 河套IT TALK 77: (原創) 解讀老黃與Ilya的爐邊談話系列之六——ChatGPT未來將走向何方(萬字長文)
河套IT TALK 77: (原創) 解讀老黃與Ilya的爐邊談話系列之六——ChatGPT未來將走向何方(萬字長文)

 一個月前,就在GPT 4發布的第二天,同時也是英偉達(NVIDIA)線上大會的契機,英偉達的創始人兼CEO黃仁勛("Jensen" Huang)與OpenAI的聯合創始人兼首席科學家伊爾亞-蘇茨克維(Ilya Sutskever )展開了一次信息量巨大的長達一個小時的“爐邊談話”(Fireside Chats)。期間談到了從伊爾亞-蘇茨克維早期介入神經網絡、深度學習,基于壓縮的無監督學習、強化學習、GPT的發展路徑,以及對未來的展望。相信很多人都已經看過了這次談話節目。我相信,因為其中摻雜的各種專業術語和未經展開的背景,使得無專業背景的同仁很難徹底消化理解他們談話的內容。本系列嘗試將他們完整的對話進行深度地解讀,以便大家更好地理解ChatGPT到底給我們帶來了什么樣的變革。今天,就是這個系列的第六篇:ChatGPT未來將走向何方?這也是本系列的最后一篇。
?
一個月前,就在GPT 4發布的第二天,同時也是英偉達(NVIDIA)線上大會的契機,英偉達的創始人兼CEO黃仁勛("Jensen" Huang)與OpenAI的聯合創始人兼首席科學家伊爾亞-蘇茨克維(Ilya Sutskever )展開了一次信息量巨大的長達一個小時的“爐邊談話”(Fireside Chats)。期間談到了從伊爾亞-蘇茨克維早期介入神經網絡、深度學習,基于壓縮的無監督學習、強化學習、GPT的發展路徑,以及對未來的展望。相信很多人都已經看過了這次談話節目。我相信,因為其中摻雜的各種專業術語和未經展開的背景,使得無專業背景的同仁很難徹底消化理解他們談話的內容。本系列嘗試將他們完整的對話進行深度地解讀,以便大家更好地理解ChatGPT到底給我們帶來了什么樣的變革。今天,就是這個系列的第六篇:ChatGPT未來將走向何方?這也是本系列的最后一篇。
?關聯回顧
解讀老黃與Ilya的爐邊談話系列之一——故事要從AlexNet說起
解讀老黃與Ilya的爐邊談話系列之二——信仰、準備、等待機會的涌現
解讀老黃與Ilya的爐邊談話系列之三——超越玄幻,背后是人類老師的艱辛付出
解讀老黃與Ilya的爐邊談話系列之四——人人都是ChatGPT的訓練器
解讀老黃與Ilya的爐邊談話系列之五——將要擁抱多模態的ChatGPT
讓ChatGPT自己來談一談人工智能倫理
全圖說ChatGPT的前世今生


對話譯文(06):
黃仁勛:這真是不可思議。你之前還說過的一件事,是關于用 AI 生成測試,來訓練另一個 AI 的事。這讓我想起了一篇論文,雖然我不確定其中的內容是否屬實。據說在未來一段時間內,全世界大概有4萬億到20萬億的語言類tokens 可以被用于訓練模型。你知道,在一段時間內,可以用來訓練的 token 會慢慢消耗殆盡。首先,我不知道你是否有同樣的感覺?
其次,我們是否可以利用 AI 生成自己的數據來訓練AI 本身?你可能會反駁這是一個循環,但我們無時無刻不在用生成的數據,通過自我反省的方式,訓練我們的大腦,并在腦海里思考某一個問題。神經科學家會建議人們保持充足的睡眠,我們會做很多事情,比如睡眠,來發展我們的神經元。你如何看待合成數據生成領域?這是否會成為未來AI 訓練重要的一部分,AI 能否自己訓練自己?
Ilya Sutskever:我認為不應該低估現有的數據,我認為可能有比人們意識到的更多的數據。至于你的第二個問題,這種可能性仍有待觀察。
黃仁勛:未來的某些時候,當我們不使用 AI 時,它可能會生成對抗性的內容來進行學習,或者想象著它需要解決的問題,不斷提升自己,并告訴我們它能做什么。關于我們現在在哪里,以及未來我們將會在哪里,時間不用很遙遠,比如說可見的一兩年,在最讓你興奮的領域中,你認為語言模型會走向何方?
Ilya Sutskever:預測是困難的,尤其是對太具體的事情。我們有理由認為這個領域會持續進步,我們將繼續看到AI 系統在它的能力邊界,讓人類感到驚訝。AI的可靠性是由它是否可以被信任決定的,未來它肯定會達到能被完全信任的地步。如果它不能完全理解,它也會通過提問來弄清楚。它會告訴你自己不知道,但同時它會說需要更多的信息。
我認為 AI 可用性影響最大的領域,未來會有最大的進步。因為現在,我們就面臨著一個挑戰,你想讓一個神經網絡去總結長文檔,獲取摘要。挑戰是,你能確定重要的細節沒被忽略嗎?
這仍然是一個有用的摘要,但當你知道所有重要的點都被涵蓋時,就會產生不同的結果。在某個時刻,尤其是當存在歧義時,這也是可以接受的。但如果某個點明顯很重要,以至于任何其他看到該點的人都會說這真的很重要,當神經網絡也能可靠地識別到這一點時,你就會知道它可信度提高了。這同樣適用于防護欄。它是否清楚的遵循用戶的意圖,也會成為衡量可靠性的標準。未來兩年,我們會看到很多這樣的技術。
黃仁勛:是的,這太棒了。這兩個領域的進步將使這項技術變得值得信賴,使它能夠應用于許多事情。這本應該是最后一個問題,但是我的確還有另外一個問題,抱歉。從 ChatGPT 到 GPT-4,你是什么時候第一次開始使用GPT-4 的?它表現出來什么樣的能力,讓你感到驚訝?
Ilya Sutskever:它展示了很多很酷的東西,非常驚人。它非常棒,我會提到兩點,我在想怎么才可以更好地表達。簡單來說,它的可靠性水平讓人感到驚訝。在此之前的神經網絡,如果你問它一個問題,它可能會以一種近乎愚蠢的方式誤解問題。但在 GPT-4 上這種情況已經不再發生。它解決數學問題的能力大大提高了,你可以認為它真的進行了推導,很長的、復雜的推導,并且還轉換了單位等等,這真的很酷。
黃仁勛:它是通過一步步的證明來工作的,這真的很神奇。
Ilya Sutskever:不是所有的證明,但起碼有很大一部分是的。另外一個例子,就像許多人注意到它可以用同一個字母開頭的單詞寫詩,每個單詞都很清晰地遵循著指令。雖然仍不完美,但是已經非常好了。
在視覺方面,我真的很喜歡它是如何解釋笑話的。它可以解釋網絡熱梗,你給它看一個網絡熱梗,并詢問它這個為什么好笑,它會告訴你原因,并且它說的還是對的。我認為,在視覺部分,它就像真的可以看到那些圖像。你用一些復雜的圖像或圖表來追問它問題,然后得到解釋,這非常酷。
但總的來說,我已經從事這項工作很長時間了,實際上幾乎整整20年了。最讓我感到驚訝的是,它真的運行起來了。它似乎一直以來對人們來說都是個小事,但它現在不再渺小,變得更重要、更強烈。
它還是那個神經網絡,只是變得更大,在更大的數據集上,以不同的方式訓練,但訓練的基礎算法都是一樣的,這是最令我驚訝的。
每當我回顧時,我就會想,這些概念性想法怎么可能呢?大腦有神經元,也許人工神經元也一樣好,我們可能只需要用某種學習算法對它們進行訓練。那些論點竟然如此正確,這本身就是最大的驚喜。
黃仁勛:在我們相識的十年里,你訓練的模型和數據量,從你在 AlexNet 上所做的工作到現在,增加了約100萬倍。在計算機科學界,沒有人會相信在這十年間,計算量會擴大100萬倍。并且你的整個職業生涯都致力于此,你有兩個開創性的研究成果,早期的 AlexNet 和現在 OpenAI 的GPT,你所取得的成就真了不起。很高興能再次與你進行思想上的碰撞,我的朋友 Ilya,這是一個相當美妙的時刻,今天的對話,你將問題抽絲剝繭,逐一解釋。這是最好的博士學位之一,除了博士學位,你還描述了大型語言模型的最新技術水平。我真的很感激,很高興見到你,恭喜你,非常感謝你。
智愿君:讓我們繼續解讀老黃和Ilya爐邊談話的第五六段對話(也就是本系列的終章),這一段主要是探討對ChatGPT未來的暢想。那么老黃和Ilya談話中哪些細節值得我們去關注呢?
AI 能否自己訓練自己?
老黃的這個問題提得蠻尖銳的。而Ilya并未展開回答這個問題。我覺得這個問題我們要回顧一下神經網絡的發展歷史:
從20世紀40年代至今,神經網絡經歷了三次浪潮。
-
-
第一次浪潮指的是早期的控制論,其核心是邏輯主義。這一潮流始于1943年,由美國著名的神經生物學家沃倫·麥卡洛克(Warren McCulloch)和數學家沃爾特·皮茨(Walter Pitts)提出了麥卡洛克-皮茨神經元模型(McCulloch-Pitts neuron model)。感知機和自適應線性單元是最典型的成果。感知機是一種學習權重的模型,根據每個類別的輸入樣本來學習。自適應線性單元則是用函數f(x)本身的值來預測一個實數。第一次浪潮的主要限制是過于理想化的數學模型和機械邏輯論,希望通過符號演算(邏輯門)的方法推理和計算。這種方式過于簡單,無法真正解決現實生活中復雜的問題,并且不具備靈活度,可以說是一個大號的計算器。
-
第二次浪潮是在20世紀80年代到90年代出現的聯結主義(connectionism),又稱為并行分布處理(parallel distributed processing)。聯結主義的指導性啟示和主要靈感來自大腦或神經系統,將認知看成是網絡的整體活動。中心思想是,當網絡將大量簡單的計算單元連接在一起時,可以實現智能行為。1982年,生物物理教授霍普菲爾德提出了一種新的神經網絡,可以解決一大類模式識別問題,還可以給出一類組合優化問題的近似解。1986年,David Rumelhart和Geoffery Hinton發展了神經網絡反向傳播學習算法Back Propagation,延展出來的分布式表示、長短期記憶以及新認知機成為了卷積網絡的基礎。聯結主義在許多領域得到了廣泛應用,如模式識別、手寫文字識別、字符識別和簡單的人臉識別。但是,應對復雜問題時聯結主義的表現力不夠強大。第二次浪潮的衰退主要限制是算力跟不上,受限硬件計算能力和互聯網的并行處理能力。
-
第三次浪潮是基于互聯網大數據和GPU的深度學習的突破。2006年,加拿大CIFAR的Geoffrey Hinton和其他附屬研究小組使用一種稱為貪婪逐層預訓練的策略來有效地訓練深度網絡。這標志這現在有能力訓練以前不可能訓練的比較深的神經網絡。此時的深度神經網絡已經優于與之競爭的基于其他機器學習技術以及手工設計功能的 AI 系統。(參見前文我們提到在ImageNet上的奪冠)。第三次浪潮的驅動力就是:推進通用人工智能(強人工智能),并探索超人工智能。不僅僅是通過硬件的升級,更是通過大數據的積累和GPU的高性能計算,使得深度學習的模型和算法得到了極大的提升,廣泛應用于語音識別、自然語言處理、圖像和視頻識別等領域。例如,深度神經網絡在計算機視覺領域的應用,如人臉識別、物體檢測、圖像分割等任務中,已經達到了人類水平甚至超越了人類。同時,深度學習還帶來了很多新的技術突破,例如生成對抗網絡(GAN)、變分自編碼器(VAE)、殘差網絡(ResNet)、注意力機制(Attention)等等。與此同時,深度學習也面臨著很多挑戰和問題。例如,深度學習算法需要大量的訓練數據和計算資源,而且很難解釋其內部的決策過程;深度學習模型容易受到對抗性攻擊和過擬合等問題的影響;深度學習的可解釋性和公平性等問題也需要進一步研究解決。
-
而回到剛才的問題就是自己訓練自己,也就是自我學習能力,是通用人工智能的標志之一。所以老黃問出這個問題,還是挺有深意的。
那么為什么Ilya回避了對這個問題的回答,我覺得大概率是兩點原因:
-
-
Ilya清楚這是一個敏感話題。他如果過度贊許AI自己訓練自己的能力,會增加AI發展不受控的社會恐慌。從近期Geoffrey Hinton 宣布辭去 Google 的職務,并稱自己現在對自己畢生的工作感到后悔這件事上,就能說明問題。Geoffrey Hinton對人工智能領域的發展所帶來的風險感到擔憂,并為人類敲響警鐘。
-
Ilya明白,確實在使用這種AI自己訓練自己的方式,但是效果有待觀察為什么這么說呢?因為自我訓練,可能會無法準確評估訓練模型的性能和魯棒性。人類的信息有很多,有些信息是正確信息,有些是錯誤信息。有些信息帶有明顯的惡意或者邏輯漏洞。如果不分青紅皂白,讓AI自己去訓練自己,可能會在訓練數據這個環節就會失控,因為“臟”數據,自然不會學出一個理想的模型和能力沉淀。在機器學習中,訓練數據的質量對最終模型的表現和準確性有著非常重要的影響。如果訓練數據集中包含了大量的錯誤數據、噪聲數據或者惡意數據,那么最終的模型可能會受到這些數據的干擾,表現不如預期甚至出現偏差和過擬合等問題。因此,在選擇訓練數據時,需要盡量篩選和清洗出具有代表性和高質量的數據,從而提高模型的表現和泛化能力。另外,對于AI自我訓練自己這一過程,需要設計合理的學習策略和算法,以避免模型的學習過程受到“臟”數據的影響。例如,在訓練過程中可以引入監督信號或者其他的先驗知識,以引導模型學習正確的知識和規律。同時,在評估模型的表現時,也需要引入合理的評估標準和指標,以評估模型的性能和泛化能力。
-
所以,我總結一下這個問題的答復應該是:1. AI可以自己訓練自己;2. 結果難與保證,所以有待觀察,或者需要人工干預。
如何看到AI系統的置信度
在對話里,Ilya拋出來一個疑問:讓AI去總結長文檔,獲取摘要。但如何確定重要的細節沒被忽略嗎?
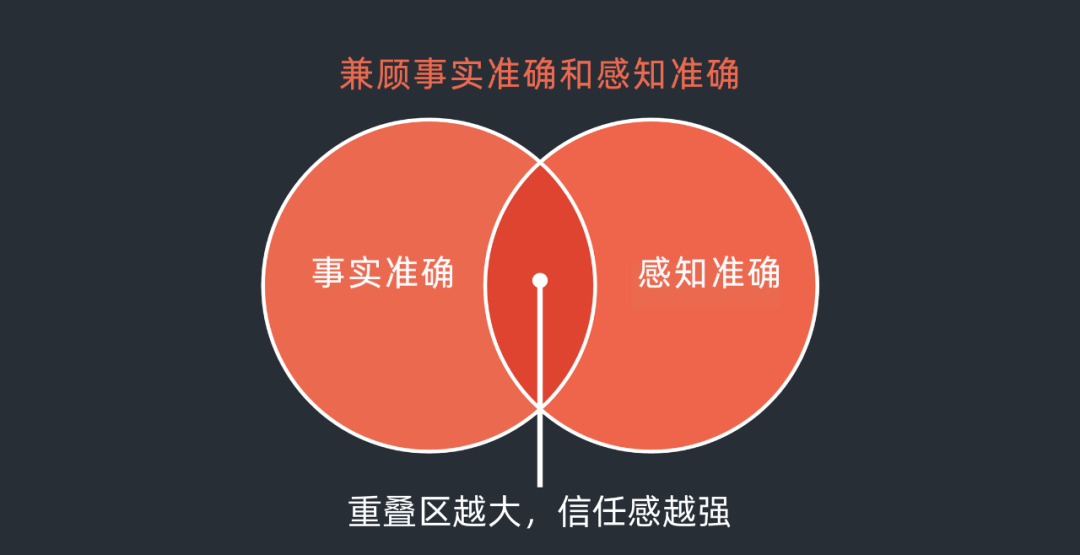
其實回答這個問題是一個置信度的平衡問題。對于到底總結是否準確或者是否有遺漏,我覺得分為兩類。一種是事實準確,一種是感知準確。前者是大模型本身通過深度學習技術和數據集的完備性來保障的,當然也和人工強化學習和調優等有關。后者是使用者的心理置信度,不管準確與否,我信任你。這兩種準確有交集,如果兩個交集越大就表明大模型的置信度能力越符合使用者的心理預期,信任感也就越容易建立。如果交集很少,使用者的產品信任度會逐漸降低,并最后放棄使用。這種邏輯在自動駕駛的事實安全和感知安全上也可以通用。
拿Ilya舉的總結長文摘要的例子。不同人總結,肯定也會有千差萬別。有的人總結詳細一點兒,有的人總結簡約一點兒。有的人偏重文章的某一方面,有些人偏重文章的另外一個方面。而且,往往業務需求不同,總結也會不一樣,比如從財務角度分析,從技術演進的角度分析,從企業創新實踐的角度分析,都會有不同的摘要。所以,對于總結長文摘要,基本上存在兩點:1. 對需求的精準理解,懂得去和使用者進一步交互,去了解對方的期待;2. 不管從哪一個角度的理解,能做到盡可能思考完備,不追求100%準確,因為很可能也不存在標準答案,但是一定要足夠靠譜。
所以對于一個好的AI,回答問題的能力是一方面,懂得向使用者提問,而且能從使用者的答復中再提煉和精準收斂理解用戶的需求,顯得更為重要。會聊天的AI,比單純只回答的AI,要總要得多。相信,這個也應該是ChatGPT未來發展的重點。
訓練AI的數據會耗盡嗎?
如果我們面臨的最終目標是要訓練通用人工智能,或者超人工智能,可能我們會思考如何應對訓練數據可能被耗竭的風險。但正如Ilya回答的那樣,我們不應該低估現有的數據,而且可能有比人們意識到的更多的數據。
這句話也有多層的涵義。
首先,我們不應該低估現有的數據。這是什么意思呢?同樣的訓練數據,如果數據標簽的數量不同,標簽覆蓋的完備性不同,訓練數據的多樣性選擇等等都會對最終結果產生影響。如果處理不當,可能會出現過擬合、梯度消失或梯度爆炸等問題。如果要利用好同一個訓練數據,那么就要通過合理的標注以確保訓練數據的質量和多樣性被體現、同時,神經網絡結構(比如層級)和參數數量的設計、訓練算法和優化技術的選擇等。在這個過程中,需要綜合考慮模型的性能、計算資源、訓練時間、數據質量等多個因素,以達到一個平衡點。也就是說,同樣一個數據集,不同公司來使用,如果標注完備性不夠,網絡結構不合理,參數不合適,訓練算法不夠優秀,都可能會導致差強人意的大模型結果。
其次,可以通過一些技術手段,來優化學習樣本。比如:
-
-
數據增強:通過對現有數據進行擴充和變換,可以生成更多的訓練樣本。例如,可以使用圖像增強技術對圖像數據進行旋轉、平移、縮放等變換,或者使用文本增強技術生成近義詞、反義詞等變換文本數據。
-
跨任務遷移學習:在某些情況下,可以利用先前訓練好的模型和數據來提高新模型的性能。這種方法稱為遷移學習。通過使用遷移學習,可以將模型從一個任務轉移到另一個任務,從而減少對大量數據的需求。
-
數據共享:在某些情況下,可以考慮共享學習的數據庫,做一定程度但拉通。例如通過共享數據集或與其他機構或組織合作共同收集數據,以充分利用可用資源。
-
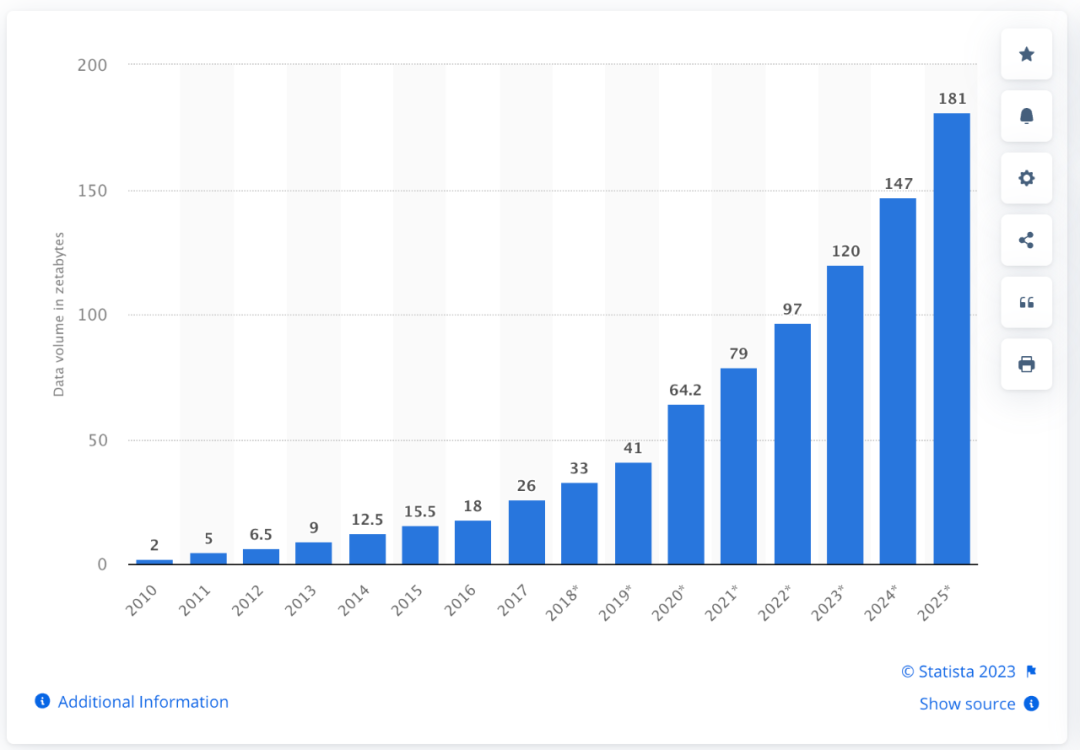
最后,要實時跟進,人們產生的數據的步伐。人類的知識是一直不停地迭代和更新的。根據Statista 2023年的統計,今年的互聯網上的數據量,已經是2021年的一倍。所以這種數據擴張的幅度和增長曲線是指數級的。而且現在數據的形態也在發生變化。除了文本之外,視頻、音頻,3D等形態的數據也在日益增長。所以,不要輕言訓練數據耗盡,這種情況基本上不會出現。
GPT-4,到底是什么?
在老黃和Ilya談話的過程中,其實聊了很多的GPT-4。但到底什么是GPT-4,它和之前的版本到底有什么不同?
首先,就是準確率的大幅提升。在本期談話中,Ilya談到了它回答錯誤率大幅度降低了。降低到什么水平呢?OpenAI提供的文檔報告稱,GPT-4-launch的錯誤行為率為0.02%,遠低于GPT-3.5的0.07%和GPT-3的0.11%。這意味著GPT-4-launch生成的文本在10000次完成中只有2次違反OpenAI的內容政策或用戶偏好。GPT-4雖然已經具備解物理題的能力,但畢竟不是專門的解題算法,一些復雜的數理問題對話中仍會出現一本正經胡說八道的情況。但是如果我們理解GPT的機制,就應該明白準確率再提升,也無法做到100%的準確。由于大模型(包括GPT-4)本質上可以視為訓練集(人類知識/語言)的有損壓縮,因此在模型運行時無法完整復現或者應答原始知識,從而模型的幻覺來自于信息壓縮的偏差。多模態幻覺的本質是這種有損壓縮偏差的體現,也是通過數學逼近人類語言的必然代價。(類似于壓縮后的圖像邊緣出現不正常的條紋)。
第二,GPT-4如上文說的那樣,是一個多模態的處理能力。已經升級為多模態大語言模型(Multi-modal Large Language Model,MLLM)。Ilya在本期和上期的談話都提到了它如何理解圖像。圖像可以幫助GPT-4實現更好的常識推理性能,跨模態遷移更有利于知識獲取,產生更多新的能力,加速了能力的涌現。這些獨立模態或跨模態新特征、能力或模式通常不是通過目的明確的編程或訓練獲得的,而是模型在大量多模態數據中自然而然的學習到的。量變引發質變。涌現能力的另一個重要表現是模型的泛化能力。在沒有專門訓練過的情況,GPT-4也可以泛化到新的、未知的多模態數據樣本上。這種泛化能力取決于模型的結構和訓練過程,以及數據的數量和多樣性。如果模型具有足夠的復雜性和泛化能力,就可以從原始數據中發現新的、未知的特征和模式。當然,GPT-4涌現出的新能力可能仍有局限性,例如:模型可能產生錯誤的回答,對某些問題缺乏理解,容易受到輸入干擾等。目前認為GPT-4的幻覺與其涌現能力具有相關性。GPT-4的多模態輸入的能力對語言模型至關重要,使得“蘋果”等單純的符號語義擴展為更多的內涵。第一,多模態感知使語言模型能夠獲得文本描述之外的常識性知識。第二,感知與語義理解的結合為新型任務提供了可能性,例如機器人交互技術和多媒體文檔處理。第三,通過感知統一了接口。圖形界面其實是最自然和高效的人機自然交互方式。多模態大語言模型可通過圖形方式直接進行信息交互,提升交互效率。多模態模型可以從多種來源和模式中學習知識,并使用模態的交叉關聯來完成任務。通過圖像或圖文知識庫學習的信息可用于回答自然語言問題;從文本中學到的信息也可在視覺任務中使用。
第三,就是更強的推理能力。GPT-4的思維鏈(Chain of Thought)能讓大眾感覺到語言模型“像人”的關鍵特性。雖然GPT-4這些模型并非具備真正的意識或思考能力,但用類似于人的推理方式的思維鏈來提示語言模型,極大的提高了GPT-4在推理任務上的表現,打破了精調(Fine-tune)的平坦曲線。具備了多模態思維鏈能力的GPT-4模型具有一定邏輯分析能力,已經不是傳統意義上的詞匯概率逼近模型。通過多模態思維鏈技術,GPT-4將一個多步驟的問題(例如圖表推理)分解為可以單獨解決的中間步驟。在解決多步驟推理問題時,模型生成的思維鏈會模仿人類思維過程。這意味著額外的計算資源被分配給需要更多推理步驟的問題,可以進一步增強GPT-4的表達和推理能力。一般認為模型的思維推理能力與模型參數大小有正相關趨勢,一般是突破一個臨界規模(大概62B,B代表10億),模型才能通過思維鏈提示的訓練獲得相應的能力。思維鏈不是隨隨便便就能被訓練出來的。另外也有研究表明,在語言訓練集中加入編程語言(例如Python編程代碼)可提升模型邏輯推理能力。具有思維鏈推理能力的GPT-4模型可用于簡單數學問題、符號操作和常識推理等任務。完成思維鏈的訓練,才算真正拿到了這波大模型AI競技的入場券。
GPT的未來,到底何去何從?
對AI的狂熱追捧的熱度高峰過去后,很多人開始冷靜下來。從一個多月前,包括埃隆馬斯克和蘋果公司聯合創始人史蒂夫沃茲尼亞克在內的一些科技行業人士發表公開信敦促OpenAI停止訓練比GPT-4更強大的人工智能系統。以及最近從谷歌辭去職務的Geoffrey Hinton警示AI 有可能會傷害人類。讓我們從另外一個視角來看到這個問題。
其實關于人工智能是否會危及人類生存的話題,很早就出現了。早在1863 年,小說家塞繆爾·巴特勒 (Samuel Butler)就在《機器中的達爾文》中寫道:“結果只是一個時間問題,但機器將真正統治世界及其居民的時刻將會到來,這是任何真正具有哲學頭腦的人都不會懷疑的。”。卡雷爾·恰佩克(Karel ?apek)在1920年羅森的萬能機器人RUR的喜劇中,第一次引入了機器人的概念,就通過夸張的舞臺故事預言AI接管人類(AI takeover)。AI takeover是一種假設情景,超級智能AI機器人成為地球上主要的智能形式,并從人類手中奪走了地球的控制權。這一概念在后續科幻小說和電影等藝術作品中被廣泛運用。甚至連計算機科學家艾倫·圖靈 (Alan Turing)也曾在1951年一篇題為“智能機械,一種異端理論”的文章中提出:隨著人工智能變得比人類更聰明,它們可能會“控制”世界。
存在風險(“x-risk”)學派認為:人類物種目前支配著其他物種,因為人類大腦具有其他動物所缺乏的一些獨特能力。如果人工智能在一般智能上超越人類,成為“超級智能”,那么人類將難以或無法控制。正如山地大猩猩的命運取決于人類的善意,人類的命運也可能取決于未來機器超級智能的行為。說白一點兒就是,盡管我們在訓練AI的過程中一直在灌輸與人類兼容的價值觀。但是我們無法控制的是機器人是否在認知提升后產生新的邏輯體系和價值判斷體系。道格拉斯·恩格爾巴特 (Douglas Engelbart)在1994年,正式提出“集體智商”(collective IQ)的概念,作為集體智慧的衡量標準。隨著互聯網的普及、大數據和基于深度學習的人工智能的迅猛發展,AI正在朝著集體智慧的方向進化。集體智慧的倫理和強調個體關系的人類的倫理會產生巨大的差別。
前一段時間,我分析過美國國防部DARPA的一些和人工智能相關的項目。其中包括:比如CREATE項目(具有對抗策略的建設性機器學習戰斗Context Reasoning for Autonomous Teaming 的縮寫)、ACK (自適應跨域“殺”網是Adapting Cross-Domain Kill-Webs 的縮寫)等。美國軍方計劃將這項技術應用于戰爭的一些想法確實令人作嘔,且毛骨悚然。這些項目都屬于致命自主武器系統(LAWS) ,也就是通常被稱為“殺手機器人”或者“戰爭機器人”,理論上能夠在沒有人類監督和干擾的情況下瞄準和射擊。而且是物聯網多武器協同作戰。2014年,常規武器公約(CCW)召開了兩次會議。第一個是致命自主武器系統 (LAWS) 專家會議。會議就LAWS 的特別授權,并引起了激烈的討論。許多非政府組織和發展中國家都呼吁預防性地禁止 LAWS。他們根據道義論和后果論推理提出了自己的觀點。人們有“不被機器殺死的權利”。
但一味的擔心,沒有解決方案,也是不對的。早在1941年,作為科幻“三巨頭”之一的艾薩克·阿西莫夫(Isaac Asimov),就在他最著名的作品銀河帝國系列和機器人系列中的一篇短篇小說《Runaround》中,第一次提及”機器人三定律”。這個奠定了機器人倫理的基礎:第一定律:機器人不得傷害人類,或因不作為而讓人類受到傷害。第二定律:機器人必須服從人類給它的命令,除非這些命令與第一定律相沖突。第三定律:只要不違反第一或第二定律,機器人就必須保護自己的存在。但隨著時代的發展,顯然,這個遠遠不夠。2005~2006,由機器人學院協調的Euron項目(The Research EURON Atelier on Roboethics),制作了第一個機器人倫理學路線圖。這里并未給出非常明確的路標,但是書中確實提出了關于機器倫理的各種挑戰、場景、原則和觀點。首次明確提出了在機器人倫理中考慮:“尊嚴、正義、公平、多元化、非歧視、自主權、隱私、利益分享、社會責任以及對生物圈的責任。比爾·希伯德(Bill Hibbard)在2014 年出版的著作《道德人工智能》,談到了他關于人工智能的看法。他認為,由于人工智能將對人類產生如此深遠的影響,人工智能開發人員是未來人類的代表,因此有道德義務在他們的努力中保持透明。因此他主張在人工智能算法和軟件代碼領域要采用開源方式,這是對整個人類負責的表現。而我們知道,從GPT-3開始,OpenAI就不再開源,違背了透明度原則,這也是讓人擔心的原因之一。
默奧大學計算機科學系的教授弗吉尼亞·迪格努姆 (Virginia Dignum) 在2018年3 月出版的《倫理與信息技術》上指出,機器人倫理有三個目標:1. 設計產生的倫理(Ethics by Design),指代倫理算法,是人工智能行為的表現基礎。2. 設計中的倫理(Ethics in Design),指代如何分析和評估設計的機器人是符合倫理的。3. 倫理化設計(Ethics for Design),也就是如何保證開發設計的人員在前期研究、設計、構建的過程中,能確保機器人倫理的實現。2019年,布里斯托爾機器人實驗室的艾倫·溫菲爾德(Alan Winfield)提出,圖靈測試存在缺陷,人工智能通過測試的要求太低。一項替代測試被稱為道德圖靈測試,該測試將通過讓多名法官決定 AI 的決定是否符合道德或不道德來評判機器人,在圖靈測試中增加道德決策的權重。2019年,IEEE推出了自治系統透明度的 IEEE 標準。描述了可測量、可測試的透明度級別,以便可以客觀地評估自治系統,并確定合規級別。不僅僅是標準組織,很多研究人員建議將政府監管作為確保透明度的一種手段,并通過它來確保人類的責任感。經合組織、聯合國、歐盟和許多國家目前正在制定監管人工智能的戰略,并尋找適當的法律框架。但以上肯定還遠遠不夠。
歐洲議會人工智能倫理領域顧問安娜·費蘭德近日表示:人類已走到了關鍵的十字路口。在人工智能野蠻生長的當下,沒有一致的立法監管,人工智能在實踐層面會面臨諸多挑戰。當前世界需要對人工智能采取倫理學上的切實有效的考量。
過去這半年時間,仿佛世界一下子翻了一個個。以前從來不相信通用人工智能的人,都開始擔心那個曾經被雷·庫茲韋爾(Ray Kurzweil)預測的2045年的奇點,會不會提前到來,甚至會不會突然的“智能爆炸”讓毫無準備的人類措手不及。所以,這種警覺的狀態已經讓大多數人行動起來,樂觀來看,這應該是值得欣慰的變化。
好了,今天我們先解讀到這里。關于英偉達的創始人兼CEO黃仁勛("Jensen" Huang)與OpenAI的聯合創始人兼首席科學家伊爾亞-蘇茨克維(Ilya Sutskever )的“爐邊談話”,我們一共花了六期來解讀,今天是終篇。解讀的觀點肯定存在片面和偏僻,歡迎大家批評指正。
<本系列完>
-
開源技術
+關注
關注
0文章
389瀏覽量
7978 -
OpenHarmony
+關注
關注
25文章
3744瀏覽量
16469
原文標題:河套IT TALK 77: (原創) 解讀老黃與Ilya的爐邊談話系列之六——ChatGPT未來將走向何方(萬字長文)
文章出處:【微信號:開源技術服務中心,微信公眾號:共熵服務中心】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
單日獲客成本超20萬,國產大模型開卷200萬字以上的長文本處理

【6千字長文】車載芯片的技術沿革與趨勢分析


NVIDIA助力企業用AI創建數據飛輪
解讀 MEMS 可編程 LVCMOS 振蕩器 SiT1602 系列:精準頻率的創新之選

解讀 MEMS 可編程 LVCMOS 振蕩器 SiT8008 系列:精準與靈活的時脈之選

NVIDIA CEO 黃仁勛對話 Meta CEO 馬克·扎克伯格:創作者將擁有個性化的 AI 助手

萬字長文淺談系統穩定性建設
奇異摩爾攜手SEMiBAY Talk 邀您暢談互聯與計算

MiniMax推出“海螺AI”,支持超長文本處理
OpenAI聯合創始人Ilya Sutskever宣布離職
黃仁勛工資多少錢?黃仁勛薪酬大漲到3420萬美元
阿里通義千問重磅升級,免費開放1000萬字長文檔處理功能
“單純靠大模型無法實現 AGI”!萬字長文看人工智能演進






 工商網監
工商網監
評論