 什么樣的模型更適合zero-shot?
什么樣的模型更適合zero-shot?
什么樣的模型更適合zero-shot?
對于模型架構,不同的論文有不同的分發,不同的名稱。我們不必糾結于稱謂,在這里我們延續BigScience的概念來討論,即:
- 架構:自回歸、非自回歸、編碼器-解碼器
- 目標:全語言模型、前綴語言模型、掩碼語言模型
- 適配器:不添加適配器、將自回歸模型用于掩碼目標訓練的適配器、將掩碼為目標的模型轉化為純語言模型目標
- 是否經過多任務微調
- 評估數據集:EAI-Eval、T0-Eval
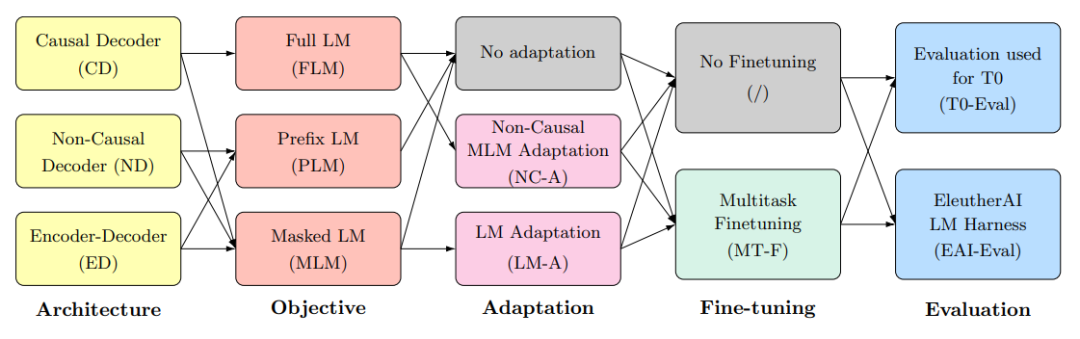
BigScience有兩項重要的結論,但這兩項結論是在控制預訓練的預算的基礎上的,而非控制參數量。如此實驗編碼器-解碼器用了11B參數量,而純解碼器卻是4.8B。
- 如果不經過多任務微調,自回歸模型最好,掩碼語言模型跟隨機結果一樣。
- 如果經過多任務微調,編碼器-解碼器掩碼模型最好【這參數量都翻倍了,很難說不是參數量加倍導致的】。換個角度想,在多任務微調之后,自回歸全語言模型在參數量不到編碼器-解碼器掩碼模型一半,計算量還少10%的情況下,效果還能差不多。
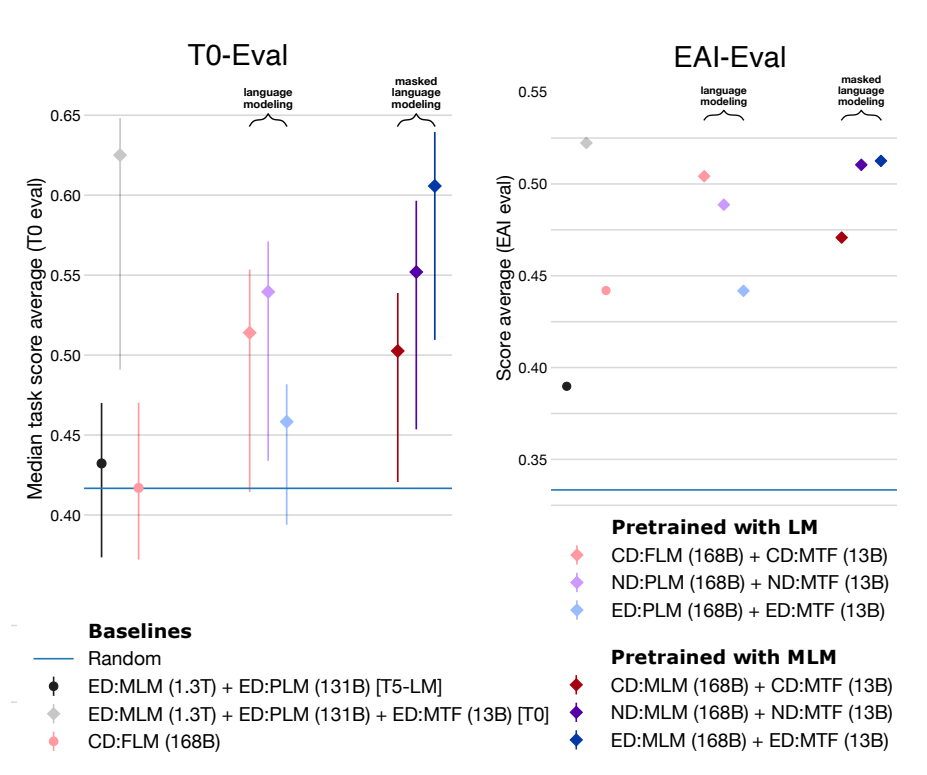
來自科學空間的對比實驗【https://spaces.ac.cn/archives/9529】更是印證了這一點:
在同等參數量、同等推理成本下,Decoder-only架構很可能是最優選擇。
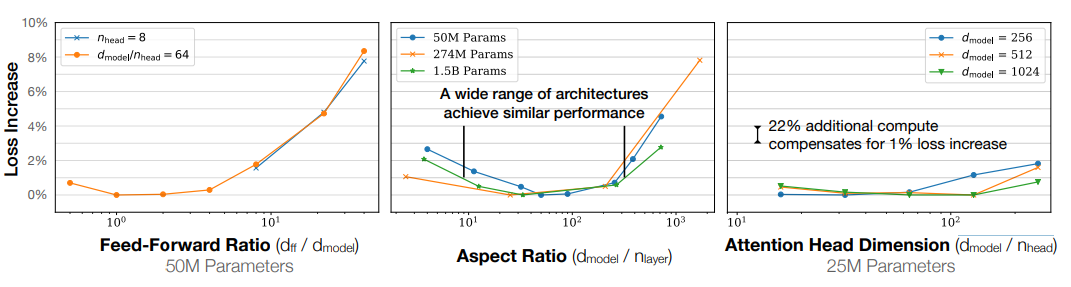
效果和模型形狀有沒有關系
在openAI的實驗中,通過控制參數量,分別調整模型形狀的三個指標前饋維度比、寬高比、注意力頭維度,實驗表明,模型形狀對性能的依賴非常輕微。
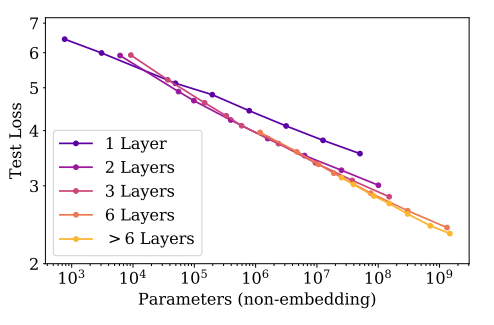
單獨研究層數,排除嵌入層的影響,除了一層這種極端情況之外,同樣參數下,不同的層數傾向于收斂于同樣的損失。
到底需要多少數據訓練
在GPT-3中參數數據比約為1:1.7,而Chinchilla是為1:20。然而GPT-3參數量是Chinchilla的2.5倍,下游任務卻大范圍地輸給了Chinchilla。再看LLaMA就更離譜了約為1:77,只有13B參數量很多任務就超越了GPT-3。這是不是和咱公眾號名字很符合:【無數據不智能】,海量高質量數據才是王道。
| Model | Parameters | Training Tokens |
|---|---|---|
| LaMDA (2022) | 137 Billion | 168 Billion |
| GPT-3 (2020) | 175 Billion | 300 Billion |
| Jurassic (2021) | 178 Billion | 300 Billion |
| Gopher (2021) | 280 Billion | 300 Billion |
| MT-NLG 530B (2022) | 530 Billion | 270 Billion |
| Chinchilla(202) | 70 Billion | 1.4 Trillion |
| LLaMA(202) | 13 Billion | 1.0 Trillion |
批次大小設置為多少好
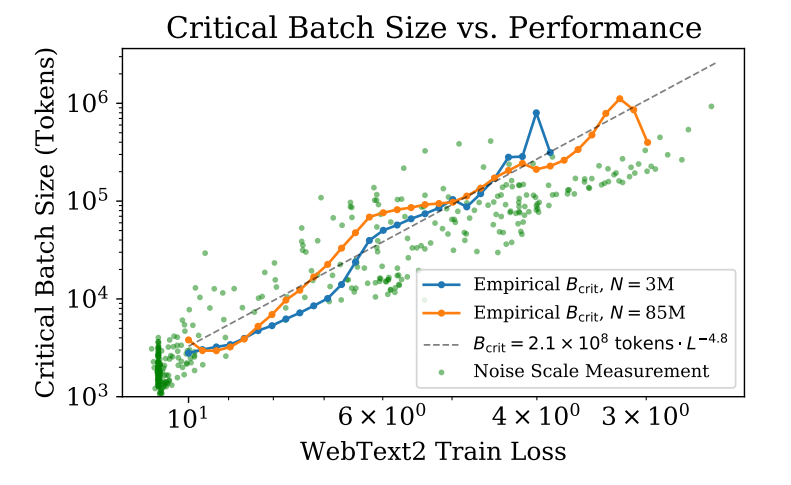
【Scaling Laws for Neural Language Models】實驗中表明batch size和模型大小無關,只和想達到的loss有關(冪次關系),同時也受到噪聲數據的影響。
學習率多大合適
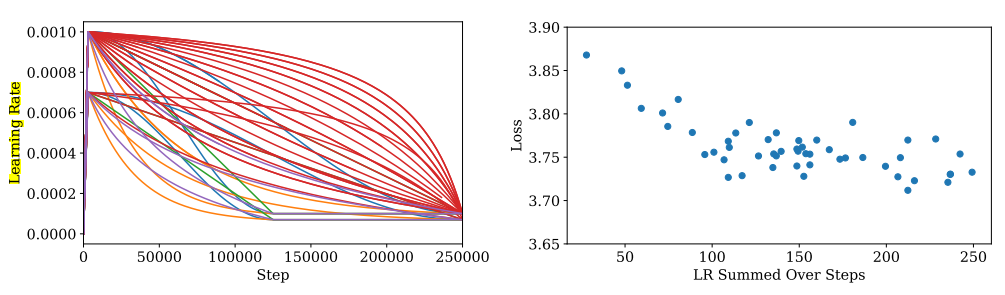
- 只要學習率不是太小,衰減不是太快,性能對學習率的依賴性并不強。
- 較大的模型需要較小的學習率來防止發散,而較小的模型可以容忍較大的學習率。
- 經驗法則:LR(N) ≈ 0.003239 ? 0.0001395log(N),N:模型參數量
參數量、數據量、訓練時長和loss什么關系
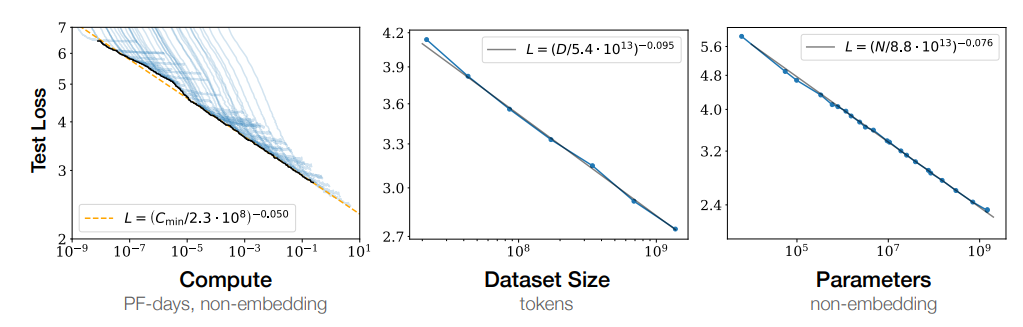
參數量、數據量、訓練時長和loss都存在冪指數關系
審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1144瀏覽量
40835 -
編碼器
+關注
關注
45文章
3655瀏覽量
134894 -
模型
+關注
關注
1文章
3279瀏覽量
48976
原文標題:引用
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于將 CLIP 用于下游few-shot圖像分類的方案
震動環境下適合用什么樣的液晶屏
請問GTR的雙晶體管模型是什么樣的?
NLP事件抽取綜述之挑戰與展望
Zero-shot-CoT是multi-task的方法
基于Zero-Shot的多語言抽取式文本摘要模型
介紹一個基于CLIP的zero-shot實例分割方法
從預訓練語言模型看MLM預測任務
基于GLM-6B對話模型的實體屬性抽取項目實現解析
大模型LLM領域,有哪些可以作為學術研究方向?

邁向多模態AGI之開放世界目標檢測
基于通用的模型PADing解決三大分割任務

為什么叫shot?為什么shot比掩膜版尺寸小很多?

基于顯式證據推理的few-shot關系抽取CoT





 工商網監
工商網監
評論