠通用,可以涵蓋廣泛的用例,并且可以在新的圖像『領域』上即開即用,無需額外的訓練。」在深度學習領域,這種能力通常被稱為零樣本遷移,這也是 GPT-4 震驚世人的一大原因。

論文地址:https://arxiv.org/abs/2304.02643
項目地址:https://github.com/facebookresearch/segment-anything
Demo 地址:https://segment-anything.com/
除了模型,Meta 還發布了一個圖像注釋數據集 Segment Anything 1-Billion (SA-1B),據稱這是有史以來最大的分割數據集。該數據集可用于研究目的,并且 Segment Anything Model 在開放許可 (Apache 2.0) 下可用。
我們先來看看效果。如下面動圖所示,SAM 能很好的自動分割圖像中的所有內容:
英偉達人工智能科學家 Jim Fan 表示:「對于 Meta 的這項研究,我認為是計算機視覺領域的 GPT-3 時刻之一。它已經了解了物體的一般概念,即使對于未知對象、不熟悉的場景(例如水下圖像)和模棱兩可的情況下也能進行很好的圖像分割。最重要的是,模型和數據都是開源的。恕我直言,Segment-Anything 已經把所有事情(分割)都做的很好了。」
方法介紹
此前解決分割問題大致有兩種方法。第一種是交互式分割,該方法允許分割任何類別的對象,但需要一個人通過迭代細化掩碼來指導該方法。第二種,自動分割,允許分割提前定義的特定對象類別(例如,貓或椅子),但需要大量的手動注釋對象來訓練(例如,數千甚至數萬個分割貓的例子)。這兩種方法都沒有提供通用的、全自動的分割方法。
SAM 很好的概括了這兩種方法。它是一個單一的模型,可以輕松地執行交互式分割和自動分割。該模型的可提示界面允許用戶以靈活的方式使用它,只需為模型設計正確的提示(點擊、boxes、文本等),就可以完成范圍廣泛的分割任務。
總而言之,這些功能使 SAM 能夠泛化到新任務和新領域。這種靈活性在圖像分割領域尚屬首創。
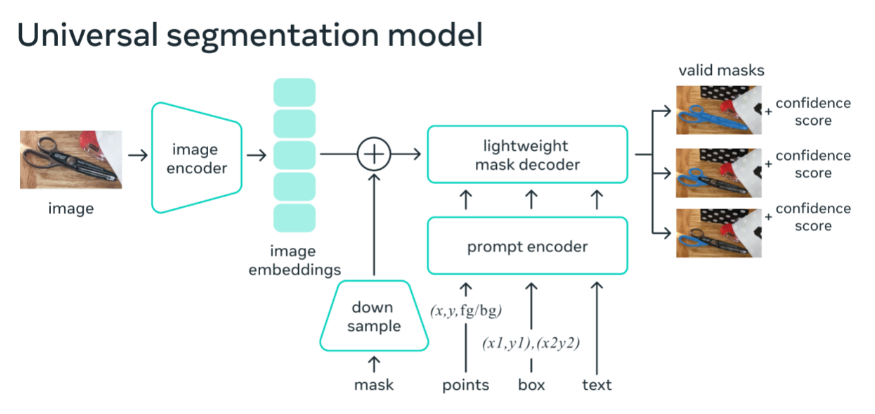
Meta 表示,他們受到語言模型中提示的啟發,因而其訓練完成的 SAM 可以為任何提示返回有效的分割掩碼,其中提示可以是前景、背景點、粗框或掩碼、自由格式文本,或者說能指示圖像中要分割內容的任何信息。而有效掩碼的要求僅僅意味著即使提示不明確并且可能指代多個對象(例如,襯衫上的一個點可能表示襯衫或穿著它的人),輸出也應該是一個合理的掩碼(就如上面動圖「SAM 還能為為不明確的提示生成多個有效掩碼」所示)。此任務用于預訓練模型并通過提示解決一般的下游分割任務。
如下圖所示 ,圖像編碼器為圖像生成一次性嵌入,而輕量級編碼器將提示實時轉換為嵌入向量。然后將這兩個信息源組合在一個預測分割掩碼的輕量級解碼器中。在計算圖像嵌入后,SAM 可以在 50 毫秒內根據網絡瀏覽器中的任何提示生成一個分割。
1100 萬張圖片,1B+ 掩碼
數據集是使用 SAM 收集的。標注者使用 SAM 交互地注釋圖像,之后新注釋的數據又反過來更新 SAM,可謂是相互促進。
使用該方法,交互式地注釋一個掩碼只需大約 14 秒。與之前的大規模分割數據收集工作相比,Meta 的方法比 COCO 完全手動基于多邊形的掩碼注釋快 6.5 倍,比之前最大的數據注釋工作快 2 倍,這是因為有了 SAM 模型輔助的結果。
最終的數據集超過 11 億個分割掩碼,在大約 1100 萬張經過許可和隱私保護圖像上收集而來。SA-1B 的掩碼比任何現有的分割數據集多 400 倍,并且經人工評估研究證實,這些掩碼具有高質量和多樣性,在某些情況下甚至在質量上可與之前更小、完全手動注釋的數據集的掩碼相媲美 。
未來展望
通過研究和數據集共享,Meta 希望進一步加速對圖像分割以及更通用圖像與視頻理解的研究。可提示的分割模型可以充當更大系統中的一個組件,執行分割任務。作為一種強大的工具,組合(Composition)允許以可擴展的方式使用單個模型,并有可能完成模型設計時未知的任務。
Meta 預計,與專門為一組固定任務訓練的系統相比,基于 prompt 工程等技術的可組合系統設計將支持更廣泛的應用。SAM 可以成為 AR、VR、內容創建、科學領域和更通用 AI 系統的強大組件。比如 SAM 可以通過 AR 眼鏡識別日常物品,為用戶提供提示。
3. 谷歌TPU超算,大模型性能超英偉達,已部署數十臺:圖靈獎得主新作
原文:https://mp.weixin.qq.com/s/uEAlKdpzutOpnPGmg5dOjw
我們還沒有看到能與 ChatGPT 相匹敵的 AI 大模型,但在算力基礎上,領先的可能并不是微軟和 OpenAI。
本周二,谷歌公布了其訓練語言大模型的超級計算機的細節,基于 TPU 的超算系統已經可以比英偉達的同類更加快速、節能。
谷歌張量處理器(tensor processing unit,TPU)是該公司為機器學習定制的專用芯片(ASIC),第一代發布于 2016 年,成為了 AlphaGo 背后的算力。與 GPU 相比,TPU 采用低精度計算,在幾乎不影響深度學習處理效果的前提下大幅降低了功耗、加快運算速度。同時,TPU 使用了脈動陣列等設計來優化矩陣乘法與卷積運算。
當前,谷歌 90% 以上的人工智能訓練工作都在使用這些芯片,TPU 支撐了包括搜索的谷歌主要業務。作為圖靈獎得主、計算機架構巨擘,大衛?帕特森(David Patterson)在 2016 年從 UC Berkeley 退休后,以杰出工程師的身份加入了谷歌大腦團隊,為幾代 TPU 的研發做出了卓越貢獻。

如今 TPU 已經發展到了第四代,谷歌本周二由 Norman Jouppi、大衛?帕特森等人發表的論文《 TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings 》詳細介紹了自研的光通信器件是如何將 4000 多塊芯片并聯成為超級計算機,以提升整體效率的。

論文鏈接:
https://arxiv.org/ftp/arxiv/papers/2304/2304.01433.pdf
TPU v4 的性能比 TPU v3 高 2.1 倍,性能功耗比提高 2.7 倍。基于 TPU v4 的超級計算機擁有 4096 塊芯片,整體速度提高了約 10 倍。對于類似大小的系統,谷歌能做到比 Graphcore IPU Bow 快 4.3-4.5 倍,比 Nvidia A100 快 1.2-1.7 倍,功耗低 1.3-1.9 倍。
除了芯片本身的算力,芯片間互聯已成為構建 AI 超算的公司之間競爭的關鍵點,最近一段時間,谷歌的 Bard、OpenAI 的 ChatGPT 這樣的大語言模型(LLM)規模正在爆炸式增長,算力已經成為明顯的瓶頸。
由于大模型動輒千億的參數量,它們必須由數千塊芯片共同分擔,并持續數周或更長時間進行訓練。谷歌的 PaLM 模型 —— 其迄今為止最大的公開披露的語言模型 —— 在訓練時被拆分到了兩個擁有 4000 塊 TPU 芯片的超級計算機上,用時 50 天。
谷歌表示,通過光電路交換機(OCS),其超級計算機可以輕松地動態重新配置芯片之間的連接,有助于避免出現問題并實時調整以提高性能。
下圖展示了 TPU v4 4×3 方式 6 個「面」的鏈接。每個面有 16 條鏈路,每個塊總共有 96 條光鏈路連接到 OCS 上。要提供 3D 環面的環繞鏈接,相對側的鏈接必須連接到相同的 OCS。因此,每個 4×3 塊 TPU 連接到 6 × 16 ÷ 2 = 48 個 OCS 上。Palomar OCS 為 136×136(128 個端口加上 8 個用于鏈路測試和修復的備用端口),因此 48 個 OCS 連接來自 64 個 4×3 塊(每個 64 個芯片)的 48 對電纜,總共并聯 4096 個 TPU v4 芯片。
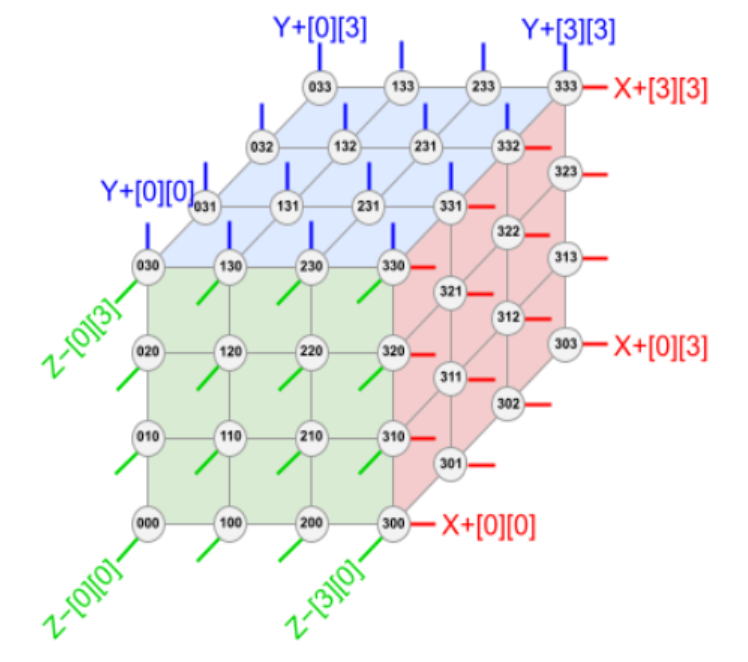
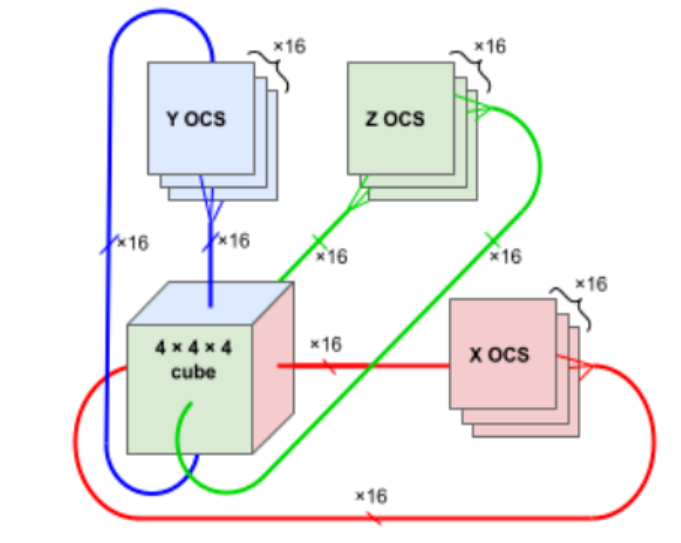
根據這樣的排布,TPU v4(中間的 ASIC 加上 4 個 HBM 堆棧)和帶有 4 個液冷封裝的印刷電路板 (PCB)。該板的前面板有 4 個頂部 PCIe 連接器和 16 個底部 OSFP 連接器,用于托盤間 ICI 鏈接。
與超級計算機一樣,工作負載由不同規模的算力承擔,稱為切片:64 芯片、128 芯片、256 芯片等。下圖顯示了當主機可用性從 99.0% 到 99.9% 不等有,及沒有 OCS 時切片大小的「有效輸出」。如果沒有 OCS,主機可用性必須達到 99.9% 才能提供合理的切片吞吐量。對于大多數切片大小,OCS 也有 99.0% 和 99.5% 的良好輸出。
與 Infiniband 相比,OCS 的成本更低、功耗更低、速度更快,成本不到系統成本的 5%,功率不到系統功率的 3%。每個 TPU v4 都包含 SparseCores 數據流處理器,可將依賴嵌入的模型加速 5 至 7 倍,但僅使用 5% 的裸片面積和功耗。
「這種切換機制使得繞過故障組件變得容易,」谷歌研究員 Norm Jouppi 和谷歌杰出工程師大衛?帕特森在一篇關于該系統的博客文章中寫道。「這種靈活性甚至允許我們改變超級計算機互連的拓撲結構,以加速機器學習模型的性能。」
在新論文上,谷歌著重介紹了稀疏核(SparseCore,SC)的設計。在大模型的訓練階段,embedding 可以放在 TensorCore 或超級計算機的主機 CPU 上處理。TensorCore 具有寬 VPU 和矩陣單元,并針對密集操作進行了優化。由于小的聚集 / 分散內存訪問和可變長度數據交換,在 TensorCore 上放置嵌入其實并不是最佳選擇。在超級計算機的主機 CPU 上放置嵌入會在 CPU DRAM 接口上引發阿姆達爾定律瓶頸,并通過 4:1 TPU v4 與 CPU 主機比率放大。數據中心網絡的尾部延遲和帶寬限制將進一步限制訓練系統。
對此,谷歌認為可以使用 TPU 超算的總 HBM 容量優化性能,加入專用 ICI 網絡,并提供快速收集 / 分散內存訪問支持。這導致了 SparseCore 的協同設計。
SC 是一種用于嵌入訓練的特定領域架構,從 TPU v2 開始,后來在 TPU v3 和 TPU v4 中得到改進。SC 相對劃算,只有芯片面積的約 5% 和功率的 5% 左右。SC 結合超算規模的 HBM 和 ICI 來創建一個平坦的、全局可尋址的內存空間(TPU v4 中為 128 TiB)。與密集訓練中大參數張量的全部歸約相比,較小嵌入向量的全部傳輸使用 HBM 和 ICI 以及更細粒度的分散 / 聚集訪問模式。
作為獨立的核心,SC 允許跨密集計算、SC 和 ICI 通信進行并行化。下圖顯示了 SC 框圖,谷歌將其視為「數據流」架構(dataflow),因為數據從內存流向各種直接連接的專用計算單元。
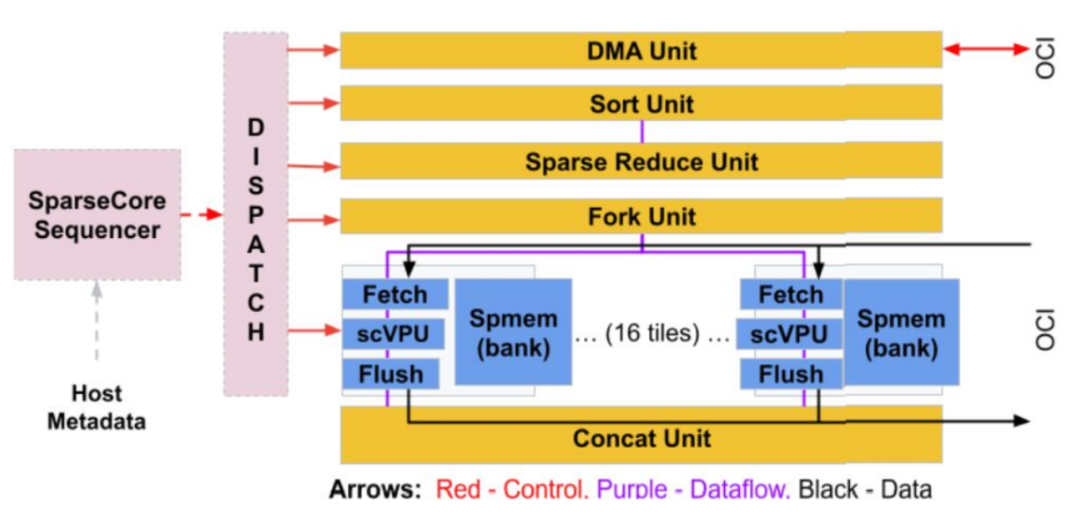
TPU v4 比當代 DSA 芯片速度更快、功耗更低,如果考慮到互連技術,功率邊緣可能會更大。通過使用具有 3D 環面拓撲的 3K TPU v4 切片,與 TPU v3 相比,谷歌的超算也能讓 LLM 的訓練時間大大減少。
性能、可擴展性和可用性使 TPU v4 超級計算機成為 LaMDA、MUM 和 PaLM 等大型語言模型 (LLM) 的主要算力。這些功能使 5400 億參數的 PaLM 模型在 TPU v4 超算上進行訓練時,能夠在 50 天內維持 57.8% 的峰值硬件浮點性能。
谷歌表示,其已經部署了數十臺 TPU v4 超級計算機,供內部使用和外部通過谷歌云使用。
4. 130億參數,8個A100訓練,UC伯克利發布對話模型Koala
原文:https://mp.weixin.qq.com/s/uI5-sUOY2vdr1ekX-bh_WQ
自從 Meta 發布并開源了 LLaMA 系列模型,來自斯坦福大學、UC 伯克利等機構的研究者們紛紛在 LLaMA 的基礎上進行「二創」,先后推出了 Alpaca、Vicuna 等多個「羊駝」大模型。
羊駝已然成為開源社區的新晉頂流。由于「二創」過于豐富,生物學羊駝屬的英文單詞都快不夠用了,但是用其他動物的名字給大模型命名也是可以的。
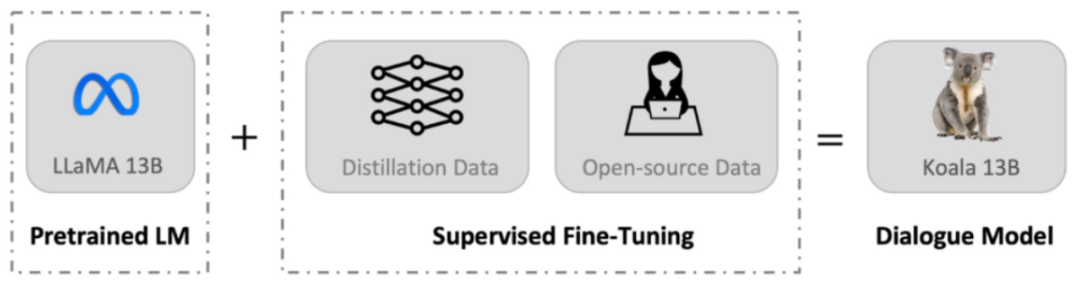
最近,UC 伯克利的伯克利人工智能研究院(BAIR)發布了一個可以在消費級 GPU 上運行的對話模型 Koala(直譯為考拉)。Koala 使用從網絡收集的對話數據對 LLaMA 模型進行微調。
項目地址:
https://bair.berkeley.edu/blog/2023/04/03/koala/
Demo 地址:
https://chat.lmsys.org/?model=koala-13b
開源地址:
https://github.com/young-geng/EasyLM
Koala 概述
與 Vicuna 類似,Koala 也使用從網絡收集的對話數據對 LLaMA 模型進行微調,其中重點關注與 ChatGPT 等閉源大模型對話的公開數據。
研究團隊表示,Koala 模型在 EasyLM 中使用 JAX/Flax 實現,并在配備 8 個 A100 GPU 的單個 Nvidia DGX 服務器上訓練 Koala 模型。完成 2 個 epoch 的訓練需要 6 個小時。在公共云計算平臺上,進行此類訓練的成本通常低于 100 美元。
研究團隊將 Koala 與 ChatGPT 和斯坦福大學的 Alpaca 進行了實驗比較,結果表明:具有 130 億參數的 Koala-13B 可以有效地響應各種用戶查詢,生成的響應通常優于 Alpaca,并且在超過一半的情況下與 ChatGPT 性能相當。
Koala 最重要的意義是它表明:在質量較高的數據集上進行訓練,那么小到可以在本地運行的模型也可以獲得類似大模型的優秀性能。這意味著開源社區應該更加努力地管理高質量數據集,因為這可能比簡單地增加現有系統的規模更能實現安全、真實和強大的模型。從這個角度看,Koala 是 ChatGPT 一種小而精的平替。
不過,Koala 還只是一個研究原型,在內容、安全性和可靠性方面仍然存在重大缺陷,也不應用于研究之外的任何用途。
數據集和訓練
構建對話模型的主要障礙是管理訓練數據。ChatGPT、Bard、Bing Chat 和 Claude 等大型對話模型都使用帶有大量人工注釋的專有數據集。為了構建 Koala 的訓練數據集,研究團隊從網絡和公共數據集中收集對話數據并整理,其中包含用戶公開分享的與大型語言模型(例如 ChatGPT)對話的數據。
不同于其他模型盡可能多地抓取網絡數據來最大化數據集,Koala 是專注于收集小型高質量數據集,包括公共數據集中的問答部分、人類反饋(正面和負面)以及與現有語言模型的對話。具體而言,Koala 的訓練數據集包括如下幾個部分:
ChatGPT 蒸餾數據:
-
公開可用的與 ChatGPT 對話數據(ShareGPT);
-
Human ChatGPT 比較語料庫 (HC3),其中同時使用來自 HC3 數據集的人類和 ChatGPT 響應。
開源數據:
-
Open Instruction Generalist (OIG);
-
斯坦福 Alpaca 模型使用的數據集;
-
Anthropic HH;
-
OpenAI WebGPT;
-
OpenAI Summarization。
實驗與評估
該研究進行了一項人工評估,將 Koala-All 與 Koala-Distill、Alpaca 和 ChatGPT 幾個模型的生成結果進行比較,結果如下圖所示。其中,使用兩個不同的數據集進行測試,一個是斯坦福的 Alpaca 測試集,其中包括 180 個測試查詢(Alpaca Test Set),另一個是 Koala Test Set。
總的來說,Koala 模型足以展示 LLM 的許多功能,同時又足夠小,方便進行微調或在計算資源有限的情況下使用。研究團隊希望 Koala 模型成為未來大型語言模型學術研究的有用平臺,潛在的研究應用方向可能包括:
-
安全性和對齊:Koala 允許進一步研究語言模型的安全性并更好地與人類意圖保持一致。
-
模型偏差:Koala 使我們能夠更好地理解大型語言模型的偏差,深入研究對話數據集的質量問題,最終有助于改進大型語言模型的性能。
-
理解大型語言模型:由于 Koala 模型可以在相對便宜的消費級 GPU 上運行,并且執行多種任務,因此 Koala 使我們能夠更好地檢查和理解對話語言模型的內部結構,使語言模型更具可解釋性。
5. 這款編譯器能讓Python和C++一樣快:最高提速百倍,MIT出品
原文:https://mp.weixin.qq.com/s/EOfsFCZa_IaqIsmsrxSujQ
自深度學習興起以來,Python 一直是最熱門的編程語言之一,它在數據科學和機器學習領域占主導地位,甚至是科學和數學計算領域的主角。如今你能想象到的任何項目,幾乎都可以找到一個相應的 Python 包。
然而,盡管高級語言的簡化語法使其易于學習和使用,但和 C 或 C++ 等低級語言相比,它的速度更慢。
麻省理工學院計算機科學與人工智能實驗室(CSAIL)的研究人員希望通過 Codon 來改變這一現狀,Codon 是一種基于 Python 的編譯器,允許用戶編寫與 C 或 C++ 程序一樣高效運行的 Python 代碼,同時可以定制和適應不同的需求和環境。
該研究的最新論文《Codon: A Compiler for High-Performance Pythonic Applications and DSLs》發表在了 2 月份的第 32 屆 ACM SIGPLAN 編譯器構建國際會議上。

項目鏈接:
https://github.com/exaloop/codon
論文:
https://dl.acm.org/doi/abs/10.1145/3578360.3580275
在開發工作中,人們需要使用編譯器將源代碼轉換為可由計算機處理器執行的機器代碼,Codon 能幫助開發者在 Python 中創建新的領域特定語言(DSL),同時仍然獲得其他語言的性能優勢。
「常規 Python 會被編譯成所謂的字節碼,該字節碼在虛擬機中執行,這就會讓速度慢上很多,」Codon 論文的主要作者 Ariya Shajii 表示,「通過 Codon,我們則進行本地編譯,因此你可以直接在 CPU 上運行最終結果 —— 不經過中間虛擬機或解釋器。」
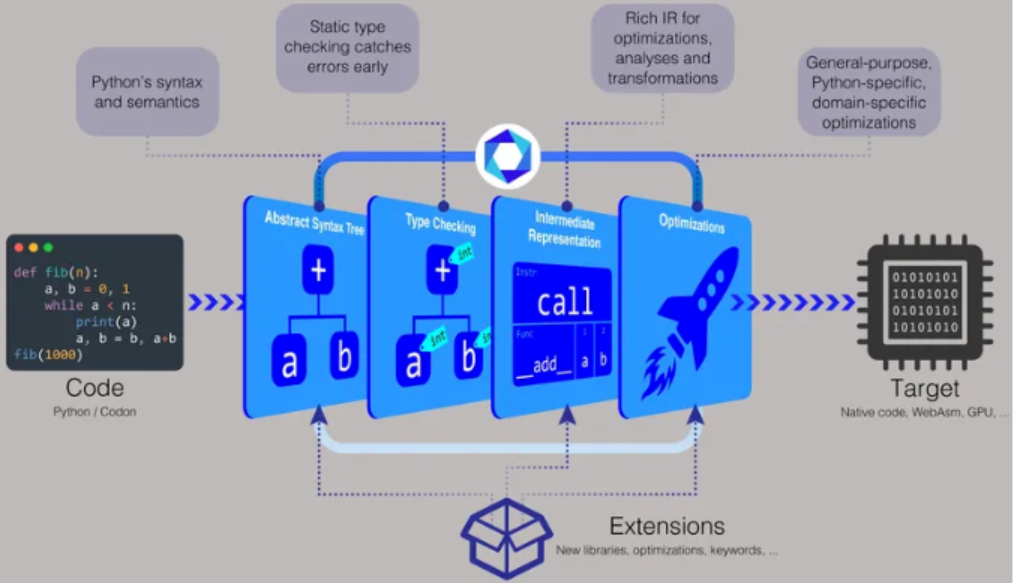
基于 Python 的編譯器帶有適用于 Linux 和 macOS 的預構建二進制文件,你還可以從源代碼構建或生成可執行文件。「使用 Codon,你可以像 Python 一樣分發源代碼,或者你可以將它編譯成二進制文件,」Shajii 說。「如果你想分發一個二進制文件,它將與像 C++ 這樣的語言一樣,例如一個 Linux 二進制文件或一個 Mac 二進制文件。」
為了讓 Codon 更快,研究人員決定在編譯時執行類型檢查。類型檢查涉及將數據類型(例如整數、字符串、字符或浮點數等)分配給值。例如數字 5 可以分配為整數,字母 c 可以分配為字符,單詞 hello 可以分配為字符串,十進制數 3.14 可以分配為浮點數。
「在常規 Python 中,所有類型都給了 runtime,」Shajii 介紹道。「使用 Codon,我們在編譯過程中進行類型檢查,這讓我們避免了在 runtime 進行所有昂貴的類型操作。」
MIT CSAIL 首席研究員 Saman Amarasinghe 補充說,「如果你有一種動態語言(比如 Python),每次你有一些數據時,你都需要在它周圍保留很多額外的元數據,以確定 runtime 的類型。Codon 取消了這種元數據,因此代碼速度更快,數據更小。」
根據 Shajii 的說法,Codon 在運行時沒有任何不必要的數據或類型檢查,所以開銷為零。在性能方面,「Codon 通常與 C++ 不相上下。與 Python 相比,我們通常看到的是 10 到 100 倍的速度改進。」
另一方面,Codon 的方法有其權衡。「我們進行這種靜態類型檢查,并且不允許使用 Python 的一些動態特性,比如在 runtime 動態更改類型,」Shajii 表示。
「還有一些 Python 庫我們還沒有實現。」Amarasinghe 補充說,「Python 已經過無數人的實際測試,而 Codon 還沒有達到那樣的水平,它需要運行更多的程序,獲得更多的反饋,并加固更多。達到常規 Python 的穩定水平需要一些時間。」
Codon 最初設計用于基因組學和生物信息學的工作。研究人員嘗試了大約 10 個用 Python 編寫的常用基因組學應用程序,并使用 Codon 對其進行了編譯,與最初的手動優化實現相比實現了 5 到 10 倍的加速。
「如今這些領域的數據集已變得非常大,而像 Python 和 R 這樣的高級語言速度太慢,無法處理每組測序 TB 級的數據量,」Shajii 說道。「這就是我們想要填補的空白 —— 通過構建一種無需寫 C 或 C++ 代碼即可處理大數據的方法,從而為非計算機科學或專業開發者的領域專家提供幫助。」
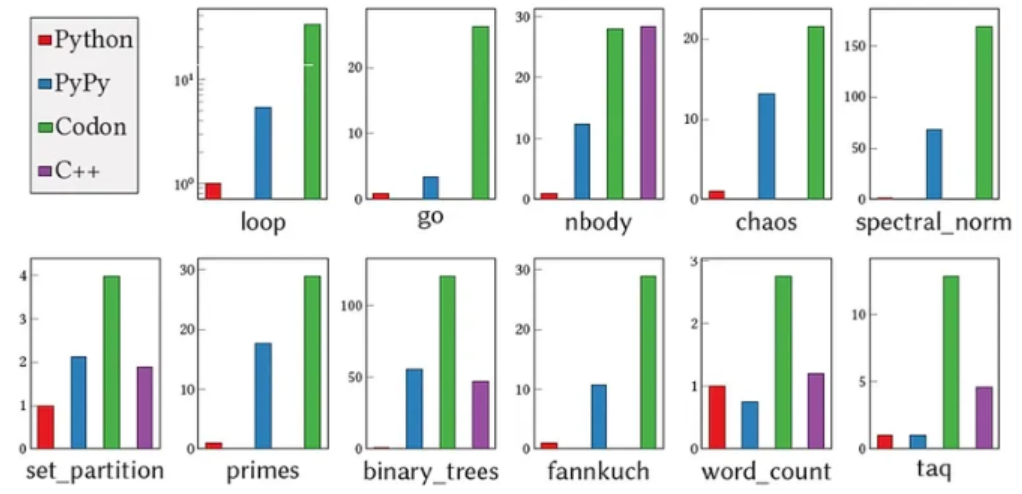
除了基因組學,Codon 還可以應用于處理海量數據集的類似應用程序,以及基于 Python 的編譯器支持的 GPU 編程和并行編程等領域。事實上,Codon 現在正通過初創公司 Exaloop 在生物信息學、深度學習和量化金融領域進行商業應用,Shajii 創立了該公司,旨在將 Codon 從學術項目轉變為行業應用。
為了使 Codon 能夠適應不同領域,該團隊開發了一個插件系統。「它就像一個可擴展的編譯器,」Shajii 說道。「你可以為基因組學或其他領域編寫插件,這些插件可以有新的庫和新的編譯器優化。」
此外,公司和機構可以使用 Codon 來制作原型和開發自己的應用程序。「我們看到的一種模式是:人們使用 Python 進行原型設計和測試,因為它易于使用,但到了某些重要事項上,他們就不得不重寫應用程序,或讓其他人用 C 或 C++ 在更大的數據集上進行重寫與測試,」Shajii 表示。「通過 Codon,你就可以完全使用 Python,并獲得兩全其美的好處。」
關于 Codon 的未來,Shajii 和他的團隊目前正在研究廣泛使用的 Python 庫的本地實現,以及特定于庫的優化,以幫助人們從這些庫中獲得更好的性能。他們還計劃創建一個廣受歡迎的功能:Codon 的 WebAssembly 后端,以支持在 Web 瀏覽器上運行代碼。
6. Pytorch中模型的保存與遷移
https://mp.weixin.qq.com/s/c0QI44bmOp6hJLVWPXAgrw
1 引言
各位朋友大家好,今天要和大家介紹的內容是如何在Pytorch框架中對模型進行保存和載入、以及模型的遷移和再訓練。
一般來說,最常見的場景就是模型完成訓練后的推斷過程。一個網絡模型在完成訓練后通常都需要對新樣本進行預測,此時就只需要構建模型的前向傳播過程,然后載入已訓練好的參數初始化網絡即可。
第2個場景就是模型的再訓練過程。一個模型在一批數據上訓練完成之后需要將其保存到本地,并且可能過了一段時間后又收集到了一批新的數據,因此這個時候就需要將之前的模型載入進行在新數據上進行增量訓練(或者是在整個數據上進行全量訓練)。
第3個應用場景就是模型的遷移學習。這個時候就是將別人已經訓練好的預模型拿過來,作為你自己網絡模型參數的一部分進行初始化。例如:你自己在Bert模型的基礎上加了幾個全連接層來做分類任務,那么你就需要將原始BERT模型中的參數載入并以此來初始化你的網絡中的Bert部分的權重參數。
在接下來的這篇文章中,筆者就以上述3個場景為例來介紹如何利用Pytorch框架來完成上述過程。
2 模型的保存與復用
在Pytorch中,我們可以通過torch.save()和torch.load()來完成上述場景中的主要步驟。下面,筆者將以之前介紹的LeNet5網絡模型為例來分別進行介紹。不過在這之前,我們先來看看Pytorch中模型參數的保存形式。
2.1 查看網絡模型參數
(1)查看參數
首先定義好LeNet5的網絡模型結構,如下代碼所示:
1classLeNet5(nn.Module):
2def__init__(self,):
3super(LeNet5,self).__init__()
4self.conv=nn.Sequential(#[n,1,28,28]
5nn.Conv2d(1,6,5,padding=2),#in_channels,out_channels,kernel_size
6nn.ReLU(),#[n,6,24,24]
7nn.MaxPool2d(2,2),#kernel_size,stride[n,6,14,14]
8nn.Conv2d(6,16,5),#[n,16,10,10]
9nn.ReLU(),
10nn.MaxPool2d(2,2))#[n,16,5,5]
11self.fc=nn.Sequential(
12nn.Flatten(),
13nn.Linear(16*5*5,120),
14nn.ReLU(),
15nn.Linear(120,84),
16nn.ReLU(),
17nn.Linear(84,10))
18defforward(self,img):
19output=self.conv(img)
20output=self.fc(output)
21returnoutput
在定義好LeNet5這個網絡結構的類之后,只要我們完成了這個類的實例化操作,那么網絡中對應的權重參數也都完成了初始化的工作,即有了一個初始值。同時,我們可以通過如下方式來訪問:
1#Printmodel'sstate_dict*
2print("Model'sstate_dict:")
3**for**param_tensor**in**model.state_dict():
4print(param_tensor," ",model.state_dict()[param_tensor].size())
其輸出的結果為:
1conv.0.weighttorch.Size([6,1,5,5])
2conv.0.biastorch.Size([6])
3conv.3.weighttorch.Size([16,6,5,5])
4....
5....
可以發現,網絡模型中的參數model.state_dict()其實是以字典的形式(實質上是collections模塊中的OrderedDict)保存下來的:
1print(model.state_dict().keys())
2#odict_keys(['conv.0.weight','conv.0.bias','conv.3.weight',
3'conv.3.bias','fc.1.weight','fc.1.bias','fc.3.weight','fc.3.bias',
4'fc.5.weight','fc.5.bias'])
(2)自定義參數前綴
同時,這里值得注意的地方有兩點:①參數名中的fc和conv前綴是根據你在上面定義nn.Sequential()時的名字所確定的;②參數名中的數字表示每個Sequential()中網絡層所在的位置。例如將網絡結構定義成如下形式:
1classLeNet5(nn.Module):
2def__init__(self,):
3super(LeNet5,self).__init__()
4self.moon=nn.Sequential(#[n,1,28,28]
5nn.Conv2d(1,6,5,padding=2),#in_channels,out_channels,kernel_size
6nn.ReLU(),#[n,6,24,24]
7nn.MaxPool2d(2,2),#kernel_size,stride[n,6,14,14]
8nn.Conv2d(6,16,5),#[n,16,10,10]
9nn.ReLU(),
10nn.MaxPool2d(2,2),
11nn.Flatten(),
12nn.Linear(16*5*5,120),
13nn.ReLU(),
14nn.Linear(120,84),
15nn.ReLU(),
16nn.Linear(84,10))
那么其參數名則為:
1print(model.state_dict().keys())
2odict_keys(['moon.0.weight','moon.0.bias','moon.3.weight',
3'moon.3.bias','moon.7.weight','moon.7.bias','moon.9.weight',
4'moon.9.bias','moon.11.weight','moon.11.bias'])
理解了這一點對于后續我們去解析和載入一些預訓練模型很有幫助。
除此之外,對于中的優化器等,其同樣有對應的state_dict()方法來獲取對于的參數,例如:
1optimizer=torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
2print("Optimizer'sstate_dict:")
3forvar_nameinoptimizer.state_dict():
4print(var_name," ",optimizer.state_dict()[var_name])
5
6#
7Optimizer'sstate_dict:
8state{}
9param_groups[{'lr':0.001,'momentum':0.9,'dampening':0,
10'weight_decay':0,'nesterov':False,
11'params':[140239245300504,140239208339784,140239245311360,
12140239245310856,140239266942480,140239266942552,140239266942624,
13140239266942696,140239266942912,140239267041352]}]
14
在介紹完模型參數的查看方法后,就可以進入到模型復用階段的內容介紹了。
2.2 載入模型進行推斷
(1) 模型保存
在Pytorch中,對于模型的保存來說是非常簡單的,通常來說通過如下兩行代碼便可以實現:
1model_save_path=os.path.join(model_save_dir,'model.pt')
2torch.save(model.state_dict(),model_save_path)
在指定保存的模型名稱時Pytorch官方建議的后綴為.pt或者.pth(當然也不是強制的)。最后,只需要在合適的地方加入第2行代碼即可完成模型的保存。
同時,如果想要在訓練過程中保存某個條件下的最優模型,那么應該通過如下方式:
1best_model_state=deepcopy(model.state_dict())
2torch.save(best_model_state,model_save_path)
而不是:
1best_model_state=model.state_dict()
2torch.save(best_model_state,model_save_path)
因為后者best_model_state得到只是model.state_dict()的引用,它依舊會隨著訓練過程而發生改變。
(2)復用模型進行推斷
在推斷過程中,首先需要完成網絡的初始化,然后再載入已有的模型參數來覆蓋網絡中的權重參數即可,示例代碼如下:
1definference(data_iter,device,model_save_dir='./MODEL'):
2model=LeNet5()#初始化現有模型的權重參數
3model.to(device)
4model_save_path=os.path.join(model_save_dir,'model.pt')
5ifos.path.exists(model_save_path):
6loaded_paras=torch.load(model_save_path)
7model.load_state_dict(loaded_paras)#用本地已有模型來重新初始化網絡權重參數
8model.eval()#注意不要忘記
9withtorch.no_grad():
10acc_sum,n=0.0,0
11forx,yindata_iter:
12x,y=x.to(device),y.to(device)
13logits=model(x)
14acc_sum+=(logits.argmax(1)==y).float().sum().item()
15n+=len(y)
16print("Accuracyintestdatais:",acc_sum/n)
在上述代碼中,4-7行便是用來載入本地模型參數,并用其覆蓋網絡模型中原有的參數。這樣,便可以進行后續的推斷工作:
1Accuracyintestdatais:0.8851
2.3 載入模型進行訓練
在介紹完模型的保存與復用之后,對于網絡的追加訓練就很簡單了。最簡便的一種方式就是在訓練過程中只保存網絡權重,然后在后續進行追加訓練時只載入網絡權重參數初始化網絡進行訓練即可,示例如下(完整代碼參見[2]):
1deftrain(self):
2#......
3model_save_path=os.path.join(self.model_save_dir,'model.pt')
4ifos.path.exists(model_save_path):
5loaded_paras=torch.load(model_save_path)
6self.model.load_state_dict(loaded_paras)
7print("####成功載入已有模型,進行追加訓練...")
8optimizer=torch.optim.Adam(self.model.parameters(),lr=self.learning_rate)#定義優化器
9#......
10forepochinrange(self.epochs):
11fori,(x,y)inenumerate(train_iter):
12x,y=x.to(device),y.to(device)
13logits=self.model(x)
14#......
15print("Epochs[{}/{}]--accontest{:.4}".format(epoch,self.epochs,
16self.evaluate(test_iter,self.model,device)))
17torch.save(self.model.state_dict(),model_save_path)
這樣,便完成了模型的追加訓練:
1####成功載入已有模型,進行追加訓練...
2Epochs[0/5]---batch[938/0]---acc0.9062---loss0.2926
3Epochs[0/5]---batch[938/100]---acc0.9375---loss0.1598
4......
除此之外,你也可以在保存參數的時候,將優化器參數、損失值等一同保存下來,然后在恢復模型的時候連同其它參數一起恢復,示例如下:
1model_save_path=os.path.join(model_save_dir,'model.pt')
2torch.save({
3'epoch':epoch,
4'model_state_dict':model.state_dict(),
5'optimizer_state_dict':optimizer.state_dict(),
6'loss':loss,
7...
8},model_save_path)
載入方式如下:
1checkpoint=torch.load(model_save_path)
2model.load_state_dict(checkpoint['model_state_dict'])
3optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
4epoch=checkpoint['epoch']
5loss=checkpoint['loss']
2.4 載入模型進行遷移
(1)定義新模型
到目前為止,對于前面兩種應用場景的介紹就算完成了,可以發現總體上并不復雜。但是對于第3中場景的應用來說就會略微復雜一點。
假設現在有一個LeNet6網絡模型,它是在LeNet5的基礎最后多加了一個全連接層,其定義如下:
1classLeNet6(nn.Module):
2def__init__(self,):
3super(LeNet6,self).__init__()
4self.conv=nn.Sequential(#[n,1,28,28]
5nn.Conv2d(1,6,5,padding=2),#in_channels,out_channels,kernel_size
6nn.ReLU(),#[n,6,24,24]
7nn.MaxPool2d(2,2),#kernel_size,stride[n,6,14,14]
8nn.Conv2d(6,16,5),#[n,16,10,10]
9nn.ReLU(),
10nn.MaxPool2d(2,2))#[n,16,5,5]
11self.fc=nn.Sequential(
12nn.Flatten(),
13nn.Linear(16*5*5,120),
14nn.ReLU(),
15nn.Linear(120,84),
16nn.ReLU(),
17nn.Linear(84,64),
18nn.ReLU(),
19nn.Linear(64,10))#新加入的全連接層
接下來,我們需要將在LeNet5上訓練得到的權重參數遷移到LeNet6網絡中去。從上面LeNet6的定義可以發現,此時盡管只是多加了一個全連接層,但是倒數第2層參數的維度也發生了變換。因此,對于LeNet6來說只能復用LeNet5網絡前面4層的權重參數。
(2)查看模型參數
在拿到一個模型參數后,首先我們可以將其載入,然查看相關參數的信息:
1model_save_path=os.path.join('./MODEL','model.pt')
2loaded_paras=torch.load(model_save_path)
3forparam_tensorinloaded_paras:
4print(param_tensor," ",loaded_paras[param_tensor].size())
5
6#----可復用部分
7conv.0.weighttorch.Size([6,1,5,5])
8conv.0.biastorch.Size([6])
9conv.3.weighttorch.Size([16,6,5,5])
10conv.3.biastorch.Size([16])
11fc.1.weighttorch.Size([120,400])
12fc.1.biastorch.Size([120])
13fc.3.weighttorch.Size([84,120])
14fc.3.biastorch.Size([84])
15#-----不可復用部分
16fc.5.weighttorch.Size([10,84])
17fc.5.biastorch.Size([10])
同時,對于LeNet6網絡的參數信息為:
1model=LeNet6()
2forparam_tensorinmodel.state_dict():
3print(param_tensor," ",model.state_dict()[param_tensor].size())
4#
5conv.0.weighttorch.Size([6,1,5,5])
6conv.0.biastorch.Size([6])
7conv.3.weighttorch.Size([16,6,5,5])
8conv.3.biastorch.Size([16])
9fc.1.weighttorch.Size([120,400])
10fc.1.biastorch.Size([120])
11fc.3.weighttorch.Size([84,120])
12fc.3.biastorch.Size([84])
13#------新加入部分
14fc.5.weighttorch.Size([64,84])
15fc.5.biastorch.Size([64])
16fc.7.weighttorch.Size([10,64])
17fc.7.biastorch.Size([10])
在理清楚了新舊模型的參數后,下面就可以將LeNet5中我們需要的參數給取出來,然后再換到LeNet6的網絡中。
(3)模型遷移
雖然本地載入的模型參數(上面的loaded_paras)和模型初始化后的參數(上面的model.state_dict())都是一個字典的形式,但是我們并不能夠直接改變model.state_dict()中的權重參數。這里需要先構造一個state_dict然后通過model.load_state_dict()方法來重新初始化網絡中的參數。
同時,在這個過程中我們需要篩選掉本地模型中不可復用的部分,具體代碼如下:
1defpara_state_dict(model,model_save_dir):
2state_dict=deepcopy(model.state_dict())
3model_save_path=os.path.join(model_save_dir,'model.pt')
4ifos.path.exists(model_save_path):
5loaded_paras=torch.load(model_save_path)
6forkeyinstate_dict:#在新的網絡模型中遍歷對應參數
7ifkeyinloaded_parasandstate_dict[key].size()==loaded_paras[key].size():
8print("成功初始化參數:",key)
9state_dict[key]=loaded_paras[key]
10returnstate_dict
在上述代碼中,第2行的作用是先拷貝網絡中(LeNet6)原有的參數;第6-9行則是用本地的模型參數(LeNet5)中可以復用的替換掉LeNet6中的對應部分,其中第7行就是判斷可用的條件。同時需要注意的是在不同的情況下篩選的方式可能不一樣,因此具體情況需要具體分析,但是整體邏輯是一樣的。
最后,我們只需要在模型訓練之前調用該函數,然后重新初始化LeNet6中的部分權重參數即可[2]:
1state_dict=para_state_dict(self.model,self.model_save_dir)
2self.model.load_state_dict(state_dict)
訓練結果如下:
1成功初始化參數:conv.0.weight
2成功初始化參數:conv.0.bias
3成功初始化參數:conv.3.weight
4成功初始化參數:conv.3.bias
5成功初始化參數:fc.1.weight
6成功初始化參數:fc.1.bias
7成功初始化參數:fc.3.weight
8成功初始化參數:fc.3.bias
9####成功載入已有模型,進行追加訓練...
10Epochs[0/5]---batch[938/0]---acc0.1094---loss2.512
11Epochs[0/5]---batch[938/100]---acc0.9375---loss0.2141
12Epochs[0/5]---batch[938/200]---acc0.9219---loss0.2729
13Epochs[0/5]---batch[938/300]---acc0.8906---loss0.2958
14......
15Epochs[0/5]---batch[938/900]---acc0.8906---loss0.2828
16Epochs[0/5]--accontest0.8808
可以發現,在大約100個batch之后,模型的準確率就提升上來了。
3 總結
在本篇文章中,筆者首先介紹了模型復用的幾種典型場景;然后介紹了如何查看Pytorch模型中的相關參數信息;接著介紹了如何載入模型、如何進行追加訓練以及進行模型的遷移學習等。
———————End———————
RT-Thread線下入門培訓-4月場次 青島、北京
1.免費2.動手實驗+理論3.主辦方免費提供開發板4.自行攜帶電腦,及插線板用于筆記本電腦充電5.參與者需要有C語言、單片機(ARM Cortex-M核)基礎,請提前安裝好RT-Thread Studio 開發環境

立即掃碼報名
報名鏈接
https://jinshuju.net/f/UYxS2k
巡回城市:青島、北京、西安、成都、武漢、鄭州、杭州、深圳、上海、南京
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!
點擊閱讀原文,進入RT-ThreadXIFX賽事官網
原文標題:【AI簡報20230407期】 MLPref放榜!大模型時代算力領域“潛力股”浮出水面、CV或迎來GPT-3時刻
-
RT-Thread
+關注
關注
31文章
1289瀏覽量
40135
原文標題:【AI簡報20230407期】 MLPref放榜!大模型時代算力領域“潛力股”浮出水面、CV或迎來GPT-3時刻
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
芯片、模型生態分散,無問芯穹、沐曦、壁仞談國產算力瓶頸破局之道

【「大模型時代的基礎架構」閱讀體驗】+ 未知領域的感受
Jim Fan展望:機器人領域即將迎來GPT-3式突破
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
蘋果新語音通信專利浮出水面


大算力時代, 如何打破內存墻
Anthropic推出Claude 3系列模型,全面超越GPT-4,樹立AI新標桿
Rambus HBM3內存控制器IP速率達到9.6 Gbps







 工商網監
工商網監
評論