") 在視覺語言表示學(xué)習(xí)中建立編碼器間的橋梁
在視覺語言表示學(xué)習(xí)中建立編碼器間的橋梁
0. Take-away messages
提出了一個(gè)簡單有效的視覺語言模型架構(gòu),BridgeTower,通過在頂層單模態(tài)層和每個(gè)跨模態(tài)層之間建立橋梁,成功地引入了不同語義層次的視覺和文本表示,從而提高了跨模態(tài)編碼器中注意力頭的多樣性,并在各種任務(wù)上實(shí)現(xiàn)了突出的性能改進(jìn)。
在公平的評(píng)估設(shè)置下,與Two-Tower架構(gòu)的METER模型相比,BridgeTower顯著地提高了模型的多模態(tài)表示能力。
僅使用400萬張圖片進(jìn)行視覺語言預(yù)訓(xùn)練,BridgeTower在各種視覺語言下游任務(wù)上取得了十分強(qiáng)大的性能,擊敗了許多用更多數(shù)據(jù)和參數(shù)進(jìn)行預(yù)訓(xùn)練的強(qiáng)大模型。
BridgeTower可以適用于不同的視覺、文本或跨模態(tài)編碼器。
1. 背景與動(dòng)機(jī)

視覺語言任務(wù)示例
圖源:12-in-1: Multi-Task Vision and Language Representation Learning
視覺語言研究的目標(biāo),是訓(xùn)練一個(gè)能夠理解圖像和文本的智能AI系統(tǒng)。上圖展示了一些流行的視覺語言任務(wù)。視覺問答是其中最著名的任務(wù)之一,它需要根據(jù)輸入圖像來回答和圖片相關(guān)的問題。
各類視覺語言模型
自2019年以來,在大規(guī)模圖像-文本對(duì)的自監(jiān)督預(yù)訓(xùn)練的幫助下,基于Transformer的視覺語言模型取得了顯著的進(jìn)展。其中,具有雙塔結(jié)構(gòu)的視覺語言 (VL) 模型在視覺語言表示學(xué)習(xí)中占主導(dǎo)地位。基于不同的文本和視覺編碼器,人們提出了各種模型架構(gòu)和預(yù)訓(xùn)練目標(biāo)。從模型架構(gòu)的角度來看,近期大多數(shù)的VL工作,可以看作是由三個(gè)模塊組成的雙塔架構(gòu),即文本編碼器、視覺編碼器,以及在它們之上的跨模態(tài)融合模塊。不同的VL模型在這三個(gè)模塊的設(shè)計(jì)上有所不同。
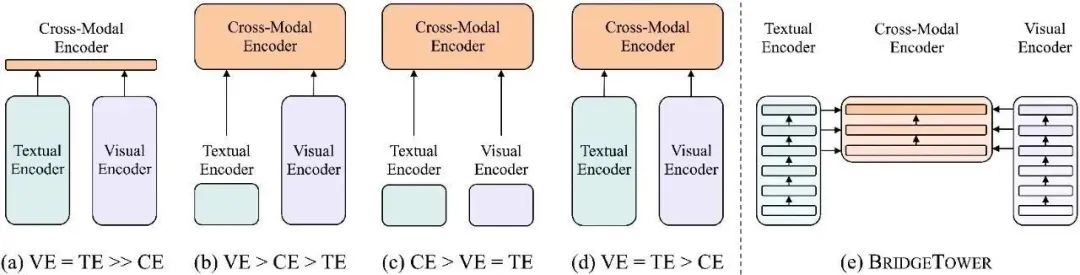
視覺語言模型架構(gòu)簡述
圖(a)-(d)是目前的四類視覺語言模型。圖(e)簡要說明了BridgeTower的模型結(jié)構(gòu)。VE、TE和CE分別是視覺編碼器、文本編碼器和跨模態(tài)編碼器的簡稱。每個(gè)矩形的高度代表其相對(duì)計(jì)算成本。本圖受到了ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision的啟發(fā)。
目前的VL模型要么使用輕量級(jí)的單模態(tài)編碼器,并學(xué)習(xí)在深度跨模態(tài)編碼器中同時(shí)提取、對(duì)齊和融合兩種模態(tài),要么將預(yù)訓(xùn)練的深層單模態(tài)編碼器的最后一層單模態(tài)表示,送入頂部的跨模態(tài)編碼器中。這兩種方法都有可能限制視覺-語言表示的學(xué)習(xí),并進(jìn)一步限制模型的性能。
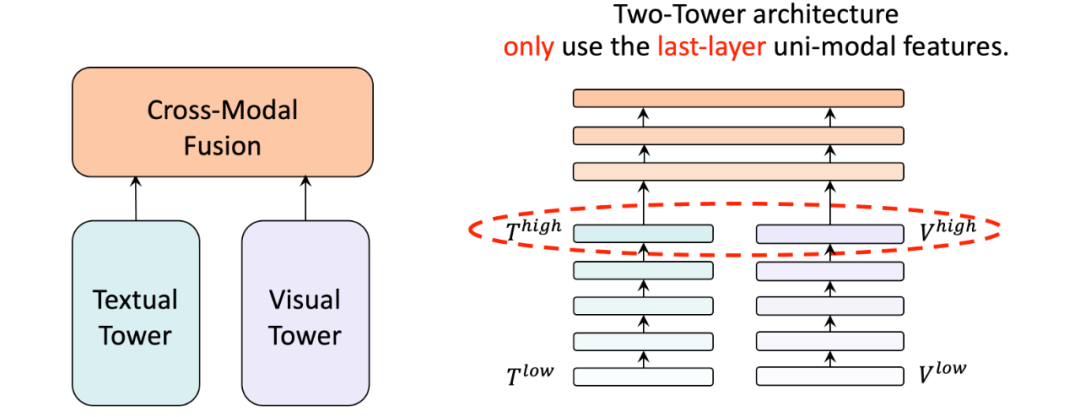
動(dòng)機(jī)
如果我們深入雙塔結(jié)構(gòu)的單模態(tài)塔 (編碼器) ,例如METER模型。我們可以發(fā)現(xiàn)他們只將最后一層的單模態(tài)特征直接送入頂部的跨模態(tài)融合模塊,忽略了深層單模態(tài)塔的不同層的語義信息。我們自然地想到,能否在不同層的預(yù)訓(xùn)練單模態(tài)塔和跨模態(tài)融合模塊之間建立起橋梁,以充分利用多層單模態(tài)特征?
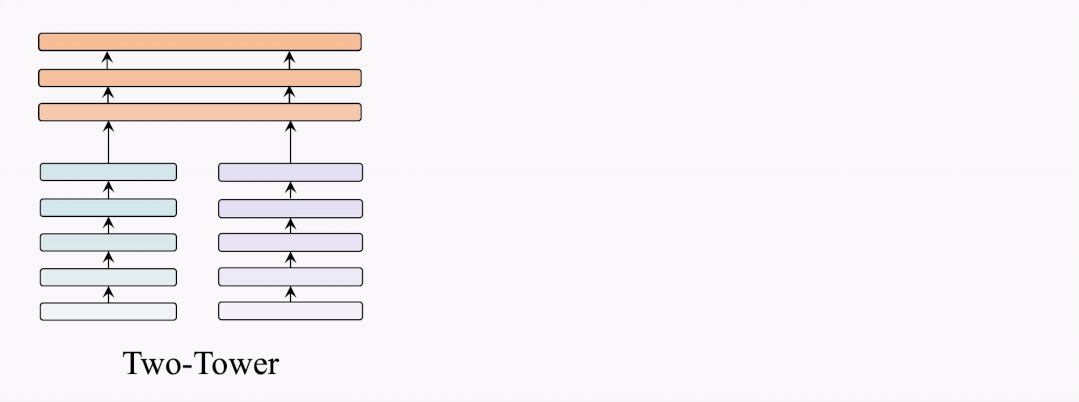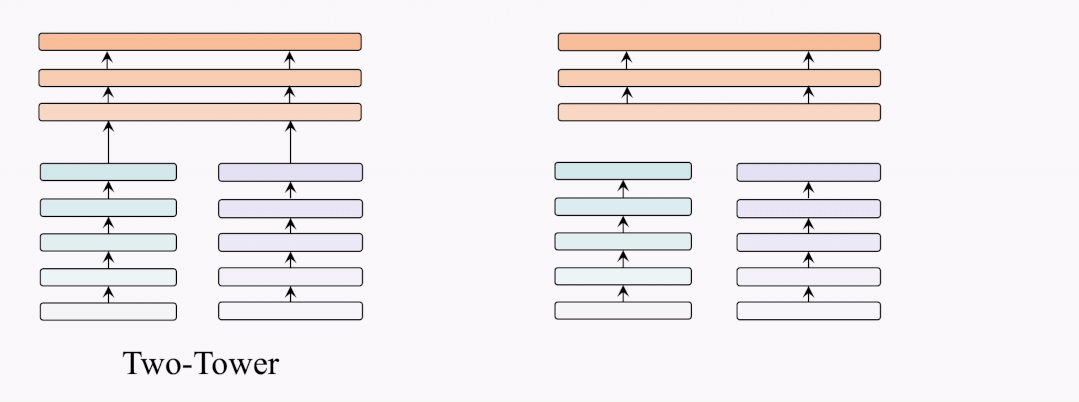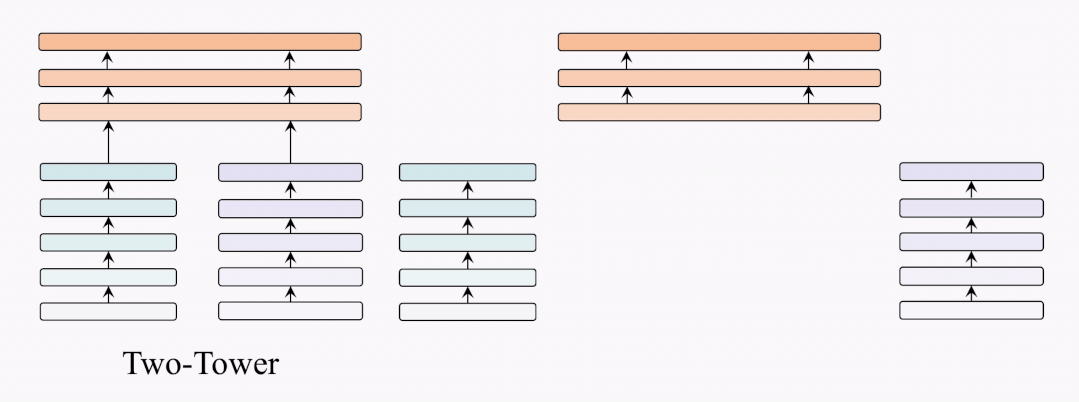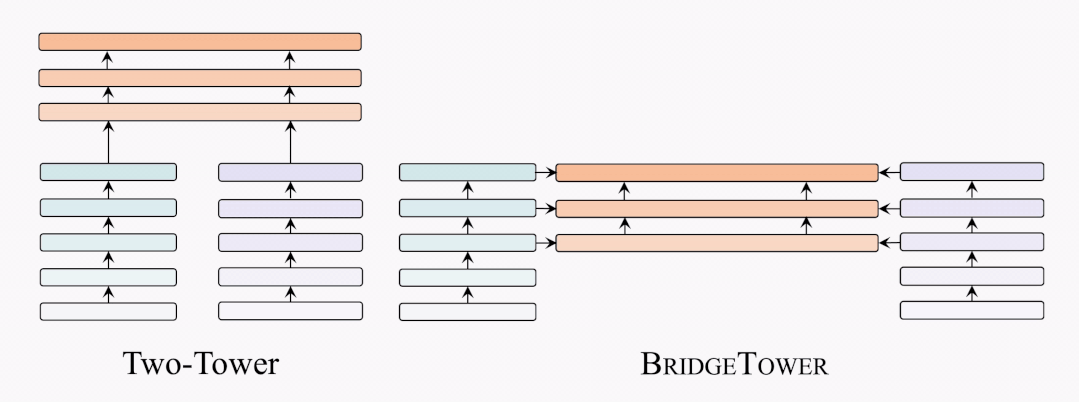
架構(gòu)對(duì)比
因此,我們提出了BridgeTower架構(gòu)。與雙塔架構(gòu)不同,BridgeTower在跨模態(tài)融合模塊和單模態(tài)編碼器之間建立起了多座橋梁。二者的主要區(qū)別在于,雙塔結(jié)構(gòu)只融合最后一層的特征,而BridgeTower則逐漸融合單模態(tài)編碼器頂部的多層特征。
2. 模型架構(gòu)
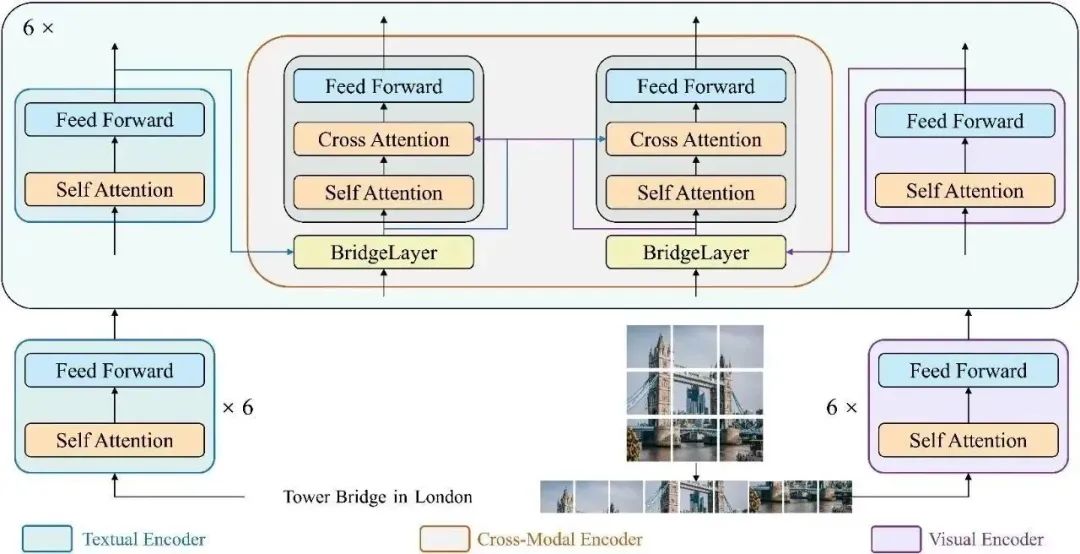
模型架構(gòu)
這里我們展示了BridgeTower的詳細(xì)架構(gòu)圖。具體而言,我們采用12層的RoBERTa-base和12層的CLIP-ViT-B作為單模態(tài)編碼器。跨模態(tài)編碼器為6層,每一層都添加了BridgeLayer來與單模態(tài)編碼器的頂部6層建立連接。
這使得預(yù)訓(xùn)練單模態(tài)編碼器中的不同語義層次的視覺和文本表示,通過BridgeLayer與跨模態(tài)表示進(jìn)行融合,從而促進(jìn)了跨模態(tài)編碼器中,高效的,自下而上的跨模態(tài)對(duì)齊與融合。需要注意的是,BridgeTower架構(gòu)適用于不同的視覺、文本或跨模態(tài)編碼器。
3. 設(shè)計(jì)選擇
我們對(duì)BridgeTower的不同設(shè)計(jì)選擇進(jìn)行了廣泛的實(shí)驗(yàn)。
3.1 BridgeLayer的定義
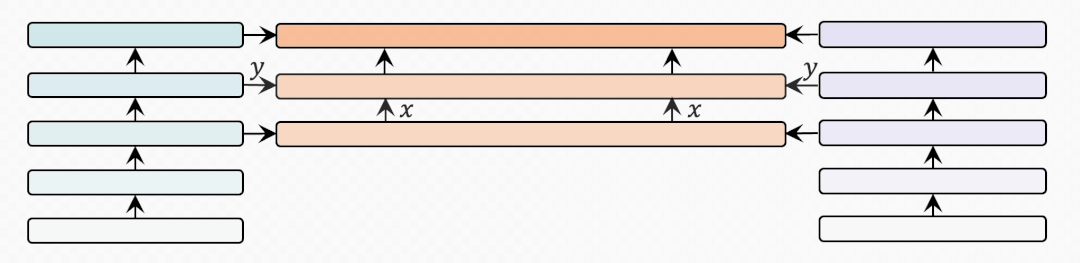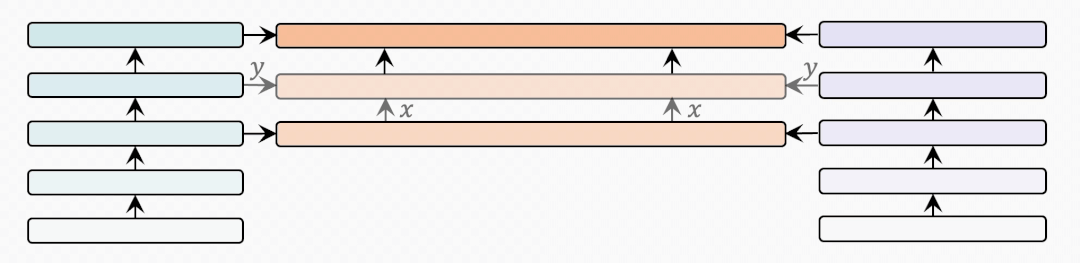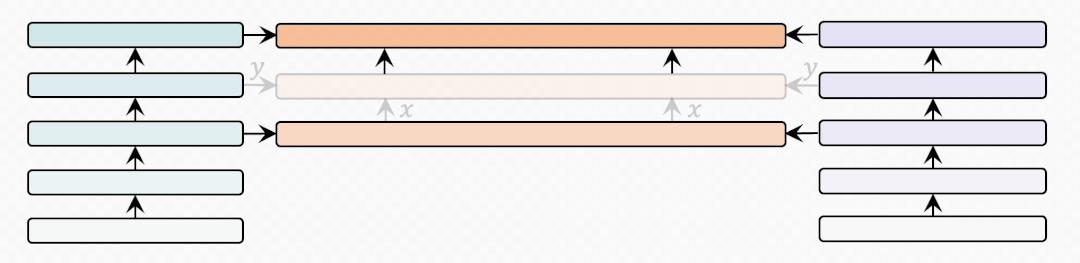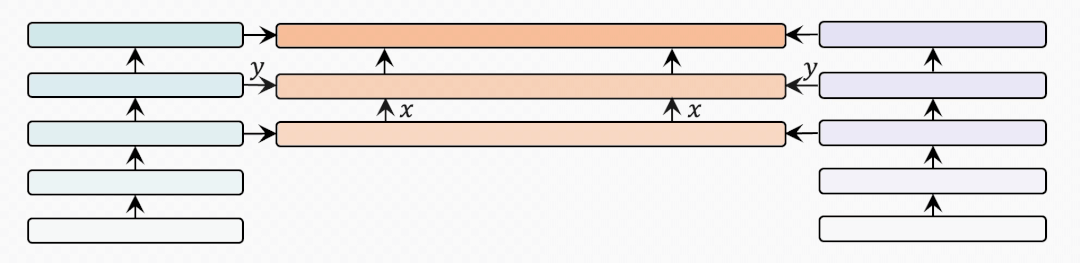
bridge-layer
首先是BridgeLayer的定義,也就是單模態(tài)信息與跨模態(tài)信息如何在BridgeLayer中融合。

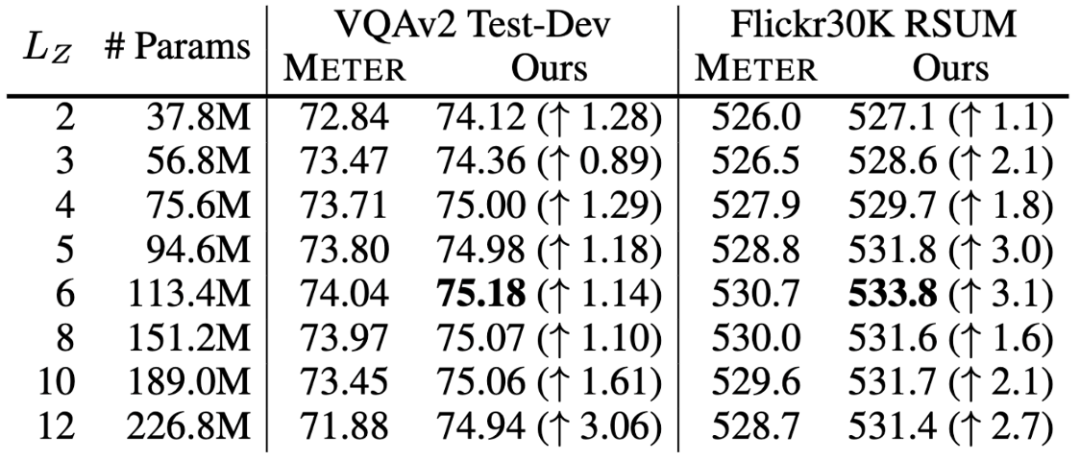
上表展示了不同定義的BridgeLayer的參數(shù)量和其在VQAv2和Flickr30K數(shù)據(jù)集上的性能。RSUM表示圖文檢索任務(wù)的召回度量之和。
表示前一層輸出的跨模態(tài)表示。
表示相應(yīng)的單模態(tài)表示。我們省略了每一行中使用的 。有些出乎意料但又合乎情理的是,第一行中的 使用最小的參數(shù)量得到了最好的結(jié)果。
3.2 Cross-Modal Layer的數(shù)量
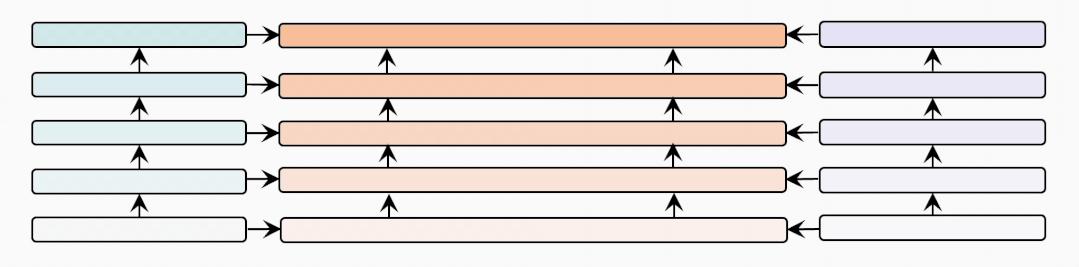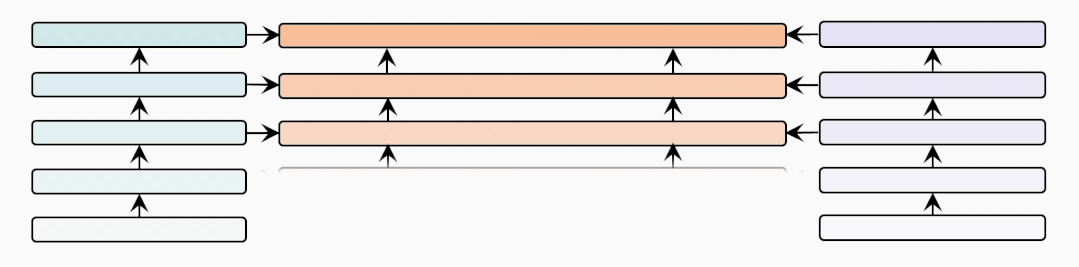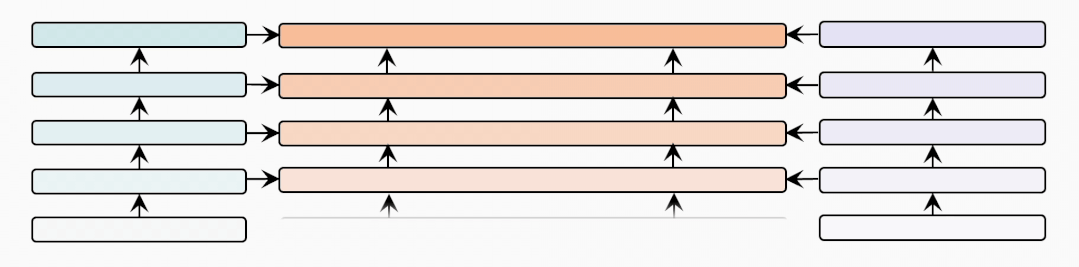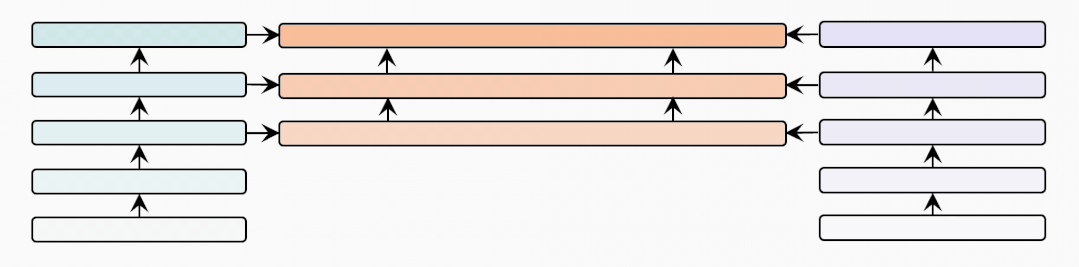
cross-modal-layer
接著我們基于12層的文本和視覺編碼器,研究不同數(shù)量的跨模態(tài)層對(duì)性能的影響。
表示跨模態(tài)層的數(shù)量,并且BridgeTower使用Top-的單模態(tài)表示作為跨模態(tài)層的輸入。我們?cè)趦蓚€(gè)數(shù)據(jù)集上比較不同下,METER和BridgeTower的性能情況,我們發(fā)現(xiàn)更多的跨模態(tài)層并不能不斷提高性能。這可能是由于
更多的跨模態(tài)層需要更多的訓(xùn)練數(shù)據(jù)。
頂層的單模態(tài)表示有利于跨模態(tài)對(duì)齊和融合,而底層的單模態(tài)表示可能不利于,甚至是有害于跨模態(tài)表示的學(xué)習(xí)。雖然METER和BridgeTower之間唯一的區(qū)別是BridgeLayers,但BridgeTower在不同數(shù)量的跨模態(tài)層中始終獲得了一致的性能提升。
3.3 BridgeLayer的數(shù)量
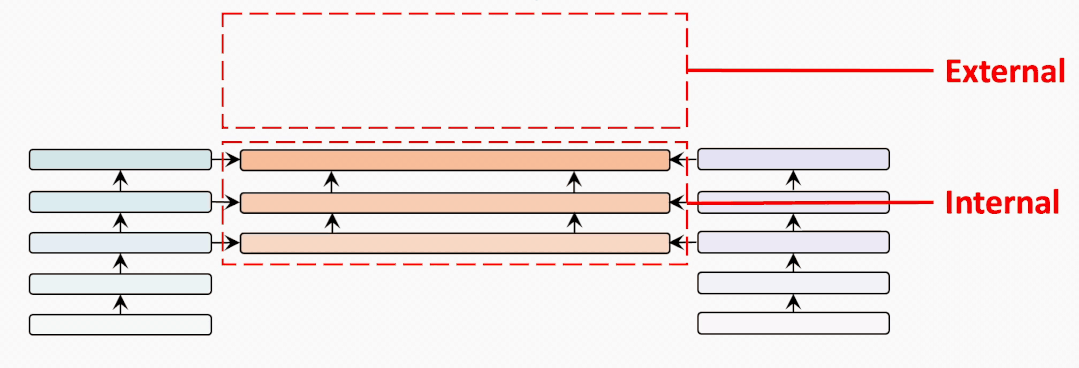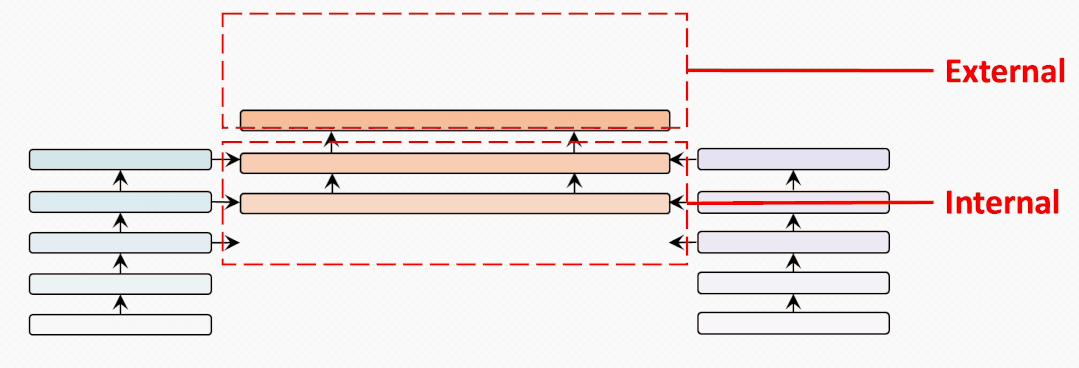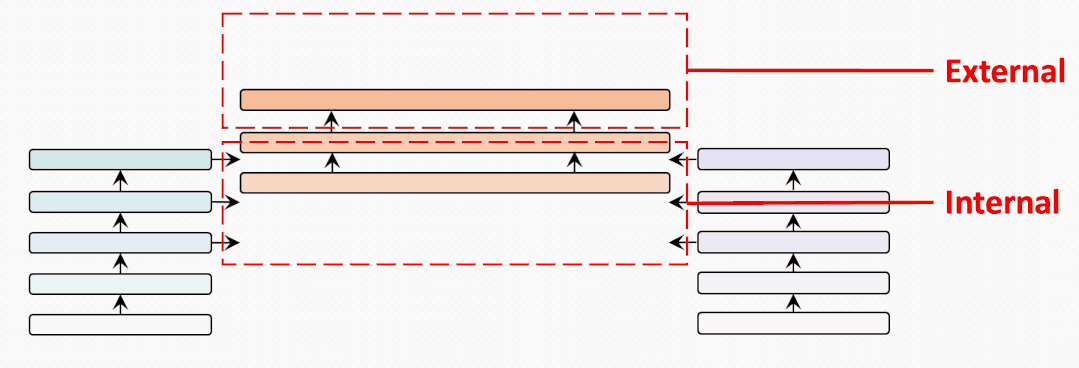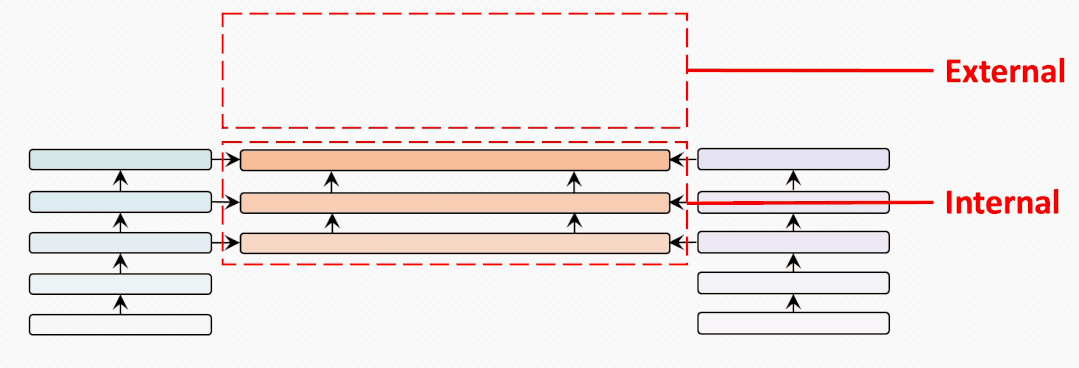
internal-external
最后是BridgeLayer的數(shù)量,也就是在使用相同數(shù)量的跨模態(tài)層時(shí),應(yīng)該加入多少個(gè)BridgeLayer。

為了充分比較BridgeTower和雙塔結(jié)構(gòu)的METER模型,我們?cè)噲D建立一個(gè)從BridgeTower到Two-Tower逐漸變化的情景。為了進(jìn)行公平的比較,我們使用共計(jì)6個(gè)跨模態(tài)層,并將它們分為外部 (External) 跨模態(tài)層和內(nèi)部 (Internal) 跨模態(tài)層。二者的區(qū)別在于內(nèi)部跨模態(tài)層具有BridgeLayer,而外部跨模態(tài)層沒有。
第一行顯示了6個(gè)跨模態(tài)層均為內(nèi)部層的BridgeTower的結(jié)果。然后,我們逐漸增加外部層,減少內(nèi)部層。我們發(fā)現(xiàn)在兩個(gè)數(shù)據(jù)集上的性能都出現(xiàn)了穩(wěn)定的下降。
最后一行顯示了雙塔結(jié)構(gòu)的METER模型的性能。這表明BridgeTower通過BridgeLayers,將單模態(tài)編碼器的頂層與跨模態(tài)編碼器的每一層連接起來,可以顯著提高性能。
3.4 單模態(tài)編碼器
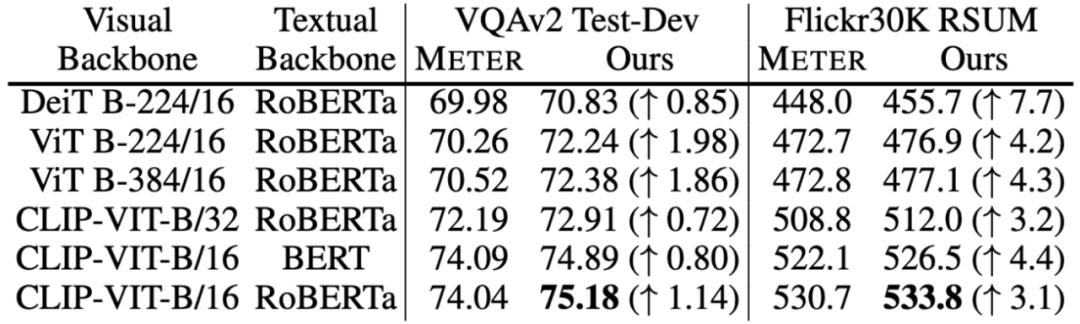
最后我們嘗試了不同的視覺和文本編碼器作為BridgeTower的預(yù)訓(xùn)練單模態(tài)編碼器,并直接對(duì)下游任務(wù)進(jìn)行微調(diào),以進(jìn)一步研究BridgeLayers帶來的影響。我們發(fā)現(xiàn),對(duì)于不同的預(yù)訓(xùn)練視覺和文本編碼器,BridgeTower的性能都持續(xù)且顯著地優(yōu)于METER的性能。
4. 實(shí)驗(yàn)效果

我們基于公共圖文對(duì)數(shù)據(jù)集對(duì)BridgeTower進(jìn)行預(yù)訓(xùn)練,如上表所示,大約共計(jì)400萬張獨(dú)立圖片,900萬對(duì)圖文對(duì)。我們使用通用的掩碼語言建模 (Masked Language Modeling, MLM) 和圖文匹配 (Image-Text Matching, ITM) 任務(wù)作為預(yù)訓(xùn)練任務(wù)。所有的預(yù)訓(xùn)練設(shè)置與預(yù)訓(xùn)練參數(shù)都與METER一致,以提供METER和BridgeTower之間的公平比較。
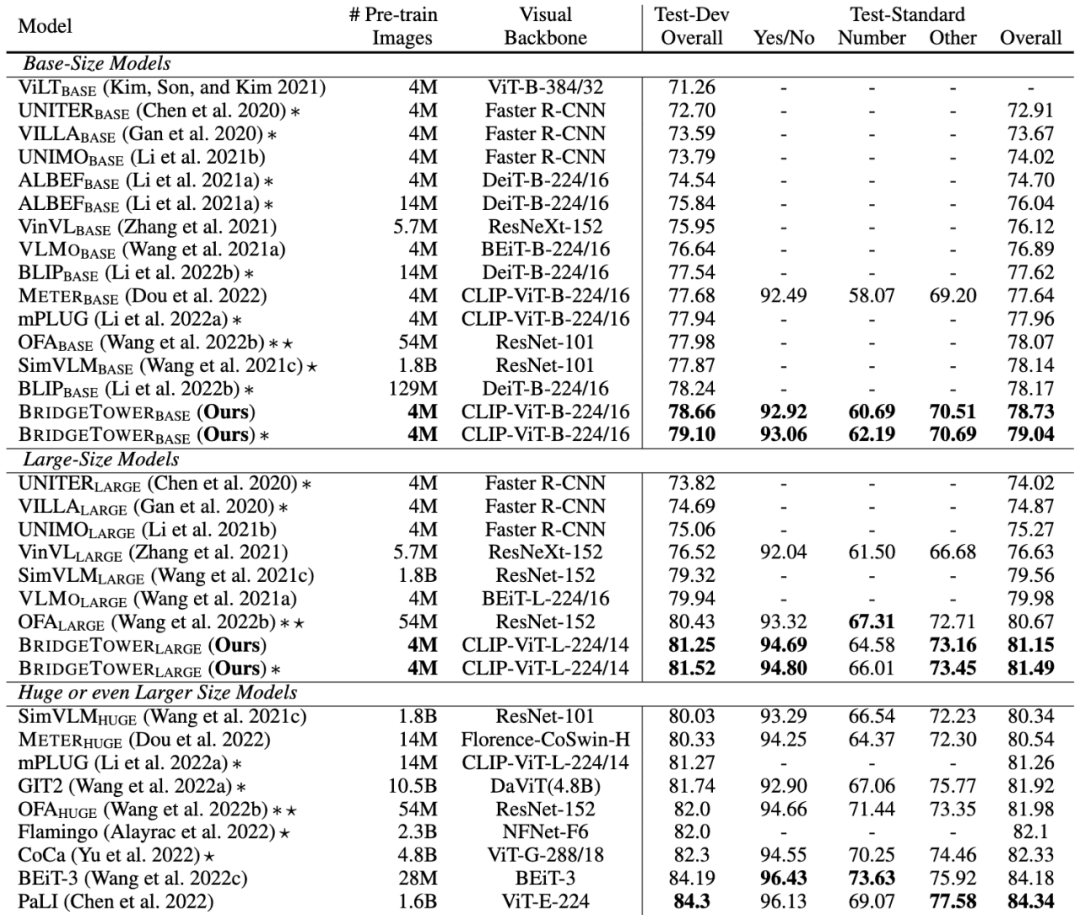
上圖展示了BridgeTower模型在視覺問答 (Visual Question Answering) 的VQAv2數(shù)據(jù)集上的Base和Large兩種Size的模型性能。在視覺-語言預(yù)訓(xùn)練中,我們的Base模型只使用了400萬張圖片進(jìn)行預(yù)訓(xùn)練,就在VQAv2基準(zhǔn)上取得了令人印象深刻的表現(xiàn)。
而且,METER和BridgeTower使用相同的文本編碼器、視覺編碼器和跨模態(tài)融合機(jī)制。只需將METER模型的Two-Tower架構(gòu)改為BridgeTower架構(gòu),在相同的預(yù)訓(xùn)練數(shù)據(jù)和幾乎可以忽略不計(jì)的額外參數(shù)和計(jì)算成本下,VQAv2數(shù)據(jù)集的Test-Standard性能就可以輕松提高1.09。BridgeTower的Large模型在VQAv2數(shù)據(jù)集上更是取得81.15的Test-Standard性能。
值得注意的是,BridgeTower超過了許多使用10倍甚至100倍的圖像進(jìn)行VL預(yù)訓(xùn)練的Base模型與Large模型,擊敗了許多用更多數(shù)據(jù)和參數(shù)進(jìn)行預(yù)訓(xùn)練的強(qiáng)大模型。
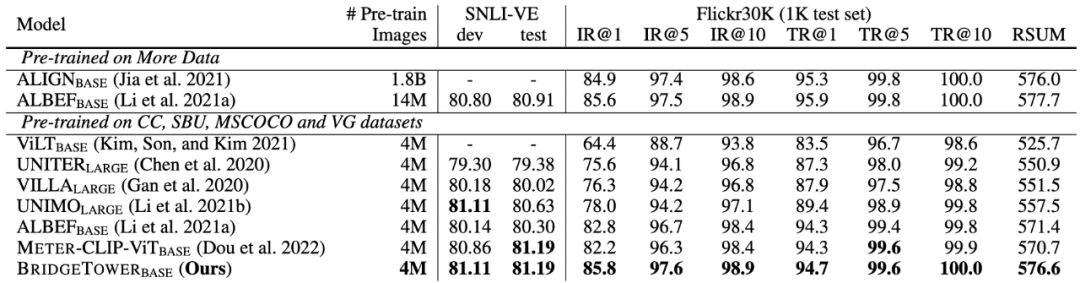
類似的趨勢(shì)也出現(xiàn)在視覺蘊(yùn)含 (Visual Entailment) 和圖像-文本檢索 (Image-Text Retrieval) 任務(wù)中。特別是在Flickr30K數(shù)據(jù)集上,BridgeTower的Base模型帶來了5.9點(diǎn)收益。
5. 可視化結(jié)果
為了進(jìn)一步研究性能提高的原因,我們通過分析每個(gè)跨模態(tài)層中,不同注意力頭的注意力權(quán)重分布之間的KL散度,來比較雙塔架構(gòu)的METER模型和我們的BridgeTower架構(gòu)。
KL散度可以被看作是注意力頭的多樣性。較高或較低的KL散度表示不同的注意力頭之間,關(guān)注的token更加不同或更加相似。
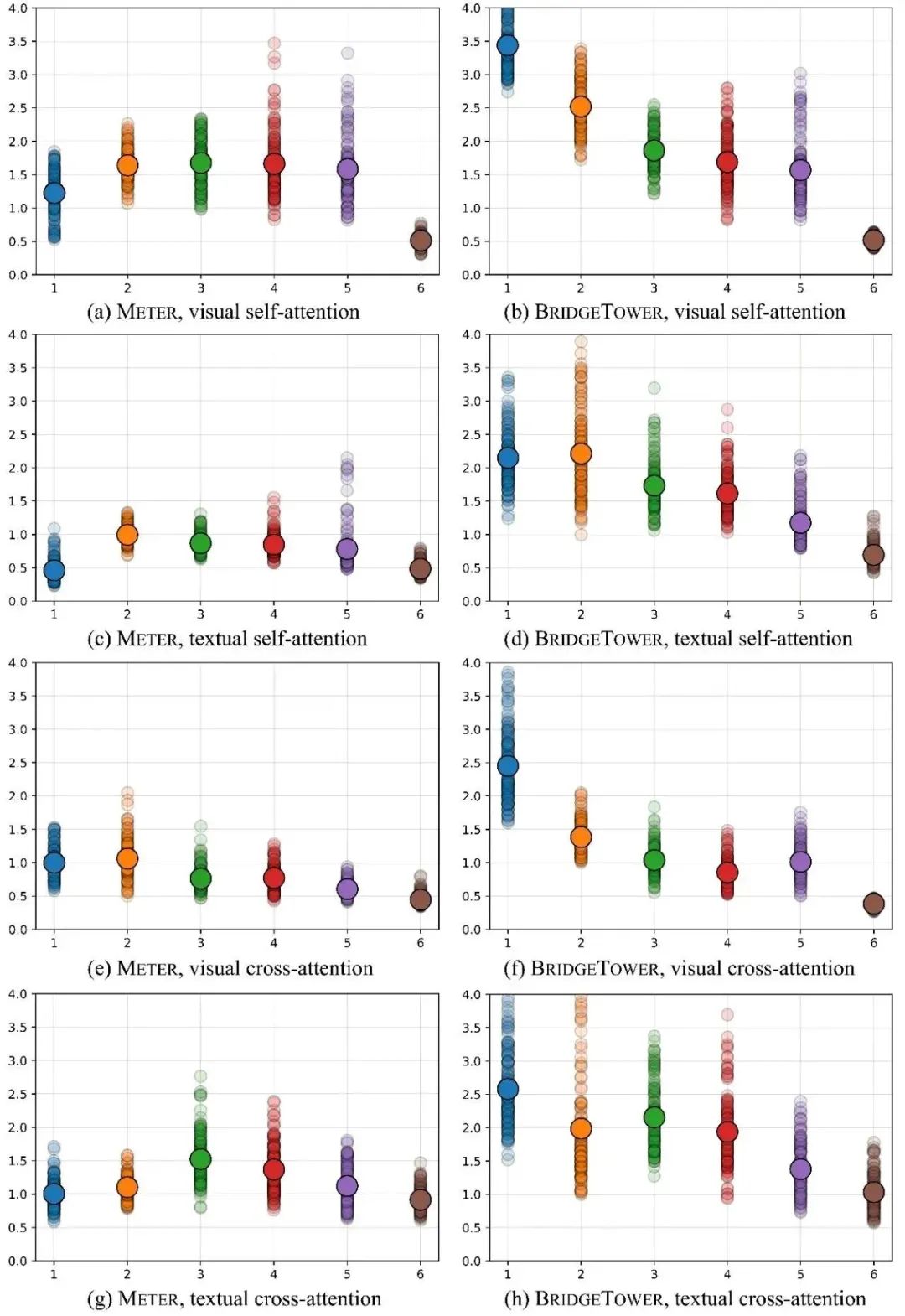
圖中的小點(diǎn)代表不同注意力頭的注意力分布間的KL散度,大點(diǎn)表示同層KL散度的均值。上圖對(duì)比了METER和BridgeTower模型的跨模態(tài)編碼器中,視覺/文本部分的自我/交叉注意力層之間的區(qū)別。
上圖展示了兩個(gè)模型的跨模態(tài)編碼器的視覺和文本部分的自注意力以及交叉注意力的注意力頭的多樣性。圖中存在兩個(gè)明顯的趨勢(shì):
對(duì)于BridgeTower來說,注意力頭的多樣性隨著層的深入而逐漸變小,但對(duì)于METER來說,注意力頭的多樣性隨著層的深入而逐漸變大,然后變小。
BridgeTower每層的注意力頭的多樣性明顯大于METER,尤其是第1層至第5層。
因此,對(duì)于跨模態(tài)編碼器的視覺和文本部分的自注意力以及交叉注意力的不同注意力頭,與METER相比,BridgeTower能夠關(guān)注到更多不同的標(biāo)記 (token)。
我們將此歸功于我們提出的BridgeLayers,它將單模態(tài)編碼器的頂層與跨模態(tài)編碼器的每一層連接起來。不同語義層次的視覺和文本表示通過BridgeLayer與跨模態(tài)表示進(jìn)行融合,從而促進(jìn)了跨模態(tài)編碼器每一層的更有效和更豐富的跨模態(tài)對(duì)齊和融合。
6. 結(jié)論
在本文中,我們提出了BridgeTower,它引入了多個(gè)BridgeLayer,在單模態(tài)編碼器的頂層和跨模態(tài)編碼器的每一層之間建立連接。這使得預(yù)訓(xùn)練單模態(tài)編碼器中的不同語義層次的視覺和文本表示,通過BridgeLayer與跨模態(tài)表示進(jìn)行融合,從而促進(jìn)了跨模態(tài)編碼器中,高效的,自下而上的跨模態(tài)對(duì)齊與融合。
僅使用400萬張圖像進(jìn)行視覺語言預(yù)訓(xùn)練,BridgeTower在各種下游的視覺-語言任務(wù)中取得了非常強(qiáng)大的性能。特別是在VQAv2數(shù)據(jù)集上,BridgeTower達(dá)到了78.73%的準(zhǔn)確率,在相同的預(yù)訓(xùn)練數(shù)據(jù)和幾乎可以忽略不計(jì)的額外參數(shù)和計(jì)算成本下,比Two-Tower架構(gòu)的METER模型高出了1.09%的準(zhǔn)確率。值得注意的是,當(dāng)進(jìn)一步擴(kuò)展該模型時(shí),BridgeTower達(dá)到了81.15%的準(zhǔn)確率,甚至超過了一些在更大數(shù)量級(jí)的數(shù)據(jù)集上使用更多參數(shù)進(jìn)行預(yù)訓(xùn)練的強(qiáng)大模型。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3643瀏覽量
134525
原文標(biāo)題:AAAI2023 | BridgeTower: 在視覺語言表示學(xué)習(xí)中建立編碼器間的橋梁
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
編碼器在機(jī)器人技術(shù)中的應(yīng)用 編碼器在傳感器系統(tǒng)中的作用
如何選擇合適的磁編碼器 磁編碼器在機(jī)器人技術(shù)中的角色
磁電編碼器和光電編碼器的區(qū)別
電機(jī)控制系統(tǒng)中的編碼器概述與作用
AGV輪轂電機(jī)中的編碼器

自編碼器的原理和類型
旋轉(zhuǎn)編碼器在PLC中怎么編程
編碼器在機(jī)器人系統(tǒng)中的應(yīng)用
編碼器在自動(dòng)化系統(tǒng)中的應(yīng)用
增量編碼器和絕對(duì)值編碼器的區(qū)別
絕對(duì)值編碼器的工作原理及其在電機(jī)控制中的應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論