 有哪些省內存的大語言模型訓練/微調/推理方法?
有哪些省內存的大語言模型訓練/微調/推理方法?
大模型(LLMs)現在是 NLP 領域的最主流方法之一了。
這個趨勢帶來的主要問題之一,就是大模型的訓練/微調/推理需要的內存也越來越多。
舉例來說,即使 RTX 3090 有著 24GB 的 RAM,是除了 A100 之外顯存最大的顯卡。但使用一塊 RTX 3090 依然無法 fp32 精度訓練最小號的 LLaMA-6B。
本文總結一些 Memory-Efficient 的 LLMs 的訓練/微調/推理方法,包括:
● fp16
●int8
●LoRA
●Gradient checkpointing
●Torch FSDP
估算模型所需的RAM
首先,我們需要了解如何根據參數量估計模型大致所需的 RAM,這在實踐中有很重要的參考意義。我們需要通過估算設置 batch_size,設置模型精度,選擇微調方法和參數分布方法等。
接下來,我們用LLaMA-6B模型為例估算其大致需要的內存。
首先考慮精度對所需內存的影響:
●fp32 精度,一個參數需要 32 bits, 4 bytes. ●fp16 精度,一個參數需要 16 bits, 2 bytes. ●int8 精度,一個參數需要 8 bits, 1 byte.
其次,考慮模型需要的 RAM 大致分三個部分:
●模型參數 ●梯度 ●優化器參數
模型參數:等于參數量*每個參數所需內存。
對于 fp32,LLaMA-6B 需要 6B*4 bytes = 24GB內存
對于 int8,LLaMA-6B 需要 6B*1 byte = 6GB
梯度:同上,等于參數量*每個梯度參數所需內存。
優化器參數:不同的優化器所儲存的參數量不同。
對于常用的 AdamW 來說,需要儲存兩倍的模型參數(用來儲存一階和二階momentum)。
fp32 的 LLaMA-6B,AdamW 需要 6B*8 bytes = 48 GB
int8 的 LLaMA-6B,AdamW 需要 6B*2 bytes = 12 GB
除此之外,CUDA kernel也會占據一些 RAM,大概 1.3GB 左右,查看方式如下。

綜上,int8 精度的 LLaMA-6B 模型部分大致需要 6GB+6GB+12GB+1.3GB = 25.3GB 左右。
再根據LLaMA的架構(hidden_size = 4096, intermediate_size =11008, num_hidden_layers = 32, context_length = 2048)計算中間變量內存。
每個 instance 需要:
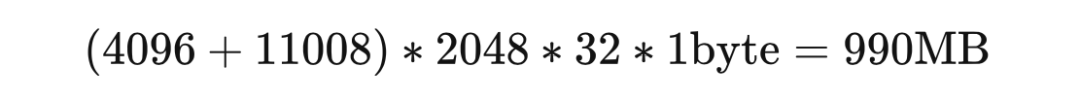
所以一張 A100(80GB RAM)大概可以在 int8 精度;batch_size = 50 的設定下進行全參數訓練。
查看消費級顯卡的內存和算力:
2023 GPU Benchmark and Graphics Card Comparison Chart
https://www.gpucheck.com/gpu-benchmark-graphics-card-comparison-chart
Fp16-mixed precision
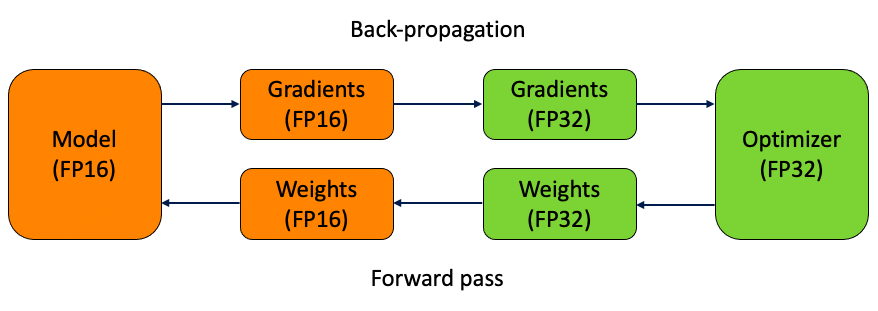
混合精度訓練的大致思路是在 forward pass 和 gradient computation 的時候使用 fp16 來加速,但是在更新參數時使用 fp32。
用 torch 實現:
CUDA Automatic Mixed Precision examples
https://pytorch.org/docs/stable/notes/amp_examples.html
torch fp16 推理:直接使用 model.half() 將模型轉換為fp16.

使用 Huggingface Transformers:在 TrainingArguments 里聲明 fp16=True
https://huggingface.co/docs/transformers/perf_train_gpu_one#fp16-training
Int8-bitsandbytes
Int8 是個很極端的數據類型,它最多只能表示 - 128~127 的數字,并且完全沒有精度。
為了在訓練和 inference 中使用這個數據類型,bitsandbytes 使用了兩個方法最大程度地降低了其帶來的誤差:
1. vector-wise quantization
2. mixed precision decompasition
Huggingface 在這篇文章中用動圖解釋了 quantization 的實現:
https://huggingface.co/blog/hf-bitsandbytes-integration
論文:
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scalehttps://arxiv.org/abs/2208.07339
借助 Huggingface PEFT,使用 int8 訓練 opt-6.5B 的完整流程:
https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb
LoRA
Low-Rank Adaptation 是微調 LLMs 最常用的省內存方法之一。
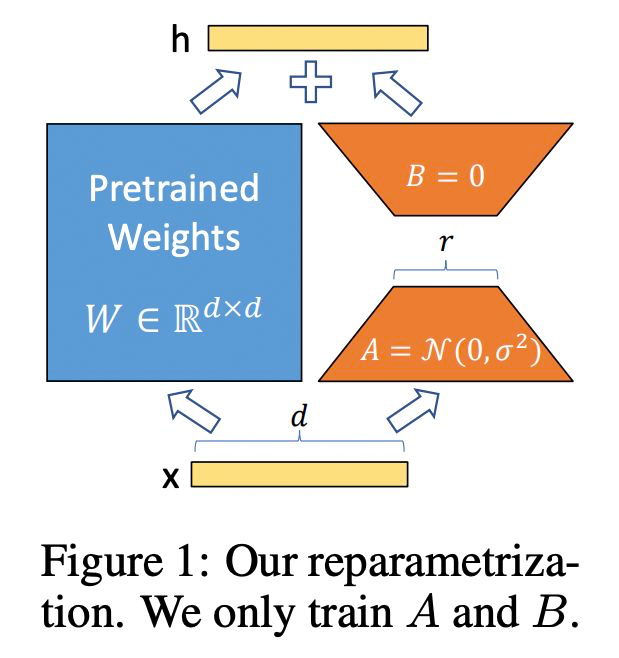
LoRA 發現再微調 LLMs 時,更新矩陣(update matrix)往往特別 sparse,也就是說 update matrix 是低秩矩陣。LoRA 的作者根據這一特點將 update matrix reparametrize 為兩個低秩矩陣的積積 。 其中,,A 和 B 的秩為 r,且 。 如此一來,A+B 的參數量將大大小于 . LoRA 的論文: https://arxiv.org/pdf/2106.09685.pdf
借助 Huggingface PEFT 框架,使用 LoRA 微調 mt0: https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb
Gradient Checkpointing
在 torch 中使用 - 把 model 用一個 customize 的 function 包裝一下即可,詳見:
Explore Gradient-Checkpointing in PyTorch
https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html 在 Huggingface Transformers 中使用: https://huggingface.co/docs/transformers/v4.27.2/en/perf_train_gpu_one#gradient-checkpointing
Torch FSDP+CPU offload
Fully Sharded Data Paralle(FSDP)和 DeepSpeed 類似,均通過 ZeRO 等分布優化算法,減少內存的占用量。其將模型參數,梯度和優化器狀態分布至多個 GPU 上,而非像 DDP 一樣,在每個 GPU 上保留完整副本。 CPU offload 則允許在一個 back propagation 中,將參數動態地從 GPU -> CPU, CPU -> GPU 進行轉移,從而節省 GPU 內存。 Huggingface 這篇博文解釋了 ZeRO 的大致實現方法: https://huggingface.co/blog/zero-deepspeed-fairscale
借助 torch 實現 FSDP,只需要將 model 用 FSDPwarp 一下;同樣,cpu_offload 也只需要一行代碼: https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/
在這個可以查看 FSDP 支持的模型: https://pytorch.org/docs/stable/fsdp.html
在 Huggingface Transformers 中使用 Torch FSDP: https://huggingface.co/docs/transformers/v4.27.2/en/main_classes/trainer#transformers.Trainin
根據某些 issue,shard_grad_op(只分布保存 optimizer states 和 gradients)模式可能比 fully_shard 更穩定: https://github.com/tatsu-lab/stanford_alpaca/issues/32
審核編輯 :李倩
-
RAM
+關注
關注
8文章
1368瀏覽量
114715 -
參數
+關注
關注
11文章
1836瀏覽量
32234 -
語言模型
+關注
關注
0文章
525瀏覽量
10277
原文標題:有哪些省內存的大語言模型訓練/微調/推理方法?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的預訓練
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
壓縮模型會加速推理嗎?
關于語言模型和對抗訓練的工作

一種基于亂序語言模型的預訓練模型-PERT
CogBERT:腦認知指導的預訓練語言模型

從原理到代碼理解語言模型訓練和推理,通俗易懂,快速修煉LLM

混合專家模型 (MoE)核心組件和訓練方法介紹





 工商網監
工商網監
評論