 DPU 究竟有什么作用呢?
DPU 究竟有什么作用呢?
這場革命始于SmartNIC,而DPU則是它的2.0版本。
“隨著DPU 越來越多地出現在大眾視野中,期待未來可以看到加密/解密、防火墻、數據包檢查、路由、存儲網絡等功能由 DPU 處理,”Turner 預測。
SmartNIC——初代DPU
GPU的蓬勃發展源于x86 系列處理器的局限性,x86 處理器更適合處理通用型任務,但對于特定工作來說它們要比專用芯片慢得多。GPU最開始被用在游戲機中,后來被發現還很適合用于AI系統。
與 GPU 一樣,SmartNIC最開始只是被用來從 CPU 中卸載一些網絡功能,實現網絡加速。現在已經被開發出了很多新的使用場景。
但 SmartNIC 并不是一個統一的、一刀切的類別。Delloro Group 的分析師 Baron Fung 解釋說,隨著網絡變得更快,SmartNIC 需要承載更多的用戶流量。網絡供應商創建了一種使用專門的 ASIC 來卸載網絡功能的“性能”網卡。但SmartNIC 有所不同。
SmartNIC 在性能網卡上又增加了另一層性能。SmartNIC 是完全可編程設備,具有自己的處理器、操作系統、集成內存和網絡結構。它就像服務器中的服務器,從主機 CPU 提供不同范圍的卸載服務。
目前大多數智能設備都是AWS、微軟、阿里等云廠商專有的,他們在自己的數據中心構建自己的 SmartNIC,但隨著越來越多創新產品和軟件開發框架的發布,其他市場也逐漸開始采用SmartNIC 。
有預測顯示,SmartNIC 在未來幾年將以每年 3% 的速度增長,但在整個市場來看仍只是占據一小部分,因為SmartNIC 價格昂貴,目前SmartNIC 的價格是標準網卡的三到五倍。這就需要證明高成本的合理性。
在一般網絡應用中,SmartNIC 可以提高網絡效率,同時因為智能設備可以通過軟件進行優化,采用SmartNIC 還能夠延長基礎設施的使用壽命,這實現了一種相對平衡。
隨著SmartNIC 的發展,市場上又出現了它的進階版——DPU。不同的廠商給它定義了不同的名稱和功能,比如英特爾的叫IPU,阿里云的叫CIPU。
DPU的到來
DPU一詞最早由Juniper創始人Pradeep Sindhu創建的硅谷創業公司Fungible提出。
“你可以使用通用 x86 定義一個非常簡單的服務器來進行通用處理,然后放入一個 DPU 來為你完成所有其余的存儲工作”,Fungible 首席執行官 Eric Hayes表示。
數據無處不在,每個人都在收集和存儲數據。真正的問題在于如何處理所有這些數據?
CPU 和 GPU 的設計初衷并不是為了完成移動和處理數據的任務,所以它們處理這類任務的效率非常低。
Hayes 認為 SmartNIC 與DPU 之間存在明顯的區別:“DPU 是為數據處理而設計的,它的出現就是為了處理 x86 和 GPU 無法高效處理的數據。”
根據 Hayes 的說法,早期的 SmartNIC “只是 Arm 或 x86 CPU、FPGA 和硬連線、可配置管道的不同組合。他們只能用有限的性能來換取靈活性。”
相比之下,DPU 架構實現了靈活性和性能兼具。
那么DPU 究竟有什么作用呢?
加速網絡
首先是加速網絡。DPU 能夠讓網絡處理速度更快。由于軟件定義網絡 (SDN) 的出現,網絡越來越多地以軟件形式實現。SDN網絡通過在軟件中處理它們的功能使系統更加靈活,但是該軟件在通用處理器上運行時效率極低。
SmartNIC 采取了一些措施來改進 SDN 功能,但還沒有達到 DPU 的性能水平。除了SDN,DPU還將在更智能的網絡生態系統中發揮重要作用,例如5G OpenRAN。
重寫存儲
DPU可以為以數據為中心的時代重建存儲,通過創建TCP/IP上運行的內存訪問協議,并將其卸載,從而創建“內聯計算存儲”。
NVMe(non-volatile memory express) 是一種用于訪問閃存的接口,通常由 PCI express 總線連接。通過 TCP/IP 運行 NVMe,并將整個堆棧放在 DPU 上,將整個內存訪問從CPU上卸載,這意味著閃存不再需要直接連接到CPU。
通過 TCP 執行 NVMe 的目的是能夠從服務器中取出所有閃存,可以使用通用 x86 定義一個非常簡單的服務器來進行通用處理,然后放入一個 DPU 來完成所有其余的存儲工作。
就 CPU 而言,DPU 看起來像一個存儲設備,卸載了通常必須在通用處理器上運行的所有驅動程序。
加速 GPU
一個基本的 x86 處理器可以管理很多 GPU,但這其中也存在一個瓶頸,因為數據必須從 GPU、PCI 接口傳輸到 CPU。
將通信任務交給 DPU 可以減少對 GPU-PCI 接口的依賴。在多用戶環境中,這比將一組GPU專用于特定的x86處理器更高效,價格也便宜得多。
DPU 的最后一個作用是安全性。DPU有加速加密和解密的能力。
DPU需要標準化嗎?
目前DPU的采用尚處于起步階段,每個DPU廠商都有自己的解決方案,標準化想要推進十分困難。
但如果DPU 要覆蓋更多客戶,就必須出現一個更加標準化的生態系統。
預計約有三分之一的 DPU 市場將集中在較小的提供商和私有數據中心中,這些小公司沒有像云巨頭廠商那樣有大量的工程師,標準化有助于降低邊際成本,創造規模效益,實現創新技術的價值變現。
Hello DPU,Goodbye CPU!
很多人都談到了DPU的優勢之一是降本增效,但是實際上并沒有能夠拿出有效的數據佐證這一觀點。近日,英偉達使用其 BlueField-2 E 系列 DPU進行了一些測試,該 DPU 具有一對 100 Gb/sec 端口,并采用同樣具有一對 100 Gb/sec 端口的常規 SmartNIC 作為對照組。
英偉達存儲營銷總監John Kim展示了將服務器上運行的hypervisor的Open vSwitch (OVS)卸載到BlueField-2 DPU的效果,以及將愛立信的用戶平面功能(UPF)工作負載從5G基站中的服務器CPU卸載到機箱中運行的DPU的效果。在每一個案例中,英偉達都計算了在10,000臺機器的集群中為這些負載卸載添加DPU的效果,并且只計算了在加州電價下節省的電力。在這兩種情況下,英偉達計算服務器上有多少個內核在運行這兩種工作負載,消耗了多少瓦,然后在DPU上運行它需要多少瓦,然后計算在三年內節省的電力和成本。
以下是 OVS 卸載的性能提升和節能數據:
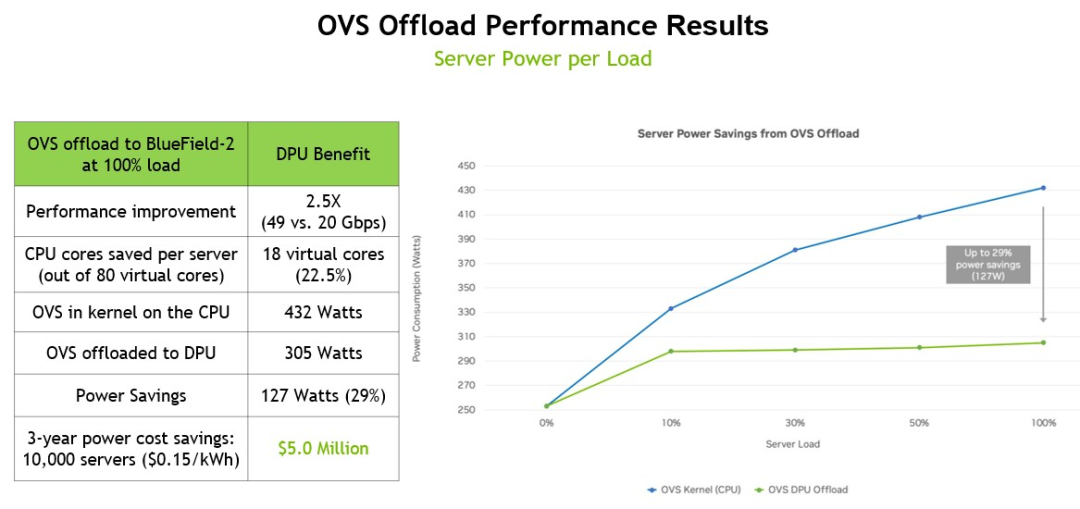
這個基準測試是在一臺戴爾PowerEdge R740服務器上運行的,該服務器使用一對英特爾“Cascade Lake”至強SP-6248 Gold處理器,每個處理器有20個內核,運行在2.5 GHz,一個BlueField-2 DPU帶有一對25 Gb/秒以太網端口。在服務器上運行OVS需要18個線程和9個內核(總共80個線程和40個內核),這占計算機固有計算能力的22.5%,也就是說理論上整個服務器150瓦CPU功率和實際432瓦CPU功率相同。通過將OVS工作負載轉移到DPU, OVS在運行時只消耗305瓦,如果將節省的電能分散到10,000個節點上,那么三年節省的成本將達到500萬美元。
重要的是,OVS 交換機的吞吐量從 20 Gb/秒提升到 49 Gb/秒,接近 DPU 上兩個端口的峰值理論性能。
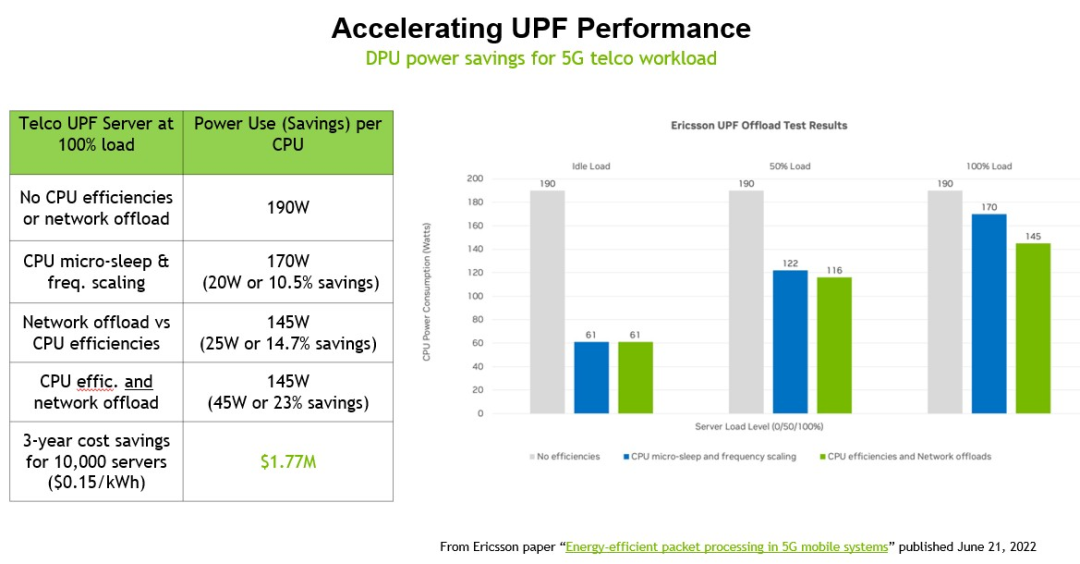
DPU 最關鍵的作用是在運行應用程序的服務器之間以及從服務器到訪問應用程序和數據的客戶端設備之間傳輸數據時對數據進行加密,因此英偉達創建了一個IPSec加密場景,用于加密應用程序的服務器端和客戶端,以及將節省多少電力。

這組測試在配備一對英特爾“Ice Lake”至強 SP-830 處理器的服務器上運行,該處理器具有 40 個內核,每個內核以 2.3 GHzm 運行,帶有一個 BlueField-2 卡,具有一對 100 GB/秒的以太網端口和 16 GB自帶內存。在此設置中,服務器端 IPSec 加密和解密消耗 6 個物理內核(占內核的 7.5%),而客戶端需要 20 個內核(占 25%)。拋開CPU 和運行 IPSec 的 DPU 之間是否存在性能差異,這個測試計算了將負載卸載到 DPU 所節省的電力,三年內通過 10,000 個節點可以節省 1420 萬美元.

從這個比較中可以看出,為 10,000 個節點的每一個節點添加 BlueField-2 DPU 可以減少支持 IPSec 加密和解密工作負載所需的節點數量。根據英偉達的計算,服務器硬件的資本支出實際上降低了 2.4%,總體成本節省了 15%(這還沒有考慮到性能差異、數據中心面積的節省以及管理的服務器的減少)。
就目前而言,為CPU減負是必然的。可以肯定地說,在未來的系統架構中,網絡、存儲訪問、虛擬化工作負載和安全功能不會在 CPU 上完成。
DPU 將成為系統架構的中心,分配對計算和存儲的訪問權限,而CPU 則應該被稱為具有龐大內存的串行處理單元。
-
DPU
+關注
關注
0文章
364瀏覽量
24205 -
網絡處理
+關注
關注
0文章
5瀏覽量
6365 -
sdn
+關注
關注
3文章
254瀏覽量
44801
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論