 計算機視覺中手語識別研究
計算機視覺中手語識別研究
計算機視覺中手語識別研究
手語識別的目的就是通過計算機提供一種有效的、準確的機制將聾啞人常用的手語手勢識別出來,使得他們與健全人之間的交互變得更方便、快捷。同時,手語識別的應用還可以提供更自然的人機交互方式,方便聾啞人對計算機等常用信息設備的使用。目前手語識別可以分為基于視覺(圖像)的識別系統和基于數據手套(佩戴式設備)的識別系統。基于視覺的手勢識別系統采用常見的視頻采集設備作為手勢感知輸入設備,價格便宜、便于安裝。鑒于基于視覺的手勢識別方法交互自然便利,適于普及應用,且更能反映機器模擬人類視覺的功能,所以目前是手勢識別的研究重點。
手語識別的研究開始于1982年,Shantz和Poizner實現了一個合成美國手語的計算機程序。之后,中國、美國、日本、德國等許多國家都進行了自己國家的手語識別與合成研究,并取得了許多重要的研究成果。Triesch和Malsburg開發了一種彈性圖模板匹配技術對復雜背景下的手形進行分類,在相對復雜的背景下的識別率達到86.2%。Davis和Shah將戴上指間具有高亮標記的視覺手套的手勢作為系統的輸入,可識別7種手勢。Starner等在對美國手語中帶有詞性的40個詞匯隨機組成的短句子識別率達到99.2%。Yang等人采用7Hu不變矩特征量進行手語字母識別,最好識別率為90%。
在圖像特征提取方面,為了能夠同時表征圖像的全局特性和局部特性,需要同時提取圖像的全局特征和局部特征,并且這些特征中用以描述圖像整體形狀的特征應當具備平移、旋轉和尺度不變性。SIFT(Scale Invariant Feature Transform)是一種對尺度空間、圖像縮放、旋轉甚至仿射不變的圖像局部特征描述算子;而7Hu不變矩特征量具有平移、旋轉和尺度不變性的特點,具有很好的穩定性,適合描述目標整體形狀。
數據堂自制版權的系列數據集產品為“手勢識別”這一技術路徑的實現提供了強有力的支持。
1314,178張18種手勢識別數據
314,178張18種手勢識別數據涵蓋多種場景、18種手勢、5種拍攝角度、多年齡段、多種光照條件。在標注方面,標注21關鍵點(每個關鍵點有可見不可見屬性)、手勢類別和手勢屬性。314,178張18種手勢識別數據可用于手勢識別、人機交互等任務。
基于線性核函數的SVM平均識別率為95.556%,基于徑向基核函數的SVM平均識別率為83.1282%。實驗表明,采用徑向基核函數的SVM識別率普遍低于采用線性核函數的SVM。
本文提出了一種采用7Hu不變矩特征量等多種圖像特征相融合的SVMs手語識別方法。實驗表明,在手語識別中,采用圖像全局和局部特征相結合的方法,可獲得較高的識別率,為手語識別方法的早日推廣應用提供了理論依據。
審核編輯黃宇
-
計算機視覺
+關注
關注
8文章
1698瀏覽量
46002
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與智能感知是干嘛的
計算機視覺在人工智能領域有哪些主要應用?
深度學習在計算機視覺領域的應用
計算機視覺的主要研究方向
計算機視覺的十大算法

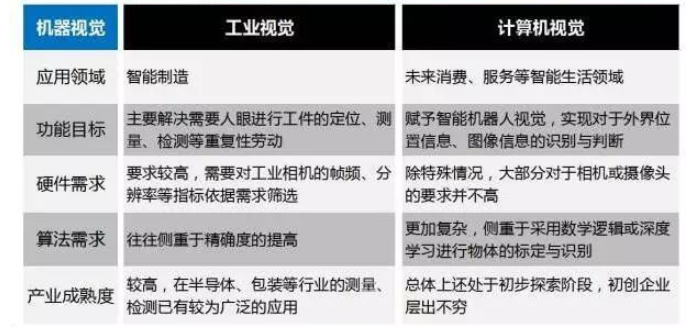
工業視覺與計算機視覺的區別
計算機視覺:AI如何識別與理解圖像





 工商網監
工商網監
評論