") CVPR 2023:基于可恢復性度量的少樣本剪枝方法
CVPR 2023:基于可恢復性度量的少樣本剪枝方法
2. 引言
近年來,卷積神經(jīng)網(wǎng)絡(luò)(CNNs)取得了顯著的成功,但較高的計算成本阻礙了其實際應(yīng)用部署。為了實現(xiàn)神經(jīng)網(wǎng)絡(luò)加速,許多模型壓縮方法被提出,如模型剪枝、知識蒸餾和模型量化。然而,大多數(shù)早期方法依賴于原始訓練集(即所有訓練數(shù)據(jù))來恢復模型的準確性。然而,在數(shù)據(jù)隱私保護或?qū)崿F(xiàn)快速部署等場景中,可能只有稀缺的訓練數(shù)據(jù)可用于模型壓縮。
例如,客戶通常要求算法提供商加速其CNN模型,但由于隱私問題,無法提供全部訓練數(shù)據(jù)。只能向算法提供商提供未壓縮的原始模型和少量訓練樣本。在一些極端情況下,甚至不提供任何數(shù)據(jù)。算法工程師需要自行合成圖像或收集一些域外的訓練圖像。因此,僅使用極少樣本甚至零樣本情況下的模型剪枝正成為亟待解決的關(guān)鍵問題。
在這種少樣本壓縮場景中,大多數(shù)先前的工作采用了濾波器級剪枝。然而,這種方法在實際計算設(shè)備(如GPU)上無法實現(xiàn)高加速比。在沒有整個訓練數(shù)據(jù)集的情況下,過往方法也很難恢復壓縮模型的準確性。為解決上述問題,本文提出了三大改進:
關(guān)注延遲-準確性的權(quán)衡而非FLOPs-準確性
在少樣本壓縮場景中,塊級(block-level)剪枝在本質(zhì)上優(yōu)于濾波器級(filter-level)。在相同的延遲下,塊級剪枝可以保留更多原始模型的容量,其準確性更容易通過微小的訓練集恢復。如圖 1 所示,丟棄塊在延遲-準確性權(quán)衡方面明顯優(yōu)于以前的壓縮方案。
提出“可恢復性”度量指標,代替過往“低損害性”度量指標[1]。具體來講,過往很多剪枝方法優(yōu)先剪去對最終 loss 影響最小的模塊,而本文優(yōu)先剪去最易通過微調(diào)恢復性能的模塊。
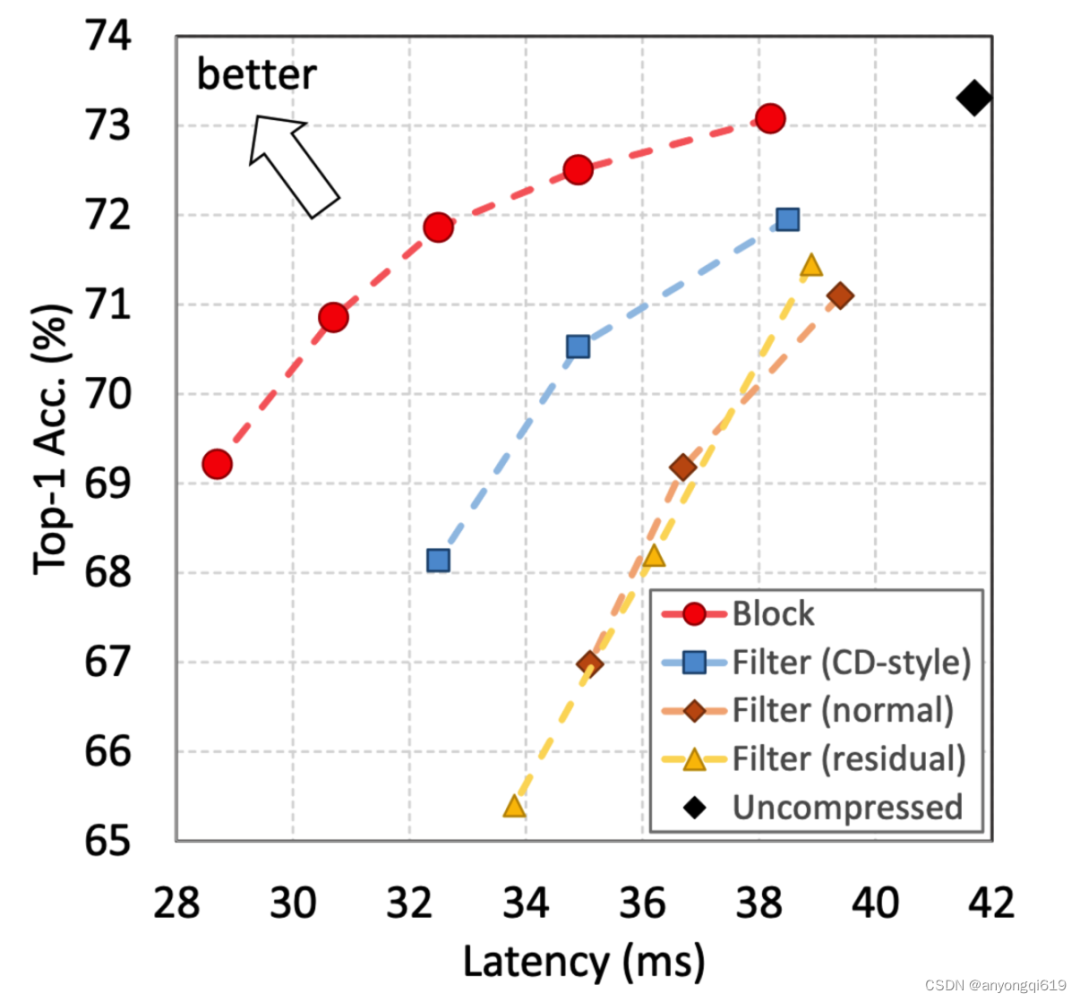
圖 1. 僅使用 500 個訓練圖像的不同壓縮方案比較,Block-level 優(yōu)于 filter-level。
圖 1. 僅使用 500 個訓練圖像的不同壓縮方案比較,Block-level 優(yōu)于 filter-level。
本文提出了PRACTISE(Practical networkacceleration withtinysets of images),以有效地使用少量數(shù)據(jù)加速網(wǎng)絡(luò)。PRACTISE 明顯優(yōu)于先前的少樣本剪枝方法。對于22.1%的延遲減少,PRACTISE 在 ImageNet-1k 上的 Top-1 準確性平均超過先前最先進方法 7.0%(百分點,非相對改進)。它還具有很強的魯棒性和泛化能力,可以應(yīng)用于合成/領(lǐng)域外圖像。
3. 方法

圖 2. PRACTISE 算法偽代碼
圖 2. PRACTISE 算法偽代碼
本文所提出的方法思想非常樸素——即依次模擬每個塊去掉后的恢復效果,按照推理延遲的提速需求,去掉最易恢復的塊,最后再在少樣本數(shù)據(jù)集上微調(diào)。該方法有三個細節(jié)值得講一講:可恢復性度量指標、評估可恢復性的過程和少樣本微調(diào)過程。
3.1 可恢復性度量指標
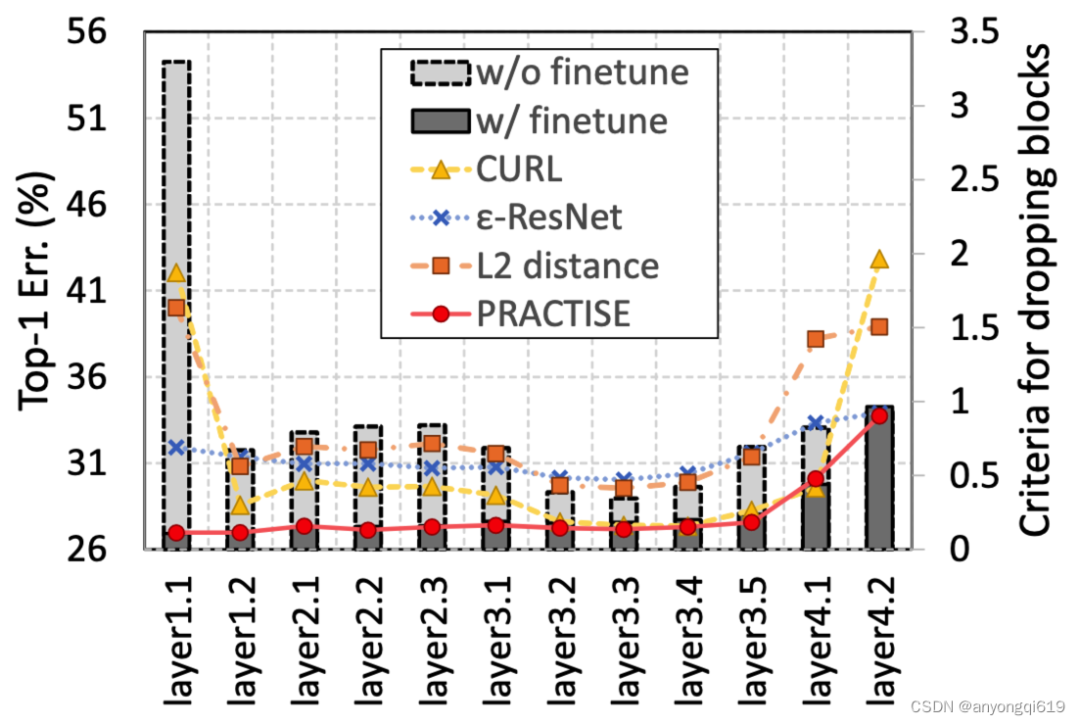
圖 3. 不同層微調(diào)前后的誤差及不同度量指標的數(shù)值對比
圖 3. 不同層微調(diào)前后的誤差及不同度量指標的數(shù)值對比
為了進一步改進塊剪枝,本文研究了選擇要丟棄哪些塊的策略,特別是在僅有少量訓練樣本的情況下。作者注意到盡管丟棄某些塊會顯著改變特征圖,但它們很容易通過端到端微調(diào)(甚至使用極少的訓練集)恢復。因此,簡單地測量剪枝/原始網(wǎng)絡(luò)之間的差異是不合理的。為了解決這些問題,本文提出了一種新的概念,即可恢復性,以更好地指示要丟棄的塊。該指標用于衡量修剪后的模型恢復精度的能力,相較于過去的低損害性指標,該指標更能反映“哪些模塊更應(yīng)該被剪去“。圖 3 表明可恢復性指標幾乎完美預測了微調(diào)后網(wǎng)絡(luò)的誤差。可恢復性計算公式可定義為:
其中, 是原始模型, 是丟棄 塊后的模型, 是模型參數(shù), 表示排除 的參數(shù), 為適配器參數(shù),適配器用于模擬恢復過程,只包括線性算子。
另一個影響因素是不同塊的延遲差異,在具有相同可恢復性的情況下,較高延遲的塊應(yīng)該被優(yōu)先丟棄,因此可定義加速比為:
最終的剪枝重要性得分為:
3.2 評估可恢復性的過程
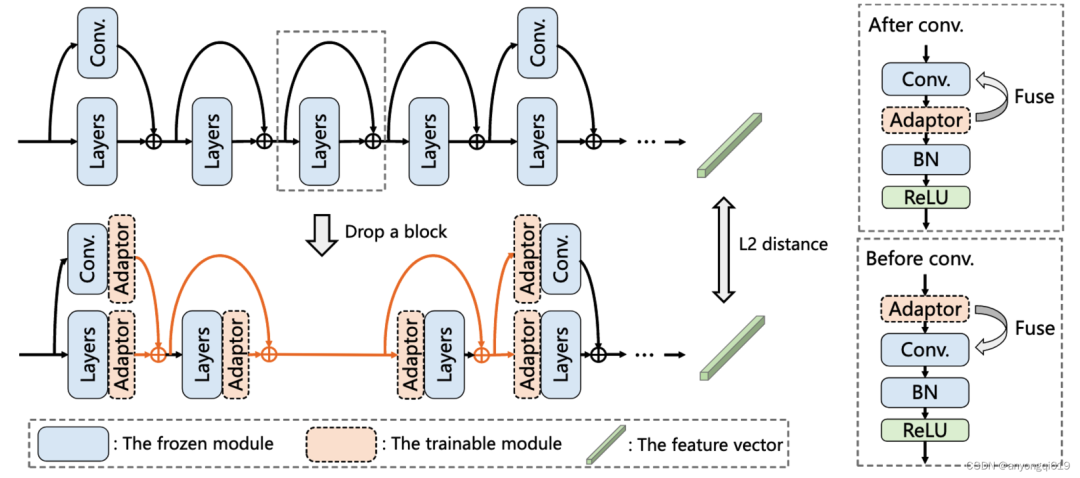
圖 4. 塊丟棄及評估過程的模型結(jié)構(gòu)圖
圖 4. 塊丟棄及評估過程的模型結(jié)構(gòu)圖
在評估階段,PRACTISE 算法將依次去掉每一個塊,在去掉 塊后將在它之前的層后插入適配器,在之后的層前插入適配器,適配器均為 的卷積層。由于卷積操作是線性的,所有適配器都可以和相鄰的卷積層融合(如圖 4 右側(cè)所示),同時保持輸出不變。在評估階段,算法將凍結(jié)模型參數(shù),在少樣本數(shù)據(jù)集上更新適配器參數(shù),對比不同塊去掉后在相同訓練輪次下的恢復損失,作為其可恢復性度量。
3.3 少樣本微調(diào)過程
最簡單的微調(diào)方法就是利用交叉熵損失。然而,正如先前的工作指出的那樣,修剪后的模型很容易受到過擬合的影響[2]。因此本文采用知識蒸餾中的特征蒸餾來緩解過擬合問題,同時這樣的微調(diào)方法也可以在合成數(shù)據(jù)和域外數(shù)據(jù)上實現(xiàn)少樣本微調(diào)。具體微調(diào)損失函數(shù)為:
4. 實驗
少樣本剪枝性能對比:如表 1 所示,PRACTISE 以顯著優(yōu)勢超過其余所有方法,最多提升了 7%的 Top-1 準確率。該表也說明,對于少樣本數(shù)據(jù)集來說,丟棄塊的延遲-準確率權(quán)衡性價比優(yōu)于濾波器級剪枝。

表 1. ResNet-34 在 ImageNet-1k 上的 Top-1/Top-5 準確率對比(Baseline 為 73.31%/91.42%)
表 1. ResNet-34 在 ImageNet-1k 上的 Top-1/Top-5 準確率對比(Baseline 為 73.31%/91.42%)
Data-free 剪枝方法對比:表 2 顯示,在合成數(shù)據(jù)上,PRACTISE 也取得了最優(yōu)的延遲-準確率權(quán)衡(更低延遲下更高性能)。
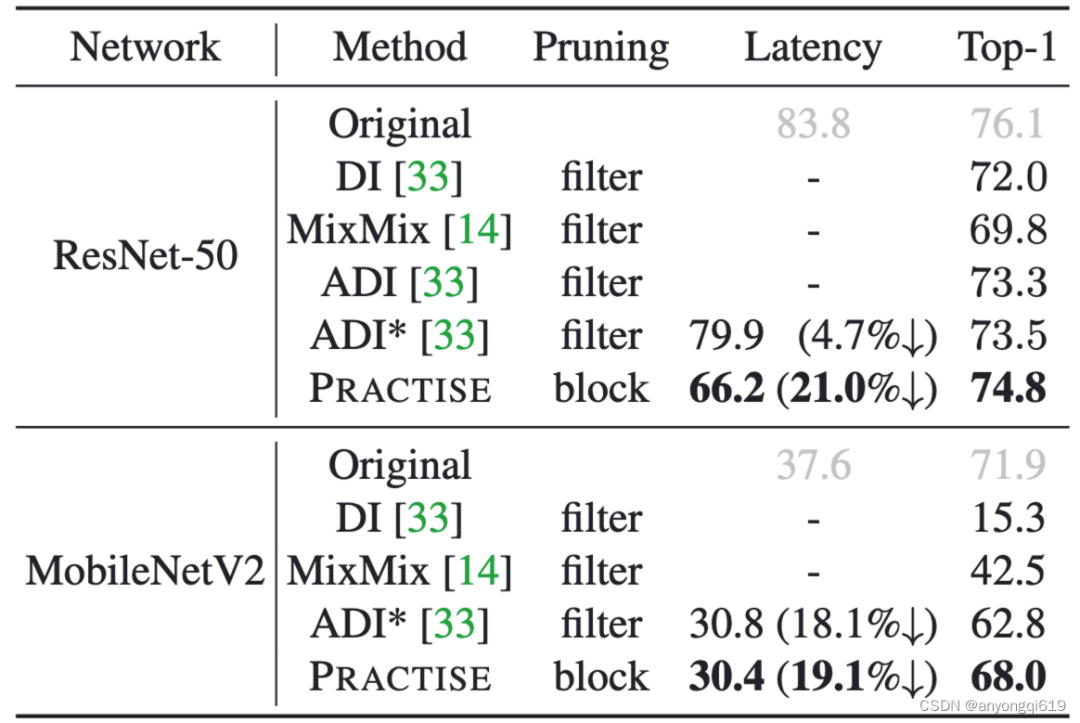
表 2. data-free 剪枝方法在 ImageNet-1k 上的性能對比
表 2. data-free 剪枝方法在 ImageNet-1k 上的性能對比
域外數(shù)據(jù)剪枝結(jié)果:如表 3 所示,PRACTISE 在域外數(shù)據(jù)上也有很強的魯棒性和泛化性。
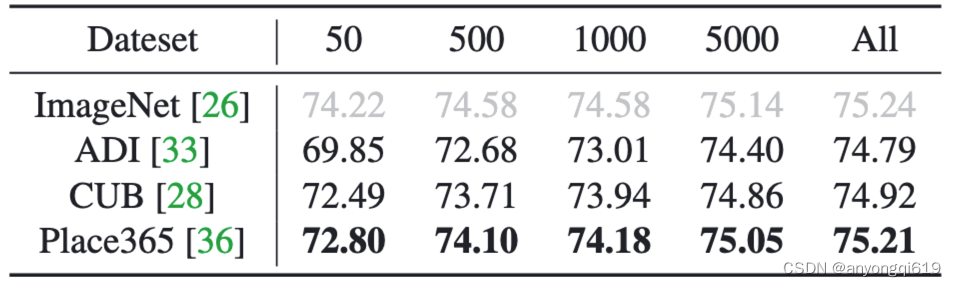
表 3. 域外訓練數(shù)據(jù)下 ImageNet-1k 的剪枝性能展示
表 3. 域外訓練數(shù)據(jù)下 ImageNet-1k 的剪枝性能展示
審核編輯 :李倩
-
濾波器
+關(guān)注
關(guān)注
161文章
7844瀏覽量
178381 -
算法
+關(guān)注
關(guān)注
23文章
4620瀏覽量
93047 -
卷積神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
4文章
367瀏覽量
11882
原文標題:CVPR 2023:基于可恢復性度量的少樣本剪枝方法
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
可恢復保險絲的工作原理
可恢復保險絲是與自恢復保險絲異同點
熔斷保險絲和自恢復保險絲性能差異
可恢復保險絲工作原理_可恢復保險絲選擇方法
可恢復保險絲的特性
膠體電池極板耐硫化、恢復性好的機理
基于噴泉碼的數(shù)據(jù)恢復系統(tǒng)
可恢復保險絲工作原理_可恢復保險絲選擇方法
中興處于“恢復性增長”中 各個業(yè)務(wù)板塊的表現(xiàn)差異比較大
高難度燒斷管腳的芯片如何解密?
48V電源系統(tǒng)可恢復eFuse的設(shè)計秘訣,在這里!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論