

概覽
市面上的標題黨往往會采用夸張的文字,例如:ChatGPT被淘汰,AutoGPT來襲。但是對于行業(yè)內(nèi)的人來說,這種標題很明顯是標題黨。這兩個模型都是基于GPT-3或者GPT-4的技術(shù),它們在技術(shù)上本質(zhì)上沒有太大的區(qū)別。
雖然GPT模型在自然語言處理領(lǐng)域中表現(xiàn)出色,但是它們?nèi)匀淮嬖谝恍﹩栴}。例如,GPT模型的自回歸設(shè)計導(dǎo)致它在生成新單詞或短語時需要等待整個序列生成完成,這樣的過程顯然會減緩生成速度。
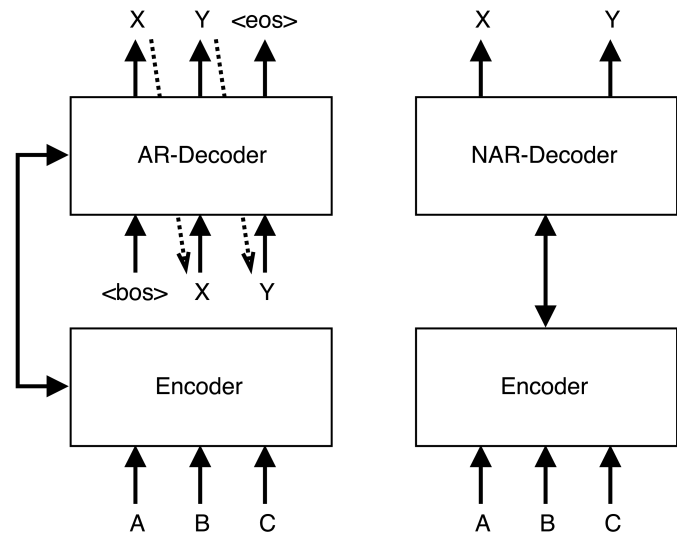
由于這些問題,一些研究人員開始探索非自回歸模型的設(shè)計,這種方法可以提高生成速度。
但非自回歸模型的輸出結(jié)果可能會出現(xiàn)不連貫的情況,這種情況需要更多的研究和解決方案。
總之,非自回歸模型是一種很有前途的技術(shù),可以成為未來顛覆GPT的重要技術(shù)之一。雖然這些方法仍然需要更多的研究和開發(fā),但是應(yīng)該持續(xù)關(guān)注它們的發(fā)展。
三種文本生成方式
自回歸(AR)
生成模型基于從左到右的輸出文本,其中每個標記yt是基于輸入文本X和前面的標記y
非自回歸(NAR)
與AR模型相比,文本生成模型同時預(yù)測輸出文本中的每個標記,而不對前向或后向標記依賴進行建模。其中每個標記yt僅根據(jù)輸入文本X進行預(yù)測。獨立性假設(shè)使NAR生成過程可并行化,從而顯著加快了推理速度。然而,在沒有token依賴的情況下,NAR模型的生成質(zhì)量低于AR模型。
半自回歸(Semi-NAR)
半NAR生成在AR和NAR生成之間形式化,其中每個標記yt以輸入文本X和輸出文本Y的可見部分Yct為條件。
本文主要關(guān)注NAR方法,并同時考慮文本生成模型的有效性和效率。
一種非自回歸的預(yù)訓(xùn)練方法
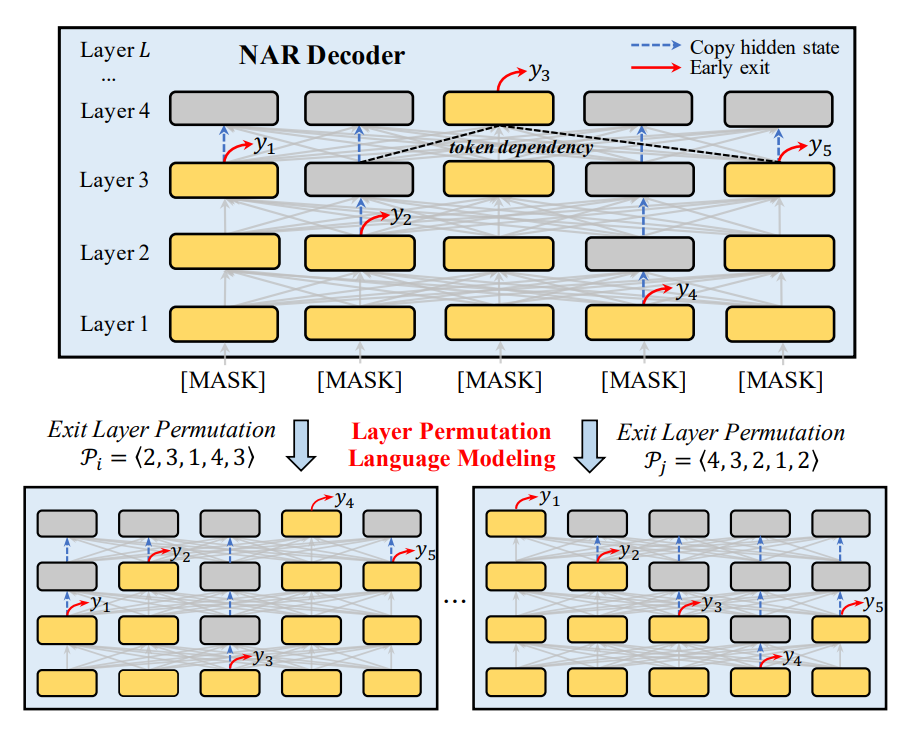
本文介紹的方法ELMER是基于Transformer編碼器-解碼器架構(gòu)構(gòu)建的。解碼器和編碼器都由多個堆疊組成,每個層包含多個子層(例如,多頭自注意力和前饋網(wǎng)絡(luò))。與原始Transformer解碼器自回歸生成文本不同,模型使用NAR方式同時生成標記。給定一對輸入-輸出文本〈X,Y〉,X被饋送到編碼器中并被處理為隱藏狀態(tài)S = 〈s1,...,sn〉。然后將一系列“[MASK]”標記序列饋送到NAR解碼器中以并行生成輸出文本Y中的每個標記。
提前退出機制
通常情況下,大多數(shù)NAR模型只在最后一層同時預(yù)測token,因此,token預(yù)測不知道其他位置生成的token。為了解決這個問題,ELMER在不同層生成token。上層token的生成可以依賴于從左側(cè)和右側(cè)生成的下層token。通過這種方式,模型可以明確地學(xué)習(xí)來自不同層標記之間的依賴關(guān)系,并且在NAR解碼中享受完全的并行性,如上圖所示。如果在較低層生成token時有足夠的置信度,則允許模型在該層退出并進行預(yù)測,而不經(jīng)過上層。
層排列預(yù)訓(xùn)練
與大多數(shù)先前工作專注于為特定任務(wù)(如翻譯)設(shè)計小規(guī)模NAR模型不同,ELMER使用大規(guī)模語料庫對通用大規(guī)模PLM進行預(yù)訓(xùn)練。這使得ELMER能夠適應(yīng)各種下游任務(wù)。
首先將損壞的文本輸入編碼器,然后使用上述LPLM以NAR方式由解碼器重建原始文本來訓(xùn)練模型。主要采用兩種有用的文檔損壞方法:
洗牌:首先將原文按照句號分成句子,然后對這些句子進行隨機洗牌。
文本填充:基于打亂的文本,從泊松分布(λ = 3)中抽取長度的15%跨度進行采樣。在BART之后,每個span都被替換為單個“[MASK]” token,模型可以學(xué)習(xí)應(yīng)該預(yù)測一個span中的多少個token。
下游微調(diào)
預(yù)訓(xùn)練模型可用于微調(diào)各種下游文本生成任務(wù)。在微調(diào)階段,可以使用小規(guī)模和特定任務(wù)的數(shù)據(jù)集,精確估計每個token的輸出層。在這里主要考慮兩種提前停止方式,即硬提前停止和軟提前停止。
硬提前退出是最直接的方法,它通過計算每個標記的預(yù)測置信度,并設(shè)置一個閾值來決定是否提前退出。如果某個標記的預(yù)測置信度低于閾值,則不會進行提前退出。
軟提前退出則是一種更加靈活的方法,它允許模型在生成文本時動態(tài)地調(diào)整每個標記的預(yù)測置信度閾值。具體來說,在軟提前退出中,模型會根據(jù)當前已經(jīng)生成的文本內(nèi)容和上下文信息來動態(tài)地調(diào)整每個標記的預(yù)測置信度閾值。這種方法可以使得模型更加靈活地適應(yīng)不同的文本生成任務(wù),并且可以在不同任務(wù)之間共享已經(jīng)學(xué)習(xí)到的知識。
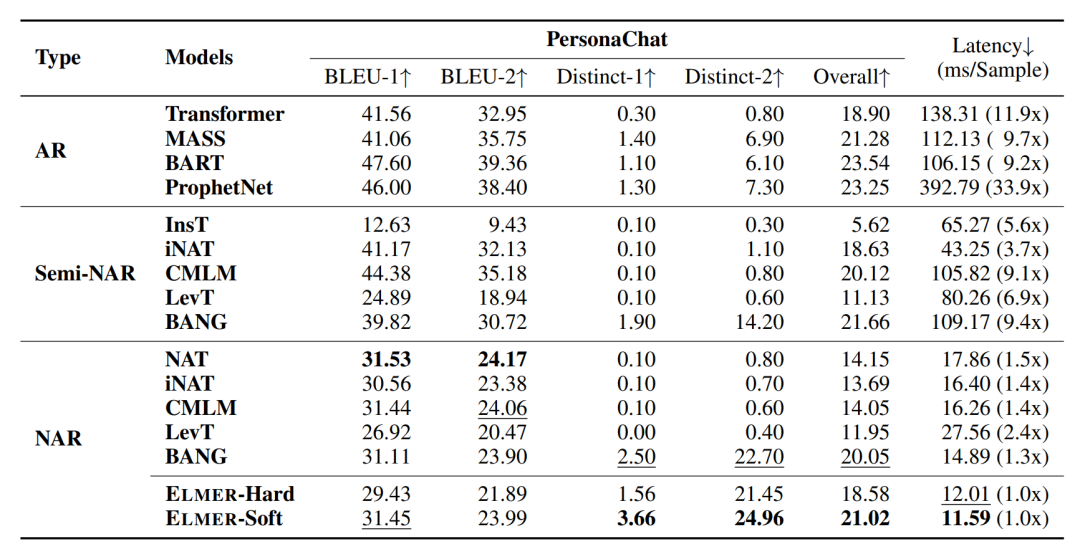
比較
雖然效果上還完全比不上自回歸,但一旦這個方向成熟,從效率上會徹底顛覆現(xiàn)在的GPT系列模型。
引用
https://arxiv.org/pdf/2210.13304.pdf
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3462瀏覽量
49789 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15856
原文標題:引用
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
一種新的記憶多項式預(yù)失真器
優(yōu)化神經(jīng)網(wǎng)絡(luò)訓(xùn)練方法有哪些?
介紹XLNet的原理及其與BERT的不同點
研究人員提出一種基于哈希的二值網(wǎng)絡(luò)訓(xùn)練方法 比當前方法的精度提高了3%
微軟在ICML 2019上提出了一個全新的通用預(yù)訓(xùn)練方法MASS

新的預(yù)訓(xùn)練方法——MASS!MASS預(yù)訓(xùn)練幾大優(yōu)勢!

檢索增強型語言表征模型預(yù)訓(xùn)練
一種側(cè)重于學(xué)習(xí)情感特征的預(yù)訓(xùn)練方法

ELMER: 高效強大的非自回歸預(yù)訓(xùn)練文本生成模型
基礎(chǔ)模型自監(jiān)督預(yù)訓(xùn)練的數(shù)據(jù)之謎:大量數(shù)據(jù)究竟是福還是禍?

基于生成模型的預(yù)訓(xùn)練方法

混合專家模型 (MoE)核心組件和訓(xùn)練方法介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論