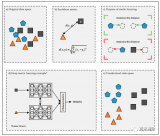
 機器學習算法的分類
機器學習算法的分類
一、監督學習根據有無標簽分類
根據有無標簽,監督學習可分類為:傳統的監督學習(Traditional Supervised Learning)、非監督學習(Unsupervised Learning)、半監督學習(Semi-supervised Learning)。
(1)傳統的監督學習
傳統的監督學習的每個訓練數據均具有標簽(標簽可被理解為每個訓練數據的正確輸出,計算機可通過其輸出值與標簽對比進行機器學習)。傳統的監督學習包括:支持向量機(Support Vector Machine)、人工神經網絡 (Neural Networks)、深度神經網絡(Deep Neural Networks)。
(2)非監督學習
非監督學習的所有數據均沒有標簽。非監督學習假設同一類訓練數據在空間中距離更近(個人理解:例如將若干含有兩個變量的訓練數據繪制于平面直角坐標系中,同一類訓練數據在坐標系中的距離更近),計算機可根據樣本空間信息,將空間距離更近的數據分為一類。非監督學習包括:聚類(Clustering)、EM算法(Expectation-Maximization Algorithm)、主成分分析(Principle Component Analysis)。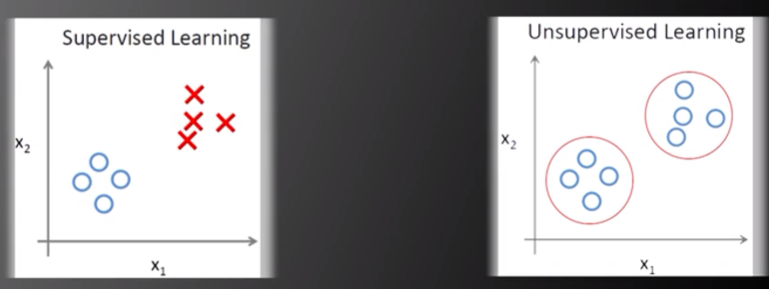
圖片來源:中國慕課大學《機器學習概論》
(3)半監督學習
半監督學習中,一部分訓練數據具有標簽,一部分訓練數據沒有標簽。因為隨著互聯網的普及,互聯網中存在大量數據,將所有互聯網數據進行標注的耗費較大,所以研究如何通過少量標注數據和大量未標注數據共同訓練機器學習算法,即半監督學習成為機器學習的研究方向之一。
二、監督學習根據標簽固有屬性分類
根據標簽固有屬性,監督學習可被分為分類(Classification)和回歸(Regression)。如果標簽是離散的值,該種監督學習被稱為分類;如果標簽是連續的值,該種監督學習被稱為回歸。 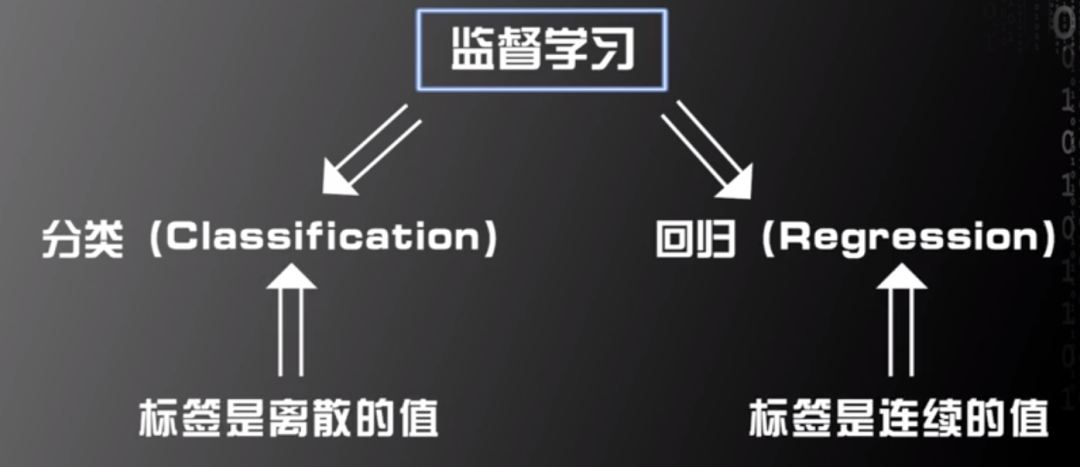
圖片來源:中國慕課大學《機器學習概論》
人臉識別屬于監督學習中的分類。人臉識別的任務包括兩個:其一是識別兩張人臉圖片是否為同一個人,開發人員可將兩張人臉圖片是同一個人的標簽定義為1,將兩張人臉圖片不是同一個人的標簽定義為0;其二是在多張人臉圖片(也可以是多個人臉在一張圖片中)識別某個人臉,開發人員可將每個人臉定義標簽為一個數字,可根據數字1、2、3……N的順序為每個人臉定義標簽。以上人臉識別兩個任務的標簽均是離散的值。 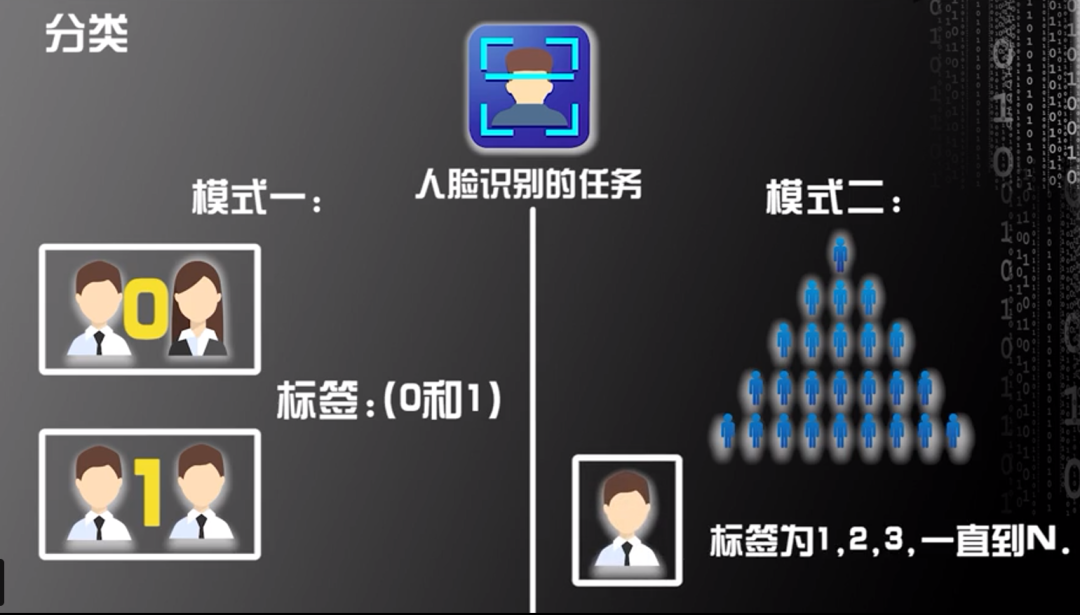
圖片來源:中國慕課大學《機器學習概論》
預測股票價格、預測房價、預測溫度、預測年齡等問題屬于監督學習問題中的回歸問題。一般,股票、房價、溫度、年齡變化的數據(個人理解:此處的數據可被理解為標簽)可被視為連續的值。
雖然監督學習可被分為分類和回歸,但分類和回歸的界限是模糊的,二者可以相互轉換,這是由于連續數據和離散數據是可以相互轉換的。例如:如果將房價值四舍五入,得出一組離散的數據(標簽),那么預測房價問題可屬于分類問題。因此,一個可以解決回歸問題的機器學習算法經過較少的改造可解決分類問題,反之亦然。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
計算機
+關注
關注
19文章
7494瀏覽量
87962 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646
原文標題:機器學習相關介紹(3)——機器學習算法的分類(下)
文章出處:【微信號:行業學習與研究,微信公眾號:行業學習與研究】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NPU與機器學習算法的關系
【每天學點AI】KNN算法:簡單有效的機器學習分類器
人工智能、機器學習和深度學習存在什么區別

LIBS結合機器學習算法的江西名優春茶采收期鑒別

利用Matlab函數實現深度學習算法
深度學習中的時間序列分類方法
機器學習算法原理詳解
機器學習在數據分析中的應用
基于神經網絡的呼吸音分類算法
機器學習怎么進入人工智能
機器學習8大調參技巧

機器學習多分類任務深度解析





 工商網監
工商網監
評論