

本文導讀
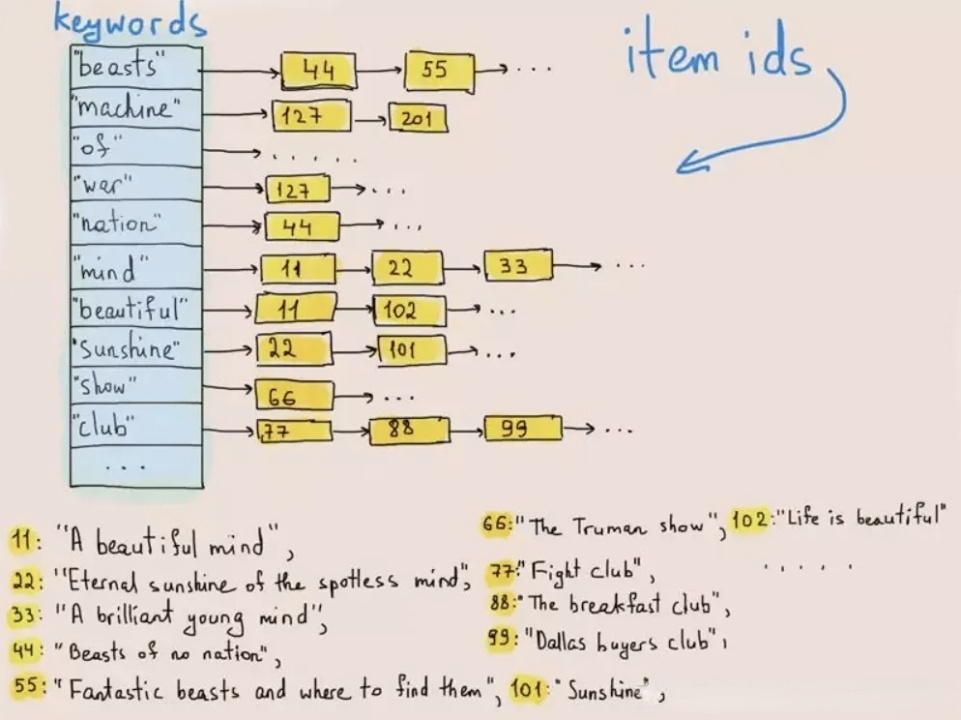
 ES 在日志場景的優勢在于全文檢索能力,能快速從海量日志中檢索出匹配關鍵字的日志,其底層核心技術是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數據結構,最早應用于信息檢索領域。如下圖所示,在數據寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構建詞(Term) -> 行號列表(Posting List) 的映射關系,將映射關系按照詞進行排序存儲。當需要查詢某個詞在哪些行出現的時候,先在 詞 -> 行號列表 的有序映射關系中查找詞對應的行號列表,然后用行號列表中的行號去取出對應行的內容。這樣的查詢方式,可以避免遍歷對每一行數據進行掃描和匹配,只需要訪問包含查找詞的行,在海量數據下性能有數量級的提升。
ES 在日志場景的優勢在于全文檢索能力,能快速從海量日志中檢索出匹配關鍵字的日志,其底層核心技術是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數據結構,最早應用于信息檢索領域。如下圖所示,在數據寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構建詞(Term) -> 行號列表(Posting List) 的映射關系,將映射關系按照詞進行排序存儲。當需要查詢某個詞在哪些行出現的時候,先在 詞 -> 行號列表 的有序映射關系中查找詞對應的行號列表,然后用行號列表中的行號去取出對應行的內容。這樣的查詢方式,可以避免遍歷對每一行數據進行掃描和匹配,只需要訪問包含查找詞的行,在海量數據下性能有數量級的提升。 業界各類系統為了支持全文檢索和任意列索引,往往有兩種實現方式:一是通過外接索引系統來實現,原始數據存儲在原系統中、索引存儲在獨立的索引系統中,兩個系統通過數據的 ID 進行關聯。數據寫入時會同步寫入到原系統和索引系統,索引系統構建索引后不存儲完整數據只保留索引。查詢時先從索引系統查出滿足過濾條件的數據 ID 集合,然后用 ID 集合去原系統查原始數據。這種架構的優勢是實現簡單,借力外部索引系統,對原有系統改動小。但是問題也很明顯:
業界各類系統為了支持全文檢索和任意列索引,往往有兩種實現方式:一是通過外接索引系統來實現,原始數據存儲在原系統中、索引存儲在獨立的索引系統中,兩個系統通過數據的 ID 進行關聯。數據寫入時會同步寫入到原系統和索引系統,索引系統構建索引后不存儲完整數據只保留索引。查詢時先從索引系統查出滿足過濾條件的數據 ID 集合,然后用 ID 集合去原系統查原始數據。這種架構的優勢是實現簡單,借力外部索引系統,對原有系統改動小。但是問題也很明顯: 高性能是 Apache Doris 倒排索引設計和實現的首要出發點,我們通過公開的測試數據集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:
高性能是 Apache Doris 倒排索引設計和實現的首要出發點,我們通過公開的測試數據集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:
日志數據的處理與分析是最典型的大數據分析場景之一,過去業內以 Elasticsearch 和 Grafana Loki 為代表的兩類架構難以同時兼顧高吞吐實時寫入、低成本海量存儲、實時文本檢索的需求。Apache Doris 借鑒了信息檢索的核心技術,在存儲引擎上實現了面向 AP 場景優化的高性能倒排索引,對于字符串類型的全文檢索和普通數值、日期等類型的等值、范圍檢索具有更高效的支持,相較于 Elasticsearch 實現性價比 10 余倍的提升,以此為日志存儲與分析場景提供了更優的選擇。

日志數據在企業大數據中非常普遍,其體量往往在企業大數據體系中占據非常高的比重,包括服務器、數據庫、網絡設備、IoT 物聯網設備產生的系統運維日志,與此同時還包含了用戶行為埋點等業務日志。
日志數據對于保障系統穩定運行和業務發展至關重要:基于日志的監控告警可以發現系統運行風險,及時預警;在故障排查過程中,實時日志檢索能幫助工程師快速定位到問題,盡快恢復服務;日志報表能通過長歷史統計發現潛在趨勢。而用戶埋點日志數據則是用戶行為分析以及智能推薦業務所依賴的決策基礎,有助于用戶需求洞察與體驗優化以及后續的業務流程改進。由于其在業務中能發揮的重要意義,因此構建統一的日志分析平臺,提供對日志數據的存儲、高效檢索以及快速分析能力,成為企業挖掘日志數據價值的關鍵一環。而日志數據和應用場景往往呈現如下的特點:- 數據增長快:每一次用戶操作、系統事件都會觸發新的日志產生,很多企業每天新增日志達到幾十甚至幾百億條,對日志平臺的寫入吞吐要求很高;
- 數據總量大:由于自身業務和監管等需要,日志數據經常要存儲較長的周期,因此累積的數據量經常達到幾百 TB 甚至 PB 級,而較老的歷史數據訪問頻率又比較低,面臨沉重的存儲成本壓力;
- 時效性要求高:在故障排查等場景需要能快速查詢到最新的日志,分鐘級的數據延遲往往無法滿足業務極高的時效性要求,因此需要實現日志數據的實時寫入與實時查詢。
- 高吞吐實時寫入:即需要保證日志流量的大規模寫入,又要支持低延遲可見;
- 低成本大規模存儲:系統自身可以存儲海量數據,且通過數據壓縮、冷熱分離等多種機制降低存儲成本;
- 高性能交互式分析且支持文本檢索:日志檢索的隨機性很強、很難提前預測模式,因此要求支持靈活的文本檢索,通過實時交互式查詢滿足分析需求。

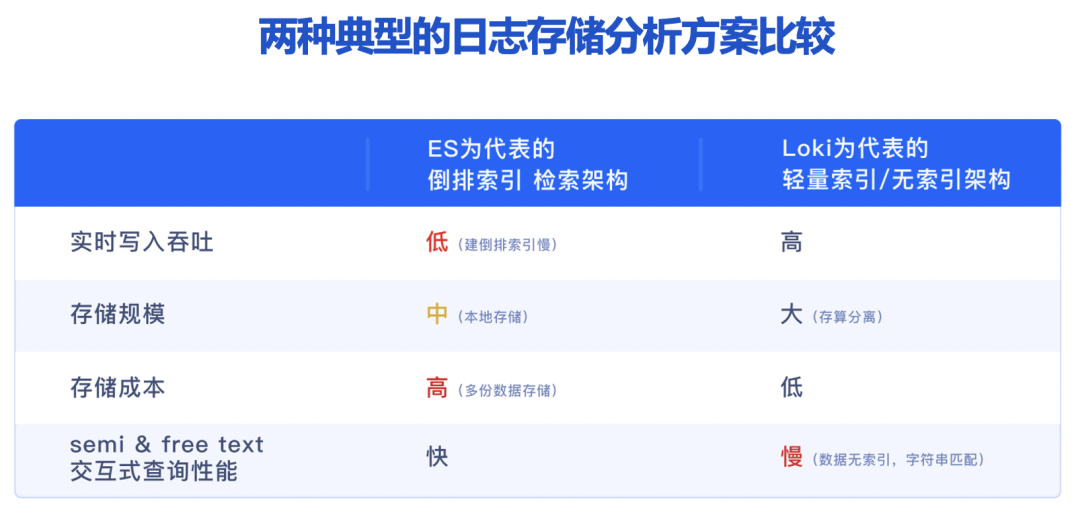
- 以 ES 為代表的倒排索引檢索架構,支持全文檢索、查詢性能好,因此在日志場景中被業內大規模應用,但其仍存在一些不足,包括實時寫入吞吐低、消耗大量資源構建索引,且需要消耗巨大存儲成本;
- 以 Loki 為代表的輕量索引或無索引架構,實時寫入吞吐高、存儲成本較低,但是檢索性能慢、關鍵時候查詢響應跟不上,性能成為制約業務分析的最大掣肘。
ES 在日志場景的優勢在于全文檢索能力,能快速從海量日志中檢索出匹配關鍵字的日志,其底層核心技術是倒排索引(Inverted Index)。倒排索引是一種用于快速查找文檔中包含特定單詞或短語的數據結構,最早應用于信息檢索領域。如下圖所示,在數據寫入時,倒排索引可以將每一行文本進行分詞,變成一個個詞(Term),然后構建詞(Term) -> 行號列表(Posting List) 的映射關系,將映射關系按照詞進行排序存儲。當需要查詢某個詞在哪些行出現的時候,先在 詞 -> 行號列表 的有序映射關系中查找詞對應的行號列表,然后用行號列表中的行號去取出對應行的內容。這樣的查詢方式,可以避免遍歷對每一行數據進行掃描和匹配,只需要訪問包含查找詞的行,在海量數據下性能有數量級的提升。

- ES 基于 Apache Lucene 構建倒排索引,Apache Lucene 自 2000 年開源至今已有超過 20 年的歷史,設計之初主要面向信息檢索領域、功能豐富且復雜,而日志和大多數 OLAP 場景只需要其核心功能,包括分詞、倒排表等,而相關度排序等并非強需求,因此存在進一步功能簡化和性能提升的空間;
- ES 和 Apache Lucene 均采用 Java 實現,而 Apache Doris 存儲引擎和執行引擎采用 C++ 開發并且實現了全面向量化,相對于 Java 實現具有更好的性能;
- 倒排索引并不能決定性能表現的全部,作為一個高性能、實時的 OLAP 數據庫,Apache Doris 的列式存儲引擎、MPP 分布式查詢框架、向量化執行引擎以及智能 CBO 查詢優化器,相較于 ES 更為高效。
業界各類系統為了支持全文檢索和任意列索引,往往有兩種實現方式:一是通過外接索引系統來實現,原始數據存儲在原系統中、索引存儲在獨立的索引系統中,兩個系統通過數據的 ID 進行關聯。數據寫入時會同步寫入到原系統和索引系統,索引系統構建索引后不存儲完整數據只保留索引。查詢時先從索引系統查出滿足過濾條件的數據 ID 集合,然后用 ID 集合去原系統查原始數據。這種架構的優勢是實現簡單,借力外部索引系統,對原有系統改動小。但是問題也很明顯:- 數據寫入兩個系統,異常有數據不一致的問題,也存在一定冗余存儲;
- 查詢需在兩個系統進行網絡交互有額外開銷,數據量大時用 ID 集合去原系統查性能比較低;
- 維護兩套系統的復雜度高,將系統的復雜性從開發測轉移到運維測;
數據庫內置倒排索引
在選擇了在數據庫內核中內置倒排索引后,我們需要進一步對 Apache Doris 索引結構進行分析,判斷能否通過在已有索引基礎上進行拓展來實現。Apache Doris 現有的索引存儲在 Segment 文件的 Index Region 中,按照適用場景可以分為跳數索引和點查索引兩類:1. 跳數索引:包括 ZoneMap 索引和 Bloom Filter 索引。
- ZoneMap 索引對每一個數據塊和文件保存 Min/Max/isnull 等匯總信息,可以用于等值、范圍查詢的粗粒度過濾,只能排除不滿足查詢條件的數據塊和文件,不能定位到行,也不支持文本分詞。
- BloomFilter 索引也是數據塊和文件級別的索引,通過 Bloom Filter 判斷某個值是否在數據塊和文件中,同樣不能定位到行、不支持文本分詞;
- ShortKey 在排序的基礎上,根據給定的前綴列實現快速查詢數據的索引方式,能夠對前綴索引的列進行等值、范圍查詢,但不支持文本分詞,另外由于數據要按前綴索引排序、因此一個表只允許一組前綴索引。
- Bitmap 索引記錄數據值 -> 行號 Bitmap 的有序映射,是一種很基礎的倒排索引,但是索引結構比較簡單、查詢效率不高、不支持文本分詞。
- 數據寫入和 Compaction 階段:在寫 Segment 文件的同時,同步寫入一個 Inverted Index 文件,文件路徑由 Segment ID + Index ID 決定。寫入 Segment 的 Row 和 Index 中的 Doc 一一對應,由于同步順序寫入,Segment 中的 Rowid 和 Index 中的 Docid 完全對應。
- 查詢階段:如果查詢 Where 條件中有建了倒排索引的列,會自動去 Index 文件中查詢,返回滿足條件的 Docid List,將 Docid List 一一對應的轉成 Rowid Bitmap,然后走 Doris 通用的 Rowid 過濾機制只讀取滿足條件的行,達到查詢加速的效果。
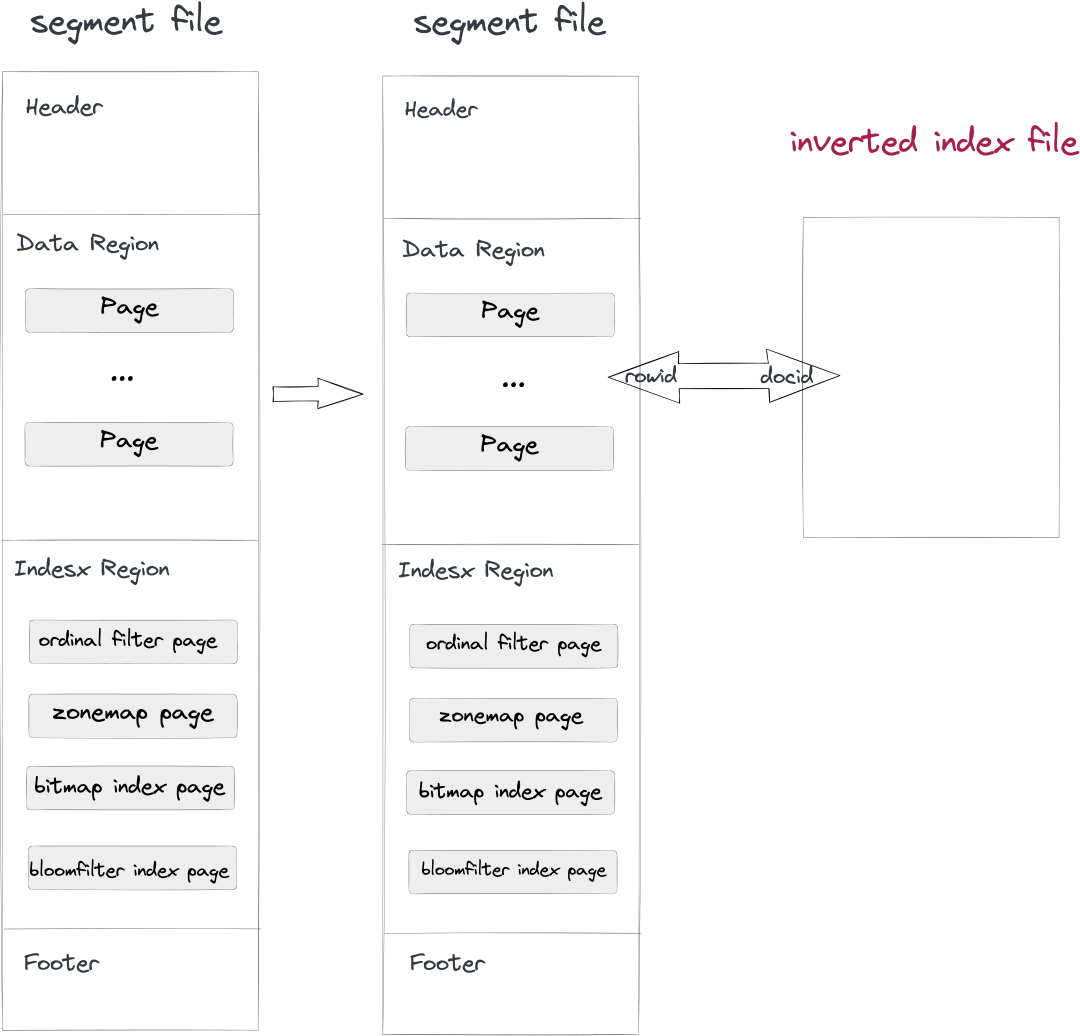
Doris倒排索引架構圖
這個設計的好處是已有的數據文件無需修改,可以做到兼容升級,而且增減索引不影響數據文件和其他索引,用戶增建索引沒有負擔。
通用倒排索引優化
C++和向量化實現Apache Doris 使用 CLucene(https://clucene.sourceforge.net/) 作為底層的倒排索引庫,CLucene 是一個用 C++ 實現的高性能、穩定的 Lucene 倒排索引庫,它的功能比較完整,支持分詞和自定義分詞算法,支持全文檢索查詢和等值、范圍查詢。Apache Doris 的存儲模塊和 CLucene 都用 C++ 實現,避免了Java Lucene 的 JVM GC 等開銷,同樣的計算 C++ 實現相對于 Java 性能優勢明顯,而且更利于做向量化加速。Doris 倒排索引進行了向量化優化,包括分詞、倒排表構建、查詢等,性能得到進一步提升。整體來看 Doris 的倒排索引寫入速度可以超過單核 20MB/s,而 ES 的單核寫入速度不到 5MB/s,有 4 倍的性能優勢。列式存儲和壓縮Lucene 本身是文檔存儲模型,主數據采用行存,而 Doris 中不同列的倒排索引是相互獨立的,因此倒排索引文件也采用列式存儲,有利于向量化構建索引和提高壓縮率。采用壓縮比高且速度快的 ZSTD,通常可以達到 5 ~10倍的壓縮比,與常用的GZIP壓縮相比有50%以上的空間節省且速度更快。BKD 索引與數值、日期類型列優化針對數值、日期類型的列,我們還實現了 BKD 索引,可以對范圍查詢提高性能,存儲空間也相對于轉成定長字符串更加高效,具有以下主要特性和優勢:- 高效范圍查詢:BKD 索引采用多維數據結構,為范圍查詢帶來高效率。它能迅速定位數值或日期類型列中所需的數據范圍,降低查詢時間復雜度。
- 存儲空間優化:與其他索引方法相比,BKD 索引在存儲空間使用上更高效。通過聚合并壓縮相鄰數據塊,減少索引所需存儲空間,降低存儲成本。
- 多維數據支持:BKD 索引具備良好擴展性,支持多維數據類型,如地理坐標(GEO point)和范圍(Range),使其在處理復雜數據類型時具有高適應性。
- 優化低基數場景:針對數值分布集中、單個數值倒排列表較多的低基數場景,我們調整了針對性的壓縮算法,降低大量倒排表解壓縮和反序列化所帶來的CPU性能消耗。
- 預查詢技術:針對查詢結果命中數較高的場景,我們采用預查詢技術進行命中數預估。若命中數顯著超過閾值,可跳過索引查詢,直接利用Doris在大數據量查詢下的技術優勢進行數據過濾。
面向 OLAP 的倒排索引優化
日志存儲和分析場景對檢索的需求很簡單,不需要特別復雜的功能(比如相關性排序),更需要降低存儲成本和快速按照條件查出數據。因此,在面對海量數據的寫入和查詢時,Apache Doris 還針對 OLAP 數據庫的特點優化了倒排索引的結構,使其更加簡潔高效。例如:- 在寫入流程保證不會多個線程寫入一個索引,從而避免寫入時多線程鎖競爭的開銷;
- 在存儲結構上去掉了不必要的正排、norm 等文件,減少寫入 IO 開銷和存儲空間占用;
- 查詢過程中簡化相關性打分和排序邏輯,降低不必要的開銷,提升查詢性能。
- 指定分區構建倒排索引,比如新增一個索引的時候指定最近7天的日志構建索引,歷史數據不建索引
- 指定分區刪除倒排索引,比如刪除超過1個月的日志的索引,釋放訪問頻度低的索引存儲空間
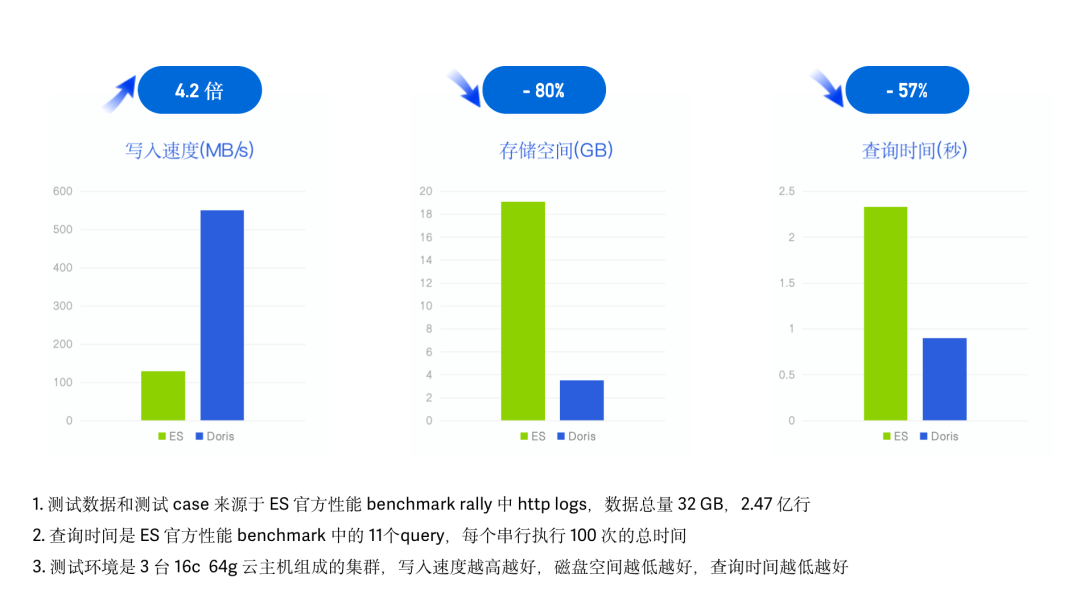
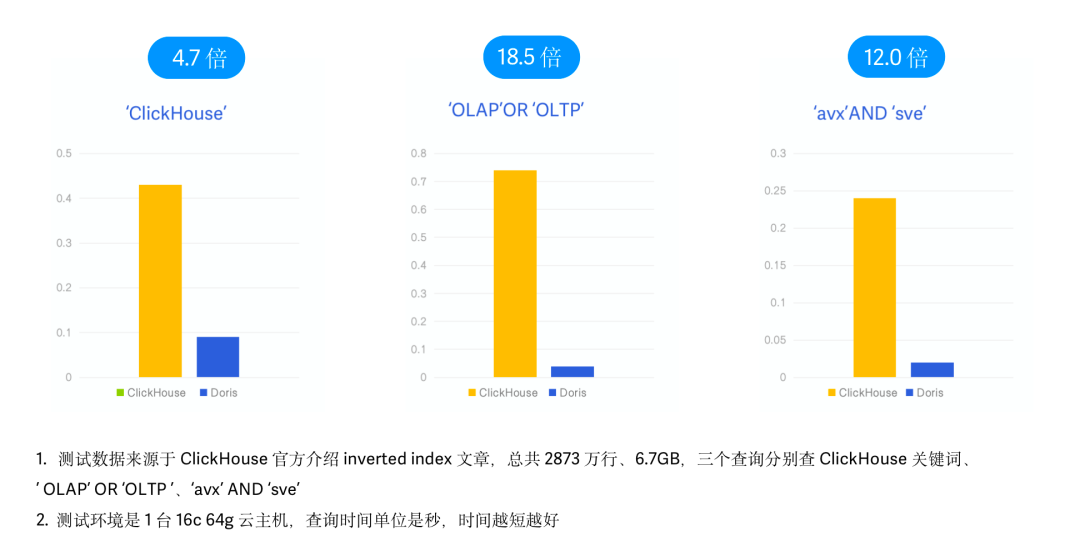
高性能是 Apache Doris 倒排索引設計和實現的首要出發點,我們通過公開的測試數據集分別與 ES 以及 Clickhouse 進行性能測試,測試效果如下:vs Elasticsearch
我們采用了 ES 官方的性能測試 Benchmark esrally 并使用其中的 HTTP Logs 日志,在同樣的硬件資源、數據、測試Case 以及測試工具下,記錄并對比各自的數據寫入時間、吞吐以及查詢延遲。- 測試數據:esrally HTTP Logs track 中自帶測試數據集,1998 年 World Cup HTTP Server Logs,未壓縮前 32G、共 2.47 億行、單行平均長度 134 字節;
- 測試查詢:esrally HTTP Logs 測試關鍵詞檢索、范圍查詢、聚合、排序等 11 個 Query,所有查詢跑 100 次串行執行;
- 測試環境:3 臺 16C 64G 云主機組成的集群。
vs Clickhouse
Clickhouse 近期的 v23.1 版本也引入了類似 Feature,將倒排索引作為實驗性功能發布,因此我們同樣進行了跟 Clickhouse 倒排索引的性能對比。在本次測試中,我們采用了 Clickhouse 官方 Inverted Index 介紹博客中使用的 Hacker News 樣例數據以及查詢 SQL ,同樣保持相同的物理資源、數據、測試 Case 以及測試工具。(參考文章:https://clickhouse.com/blog/clickhouse-search-with-inverted-indices)- 測試數據:Hacker News 2873 萬條數據,6.7G,Parquet 格式;
- 測試查詢:3 個查詢,分別查詢 'clickhouse'、'olap' OR 'oltp'、'avx' AND 'sve' 等關鍵字出現的次數;
- 測試機器:1 臺 16C 64G 云主機

-
INDEX idx_comment (`comment`)指定對 comment 列建一個名為idx_comment的索引 -
USING INVERTED指定索引類型為倒排索引 -
PROPERTIES("parser" = "english")指定分詞類型為英文分詞
MATCH_ALL在comment這一列上匹配 OLAP 和 OLTP 兩個詞,和LIKE掃描硬匹配相比,查詢性能有十余倍的提升。(這僅是 100 萬條數據下的測試效果,而隨著數據量增大、性能提升越明顯)
mysql>SELECTcount()FROMhackernews_1mWHEREcommentLIKE'%OLAP%'ANDcommentLIKE'%OLTP%'; +---------+ |count()| +---------+ |15| +---------+ 1rowinset(0.13sec) mysql>SELECTcount()FROMhackernews_1mWHEREcommentMATCH_ALL'OLAPOLTP'; +---------+ |count()| +---------+ |15| +---------+ 1rowinset(0.01sec)更多詳細功能介紹和測試步驟可以參考Apache Doris 倒排索引官方文檔:https://doris.apache.org/zh-CN/docs/dev/data-table/index/inverted-index/

審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
日志
+關注
關注
0文章
140瀏覽量
10780 -
數據類型
+關注
關注
0文章
236瀏覽量
13752 -
數組
+關注
關注
1文章
419瀏覽量
26271
原文標題:從 Elasticsearch 到 Apache Doris,10 倍性價比的新一代日志存儲分析平臺|新版本揭秘
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
新一代光纖涂覆機
新一代光纖涂覆機系列:國產!
2025年,濰坊華纖光電科技將推出五大類全光纖涂覆機,標志著國產光纖涂覆機技術邁入水平。以下是該系列產品的詳細介紹:
五大類光纖涂覆機
單套模組光纖涂覆機
特點:可替代
發表于 04-03 09:13
隆基新一代分布式組件Hi-MO X10登陸南歐市場
2月末,隆基新一代分布式組件Hi-MO X10強勢登陸法國、西班牙、意大利等南歐市場,以“技術+場景”雙核驅動,掀起一場跨越國界的光伏風暴。從古堡盛典
Simcenter Testlab Neo多學科性能工程的新一代軟件平臺
SimcenterTestlabNeo多學科性能工程的新一代軟件平臺通過在任何流程中集成分析和仿真模型,提高基于測試的多學科性能工程的工作效率和洞察力。為何選擇SimcenterTestlabNeo

在華為云上通過 Docker 容器部署 Elasticsearch 并進行性能評測
Elasticsearch容器 ? 3.3 驗證Elasticsearch ? 4. 安裝Apache Benchmark (ab) 工具 ? 5. 使用 ab 工具對 Elasticsear
Linux實時查看日志的四種命令詳解
tail命令 - 實時監控日志 如上所述,tail命令是實時顯示日志文件的最常用解決方案。但是,顯示該文件的命令有兩個版本,如下面的示例所示。 在第一個示例中,命令tail需要-f參數來跟蹤文件的內容
亞馬遜云科技發布新一代Amazon SageMaker
近期,亞馬遜云科技正式宣布推出新一代Amazon SageMaker平臺。這一創新舉措旨在將客戶在數據處理、分析、建模及生成式人工智能應用方面的多樣化需求,統
VoIP?網絡排障新思路:從日志到 IOTA?分析
VoIP 網絡需要高可用性與低延遲,但復雜的問題如 SIP 403 錯誤常導致服務中斷。傳統的日志和基本流量分析方法往往耗時低效,而 IOTA 工具通過實時流量捕獲與深入分析,大幅提高排障效率。本文
亞馬遜云科技推出新一代Amazon SageMaker
為數據、分析和AI提供統一平臺 北京2024年12月10日?/美通社/ -- 亞馬遜云科技在2024 re:Invent全球大會上,宣布推出新一代
日志篇:模組日志總體介紹
?今天我們學習合宙模組日志總體介紹,以下進入正文。 一、本文討論的邊界 本文是對合宙 4G 模組, 以及 4G+GNSS 模組的日志功能的總體介紹。通過日志,可以對研發過程中,以及模組

啟明信息完成國產化Doris數據庫升級替代任務
近日,隨著集團公司監控平臺(Elasticsearch集群)的下線,標志著啟明信息正式完成國產化Doris數據庫升級替代任務。該項目既標志著啟明信息信創升級替代邁入新臺階,同時也標志著在Dor
th4521在0輸入時,251倍放大倍數,25℃到130℃時輸出從10mv到0.35v是什么原因引起的?
th4521在0輸入時,251倍放大倍數,25℃到130℃時輸出從10mv到0.35v,是什么原因引起的,怎么解決?
發表于 08-14 06:49
浪潮信息推出基于新一代分布式存儲平臺AS13000G7的AIGC存儲解決方案
6月28日,浪潮信息“元腦中國行”全國巡展杭州站順利舉行。會上,浪潮信息重磅推出基于新一代分布式存儲平臺AS13000G7的AIGC存儲解決方案。通過加持EPAI/AIStation的

Rokid正式發布新一代AR Lite空間計算套裝
Rokid正式發布新一代AR Lite空間計算套裝,包括Rokid Max2眼鏡和搭載驍龍平臺的Rokid Station2主機。





 工商網監
工商網監

評論