 SAM-Adapter:首次讓SAM在下游任務適應調優!
SAM-Adapter:首次讓SAM在下游任務適應調優!
近日,由魔芯科技、浙江大學、湖州師范學院、新加坡科技設計大學(SUTD)、北京航空航天大學等多單位聯合發表學術論文,發現了SAM這一通用大模型在部分下游任務上的性能表現不佳,并首次提出了將任務特定知識和大模型SAM學到的通用知識和在下游任務中結合,進行適應調優(而非重新訓練)的方法。研究提出了一個輕量的adapter框架將這些任務相關的知識輸入進SAM中,以實現SAM在下游任務的針對性應用。該論文的代碼已經在GitHub上開源。

主頁:https://tianrun-chen.github.io/SAM-Adaptor/ 代碼(已開源):https://github.com/tianrun-chen/SAM-Adaptor-PyTorch 論文:https://arxiv.org/abs/2304.09148
這項研究成果開辟了利用大型預訓練圖像模型在不同領域和工業應用中進行各種下游分割任務研究的新時代。它為研究人員和從業者提供了有價值的見解,展示了如何利用內部知識和外部控制信號來適應預訓練模型,以在具有挑戰性的任務中實現最先進的性能。該研究成果還為醫學圖像處理、自然科學、農牧業、遙感等領域的應用提供了新思路。
人工智能研究已經見證了一個由大規模海量數據上訓練的模型所帶來的范式上的轉變。這些模型,或稱為基礎模型,如BERT、DALL-E和GPT-3,已經在許多語言或視覺任務中顯示出有優秀的結果。
在這些基礎模型中,Segment Anything Model(SAM)作為一個在大型視覺語料庫上訓練的通用圖像分割模型取得了顯著的突破。事實證明,SAM在不同的場景下具有成功的分割能力,這使得它在圖像分割和計算機視覺的相關領域邁出了突破性的一步。
然而,由于計算機視覺包含了廣泛的問題,SAM的不完整性是顯而易見的,這與其他基礎模型類似,因為訓練數據不能包含整個語料庫,工作場景也會有變化。在本研究中,作者首先在一些具有挑戰性的低層次結構分割任務中測試SAM,包括偽裝物體檢測(隱蔽場景)和陰影檢測,作者發現在一般圖像上訓練的SAM模型在這些情況下不能完美地 "分割任何東西",包括影子檢測、偽裝物體檢測等。
因此,一個關鍵的研究問題是:如何高效利用大型模型從大規模語料庫中獲得的能力,并利用它們使下游的任務受益?
在這項工作中,來自魔芯科技、浙江大學、新加坡科技設計大學等單位的研究者提出了SAM-adapter,它是一個針對上述研究問題的優秀解決方案。這項開創性的工作首次嘗試將大型預訓練的圖像分割一切模型SAM適應于特定的下游任務,并提高其性能。正如其名,SAM-adapter是一種非常簡單而有效的適應技術,可以同時利用來自大模型的內部知識和針對下游任務設定的外部控制信號。在該方法中,信息是通過視覺提示傳達給網絡的,這已被證明了在用最少的額外可訓練參數,能高效地將一個凍結的大基礎模型適應到許多下游任務工作。

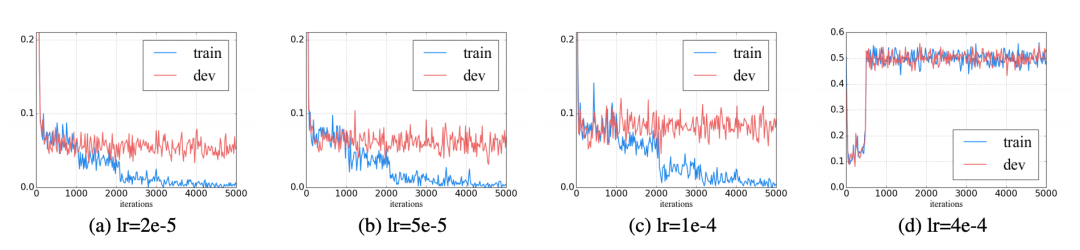
圖:SAM-Adapter (Ours) 在偽裝物體檢測上的性能測試
這項工作率先證明了大規模海量數據訓練給SAM帶來的特殊能力可以被應用到其他數據領域。SAM-Adapter可以被用作這樣的遷移。作者在影子檢測、偽裝物體檢測等任務的數據上實現了超過已有算法的高性能(SOTA)表現。未來,我們相信SAM-Adapter作為一個通用框架,可以被應用于更多不同領域的各種下游分割任務中,包括在醫學影像診斷、農業、工業檢測等不同領域。
審核編輯 :李倩
-
人工智能
+關注
關注
1791文章
47279瀏覽量
238513 -
SAM
+關注
關注
0文章
112瀏覽量
33524
原文標題:SAM無法分割一切?SAM-Adapter:首次讓SAM在下游任務適應調優!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于PSAM卡和SAM卡作用
【AT91SAM9261申請】基于AT91SAM9261評估套件的物聯網系統
基于AT91SAM9G35 SAM9G35 MCU ARM9系列的評估套件AT91SAM9G35-EK
基于AT91SAM9G25 SAM9G25 MCU ARM9系列的評估板AT91SAM9G25-EK
法國DREAM方案SAM5504B/SAM5704B音源芯片
Atmel SAM V71開發板用戶指南
如何讓Bert模型在下游任務中提高性能?
從SAM9x5移植到SAM9X60
針對SAM L10 /SAM L11的UART自舉程序

SAM卡讀寫芯片
SAM 到底是什么


一種新的分割模型Stable-SAM






 工商網監
工商網監
評論