") 如何優(yōu)雅地將Swin Transformer模型部署到AX650N Demo板上?
如何優(yōu)雅地將Swin Transformer模型部署到AX650N Demo板上?
01
背景
今年來(lái)以ChatGPT為代表的大模型的驚艷效果,讓AI行業(yè)迎來(lái)了新的動(dòng)力。各種AIGC的應(yīng)用接踵而至。我們知道類似ChatGPT的大模型,其核心網(wǎng)絡(luò)結(jié)構(gòu)均基于Google 2017年的論文提出的Transformer的論文《Attention Is All You Need》。在計(jì)算機(jī)視覺(jué)建模一直由卷積神經(jīng)網(wǎng)絡(luò)(CNN)主導(dǎo),基于Transformer結(jié)構(gòu)的網(wǎng)絡(luò)模型長(zhǎng)時(shí)間停留在各大頂會(huì)“刷榜”階段,真正大規(guī)模落地并不突出。直到ICCV 2021的最佳論文《Swin Transformer》才達(dá)到了準(zhǔn)確率和性能雙佳的效果。
但是到目前為止,類似Swin Transformer的視覺(jué)類Transformer網(wǎng)絡(luò)模型大多數(shù)還是部署在云端服務(wù)器上,原因是GPU對(duì)于MHA結(jié)構(gòu)計(jì)算支持更友好,反而邊緣側(cè)/端側(cè)AI芯片由于其DSA架構(gòu)限制,為了保證CNN結(jié)構(gòu)的模型效率更好,基本上對(duì)MHA結(jié)構(gòu)沒(méi)有過(guò)多性能優(yōu)化,甚至需要修改網(wǎng)絡(luò)結(jié)構(gòu)才能勉強(qiáng)部署。這也間接限制了算法工程師在邊緣計(jì)算應(yīng)用上進(jìn)一步發(fā)揮Transformer網(wǎng)絡(luò)的想象力。
今年3月,愛(ài)芯元智發(fā)布了新一代產(chǎn)品AX650N,內(nèi)置了其自主研發(fā)的第三代神經(jīng)網(wǎng)絡(luò)單元,進(jìn)一步提升了最新AI算法模型的部署能力,可幫助用戶在智慧城市,智慧教育,智能制造等領(lǐng)域發(fā)揮更大的價(jià)值。最近我通過(guò)正式渠道有幸拿到了一塊AX650N Demo板進(jìn)行嘗鮮體驗(yàn)。
本文的目的是簡(jiǎn)單介紹基于AX650N Demo配套的新一代AI工具鏈如何優(yōu)雅地將Swin Transformer模型部署到AX650N Demo板上,希望能給算法工程師們?cè)赥ransformer網(wǎng)路部署落地上提供一種新的思路和途徑。
02
Swin Transformer
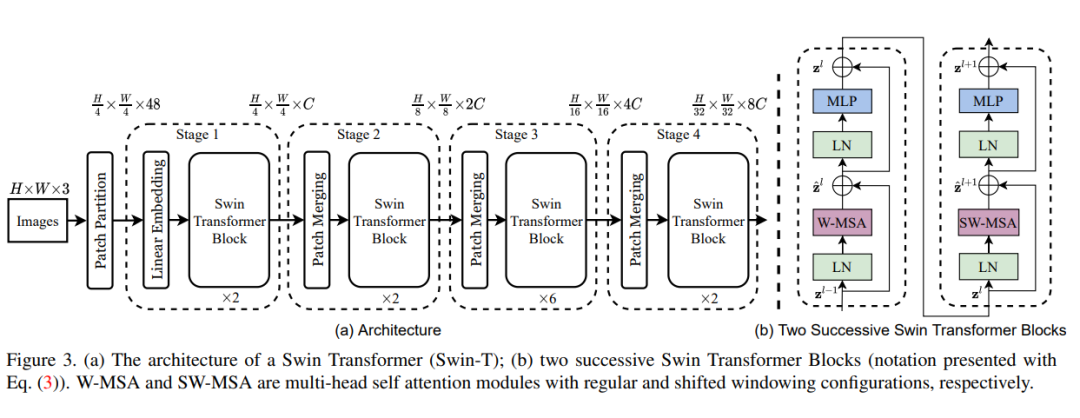
The architecture of a Swin Transformer
目前Transformer應(yīng)用到圖像領(lǐng)域主要有兩大挑戰(zhàn):
視覺(jué)實(shí)體變化大,在不同場(chǎng)景下視覺(jué)Transformer性能未必很好;
圖像分辨率高,像素點(diǎn)多,Transformer基于全局自注意力的計(jì)算導(dǎo)致計(jì)算量較大。
2.1 原理
針對(duì)上述兩個(gè)問(wèn)題,微軟在《Swin Transformer》的論文中提出了一種包含滑窗操作。其中滑窗操作包括不重疊的local window,和重疊的cross-window。將注意力計(jì)算限制在一個(gè)窗口中,一方面能引入CNN卷積操作的局部性,另一方面能節(jié)省計(jì)算量。在各大圖像任務(wù)上,Swin Transformer都具有很好的性能。
2.2 分析
相比常見(jiàn)CNN網(wǎng)絡(luò)模型,其實(shí)也就是新增了MHA(Multi Head Attention)的關(guān)鍵算子
LayerNormalization
Matmul
GELU
量化
LN、GELU、Matmul存在掉點(diǎn)風(fēng)險(xiǎn)
計(jì)算效率
占比最大的計(jì)算操作由Conv變成Matmul,因此要求硬件平臺(tái)MatMul計(jì)算能力強(qiáng)
03
模型轉(zhuǎn)換
Pulsar2介紹
Pulsar2(暫定名)是我們的新一代AI工具鏈,在吸取上一代工具鏈Pulsar的優(yōu)秀行業(yè)經(jīng)驗(yàn)和不足之處的反思后進(jìn)行的重構(gòu),依然包含“模型轉(zhuǎn)換、離線量化、模型編譯、異構(gòu)調(diào)度”四合一功能,進(jìn)一步強(qiáng)化的網(wǎng)絡(luò)模型快速、高效的部署需求。在針對(duì)第三NPU架構(gòu)進(jìn)行了深度定制優(yōu)化的同時(shí),也擴(kuò)展了算子&模型支持的能力及范圍,對(duì)Transformer結(jié)構(gòu)的網(wǎng)絡(luò)也有較好的支持。
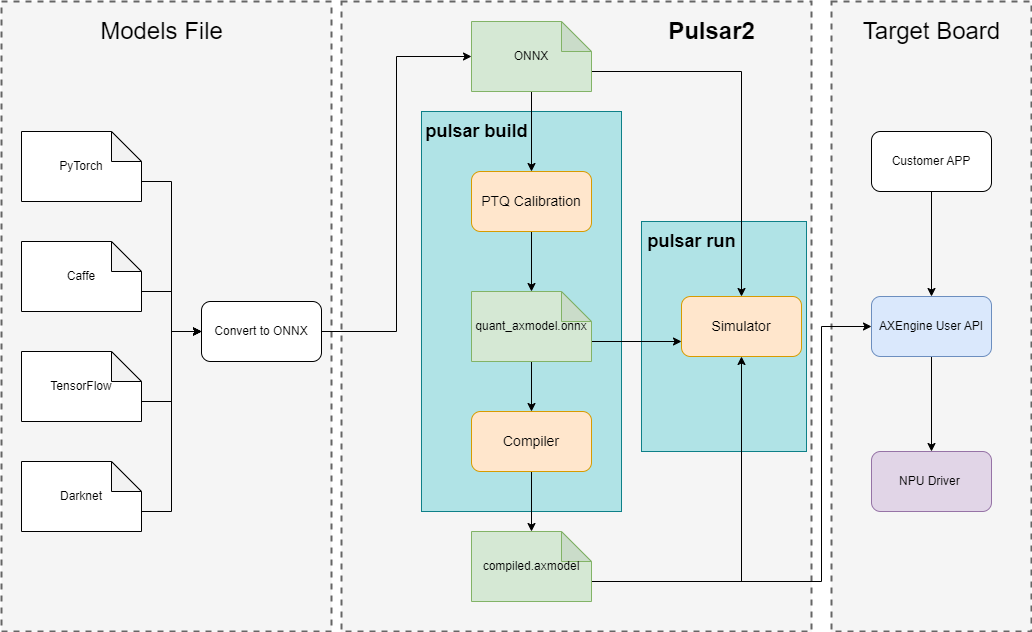
pulsar2 deploy pipeline
3.1 模型下載
從Swin Transformer的官方倉(cāng)庫(kù)獲取模型,由于是基于PyTorch訓(xùn)練,導(dǎo)出的是原始的pth模型格式,而對(duì)于部署的同學(xué)而言,更喜歡使用ONNX模型進(jìn)行后續(xù)的產(chǎn)品落地,為了方便測(cè)試,我們提供該模型的ONNX版本導(dǎo)出腳本,降低模型獲取門檻,便于之前不熟悉的同學(xué)直接掌握其中的關(guān)鍵操作。
import onnx import torch import requests from onnxsim import simplify from PIL import Image from transformers import AutoFeatureExtractor, SwinForImageClassification def download_swin_model(model_name): prefix = "microsoft" model_id = f"{prefix}/{model_name}" # google/vit-base-patch16-384 url = 'http://images.cocodataset.org/val2017/000000039769.jpg' image = Image.open(requests.get(url, stream=True).raw) feature_extractor = AutoFeatureExtractor.from_pretrained(model_id) model = SwinForImageClassification.from_pretrained(model_id) inputs = feature_extractor(images=image, return_tensors="pt") outputs = model(**inputs) logits = outputs.logits # model predicts one of the 1000 ImageNet classes predicted_class_idx = logits.argmax(-1).item() print("Predicted class:", model.config.id2label[predicted_class_idx]) # export model_path = f"{model_name}.onnx" torch.onnx.export( model, tuple(inputs.values()), f=model_path, do_constant_folding=True, opset_version=13, input_names=["input"], output_names=["output"] ) # simplify model = onnx.load(model_path) model_simp, check = simplify(model) assert check, "Simplified ONNX model could not be validated" simp_path = f"{model_name}_sim.onnx" onnx.save(model_simp, simp_path) def main(): download_swin_model(model_name="swin-tiny-patch4-window7-224") # microsoft/swin-tiny-patch4-window7-224 if __name__ == "__main__": main()
3.2 模型編譯
Pulsar2為了提升用戶使用體驗(yàn),降低Pulsar客戶遷移的學(xué)習(xí)成本,基本上延續(xù)了原有風(fēng)格,包括Docker環(huán)境安裝、命令行指令、配置文件修改參數(shù)、仿真功能等。同時(shí)針對(duì)編譯速度慢的痛點(diǎn),進(jìn)行了大幅度優(yōu)化,模型編譯的耗時(shí)相比第一代工具鏈平均降低了一個(gè)數(shù)量級(jí)(分鐘->秒)。
$ pulsar2 build --input model/swin-t.onnx --output_dir output --config config/swin-t.json --target_hardware=AX650 32 File(s) Loaded. [10:22:36] AX Quantization Config Refine Pass Running ... Finished. [10:22:36] AX Quantization Fusion Pass Running ... Finished. [10:22:36] AX Quantize Simplify Pass Running ... Finished. [10:22:36] AX Parameter Quantization Pass Running ... Finished. Calibration Progress(Phase 1): 100%|████████| 32/32 [00:08<00:00, ?3.92it/s] Finished. [10:22:45] AX Passive Parameter Quantization Running ... ?Finished. [10:22:45] AX Parameter Baking Pass Running ... ? ? ? ? ? Finished. [10:22:45] AX Refine Int Parameter pass Running ... ? ? ? Finished. Network Quantization Finished. quant.axmodel export success: output/quant/quant_axmodel.onnx Building native ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 100% 0:00:00 ...... 2023-04-13 10:23:07.109 | INFO ? ? | yasched.test_onepass1475 - max_cycle = 6689562 2023-04-13 10:23:25.765 | INFO ? ? | yamain.command.build832 - fuse 1 subgraph(s)
從編譯log中我們大致看出,計(jì)算圖優(yōu)化、PTQ量化、離線編譯總共耗時(shí)只需50秒。然后我們來(lái)看一下大家比較關(guān)心的MHA結(jié)構(gòu)變成了什么樣子:
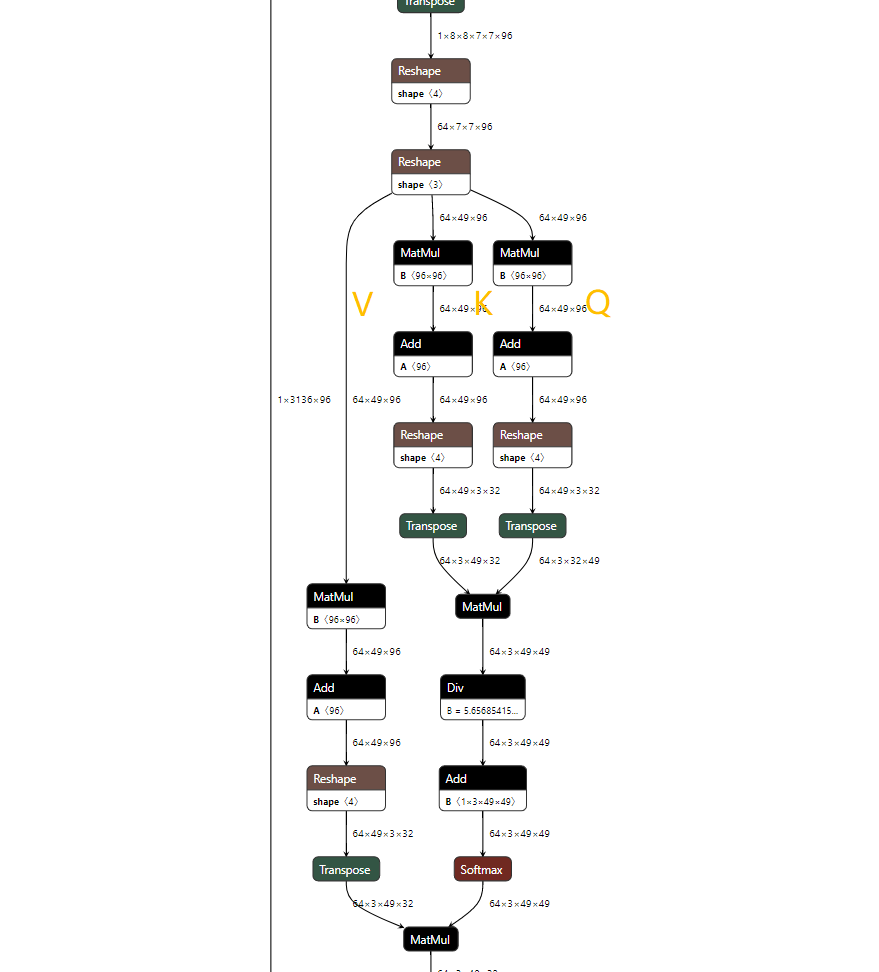
MHA ONNX原始結(jié)構(gòu)
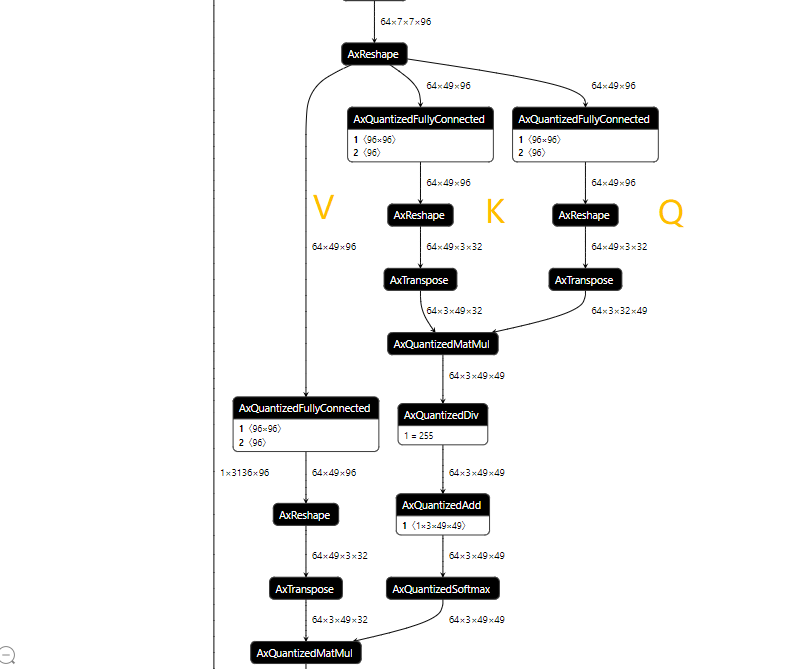
MHA由工具鏈進(jìn)行圖優(yōu)化之后的quant.axmodel結(jié)構(gòu)
3.3 仿真運(yùn)行
在這一代工具鏈,我們提供更方便的pulsar2-run-helper的插件,可以模擬NPU計(jì)算流程,方便提前獲得上板運(yùn)行結(jié)果。(請(qǐng)大家記住仿真運(yùn)行的結(jié)果,后續(xù)章節(jié)將與上板實(shí)際部署的推理結(jié)果進(jìn)行比對(duì))
python3 cli_classification.py --post_processing --axmodel_path models/swin-t.axmodel --intermediate_path sim_outputs/0 [I] The following are the predicted score index pair. [I] 2.6688, 285 [I] 1.9528, 223 [I] 1.8877, 279 [I] 1.8877, 332 [I] 1.8226, 282
04
上板部署
AX650N Demo板的BSP上已經(jīng)預(yù)裝了NPU模型測(cè)試需要的工具
/root # sample_npu_classification -m swin-t.axmodel -i cat.jpg -r 100 -------------------------------------- model file : swin-t.axmodel image file : cat.jpg img_h, img_w : 224 224 -------------------------------------- Engine creating handle is done. Engine creating context is done. Engine get io info is done. Engine alloc io is done. Engine push input is done. -------------------------------------- 2.6688, 285 1.9528, 223 1.8877, 332 1.8877, 279 1.8226, 282 -------------------------------------- Repeat 100 times, avg time 8.64 ms, max_time 8.65 ms, min_time 8.64 ms --------------------------------------
對(duì)比上一章節(jié)的仿真結(jié)果,完全一致。
4.1 算力分配
AX650N的10.8Tops@Int8的算力其實(shí)是可分配的,上述內(nèi)容中,按照默認(rèn)的編譯選項(xiàng),其實(shí)只發(fā)揮了一部分算力(3.6Tops@Int8)。我們來(lái)看看滿算力下的耗時(shí)表現(xiàn)如何呢?
/root # ax_run_model -m swin-t-npu3.axmodel -r 100
Run AxModel:
model: swin-t-npu3.axmodel
type: NPU3
vnpu: Disable
affinity: 0b001
repeat: 100
warmup: 1
batch: 1
tool ver: 1.0.0
------------------------------------------------------
min = 3.769 ms max = 3.805 ms avg = 3.778 ms
------------------------------------------------------
/root #
/root # sample_npu_classification -m swin-t-npu3.axmodel -i cat.jpg -r 100
--------------------------------------
model file : swin-t-npu3.axmodel
image file : cat.jpg
img_h, img_w : 224 224
--------------------------------------
Engine creating handle is done.
Engine creating context is done.
Engine get io info is done.
Engine alloc io is done.
Engine push input is done.
--------------------------------------
2.6688, 285
1.9528, 223
1.8877, 332
1.8877, 279
1.8226, 282
--------------------------------------
Repeat 100 times, avg time 3.78 ms, max_time 3.79 ms, min_time 3.77 ms
--------------------------------------
05
性能統(tǒng)計(jì)
| 算力 | 耗時(shí)(ms) | 幀率(fps) |
| 3.6Tops@Int8 | 8.64 | 115 |
| 10.8Tops@Int8 | 3.77 | 265 |
NPU工具鏈的性能優(yōu)化是個(gè)長(zhǎng)期堅(jiān)持的過(guò)程,最新版本的性能數(shù)據(jù)會(huì)更優(yōu)秀。
審核編輯:劉清
-
gpu
+關(guān)注
關(guān)注
28文章
4760瀏覽量
129131 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22265 -
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
367瀏覽量
11885 -
ChatGPT
+關(guān)注
關(guān)注
29文章
1564瀏覽量
7861
原文標(biāo)題:愛(ài)芯分享 | 基于AX650N部署Swin Transformer
文章出處:【微信號(hào):愛(ài)芯元智AXERA,微信公眾號(hào):愛(ài)芯元智AXERA】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
transformer專用ASIC芯片Sohu說(shuō)明

基于AX650N的M.2智能推理卡解決方案
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測(cè)模型
基于AX650N/AX630C部署多模態(tài)大模型InternVL2-1B

基于AX650N芯片部署MiniCPM-V 2.0高效端側(cè)多模態(tài)大模型

Transformer語(yǔ)言模型簡(jiǎn)介與實(shí)現(xiàn)過(guò)程
llm模型本地部署有用嗎
基于AX650N/AX630C部署端側(cè)大語(yǔ)言模型Qwen2
使用PyTorch搭建Transformer模型
【大語(yǔ)言模型:原理與工程實(shí)踐】大語(yǔ)言模型的基礎(chǔ)技術(shù)
愛(ài)芯元智AX620E和AX650系列芯片正式通過(guò)PSA Certified安全認(rèn)證

基于AX650N/AX620Q部署YOLO-World
使用CUBEAI部署tflite模型到STM32F0中,模型創(chuàng)建失敗怎么解決?
基于Transformer模型的壓縮方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論