 機器學習算法學習之特征工程3
機器學習算法學習之特征工程3
處理偏度和峰度
偏度和峰度是可以幫助理解數據分布的統計量。偏度度量數據的不對稱程度,而峰度度量分布的峰度或平坦程度。

Fig.5 — Skewness
處理偏度的方法會對機器學習模型的性能產生負面影響。因此,處理數據中的偏度非常重要。以下是一些處理數據偏度的技巧:
1.對數變換(Log transformation):對數變換可以用來減少數據的偏度。它可以應用于正偏態和負偏態數據。
2.平方根變換(Square root transformation):平方根變換可以用于減少數據的偏度。它可以應用于正偏態數據。
3.Box-Cox變換(Box-Cox transformation):Box-Cox變換是一種更通用的變換方法,可以處理正偏態和負偏態數據。它使用參數lambda來確定要應用于數據的變換類型。
以下是一些Python代碼演示這些變換技巧:
import numpy as np
import pandas as pd
from scipy import stats
# Generate some skewed data
data = np.random.gamma(1, 10, 1000)
# Calculate skewness and kurtosis
skewness = stats.skew(data)
kurtosis = stats.kurtosis(data)
print("Skewness:", skewness)
print("Kurtosis:", kurtosis)
# Log transformation
log_data = np.log(data)
log_skewness = stats.skew(log_data)
log_kurtosis = stats.kurtosis(log_data)
print("Log Skewness:", log_skewness)
print("Log Kurtosis:", log_kurtosis)
# Square root transformation
sqrt_data = np.sqrt(data)
sqrt_skewness = stats.skew(sqrt_data)
sqrt_kurtosis = stats.kurtosis(sqrt_data)
print("Sqrt Skewness:", sqrt_skewness)
print("Sqrt Kurtosis:", sqrt_kurtosis)
# Box-Cox transformation
box_cox_data, _ = stats.boxcox(data)
box_cox_skewness = stats.skew(box_cox_data)
box_cox_kurtosis = stats.kurtosis(box_cox_data)
print("Box-Cox Skewness:", box_cox_skewness)
print("Box-Cox Kurtosis:", box_cox_kurtosis)
處理峰度(kurtosis)的方法可以采用類似于處理偏度的變換方法。一些處理峰度的技巧包括:
1.對數變換:對數變換也可以用于處理數據中的峰度。
2.平方變換:平方變換也可以用于處理數據中的峰度。
3.Box-Cox變換:Box-Cox變換也可以用于處理數據中的峰度。
Fig.6 — Kurtosis
下面是一些 Python 代碼來演示這些轉換:
import numpy as np
import pandas as pd
from scipy import stats
# Generate some data with high kurtosis
data = np.random.normal(0, 5, 1000)**3
# Calculate skewness and kurtosis
skewness = stats.skew(data)
kurtosis = stats.kurtosis(data)
print("Skewness:", skewness)
print("Kurtosis:", kurtosis)
# Log transformation
log_data = np.log(data)
log_skewness = stats.skew(log_data)
log_kurtosis = stats.kurtosis(log_data
處理罕見類別
處理罕見類別是指處理在數據中出現不頻繁的分類變量的過程。罕見類別可能會對機器學習模型造成問題,因為它們可能在數據中沒有足夠的代表性來準確地建模。一些處理罕見類別的技巧包括:
1.合并罕見類別:這涉及將罕見類別合并為單個類別或少數類別。這會減少變量中的類別數量,并增加罕見類別的代表性。
2.用更常見的類別替換罕見類別:這涉及用變量中最常見的類別替換罕見類別。如果罕見類別對分析不重要,這種方法可以很有效。
3.使用標志進行獨熱編碼:這涉及為罕見類別創建一個新的類別,并將它們標記為罕見類別。這使得模型可以將罕見類別與其他類別區別對待。
以下是一個使用泰坦尼克號數據集處理罕見類別的示例:
import pandas as pd
import numpy as np
# load Titanic dataset
titanic = pd.read_csv('titanic.csv')
# view value counts of the 'Embarked' column
print(titanic['Embarked'].value_counts())
# group rare categories into a single category
titanic['Embarked'] = np.where(titanic['Embarked'].isin(['C', 'Q']), titanic['Embarked'], 'R')
# view value counts of the 'Embarked' column after grouping
print(titanic['Embarked'].value_counts())
# replace rare categories with the most common category
titanic['Embarked'] = np.where(titanic['Embarked'].isin(['C', 'Q']), titanic['Embarked'], 'S')
# view value counts of the 'Embarked' column after replacement
print(titanic['Embarked'].value_counts())
# create a new category for rare categories and flag them as rare
titanic['Embarked_R'] = np.where(titanic['Embarked'].isin(['C', 'Q']), 0, 1)
處理時間序列數據
處理時間序列數據涉及到多種技術,如數據預處理、特征提取和建模。讓我們看一些技術以及如何使用Python實現它們。
Fig.7 — Time Series Data
1.數據預處理:時間序列數據通常包含缺失值、離群值和噪聲數據,這些可能會影響模型的性能。因此,在訓練模型之前進行數據預處理是必要的。一些常見的數據預處理技術包括填充缺失值、處理離群值和縮放。
2.特征提取:特征提取涉及從時間序列數據中提取有用的信息,以用于建模。一些流行的特征提取技術包括滾動統計、傅立葉變換和小波變換。
3.建模:一旦數據經過預處理并提取特征,就可以用于建模。一些流行的時間序列模型包括ARIMA(自回歸綜合移動平均)、LSTM(長短期記憶)和Prophet。
# Import libraries
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from statsmodels.tsa.arima_model import ARIMA
from keras.models import Sequential
from keras.layers import LSTM, Dense
# Load time-series data
data = pd.read_csv('time_series_data.csv')
# Preprocess data
data.fillna(method='ffill', inplace=True)
data = data[(data['date'] > '2020-01-01') & (data['date'] < '2021-12-31')]
data.set_index('date', inplace=True)
scaler = StandardScaler()
data = scaler.fit_transform(data)
# Extract features
rolling_mean = data.rolling(window=7).mean()
fft = np.fft.fft(data)
wavelet = pywt.dwt(data, 'db1')
# Train ARIMA model
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit(disp=0)
predictions = model_fit.predict(start='2022-01-01', end='2022-12-31')
# Train LSTM model
X_train, y_train = [], []
for i in range(7, len(data)):
X_train.append(data[i-7:i, 0])
y_train.append(data[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
# Define the LSTM model
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], 1)))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=1))
# Compile the model
model.compile(optimizer='adam', loss='mean_squared_error')
# Fit the model to the training data
model.fit(X_train, y_train, epochs=100, batch_size=32)
**文本預處理 **
文本預處理是處理文本數據時特征工程的一個關鍵步驟。其目標是將原始文本轉換為可用于機器學習模型的數字表示。以下是Python中常用的一些文本預處理技術:
分詞:將句子或文檔分解為單個單詞或短語。NLTK庫提供了各種分詞器,例如單詞分詞器和句子分詞器。
from nltk.tokenize import word_tokenize, sent_tokenize
text = "This is a sample sentence. It contains some words."
words = word_tokenize(text)
sentences = sent_tokenize(text)
print(words)
# Output: ['This', 'is', 'a', 'sample', 'sentence', '.', 'It', 'contains', 'some', 'words', '.']
print(sentences)
# Output: ['This is a sample sentence.', 'It contains some words.']
2.停用詞去除:停用詞是一些常見的不添加任何文本含義的單詞,例如“a”、“the”、“and”等。去除停用詞可以提高文本處理的效率并減小數據的大小。NLTK庫為各種語言提供了一個停用詞列表。
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtered_words = [word for word in words if word.casefold() not in stop_words]
print(filtered_words)
# Output: ['sample', 'sentence', '.', 'contains', 'words', '.']
Fig.8 — Text Processing
3.詞干提取和詞形還原:詞干提取和詞形還原是將單詞縮減為其基本或根形式的技術。例如,“running”、“runner”和“runs”可以縮減為根詞“run”。NLTK庫提供了各種詞干提取器和詞形還原器。
from nltk.stem import PorterStemmer, WordNetLemmatizer
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
stemmed_words = [stemmer.stem(word) for word in filtered_words]
lemmatized_words = [lemmatizer.lemmatize(word) for word in filtered_words]
print(stemmed_words)
# Output: ['sampl', 'sentenc', '.', 'contain', 'word', '.']
print(lemmatized_words)
# Output: ['sample', 'sentence', '.', 'contains', 'word', '.']
4.文本規范化:文本規范化涉及將文本轉換為標準化形式,例如將所有文本轉換為小寫,去除標點符號,并用它們的全稱替換縮寫和縮略語。
import re
def normalize_text(text):
text = text.lower()
text = re.sub(r'[^\\w\\s]', '', text)
text = re.sub(r'\\b(can\\'t|won\\'t|shouldn\\'t)\\b', 'not', text)
text = re.sub(r'\\b(i\\'m|you\\'re|he\\'s|she\\'s|it\\'s|we\\'re|they\\'re)\\b', 'be', text)
return text
text = "I can't believe it's not butter!"
normalized_text = normalize_text(text)
print(normalized_text)
# Output: 'i not believe be not butter'
總結
總之,特征工程是機器學習過程中的關鍵步驟,涉及將原始數據轉換為機器學習算法可以有效使用的格式。在本篇博客文章中,我們介紹了各種特征工程技術,包括特征選擇和提取、編碼分類變量、縮放和歸一化、創建新特征、處理不平衡數據、處理偏斜和峰度、處理稀有類別、處理時間序列數據、特征轉換和文本預處理。
以下是本文的主要要點:
1.特征選擇和提取可以使用統計方法,如PCA、LDA和相關性分析,以及機器學習方法,如基于樹的方法、包裝方法和嵌入式方法。
2.編碼分類變量可以使用諸如獨熱編碼、標簽編碼和計數編碼等技術。
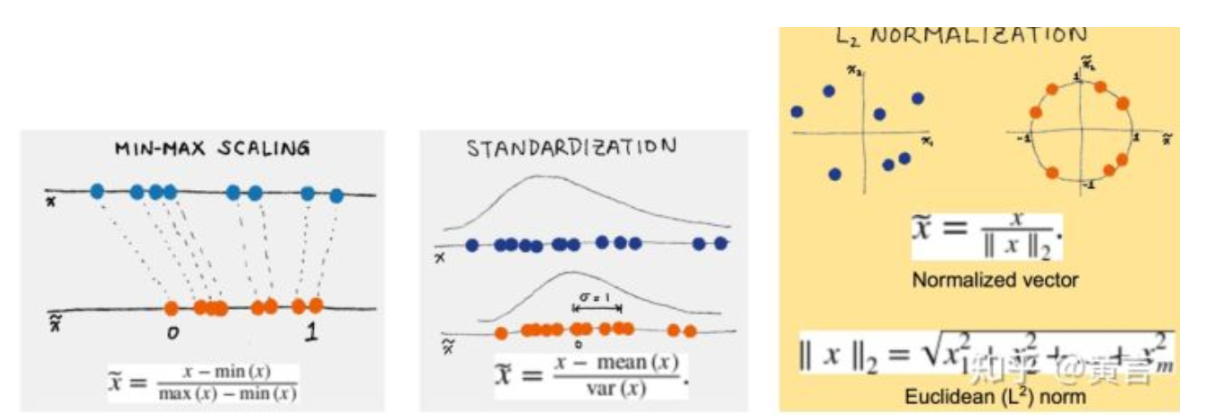
3.縮放和歸一化可以使用諸如最小-最大縮放、標準縮放和魯棒縮放等技術。
4.文本預處理涉及技術,如分詞、停用詞去除、詞干提取和詞形還原。
-
編碼
+關注
關注
6文章
942瀏覽量
54831 -
機器學習
+關注
關注
66文章
8418瀏覽量
132646 -
預處理
+關注
關注
0文章
33瀏覽量
10485
發布評論請先 登錄
相關推薦
機器學習算法的特征工程與意義詳解

有感FOC算法學習與實現總結
SVPWM的原理與算法學習課件免費下載








 工商網監
工商網監
評論