 TinyML,無需重新合成或重新啟動FPGA即可更新
TinyML,無需重新合成或重新啟動FPGA即可更新
預計到本十年末,FPGA 芯片將主導物聯網端點深度神經網絡 (DNN)。它們比微控制器更節能、更快,并且比ASIC更容易開發。Infxl與Microchip合作,通過提供兩項技術優勢來加快其采用速度:
1. 從訓練數據到緊湊的 DNN 的簡單工具 C 語言和 HLS
2. TinyML FPGA實現,無需重新合成或重啟即可更新
其中第一個解決了嵌入式開發人員社區共同關注的問題:ML 和 FPGA 工具需要一定程度的專業知識,而這種專業知識既昂貴又難以找到。
第二個解決了機器學習 (ML) 固有的問題:ML 解決方案在一段時間后會過時,需要定期恢復活力。我們提出了一種 DNN-ON-FPGA 設計,可確保 DNN 無需重新合成、重新實現或重新啟動 FPGA 即可更新。
通過使用簡單緊湊的ML模型,可以進一步放大FPGA實現的能效和速度優勢。Infxl 網絡就是這樣一種模型(示例代碼 [2])。它使用 8/16 位數據路徑在簡單 C 中實現完全連接的 DNN,而無需使用乘法或任何浮點運算。
Infxl 網絡的一個關鍵特征是它在網絡結構/參數和推理引擎之間保持清晰的分離。我們通過在LSRAM中保留參數來利用此功能,同時使用LUT和FF實現引擎。這樣,當我們需要更新已部署的 Infxl 網絡時,我們不需要重新合成、重新實現甚至重新啟動 FPGA。我們只需更新LSRAM中的參數,FPGA幾乎立即開始根據更新的網絡結構/參數提供改進的結果。
開發過程包括兩個主要步驟:
? 將預處理的數據上傳到 cloud.infxl.com,并將經過訓練的 Infxl 網絡下載為即用型 C 代碼。此過程不需要任何 ML 背景。
? 使用Microchip易于使用的SmartHLS編譯器[3],根據項目的確切要求從C代碼生成HLS。SmartHLS是一個基于Eclipse的IDE,它將C / C++代碼作為輸入,并生成SmartDesign IP組件(Verilog HDL)作為輸出。我們可以在Libero SoC設計套件[4]中提供的SmartDesign畫布中實例化生成的SmartDesign IP組件,以構建FPGA系統。
Infxl net C 代碼包括一個測試平臺和一個通用接口。在將其部署到FPGA中之前,需要進行一些簡單的修改:
? 定義首選互連,例如,用于傳入傳感器數據的寄存器或 AXI4 接口。
? 定義用于通信 Infxl 網絡預測的類的機制。
? 將 Infxl 網絡的存儲器類型更改為僅仿真,并定義 C 代碼外部但仍在 FPGA 內部的存儲器。
? 在 C 代碼中創建一個頂級函數以合并 Infxl 網絡。這將是之后實例化到整個FPGA系統中的IP。
默認的 Infxl net C 代碼通過少量 RAM 將推理引擎連接到輸入和輸出。這是微控制器的典型方法。對于FPGA實現,與類似FIFO的接口進行交互會更有效。在默認的 Infxl net C 代碼中添加了額外的小函數以適應這一點。然而,Infxl網絡的推理引擎的代碼保持不變。
有關原始 C 代碼和修改后的 C 代碼的比較,請參見下文。
源語言:
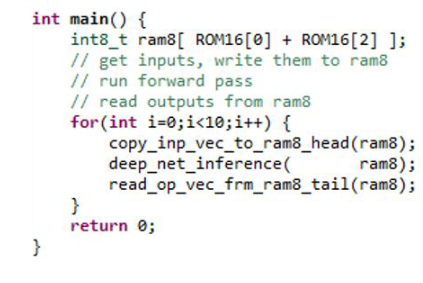
改 性:
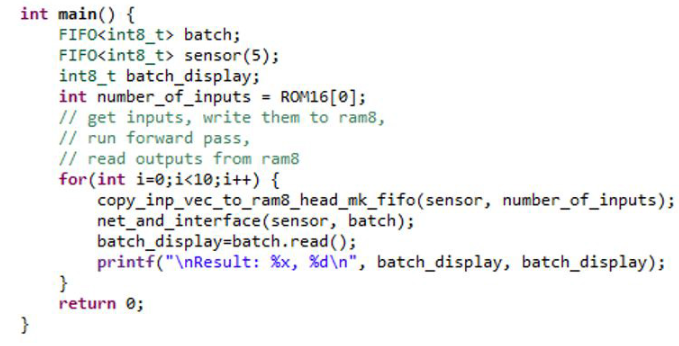
修改或刪除了 Infxl 網絡的默認測試平臺功能(copy_inp_vec_to_ram8_head 和 read_op_vec_frm_ram8_tail),并引入了新的函數net_and_interface。net_and_interface是將使用 SmartHLS 合成的頂級函數。該函數copy_inp_vec_to_ram8_head仍然從測試平臺獲取數據,但是,它使用 FIFO 數據類型將數據輸出到頂級函數中。來自FPGA-IP的數據使用batch.read()命令讀取。然后,變量批次為預測類設置位。
下一步,函數內部RAM被提取出來,并將在SmartHLS的代碼生成過程中轉換為簡單的內存接口。這需要對 ROM16 陣列進行簡單的修改。ROM16封裝了Infxl網絡的結構以及所有參數。對于狀態監測用例,原始ROM16修改如下:
源語言:

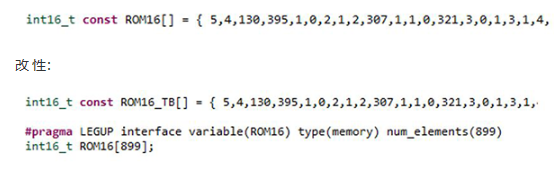
在測試平臺中,ROM16 將在運行 Infxl 網絡之前填充。在整個FPGA設計中也需要等效負載。此加載機制還支持更新已部署的 Infxl 網絡:
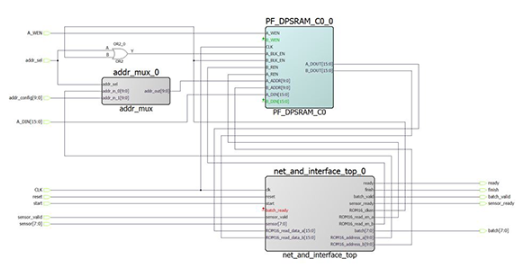
多路復用器 (MUX) 被放入 LSRAM 的一個端口的地址路徑中。與這些用戶可訪問的地址和寫入端口一起,LSRAM可以根據需要填充和更新。上圖顯示了 IP 核,其中 Infxl 網絡配置了 FIFO 接口,用于傳感器數據和可識別的類類型。但是,根據合成設置,可以更改此設置。
現在讓我們看一下硬件。IP 核的確切大小取決于所選接口和任何所需的附加組件。AXI4接口由于其額外的接口功能,將比類似FIFO的接口或連接到AHB總線的寄存器接口需要更多的資源。上面顯示的配置大約需要以下資源:
? 763 個 LUT 和 776 FF 用于 IP,包括接口
? 546 個 LUT 和 610 FF,僅用于 Infxl 網絡
在此配置中,對單個輸入向量的推理大約需要 2800 個時鐘周期。以 100 MHz 或 200 MHz 運行,這將分別導致每 28 μs 或 14 μs 進行一次新分類。
當以上面顯示的方式實現時,我們可以通過將現有的ROM16替換為更新版本來更新Infxl net的結構和參數。交換 Infxl 網絡的內容定義需要 ROM16 中每個項目一個時鐘周期。在我們的用例中,ROM16 陣列的長度為 899。這相當于899個時鐘周期,其中無法進行識別。但是,可以在新舊ROM16之間進行更快的切換,但需要犧牲一些額外的LSRAM。如果需要連續操作,可以使用兩個并聯LSRAM。在兩者中,只有一個在任何給定時間處于活動狀態,另一個處于待機狀態。要更新 Infxl 網絡,備用 LSRAM 將使用新的 ROM16 進行更新。之后,LSRAM輸出數據路徑中的多路復用器被切換,從而激活新加載的ROM16并停用前一個ROM《》。這種切換可以在一個時鐘周期內完成,從而在沒有任何實際延遲的情況下進行更新。
如果對分類率有更高的性能要求,Infxl 網絡也可以合成為并行結構,直至完全并行。這將大大加快分類速度。此優化是實現大小和性能之間的權衡。此外,完全并行的實現將Infxl網絡的結構和參數整合到IP核本身中。這將刪除在不重新合成和重新啟動的情況下進行簡單更新的功能。我們一直在討論的用例的完全并行實現大約需要 10900 個 LUT 和 4800 個 FF,但將分類速度加快到大約 600 個時鐘周期(包括所有握手)。
從本質上講,Infxl net與Microsemi的SmartHLS相結合,提供了一種簡單且面向未來的方法,可以將ML整合到各種系統中。本文中討論的用例基于運動傳感器的數據。但是,使用 Infxl 網絡的應用程序不僅限于該用例。它可用于從預測性維護到環境監測、機器人技術、惡意軟件檢測、醫療保健可穿戴設備等用例。
審核編輯:郭婷
-
FPGA
+關注
關注
1630文章
21781瀏覽量
604913 -
機器人
+關注
關注
211文章
28593瀏覽量
207823 -
機器學習
+關注
關注
66文章
8434瀏覽量
132871
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論