") HuggingGPT在線演示驚艷亮相
HuggingGPT在線演示驚艷亮相
【導(dǎo)讀】浙大&微軟推出的HuggingGPT爆火之后,剛剛開(kāi)放了demo,急不可待的網(wǎng)友自己上手體驗(yàn)了一番。
最強(qiáng)組合HuggingFace+ChatGPT=「賈維斯」現(xiàn)在開(kāi)放demo了。
前段時(shí)間,浙大&微軟發(fā)布了一個(gè)大模型協(xié)作系統(tǒng)HuggingGPT直接爆火。 研究者提出了用ChatGPT作為控制器,連接HuggingFace社區(qū)中的各種AI模型,完成多模態(tài)復(fù)雜任務(wù)。 整個(gè)過(guò)程,只需要做的是:用自然語(yǔ)言將你的需求輸出。 英偉達(dá)科學(xué)家稱,這是我本周讀到的最有意思的論文。它的思想非常接近我之前說(shuō)的「Everything App」,即萬(wàn)物皆App,被AI直接讀取信息。

上手體驗(yàn)
現(xiàn)在,HuggingGPT增加了Gradio演示。
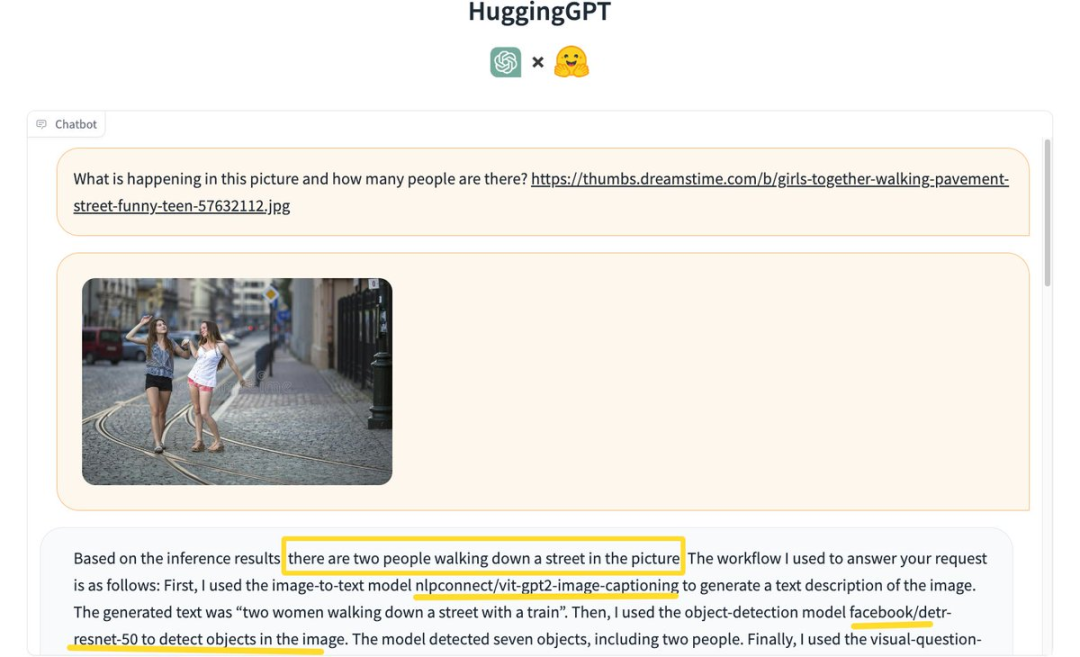
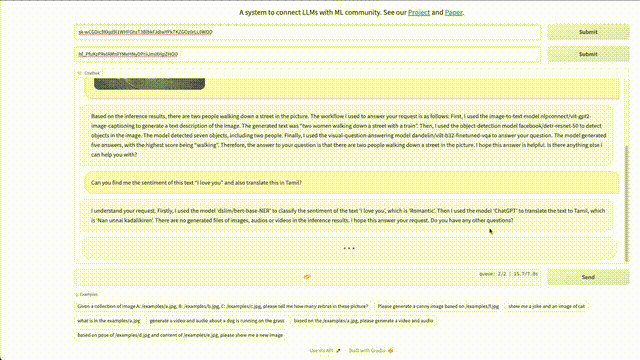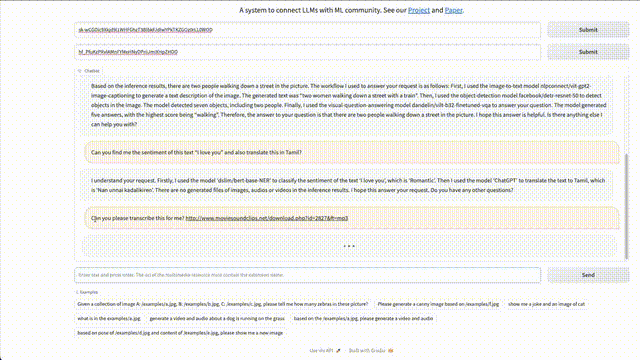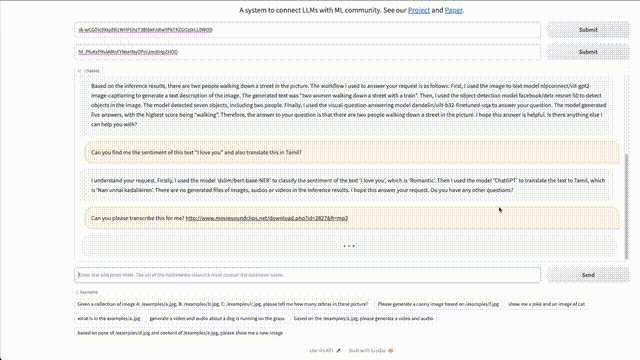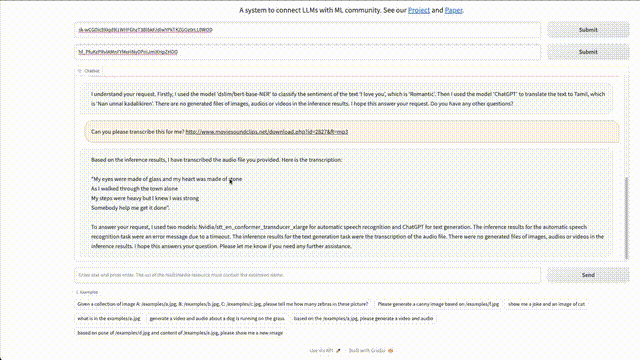
項(xiàng)目地址:https://github.com/microsoft/JARVIS 有網(wǎng)友便上手體驗(yàn)了一番,先來(lái)「識(shí)別圖上有幾個(gè)人」?

HuggingGPT根據(jù)推理結(jié)果,得出圖片中有2個(gè)人正在街道上行走。 具體過(guò)程如下: 首先使用圖像到文本模型nlpconnect/vit-gpt2-image-captioning進(jìn)行圖像描述,生成的文本「2個(gè)女人在有火車的街道上行走」。 接著,使用了目標(biāo)檢測(cè)模型facebook/detrresnet 50來(lái)檢測(cè)圖片中的人數(shù)。模型檢測(cè)出7個(gè)物體,2個(gè)人。 再使用視覺(jué)問(wèn)題回答模型dandelin/vilt-b32-finetuned-vqa得出結(jié)果。最后,系統(tǒng)提供了詳細(xì)的響應(yīng)和用于解答問(wèn)題的模型信息。
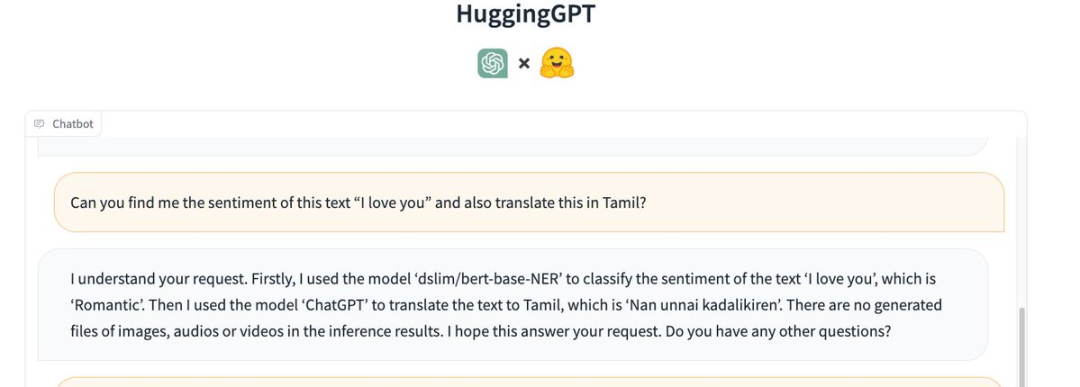
另外,讓它理解「我愛(ài)你」這句話的情感,并將其翻譯成泰米爾語(yǔ)(Tami?)。 HuggingGPT調(diào)用了以下模型: 首先,使用了模型「dslim/bert-base-NER」對(duì)文本「l love you」進(jìn)行情感分類,是「浪漫」。 然后,使用「ChatGPT」將文本翻譯成泰米爾語(yǔ),即「Nan unnai kadalikiren」。 在推理結(jié)果中沒(méi)有生成的圖片、音頻或視頻文件。
轉(zhuǎn)錄MP3文件時(shí),HuggingGPT卻失敗了。網(wǎng)友表示,「不確定這是否是我的輸入文件的問(wèn)題。」
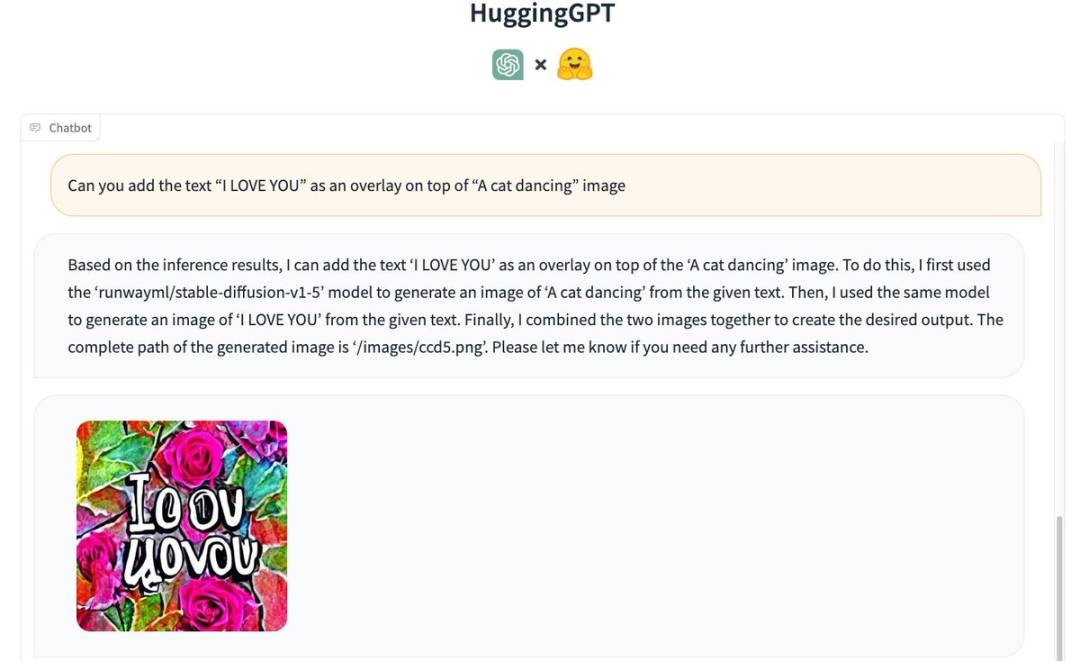
再來(lái)看看圖像生成的能力。 輸入「一只貓?zhí)琛箞D像上添加文字「I LOVE YOU」作為疊加層。 HuggingGPT首先使用了「runwayml/stable-diffusion-1-5」模型根據(jù)給定的文本生成「跳舞的貓」的圖片。 然后,使用同一個(gè)模型根據(jù)給定的文本生成了「I LOVE YOU」的圖片。 最后,將2個(gè)圖片合并在一起,輸出如下圖:
賈維斯照進(jìn)現(xiàn)實(shí)
項(xiàng)目公開(kāi)沒(méi)幾天,賈維斯已經(jīng)在GitHub上收獲了12.5k星,以及811個(gè)fork。

研究者指出解決大型語(yǔ)言模型(LLMs)當(dāng)前的問(wèn)題,可能是邁向AGI的第一步,也是關(guān)鍵的一步。
因?yàn)楫?dāng)前大型語(yǔ)言模型的技術(shù)仍然存在著一些缺陷,因此在構(gòu)建 AGI 系統(tǒng)的道路上面臨著一些緊迫的挑戰(zhàn)。
為了處理復(fù)雜的人工智能任務(wù),LLMs應(yīng)該能夠與外部模型協(xié)調(diào),以利用它們的能力。 因此,關(guān)鍵點(diǎn)在于如何選擇合適的中間件來(lái)橋接LLMs和AI模型。 在這篇研究論文中,研究者提出在HuggingGPT中語(yǔ)言是通用的接口。其工作流程主要分為四步:

論文地址:https://arxiv.org/pdf/2303.17580.pdf 首先是任務(wù)規(guī)劃,ChatGPT解析用戶請(qǐng)求,將其分解為多個(gè)任務(wù),并根據(jù)其知識(shí)規(guī)劃任務(wù)順序和依賴關(guān)系。 接著,進(jìn)行模型選擇。LLM根據(jù)HuggingFace中的模型描述將解析后的任務(wù)分配給專家模型。 然后執(zhí)行任務(wù)。專家模型在推理端點(diǎn)上執(zhí)行分配的任務(wù),并將執(zhí)行信息和推理結(jié)果記錄到LLM中。 最后是響應(yīng)生成。LLM總結(jié)執(zhí)行過(guò)程日志和推理結(jié)果,并將摘要返回給用戶。
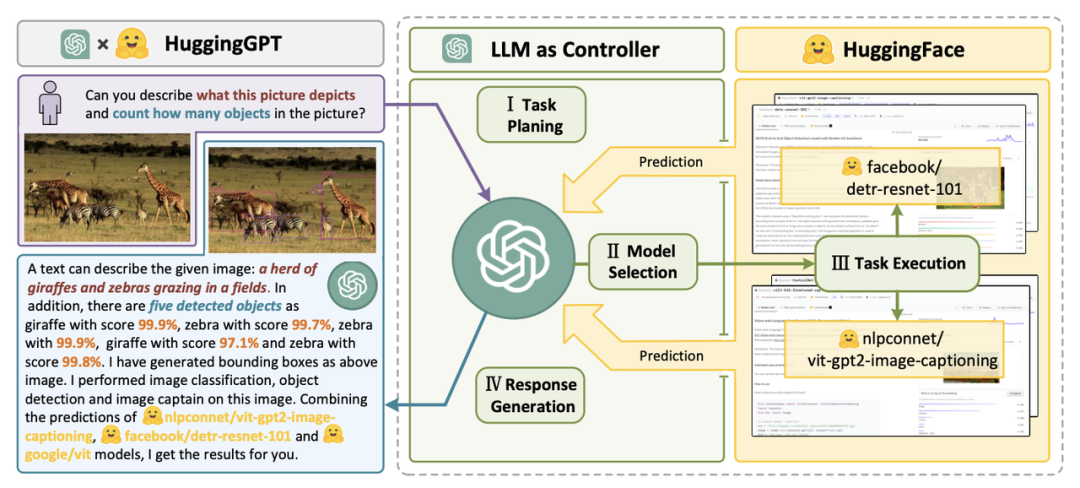
假如給出這樣一個(gè)請(qǐng)求:
請(qǐng)生成一個(gè)女孩正在看書的圖片,她的姿勢(shì)與example.jpg中的男孩相同。然后請(qǐng)用你的聲音描述新圖片。
可以看到HuggingGPT是如何將它拆解為6個(gè)子任務(wù),并分別選定模型執(zhí)行得到最終結(jié)果的。

通過(guò)將AI模型描述納入提示中,ChatGPT可以被視為管理人工智能模型的大腦。因此,這一方法可以讓ChatGPT能夠調(diào)用外部模型,來(lái)解決實(shí)際任務(wù)。 簡(jiǎn)單來(lái)講,HuggingGPT是一個(gè)協(xié)作系統(tǒng),并非是大模型。 它的作用就是連接ChatGPT和HuggingFace,進(jìn)而處理不同模態(tài)的輸入,并解決眾多復(fù)雜的人工智能任務(wù)。 所以,HuggingFace社區(qū)中的每個(gè)AI模型,在HuggingGPT庫(kù)中都有相應(yīng)的模型描述,并將其融合到提示中以建立與ChatGPT的連接。 隨后,HuggingGPT將ChatGPT作為大腦來(lái)確定問(wèn)題的答案。 到目前為止,HuggingGPT已經(jīng)圍繞ChatGPT在HuggingFace上集成了數(shù)百個(gè)模型,涵蓋了文本分類、目標(biāo)檢測(cè)、語(yǔ)義分割、圖像生成、問(wèn)答、文本到語(yǔ)音、文本到視頻等24個(gè)任務(wù)。 實(shí)驗(yàn)結(jié)果證明,HuggingGPT可以在各種形式的復(fù)雜任務(wù)上表現(xiàn)出良好的性能。
網(wǎng)友熱評(píng)
有網(wǎng)友稱,HuggingGPT類似于微軟此前提出的Visual ChatGPT,似乎他們把最初的想法擴(kuò)展到了一組龐大的預(yù)訓(xùn)練模型上。

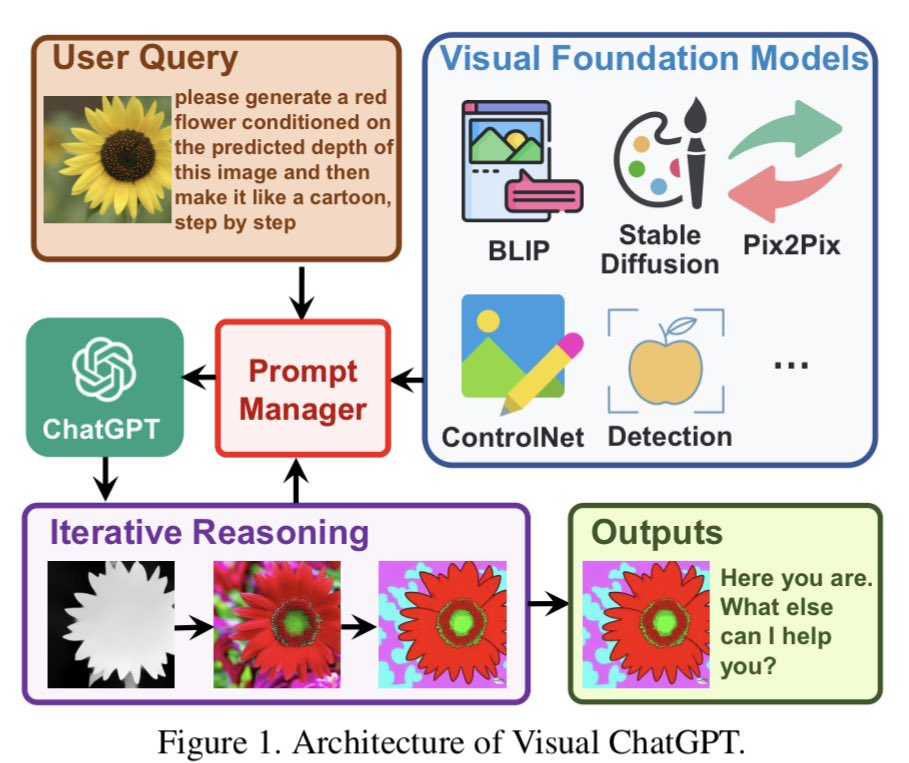
Visual ChatGPT是直接基于ChatGPT構(gòu)建,并向其注入了許多可視化模型(VFMs)。文中提出了Prompt Manage。 在PM的幫助下,ChatGPT可以利用這些VFMs,并以迭代的方式接收其反饋,直到滿足用戶的要求或達(dá)到結(jié)束條件。
還有網(wǎng)友認(rèn)為,這個(gè)想法確實(shí)與ChatGPT插件非常相似。以LLM為中心進(jìn)行語(yǔ)義理解和任務(wù)規(guī)劃,可以無(wú)限提升LLM的能力邊界。通過(guò)將LLM與其他功能或領(lǐng)域?qū)<蚁嘟Y(jié)合,我們可以創(chuàng)建更強(qiáng)大、更靈活的 AI 系統(tǒng),能夠更好地適應(yīng)各種任務(wù)和需求。

這就是我一直以來(lái)對(duì)AGI的看法,人工智能模型能夠理解復(fù)雜任務(wù),然后將較小的任務(wù)分派給其他更專業(yè)的AI模型。

就像大腦一樣,它也有不同的部分來(lái)完成特定的任務(wù),聽(tīng)起來(lái)很符合邏輯。

審核編輯 :李倩
-
AI
+關(guān)注
關(guān)注
87文章
31158瀏覽量
269503 -
模型
+關(guān)注
關(guān)注
1文章
3268瀏覽量
48937 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1564瀏覽量
7827
原文標(biāo)題:炫到爆炸!HuggingGPT在線演示驚艷亮相,網(wǎng)友親測(cè)圖像生成絕了
文章出處:【微信號(hào):玩轉(zhuǎn)VS Code,微信公眾號(hào):玩轉(zhuǎn)VS Code】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
理想MEGA首次亮相CES!全球首款支持杜比視界和杜比全景聲車型
宇樹(shù)科技CES 2025大放異彩,多款創(chuàng)新產(chǎn)品驚艷亮相

KMPHM在線監(jiān)測(cè)平臺(tái)實(shí)現(xiàn)設(shè)備高效管理#在線監(jiān)測(cè)#振動(dòng)監(jiān)測(cè)#振動(dòng)在線監(jiān)測(cè)
聯(lián)誠(chéng)發(fā)LED屏驚艷亮相土耳其廣告展

KM振動(dòng)在線監(jiān)測(cè)系統(tǒng)助力設(shè)備煥新升級(jí)#振動(dòng)在線監(jiān)測(cè)#振動(dòng)監(jiān)測(cè)#在線監(jiān)測(cè)
揚(yáng)帆出海!九章云極DataCanvas公司驚艷亮相迪拜GITEX Global 2024


KMPHM振動(dòng)在線監(jiān)測(cè)助力企業(yè)輕裝上陣#振動(dòng)在線監(jiān)測(cè) #在線監(jiān)測(cè) #振動(dòng)監(jiān)測(cè)
巍泰技術(shù)攜多款創(chuàng)新產(chǎn)品驚艷亮相 2024 第二十二屆物聯(lián)網(wǎng)展

折疊屏旗艦榮耀Magic V3將攜其突破性設(shè)計(jì)驚艷亮相
億緯鋰能亮相EUROBIKE 2024歐洲自行車展

納雷科技攜全新交通流量統(tǒng)計(jì)毫米波雷達(dá)產(chǎn)品驚艷亮相中國(guó)高速公路展







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論