 視覺激光雷達信息融合與聯合標定
視覺激光雷達信息融合與聯合標定
編者薦語使用視覺進行目標檢測,將檢測結果2D bounding box坐標信息投影到點云里面獲得3D bounding boxx坐標,這里面需要將攝像頭和激光雷達進行聯合標定,即獲取二者坐標系的空間轉換關系。
一、引言
最近在為車輛添加障礙物檢測模塊,障礙物檢測可以使用激光雷達進行物體聚類,但是我們使用的是16線的velodyne,線數還是有些稀疏,對于較遠的物體過于稀疏的線數聚類效果并不好,因此考慮使用視覺進行目標檢測,然后投影到3D點云里面,獲取障礙物位置,同時視覺還可以給出障礙物類別信息。 使用視覺進行目標檢測,將檢測結果2D bounding box坐標信息投影到點云里面獲得3D bounding boxx坐標,這里面需要將攝像頭和激光雷達進行聯合標定,即獲取二者坐標系的空間轉換關系。 相關代碼已經同步到我的github-smartcar 鏈接:https://github.com/sunmiaozju/smartcar 標定部分在detection/calibration文件夾, 信息融合部分在detection/camera_point_fusion
二、聯合標定轉換關系
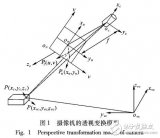
聯合標定的作用就是建立點云的point和圖像pixel之間的對應關系, 需要獲取相機與激光雷達外參,將點云3維坐標系下的點投影到相機3維坐標系下。 還需要通過相機標定獲得相機內參,這個是把相機3維坐標系下的點投影到成像平面。具體如下所示:
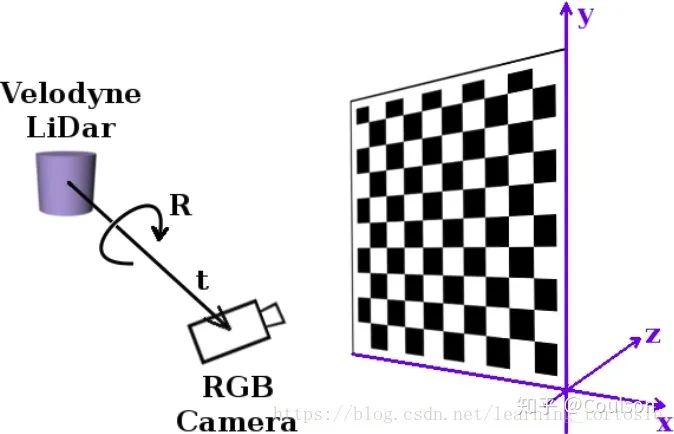
上圖顯示的就是聯合標定得到的4×4轉換矩陣的作用,將我們的3D點云轉換到相機坐標系下面
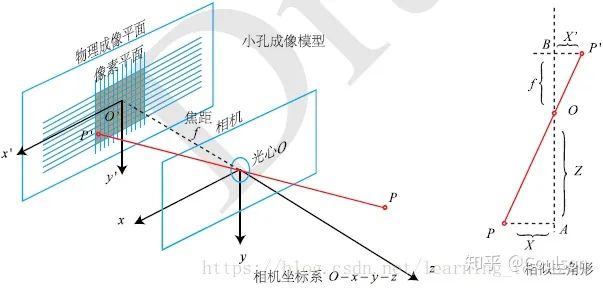
這幅圖顯示了相機坐標系和成像坐標系的關系,相機標定會得到相機內參矩陣和畸變系數,畸變系數可以消除相機凸透鏡的畸變效應,相機內參的信息就可以想相機坐標下的3維點投影到2維的像素平面。相機標定的具體原理可以參考//zhuanlan.zhihu.com/p/24651968三、相機標定需要一個標定板,要硬質板或者泡沫的標定板,因為標定板的平面要保證是平的。標定板的文件可以到opencv官網下載。 首先做相機標定,相機標定模塊在detection/calibration/camera_calibration 編譯
cd your_rosworkspace_path/ catkin_make -DCATKIN_BLACKLIST_PACKAGES=ndt_mapping;static_map;ndt_localization
這里我們先不編譯ndt_mapping;static_map;ndt_localization這三個軟件包 如果出錯,可以先編譯消息文件,再編譯全部文件:
catkin_make -DCATKIN_WHITELIST_PACKAGES=smartcar_msgs;yunle_msgs;smartcar_config_msgs catkin_make -DCATKIN_WHITELIST_PACKAGES=“”
然后要修改detection/calibration/camera_calibration/nodes文件夾下面python文件的可執行權限:
sudo chmod a+x your_path/detection/calibration/camera_calibration/.
啟動攝像頭驅動節點
roslaunch cv_camera cv_camera_driver.launch
這里注意你自己的攝像頭video_id,使用如下命令查看
ls /dev/video*
然后根據需要修改your_path/driver/cv_camera/launch/cv_camera_driver.launch里面的
新開一個終端,執行
rosrun calibration cameracalibrator.py --square 0.13 --size 8x6 image:=/cv_camera/image_raw
然后就可以進行標定了,彈出的界面如下所示:

需要做的就是移動標定版,讓右上角的四個條都變綠(我這里綠的是已經調好了,未調整是偏黃色) x代表左右移動,y代表上下移動,size代表遠近移動,skew代表傾斜側角,可以上下傾,也可以左右傾。 只有四個尺度的信息都滿足要求之后,右側的calibration圖標才會顯示出來,這時候代表可以計算標定結果了,點擊calibration,然后save,標定結果會保存在home文件夾下面。
四、聯合標定
聯合標定使用的是autoware的CalibrationTookit模塊,代碼在detection/calibration/calibration_camera_lidar文件夾下面 編譯好代碼之后,首先要啟動攝像頭和激光雷達的驅動節點
roslaunch cv_camera cv_camera_driver.launch
新終端
roslaunch velodyne_pointcloud VLP16_points.launch
然后驅動聯合標定節點
roslaunch calibration_camera_lidar camera_lidar_calib.launch
啟動之后可以看到UI界面,具體操作指南,可以參考文檔:detection/calibration/calibration_camera_lidar/CalibrationToolkit_Manual.pdf 的2.3節 也可以參考鏈接//blog.csdn.net/AdamShan/article/details/81670732#commentBox 如何使用這個模塊上面的鏈接已經說的很明白,這里簡單說一下:·首先左上角load之前標定的相機內參文件,導入相機內參·調整點云的視角(操作方法參考上面鏈接),然后確保圖像和點云都可以看到完整的白標定板,點擊右上角的grab捕獲單幀圖片和點云·在捕獲單幀的點云上面,選取圖片中對應標定板的位置,選取的是圓圈內的所有點,所包含的信息不僅僅只有點,還有平面法相量,標定的時候一定要確保法相量與平面是垂直的,因為開始我沒有注意這個,結果后面驗證的時候投影點在圖片上顯示不出,根本沒有投影在圖像范圍內。 標定好之后,在右上角有一個project,可以查看標定的效果,一般來將,可以看到如下效果:
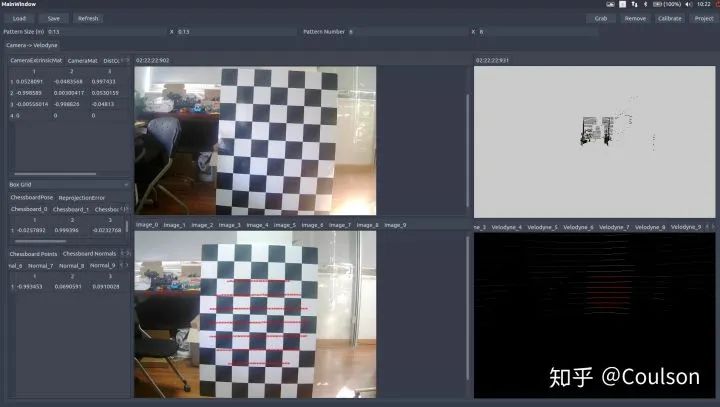
左下角圖片上的紅線就是右下角點云紅線投影到圖片上的位置,下面這幅圖片換一個角度,點同樣投影上去,而且相對位置在點云和圖片里面基本一致:
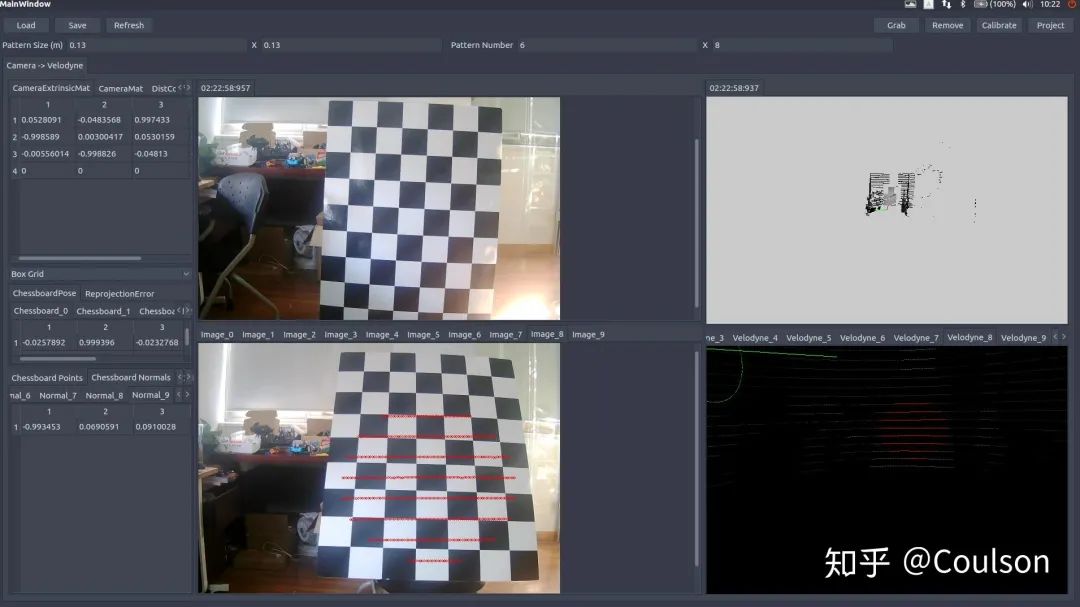
這樣的效果基本就是可以了,點擊save,會將輸出的外參文件保存在home文件夾下面。
五、視覺與點云信息融合
有了聯合標定的外參文件,我們就可以進行信息融合了。 信息融合主要有兩個模塊:點云到圖像 、 圖像到點云
5.1 image2points
這部分代碼在your_path/deteection/camera_point_fusion/packages/joint_pixel_pointcloud這個pkg下面 這部分代碼實現的功能是建立將velodyne-16的點云投影到640×480的圖像上面,如果點云投影的二維點在圖像640×480范圍內,那么就把這個三維激光雷達點的位置記下來,同時匹配圖像上對應像素的顏色,變成pcl::XYZRGB點返回,并顯示出來。 除此之外,這個模塊還可以訂閱目標檢測信息,攝像頭獲取圖像,經過目標檢測模塊之后,得到2維bounding box坐標,利用點云和圖像像素的對應關系,得到3維bounding box信息,并在RVIZ中顯示出來。 編譯好代碼之后,運行:
roslaunch joint_pixel_pointcloud joint_pixel_pointcloud.launch
同樣,需要先運行攝像頭驅動節點和velodyne驅動節點,還有目標檢測節點,不過目標檢測模塊因為某些原因不能公開到github,你可以使用自己的目標檢測模塊,作為ROS節點添加到工作空間即可。 代碼運行效果如下所示:
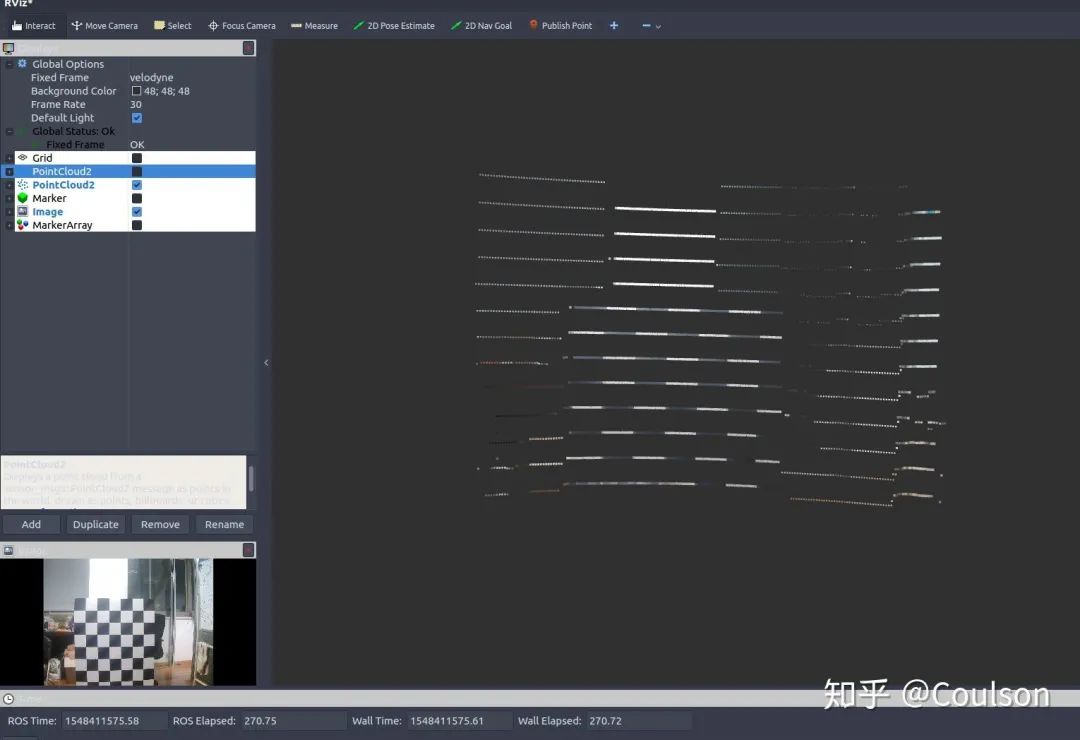
這個就是圖像像素所對應的點云,可以看到點云已經被加上了黑白的顏色,點云周邊有一些比較淡的顏色,下面這幅圖加深了顏色,同時顯示出圖像對應的點云在整個點云幀的位置:

下面是目標檢測的效果:
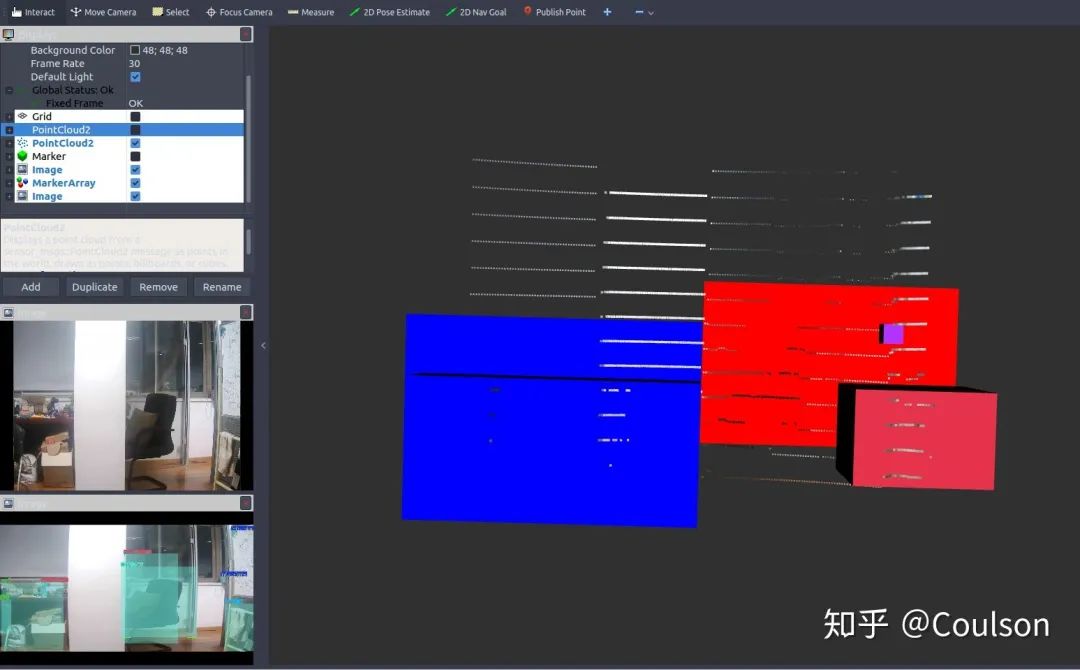
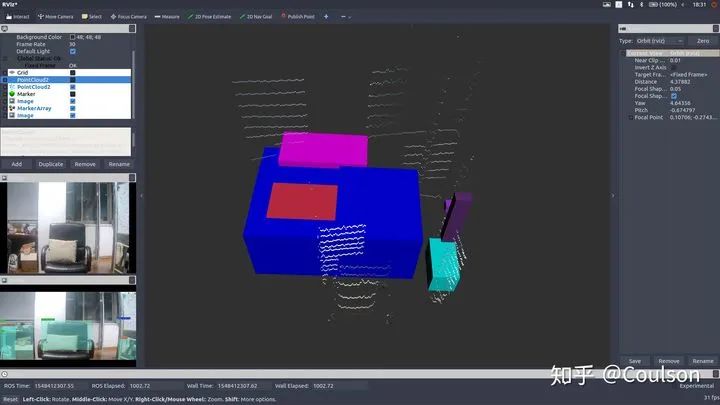
可以看到,圖像上檢測出來的物體,基本都在3D場景下對應出來了,其中,不同的顏色代表不同的物體類別。 不過,因為這個目標檢測模型是針對于自動駕駛場景的,分類對象都是car,pedestrian,info signs等,而因為實驗條件的原因我還沒有來得及拿出去測試代碼效果,就先在房間測試了一下,所以可以看到目標檢測的框是有些沒意義的東西,不過不影響驗證信息融合效果。 這個節點可以便于我們進行障礙物檢測,因為視覺信息進行障礙物檢測是要優于低線數激光雷達聚類的,但是視覺信息識別物體雖然準,卻沒有距離信息,激光雷達可以提供距離信息,因此,視覺和激光雷達二者結合,就可以獲得障礙物的距離、類別以及位置了
5.2 points2image
這個是把點云投影到圖像上,具體運行基本同理我就不說了。 代碼的具體效果如下所示:
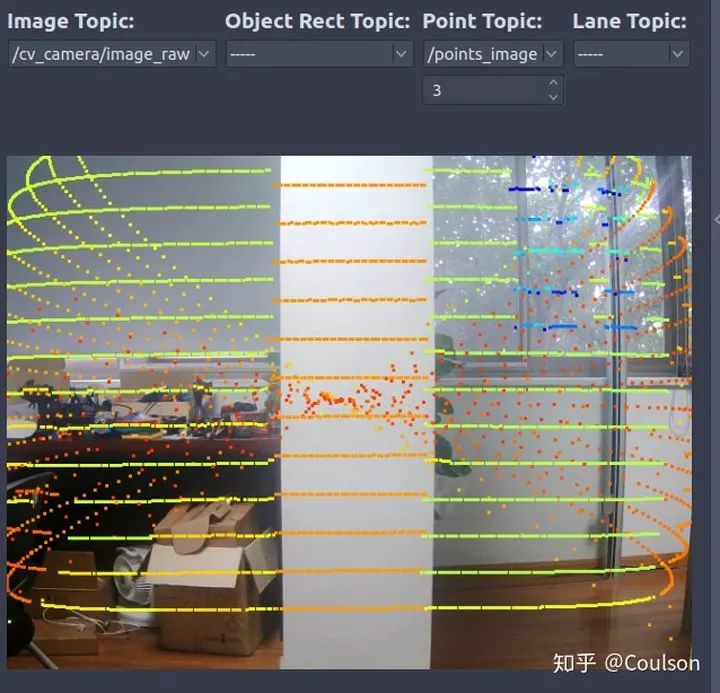
可以看到,點云基本是和圖像是匹配的。 這個節點的作用是可以幫助我們進行紅綠燈識別或者其他info_sign識別。因為進行紅綠燈檢測最好是可以獲取紅綠燈在圖像上的位置,即ROI,然后再進行識別會容易很多。我們可以在事先建立好的場景語義地圖中,加入紅綠燈的位置,這樣車輛到達該位置的時候就可以立刻找到紅綠燈在圖像上的ROI,這樣會優化info sign的檢測。具體如下所示:

六、總結
本文主要介紹了關于視覺和激光雷達進行信息融合相關內容,包括相機標定,攝像頭與激光雷達聯合標定,信息融合節點等等 利用激光雷達和視覺信息融合,我們可以結合二者的優點優化障礙物檢測或交通標志的識別,以及優化其他相關任務等等。
審核編輯 :李倩
-
3D
+關注
關注
9文章
2899瀏覽量
107706 -
視覺
+關注
關注
1文章
147瀏覽量
23991 -
目標檢測
+關注
關注
0文章
210瀏覽量
15641 -
激光雷達
+關注
關注
968文章
4003瀏覽量
190136
原文標題:視覺激光雷達信息融合與聯合標定(附代碼)
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺析自動駕駛發展趨勢,激光雷達是未來?
激光雷達是自動駕駛不可或缺的傳感器
激光雷達分類以及應用
常見激光雷達種類
消費級激光雷達的起航
北醒固態設計激光雷達
固態設計激光雷達
機器人和激光雷達都不可或缺
一種不依賴于棋盤格等輔助標定物體實現像素級相機和激光雷達自動標定的方法
基于梯形棋盤格標定板對激光雷達和攝像機聯合標定方法





 工商網監
工商網監
評論