") 目標(biāo)跟蹤新的建模方式
目標(biāo)跟蹤新的建模方式
如果模型知道目標(biāo)在哪,那么我們只需要教模型讀出目標(biāo)的位置,而不需要顯式地進(jìn)行分類、回歸。對于這項工作,研究者們希望可以啟發(fā)人們探索目標(biāo)跟蹤等視頻任務(wù)的自回歸式序列生成建模。 自回歸式的序列生成模型在諸多自然語言處理任務(wù)中一直占據(jù)著重要地位,特別是最近ChatGPT的出現(xiàn),讓人們更加驚嘆于這種模型的強(qiáng)大生成能力和潛力。 最近,微軟亞洲研究院與大連理工大學(xué)的研究人員提出了一種使用序列生成模型來完成視覺目標(biāo)跟蹤任務(wù)的新框架SeqTrack,來將跟蹤建模成目標(biāo)坐標(biāo)序列的生成任務(wù)。目前的目標(biāo)跟蹤框架,一般把目標(biāo)跟蹤拆分為分類、回歸、角點(diǎn)預(yù)測等多個子任務(wù),然后使用多個定制化的預(yù)測頭和損失函數(shù)來完成這些任務(wù)。而SeqTrack通過將跟蹤建模成單純的序列生成任務(wù),不僅擺脫了冗余的預(yù)測頭和損失函數(shù),也在多個數(shù)據(jù)集上取得了優(yōu)秀的性能。
1.新的目標(biāo)跟蹤框架,將跟蹤建模為序列生成任務(wù),一個簡潔而有效的新基線;
2.摒棄冗余的預(yù)測頭和損失函數(shù),僅使用樸素的Transformer和交叉熵?fù)p失,具有較高的可擴(kuò)展性。
一 、研究動機(jī)
現(xiàn)在比較先進(jìn)的目標(biāo)跟蹤方法采用了“分而治之”的策略,即將跟蹤問題解耦成多個子任務(wù),例如中心點(diǎn)預(yù)測、前景/背景二分類、邊界框回歸、角點(diǎn)預(yù)測等。盡管在各個跟蹤數(shù)據(jù)機(jī)上取得了優(yōu)秀的性能,但這種“分而治之”的策略存在以下兩個缺點(diǎn):
1、模型復(fù)雜:每個子任務(wù)都需要一個定制化的預(yù)測頭,導(dǎo)致框架變得復(fù)雜,不利于擴(kuò)展
2、損失函數(shù)冗余:每個預(yù)測頭需要一個或多個損失函數(shù),引入額外超參數(shù),使訓(xùn)練困難
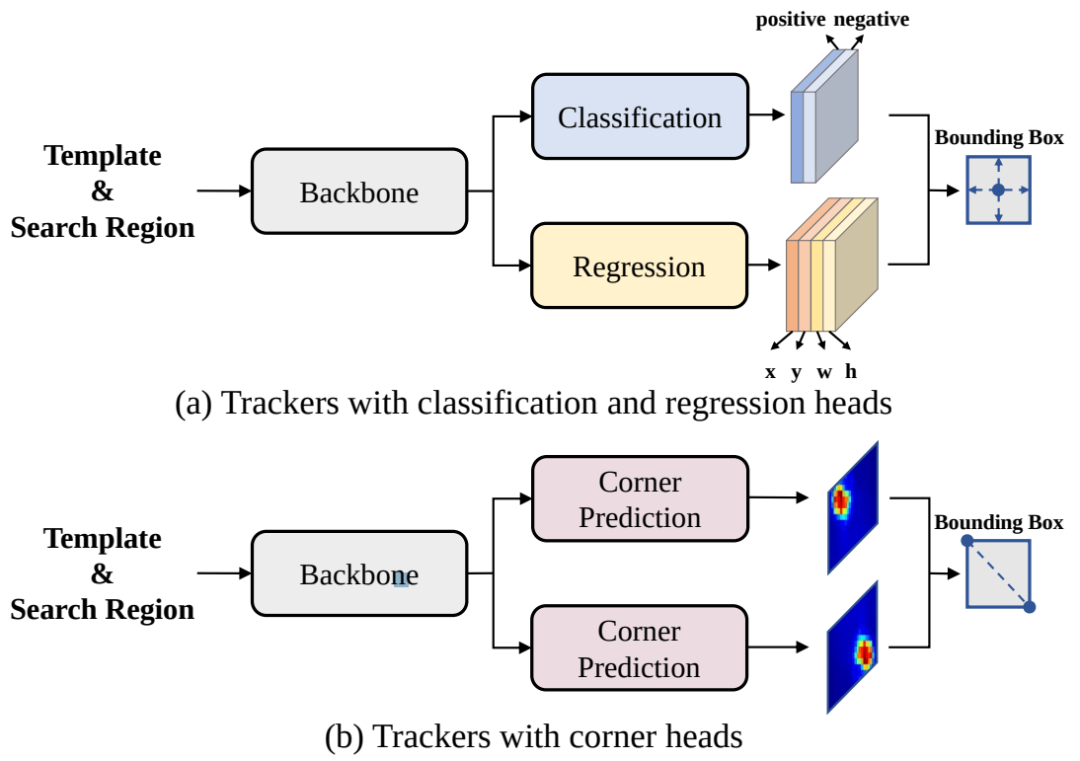
圖1 目前常見的跟蹤框架
研究者認(rèn)為,如果模型知道目標(biāo)在圖像中的位置,那么只需要簡單地教模型讀出目標(biāo)邊界框即可,不需要用“分而治之”的策略去顯式地進(jìn)行分類和回歸等。為此,作者采用了自回歸式的序列生成建模來解決目標(biāo)跟蹤任務(wù),教模型把目標(biāo)的位置作為一句話去“讀”出來。
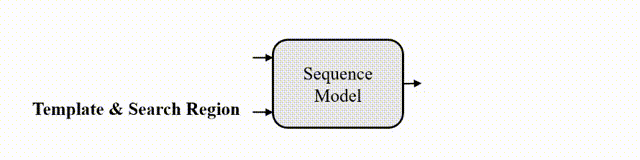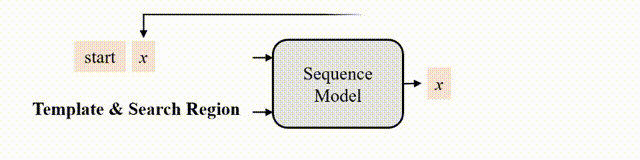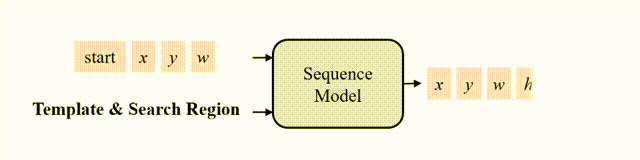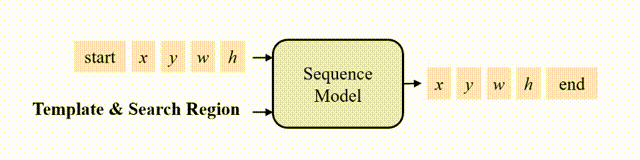
圖2 跟蹤的序列生成建模
二、方法概覽
研究者將目標(biāo)邊界框的四個坐標(biāo)轉(zhuǎn)化為由離散值token組成的序列,然后訓(xùn)練SeqTrack模型逐個token地預(yù)測出這個序列。在模型結(jié)構(gòu)上,SeqTrack采用了原汁原味的encoder-decoder形式的transformer,方法整體框架圖如下圖3所示:
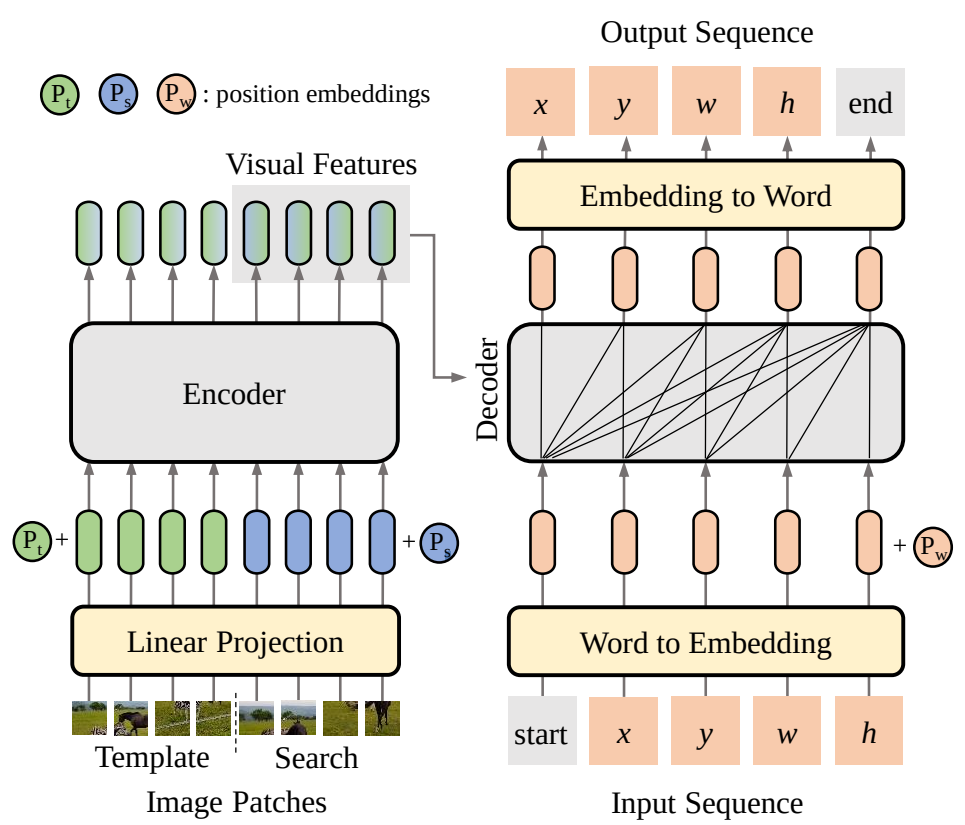
圖3 SeqTrack結(jié)構(gòu)圖
Encoder提取模板與搜索區(qū)域圖片的視覺特征,decoder參考這些視覺特征,完成序列的生成。序列包含構(gòu)成邊界框的 x,y,w,h token,以及兩個特殊的 start 和 end token,分別表示生成的開始與結(jié)束。 在推理時,start token告知模型開始生成序列,然后模型依次生成 x,y,w,h ,每個token的生成都會參考前序已生成好的token,例如,生成 w 時,模型會以 [start, x, y] 作為輸入。當(dāng) [x,y,w,h] 生成完,模型會輸出end token,告知用戶預(yù)測完成。 為了保證訓(xùn)練的高效,訓(xùn)練時token的生成是并行的,即 [start, x,y,w,h] 被同時輸入給模型,模型同時預(yù)測出 [x,y,w,h, end] 。為了保證推理時的自回歸性質(zhì),在訓(xùn)練時對decoder中的自注意力層中添加了因果性的attention mask,以保證每個token的預(yù)測僅取決于它前序的token,attention mask如下圖4所示。
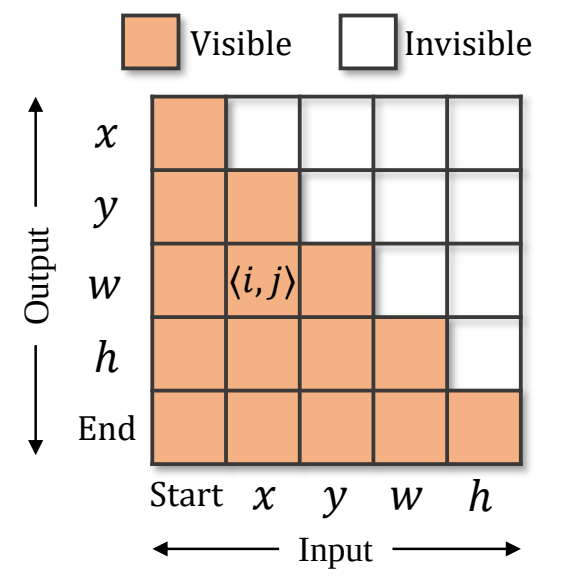
圖3 Attention mask,第 i 行第 j 列的橘色格子代表第生成第 i 個輸出token時,允許觀察到第 j 個輸入token,而白色格子代表不可觀察。
圖像上連續(xù)的坐標(biāo)值被均勻地離散化為了[1, 4000]中的整數(shù)。每個整數(shù)可以被視為一個單詞,構(gòu)成了單詞表 V ,x,y,w,h 四個坐標(biāo)從單詞表 V 中取值。
與常見的序列模型類似,在訓(xùn)練時,SeqTrack使用交叉熵?fù)p失來最大化目標(biāo)值基于前序token的預(yù)測值、搜索區(qū)域、模板三者的條件概率:
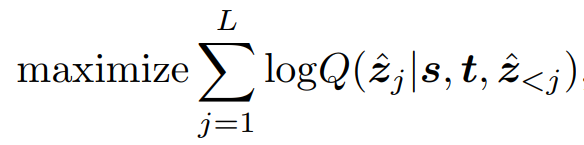
在推理時,使用最大似然從單詞表 V 中為每個token取值:
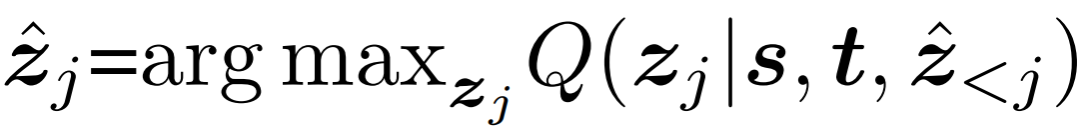
通過這種方式,僅需要交叉熵?fù)p失即可完成模型的訓(xùn)練,大大簡化了復(fù)雜度。 除此之外,研究者們還設(shè)計了合適的方式,在不影響模型與損失函數(shù)的情況下,引入了在線模板更新、窗口懲罰等技術(shù)來集成跟蹤的先驗(yàn)知識,這里不再贅述,具體細(xì)節(jié)請參考論文。
三、實(shí)驗(yàn)結(jié)果
研究者開發(fā)了四種不同大小的模型,以取得性能與速度之間的平衡,并在8個跟蹤數(shù)據(jù)集上驗(yàn)證了這些模型的性能。
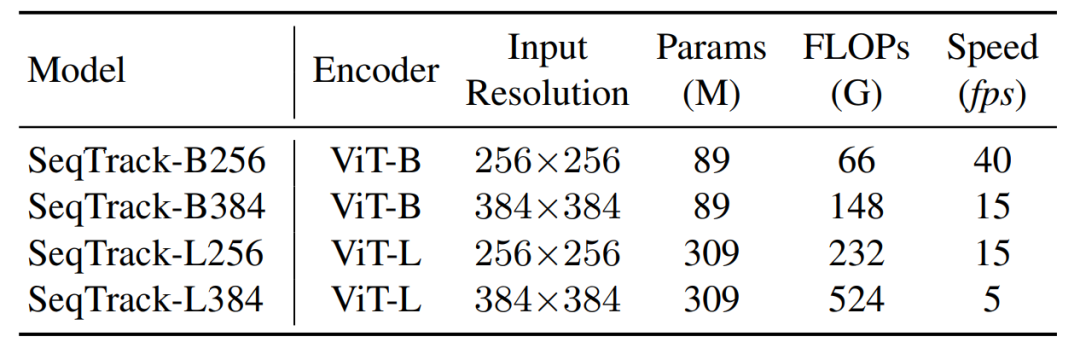
表1 SeqTrack模型參數(shù)
如下表2所示,在大尺度數(shù)據(jù)集LaSOT, LaSOText,TrackingNet, GOT-10k上,SeqTrack取得了優(yōu)秀的性能。例如,與同樣使用ViT-B和256輸入圖片分辨率的OSTrack-256相比,SeqTrack-B256在四個數(shù)據(jù)集上都取得了更好的結(jié)果。
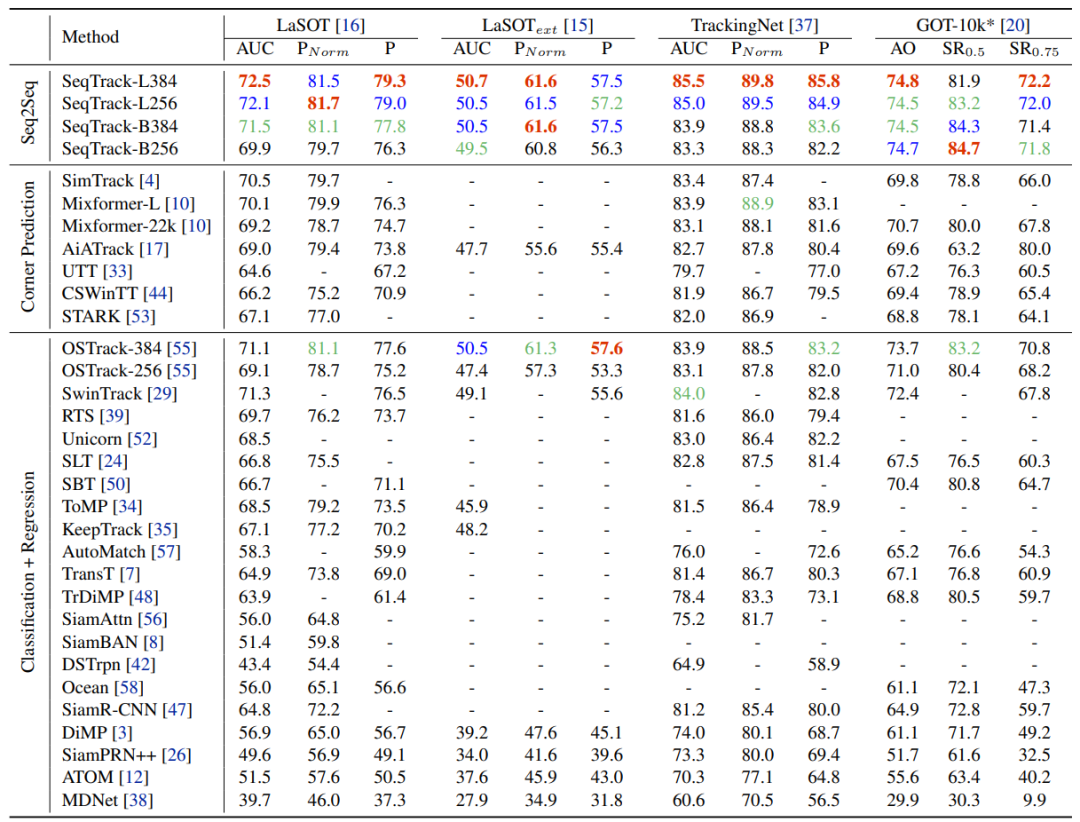
表2大規(guī)模數(shù)據(jù)集性能
如表3所示,SeqTrack在包含多種不常見目標(biāo)類別的TNL2K數(shù)據(jù)集上取得了領(lǐng)先的性能,驗(yàn)證了SeqTrack的泛化性。在小規(guī)模數(shù)據(jù)集NFS和UAV123上也都取得了具有競爭力的性能。
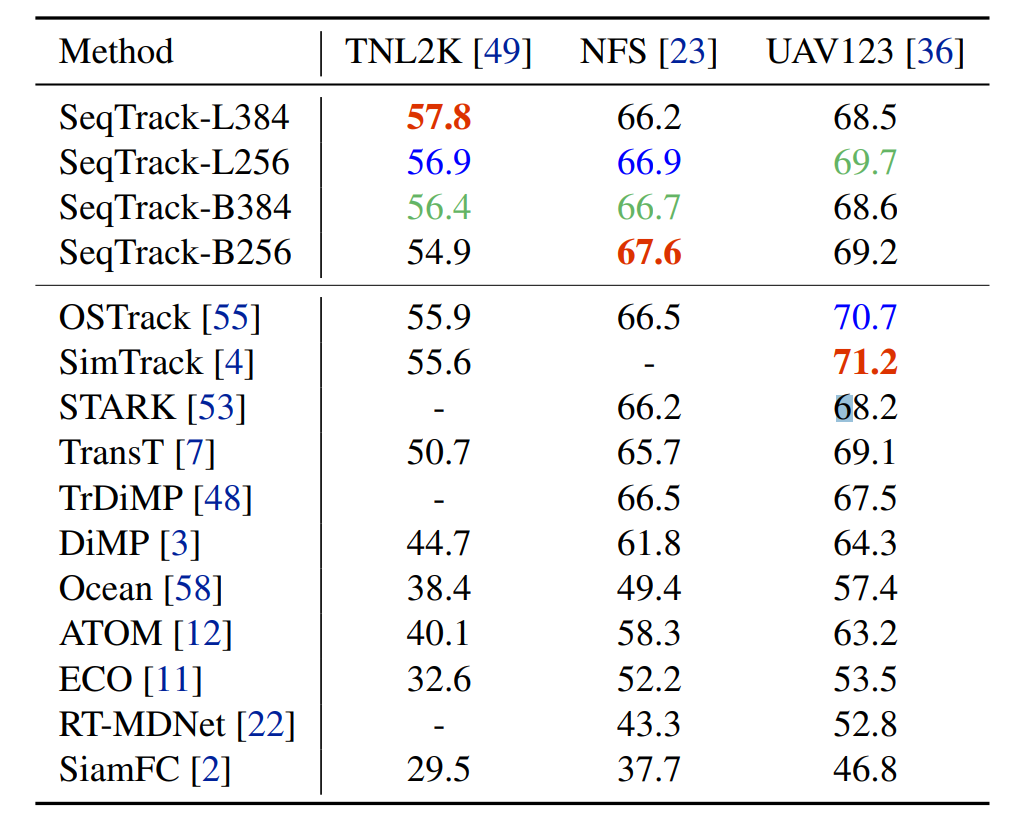
表3額外數(shù)據(jù)集性能
圖4所示,在VOT競賽數(shù)據(jù)集上,分別使用邊界框測試和分割掩膜測試,SeqTrack都取得了優(yōu)秀的性能。
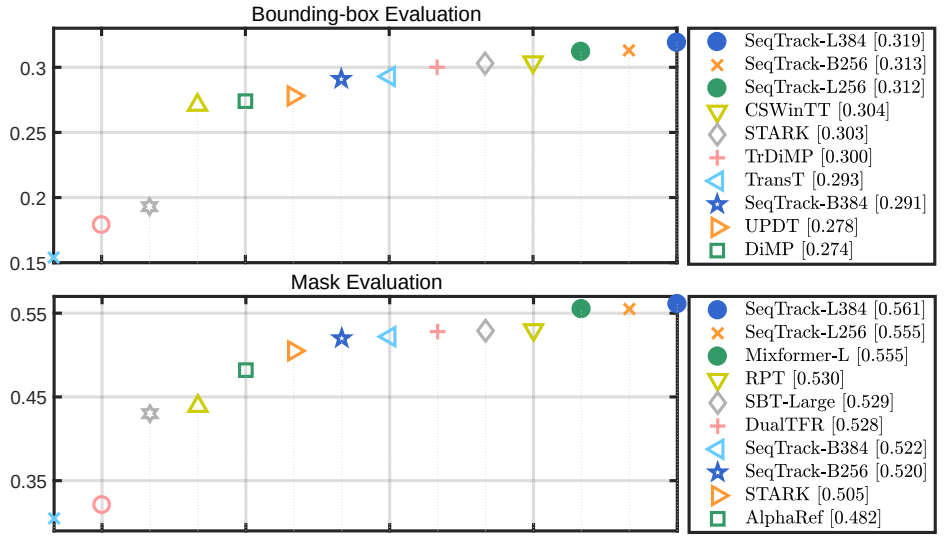
圖4 VOT2020性能
這樣簡單的框架具有良好的可擴(kuò)展性,只需要將信息引入到序列構(gòu)建中,而無需更改網(wǎng)絡(luò)結(jié)構(gòu)。例如,研究者們進(jìn)行了額外的實(shí)驗(yàn)來嘗試在序列中引入時序信息。具體來說,將輸入序列擴(kuò)展到多幀,包含了目標(biāo)邊界框的歷史值。表4顯示這樣的簡單擴(kuò)展提升了基線模型的性能。
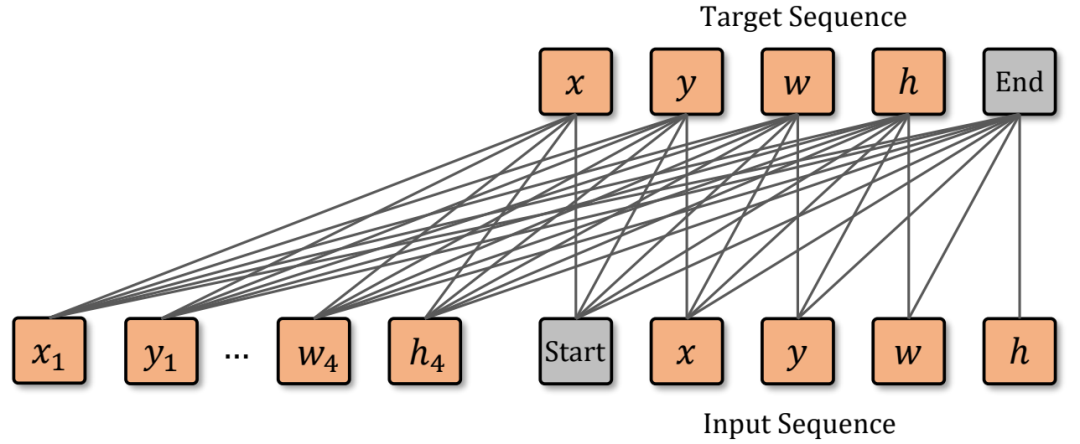
圖5 時序序列示意圖

表4 時序序列結(jié)果
四、結(jié)語
本文提出了目標(biāo)跟蹤的新的建模方式:序列生成式建模。它將目標(biāo)跟蹤建模為了序列生成任務(wù),僅使用簡單的Transformer結(jié)構(gòu)和交叉熵?fù)p失,簡化了跟蹤框架。大量實(shí)驗(yàn)表明了序列生成建模的優(yōu)秀性能和潛力。在文章的最后,研究者希望通過本文給視覺目標(biāo)跟蹤和其他視頻任務(wù)的序列建模提供靈感。在未來工作,研究者將嘗試進(jìn)一步融合時序信息,以及擴(kuò)展到多模態(tài)任務(wù)。
-
建模
+關(guān)注
關(guān)注
1文章
312瀏覽量
60802 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4343瀏覽量
62806 -
Transformer
+關(guān)注
關(guān)注
0文章
145瀏覽量
6026
原文標(biāo)題:CVPR 2023 | 大連理工和微軟提出SeqTrack:目標(biāo)跟蹤新框架
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
視頻跟蹤(目標(biāo)取差器)-基于DM8168實(shí)現(xiàn)的自動視頻跟蹤
視頻跟蹤目標(biāo)跟蹤算法簡介(上海凱視力成信息科技有限...
基于OPENCV的運(yùn)動目標(biāo)跟蹤實(shí)現(xiàn)
無人機(jī)編隊視頻序列中的多目標(biāo)精確跟蹤
目標(biāo)跟蹤中目標(biāo)匹配的特征融合算法研究
基于KCFSE結(jié)合尺度預(yù)測的目標(biāo)跟蹤方法

機(jī)器人目標(biāo)跟蹤
基于融合的快速目標(biāo)跟蹤算法
一種實(shí)時運(yùn)動目標(biāo)檢測與跟蹤算法
如何使用連續(xù)離散問題聯(lián)合求解和群組分析進(jìn)行多目標(biāo)跟蹤技術(shù)研究

基于多尺度自適應(yīng)權(quán)重的目標(biāo)跟蹤算法
視頻目標(biāo)跟蹤分析
最常見的目標(biāo)跟蹤算法
利用TRansformer進(jìn)行端到端的目標(biāo)檢測及跟蹤
目標(biāo)跟蹤初探(DeepSORT)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論