 基于神經匹配的二維地圖視覺定位
基于神經匹配的二維地圖視覺定位
主要內容:
提出了一種基于人類使用的2D語義圖以亞米精度定位圖像的算法,OrienterNet,通過將BEV圖與OpenStreetMap中開放可用的全局地圖相匹配來估計查詢圖像的位置和方向,使任何人都能夠在任何可用地圖的地方進行定位。 OrienterNet只受相機姿態的監督,學習以端到端的方式與各種地圖元素進行語義匹配。引入了一個大規模的眾包圖像數據集,該數據集以汽車、自行車和行人的不同角度在12個城市進行拍攝得到。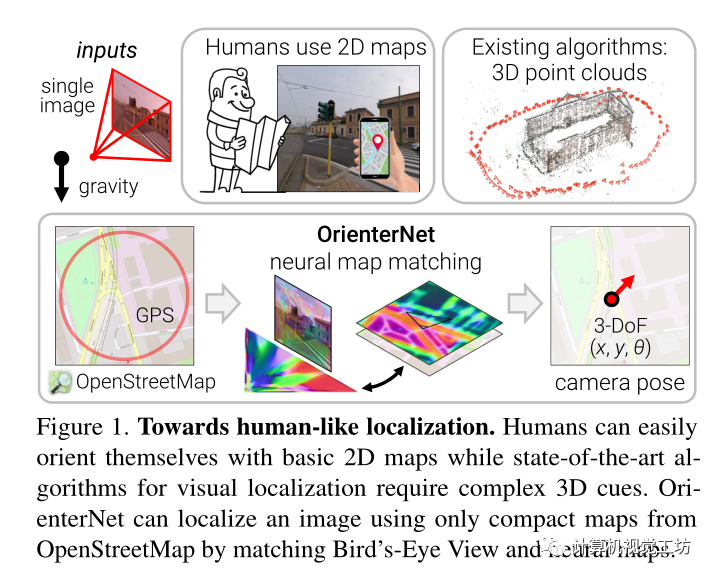
Motivation:
作為人類,我們直觀地理解我們所看到的局部場景和我們所處場景的全局地圖之間的關系。當我們迷失在未知區域時,我們可以通過使用不同的地理特征仔細比較地圖和周圍環境來準確定位我們的位置。
傳統的視覺定位算法通常很復雜,其依賴于圖像匹配,并且需要冗余的3D點云和視覺描述子,而且使用激光雷達或攝影測量構建3D地圖是昂貴的,并且需要更新數據來捕捉視覺外觀的變化,3D地圖的存儲成本也很高,因為它們比基本的2D地圖大幾個數量級。這些限制了其在移動設備上執行定位,現在的方法一般需要昂貴的云基礎設施。
這就引出了一個重要的問題:我們如何像人類一樣教機器從基本的2D地圖進行定位? 本文就根據這個問題提出了第一種方法,該方法可以在給定人類使用的相同地圖的情況下,以亞米精度定位單個圖像和圖像序列。
這些平面圖只對少數重要物體的位置和粗略的二維形狀進行編碼,而不對其外觀和高度進行編碼。這樣的地圖非常緊湊,尺寸比3D地圖小104倍,因此可以存儲在移動設備上,并用于大區域內的設備上定位。該解決方案也不需要隨著時間的推移構建和維護昂貴的3D地圖,也不需要收集潛在的敏感地圖數據。
其算法估計2D地圖中圖像的3-DoF姿態,位置和航向。
該估計是概率性的,因此可以在多相機設備或圖像序列的多個視圖之前或跨多個視圖與不準確的GPS融合。所得到的解決方案比消費級GPS傳感器準確得多,并且基于特征匹配達到了接近傳統算法的精度水平。
使用的2D地圖與傳統地圖的區別: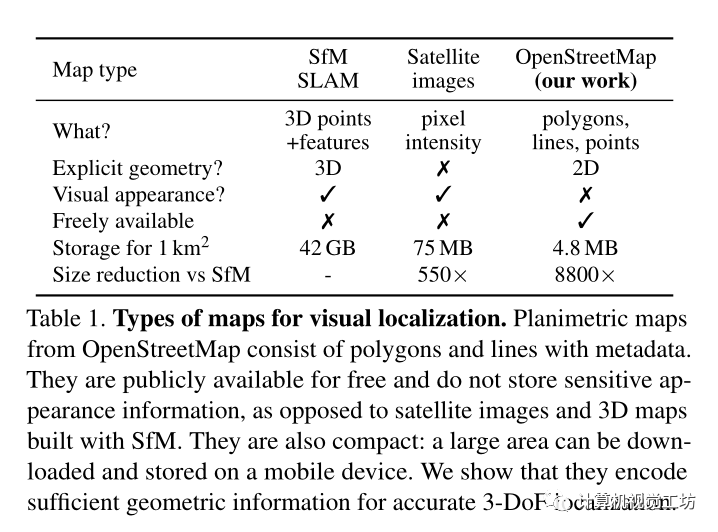
Pipeline: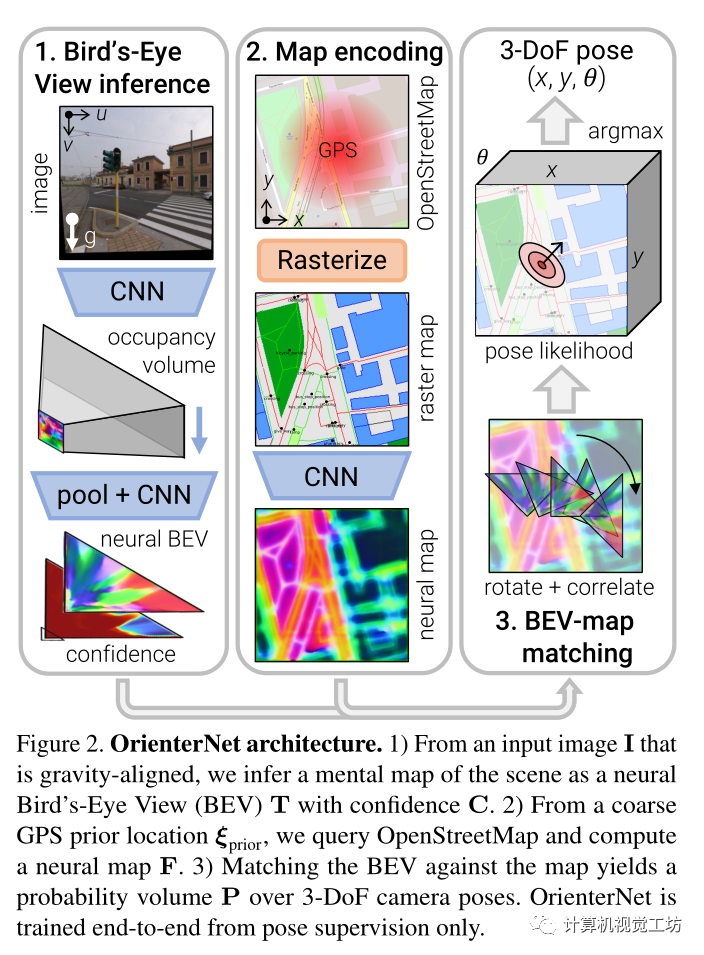
輸入:
輸入為具有已知相機內參的圖像I。通過根據已知重力計算的單應性對圖像進行校正,使其roll和tilt為零,然后其主軸為水平。還有一個粗略的位置先驗ξ。從OpenStreetMap查詢地圖數據,將其作為以ξ先驗為中心的正方形區域,其大小取決于先驗的噪聲程度。數據由多邊形、線和點的集合組成,每個多邊形、線或點都屬于給定的語義類,其坐標在同一局部參考系中給定。
OrienterNet由三個模塊組成:
1)圖像CNN從圖像中提取語義特征,并通過推斷場景的3D結構將其提升為鳥瞰圖(BEV)表示
2) OSM map由map-CNN編碼為嵌入語義和幾何信息的神經map F。
3) 通過將BEV與地圖進行窮舉匹配來估計相機姿態ξ上的概率分布
論文技術點:
鳥瞰圖BEV推理:
從一個圖像I中推斷一個BEV表示 ,其分布在與相機截頭體對齊的L×D的網格上,由N維特征組成,網格上每個特征都被賦予了一個置信度,有矩陣
,其分布在與相機截頭體對齊的L×D的網格上,由N維特征組成,網格上每個特征都被賦予了一個置信度,有矩陣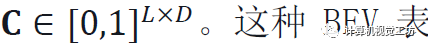 。
。
這種BEV表示類似于人類在地圖中自我定位時從環境中推斷出的心理地圖。
圖像和地圖之間的跨模態匹配需要從視覺線索中提取語義信息,算法依靠單目推理將語義特征提升到BEV空間,分兩步來獲得神經BEV:
i)通過將圖像列映射到極射線來將圖像特征轉移到極坐標表示
ii)將極坐標網格重新采樣為笛卡爾網格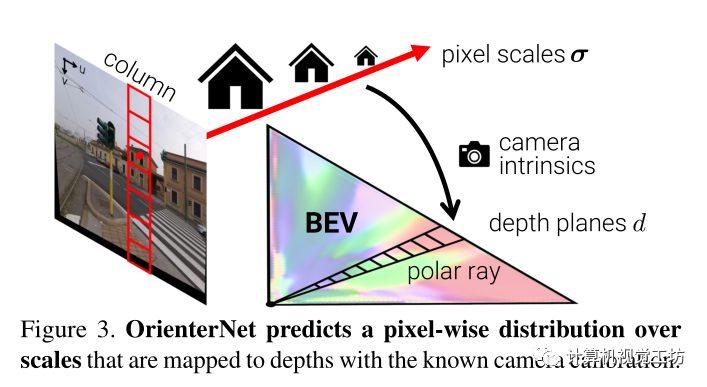
神經map編碼:
將平面圖編碼為結合了幾何和語義的W×H神經圖 ?
?
Map data:OpenStreetMap元素根據其語義類定義為多邊形區域、多段線或單點。區域的例子包括建筑足跡、草地、停車場;線條包括道路或人行道中心線、建筑輪廓;點包括樹木、公交車站、商店等。這些元素提供了定位所需的幾何約束,而它們豐富的語義多樣性有助于消除不同姿勢的歧義。
預處理:首先將區域、線和點光柵化為具有固定地面采樣距離
▲(例如50cm/pixel)的3通道圖像。
編碼:將每個類與學習的N維嵌入相關聯,生成W×H×3N的特征圖。然后通過一個CNN 將其編碼到神經圖F中,其提取有助于定位的幾何特征。F不是歸一化的,因為我們讓Φ映射將其范數調制為匹配中的重要權重。F通常看起來像一個距離場,在那里我們可以清楚地識別建筑物的角落或相鄰邊界等獨特特征。
基于模板匹配的姿態估計:
概率體:
估計一個相機姿態ξ上的離散概率分布。這是可解釋的,并充分反映了估計的不確定性。因此在不明確的情況下,分布是多模式的。圖4顯示了各種示例。這樣就可以很容易地將姿態估計與GPS等附加傳感器相融合。計算這個體積是容易處理的,因為姿勢空間已經減少到三維。它被離散化為每個地圖位置和以規則間隔采樣的K個旋轉。 這產生了W×H×K概率體積P,使得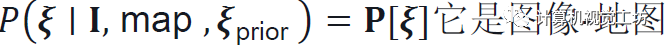
它是圖像-地圖匹配項M和位置先驗的組合?:
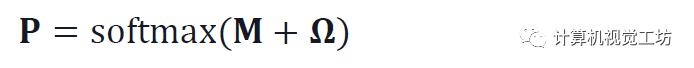
圖像-地圖匹配:
將神經map F和BEV T進行窮舉匹配,得到分數體M。通過將F與由相應姿勢變換的T相關來計算每個元素,如:
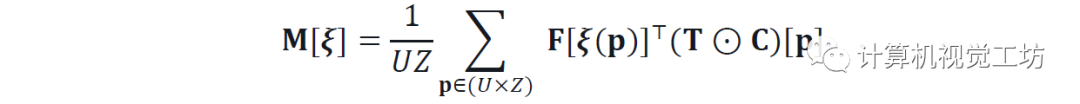
其中ξ(p)將2D點p從BEV變換為地圖坐標系。置信度C掩蓋相關性以忽略BEV空間的一些部分,例如被遮擋的區域。該公式得益于通過旋轉T K次并在傅立葉域中執行作為分批乘法的單個卷積的有效實現。
姿態推斷: 通過最大似然估計單個姿態: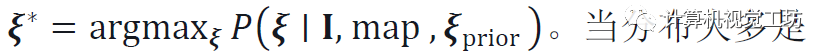 。當分布大多是單峰分布時,可以獲得一個不確定性度量,作為P在ξ*周圍的協方差。
。當分布大多是單峰分布時,可以獲得一個不確定性度量,作為P在ξ*周圍的協方差。
序列和多相機定位:
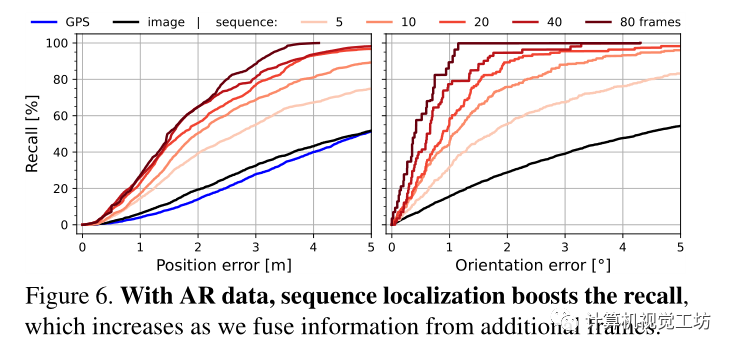
單圖像定位在幾乎沒有表現出獨特語義元素或重復模式的位置是模糊的。當多個視圖的相對姿勢已知時,可以通過在多個視圖上積累額外的線索來消除這種挑戰。這些視圖可以是來自VI SLAM的具有姿勢的圖像序列,也可以是來自校準的多攝像機設備的同時視圖。圖5顯示了這樣一個困難場景的例子,通過隨著時間的推移累積預測來消除歧義。不同的幀在不同的方向上約束姿勢,例如在交叉點之前和之后。融合較長的序列會產生更高的精度(圖6)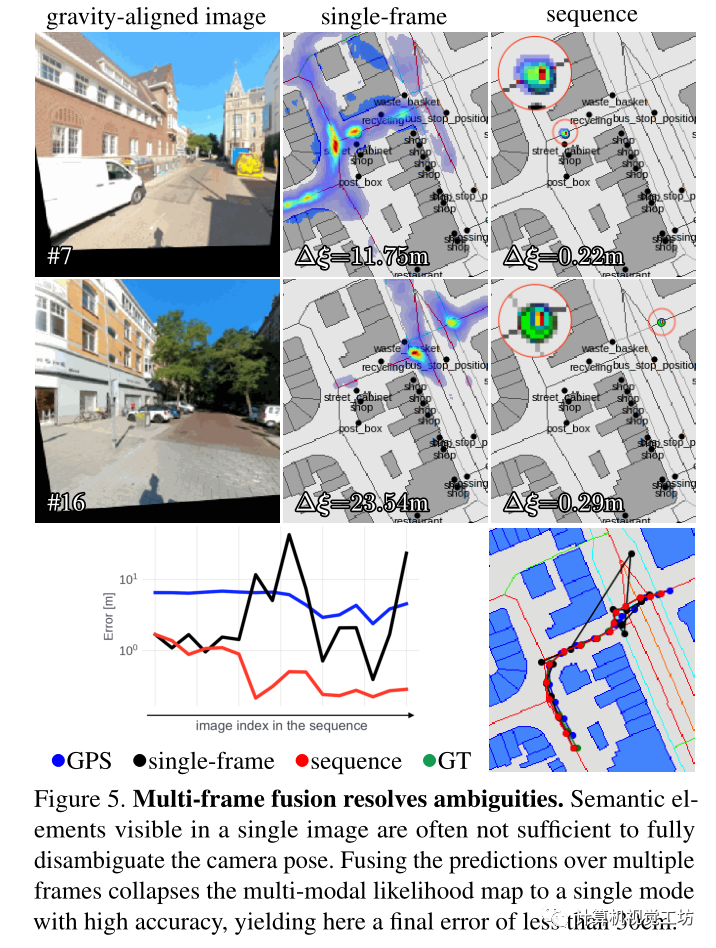
將ξi表示為視圖i的未知絕對姿態,將ξij表示為視圖j到i的已知相對姿態。對于任意參考視圖i,將所有單視圖預測的聯合似然表示為:
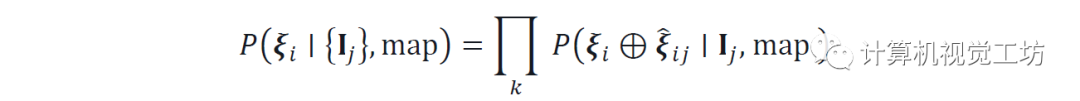
其中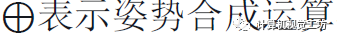
表示姿勢合成運算符。這是通過將每個概率體積Pj扭曲到參考幀i來有效計算的。也可以通過迭代扭曲和歸一化來定位連續流的每個圖像,就像經典的馬爾可夫定位一樣。
實驗:
在駕駛和AR的背景下評估了定位模型。圖4顯示了定性示例,而圖5說明了多幀融合的有效性。
實驗表明:
1)OrienterNet在2D地圖定位方面比現有的深度網絡更有效;
2) 平面圖比衛星圖像更準確地定位;
3) 在考慮多個視圖時,OrienterNet比嵌入式消費級GPS傳感器準確得多。
在MGL數據集的驗證拆分上評估了OrienterNet的設計。這確保了攝像機、動作、觀看條件和視覺特征的分布與訓練集相同。報告了三個閾值1/3/5m和1/3/5°時的位置和旋轉誤差的召回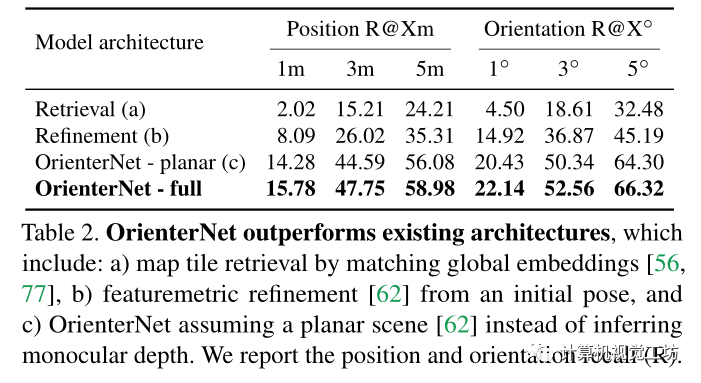
使用KITTI數據集考慮駕駛場景中的定位。為了評估零樣本性能使用了他們的Test2分割,該分割與KITTI和MGL訓練集不重疊。圖像由安裝在城市和住宅區行駛的汽車上的攝像頭拍攝,并具有RTK的GT姿勢。使用OSM map來擴充數據集。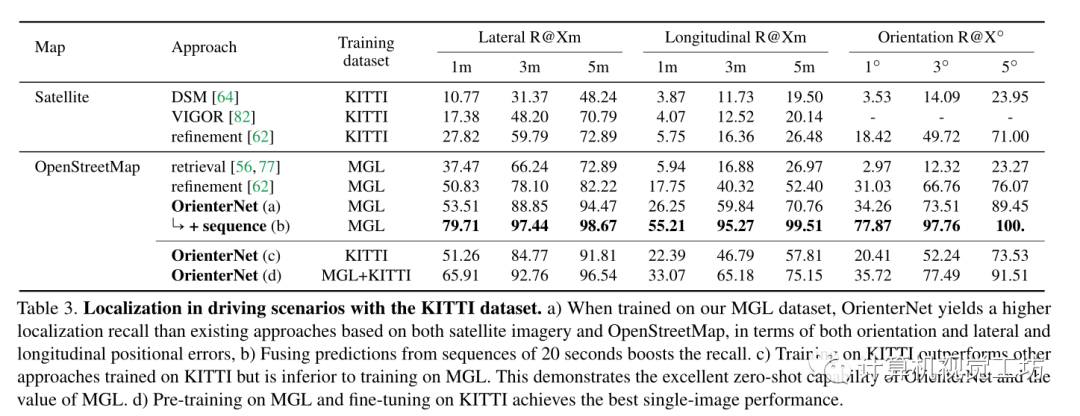
用于增強現實(AR)的頭戴式設備的定位。 因為沒有公共基準可以為在不同的戶外空間使用AR設備拍攝的圖像提供地理對齊的GT姿勢。因此用Aria眼鏡記錄了自己的數據集。它展示了AR的典型模式,帶有嘈雜的消費者級傳感器和行人的視角和動作。 包括兩個地點:i)西雅圖市中心,有高層建筑;ii)底特律,有城市公園和較低的建筑。記錄了每個城市的幾個圖像序列,所有圖像序列都大致遵循多個街區的相同循環。
記錄每幅校準的RGB圖像和GPS測量值,并從離線專有的VI SLAM系統中獲得相對姿態和重力方向。通過基于GPS、VI約束和OrienterNet的預測聯合優化所有序列來獲得偽GT全局姿態。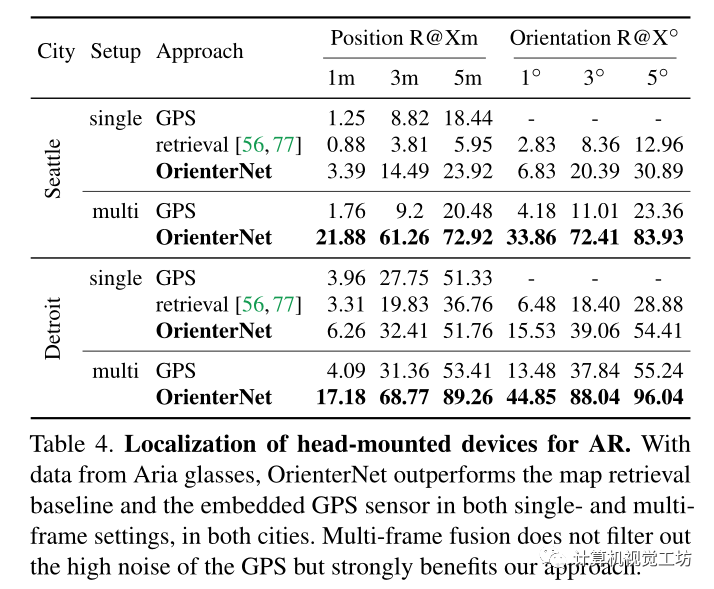
總結:
OrienterNet是第一個深度神經網絡,可以在人類使用的2D平面圖中以亞米精度定位圖像。OrienterNet通過將輸入地圖與源自視覺觀察的心理地圖相匹配,模仿人類在環境中定位自己的方式。與機器迄今為止所依賴的大型且昂貴的3D地圖相比,這種2D地圖非常緊湊,因此最終能夠在大型環境中進行設備上定位。OrienterNet基于OpenStreetMap的全球免費地圖,任何人都可以使用它在世界任何地方進行定位。
審核編輯:劉清
-
傳感器
+關注
關注
2551文章
51125瀏覽量
753759 -
gps
+關注
關注
22文章
2896瀏覽量
166257
原文標題:ETH最新工作:基于神經匹配的二維地圖視覺定位(CVPR2023)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RS232接口的二維影像掃描引擎,廣泛用在醫療設備上掃一維二維碼

工業視覺在條碼/二維碼識別領域的應用

二維碼識讀設備有哪些類型

labview按行讀取二維數組之后再按讀取順序重新組成二維數組如何實現?
agv叉車激光導航和二維碼導航有什么區別?適用什么場景?選哪種比較好?
二維力傳感器怎么安裝,在安裝二維力傳感器的安裝步驟

工業二維碼掃描設備如何助力流水線生產?

如何為柜式終端設備選配(集成)二維碼模塊?

技術|二維PDOA平面定位方案








 工商網監
工商網監
評論