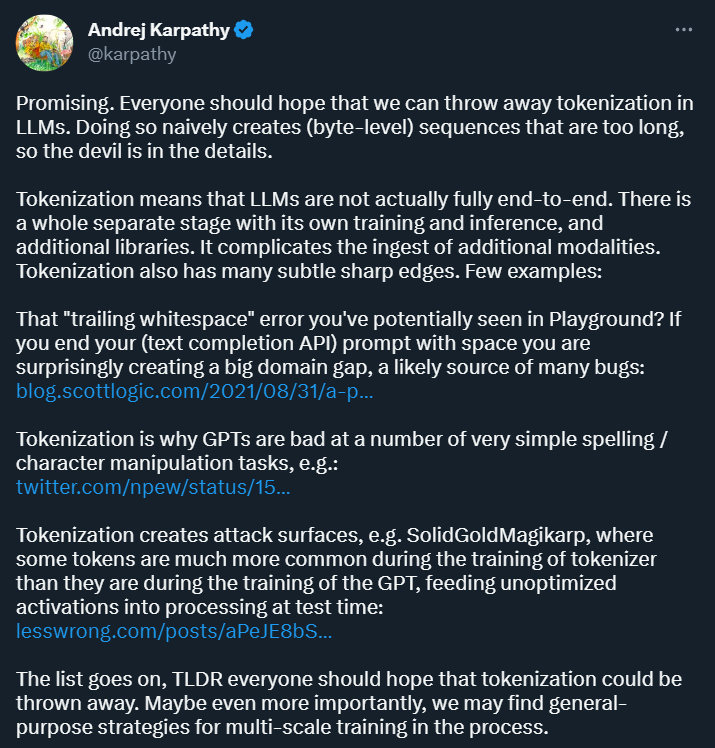
") 一定要「分詞」嗎?Andrej Karpathy:是時候拋棄這個歷史包袱了
一定要「分詞」嗎?Andrej Karpathy:是時候拋棄這個歷史包袱了
是時候拋棄 tokenization 了?ChatGPT 等對話 AI 的出現(xiàn)讓人們習慣了這樣一件事情:輸入一段文本、代碼或一張圖片,對話機器人就能給出你想要的答案。但在這種簡單的交互方式背后,AI 模型要進行非常復雜的數(shù)據(jù)處理和運算,tokenization 就是比較常見的一種。 在自然語言處理領(lǐng)域,tokenization 指的是將文本輸入分割成更小的單元,稱為「token」。這些 token 可以是詞、子詞或字符,取決于具體的分詞策略和任務需求。例如,如果對句子「我喜歡吃蘋果」執(zhí)行 tokenization 操作,我們將得到一串 token 序列:["我", "喜歡", "吃", "蘋果"]。有人將 tokenization 翻譯成「分詞」,但也有人認為這種翻譯會引起誤導,畢竟分割后的 token 未必是我們?nèi)粘K斫獾摹冈~」。


- patch 嵌入器,它通過無損地連接每個字節(jié)的嵌入來簡單地編碼 patch;
- 全局模塊 —— 帶有輸入和輸出 patch 表征的大型自回歸 transformer;
- 局部模塊 —— 一個小型自回歸模型,可預測 patch 中的字節(jié)。
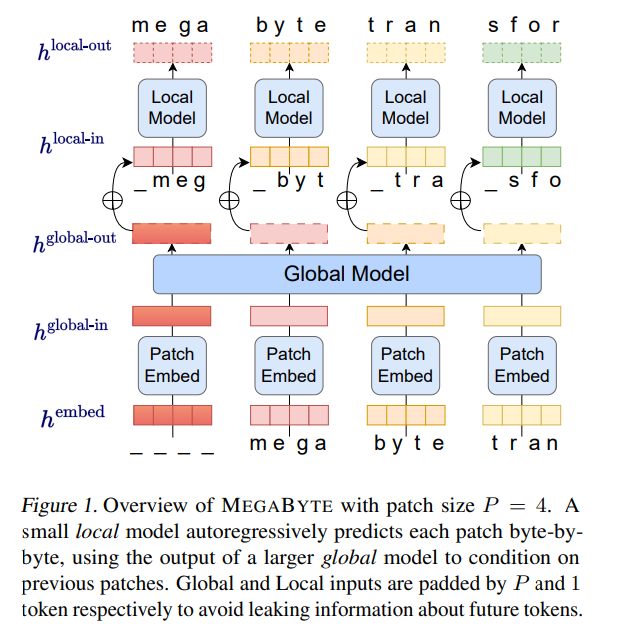
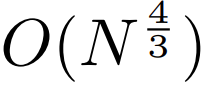 ,即使是長序列也能易于處理。
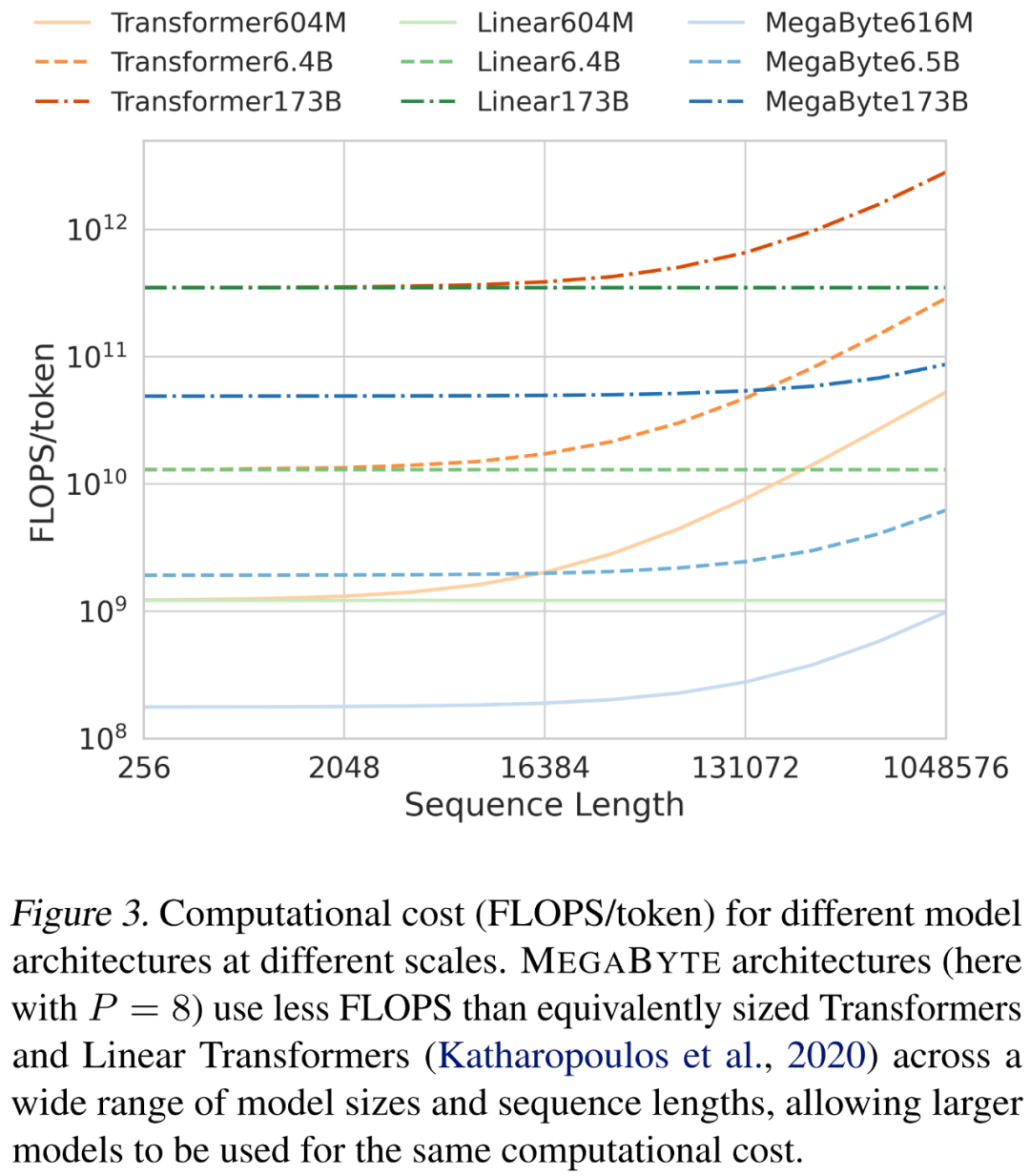
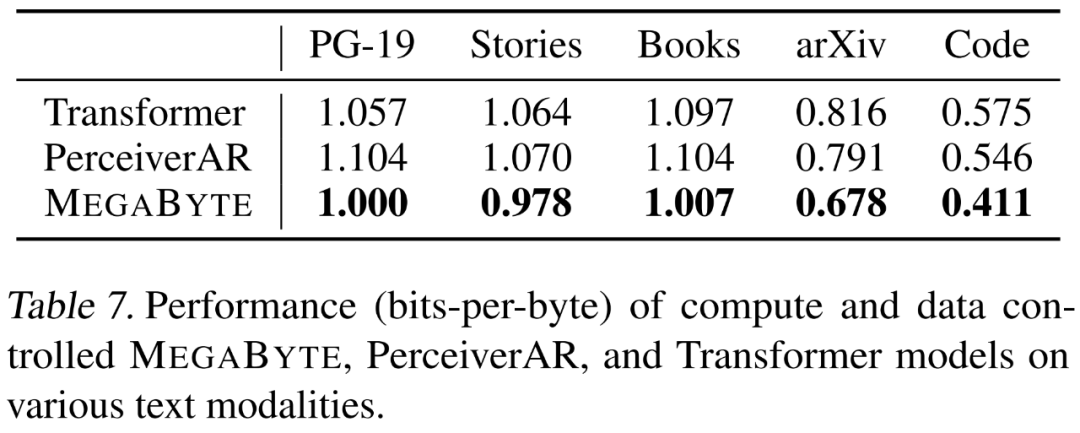
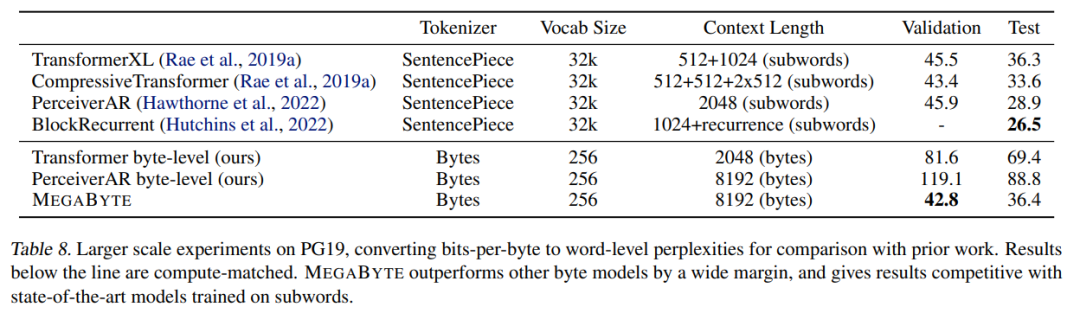
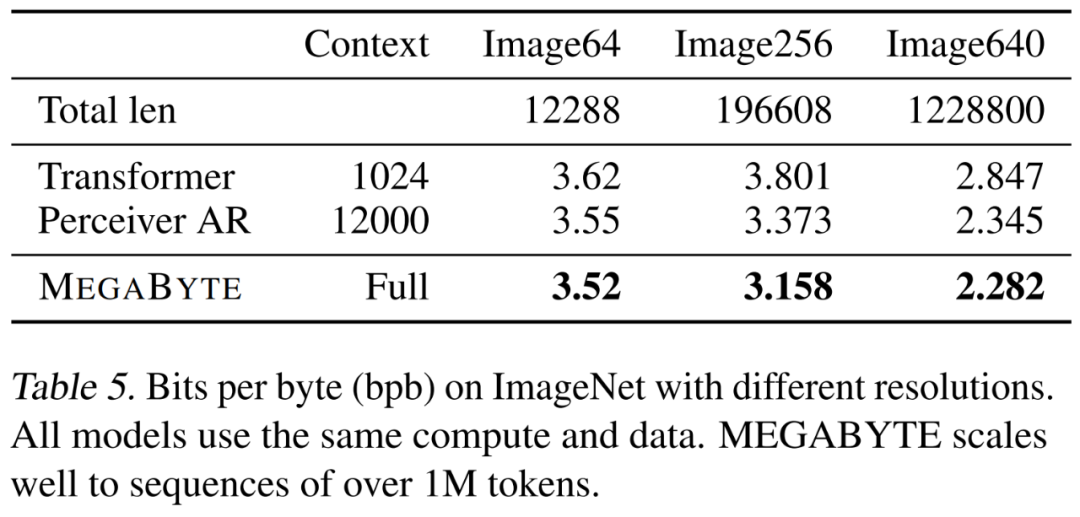
,即使是長序列也能易于處理。2. per-patch 前饋層。在 GPT-3 等超大模型中,超過 98% 的 FLOPS 用于計算 position-wise 前饋層。MEGABYTE 通過給 per-patch(而不是 per-position)使用大型前饋層,在相同的成本下實現(xiàn)了更大、更具表現(xiàn)力的模型。在 patch 大小為 P 的情況下,基線 transformer 將使用具有 m 個參數(shù)的相同前饋層 P 次,而 MEGABYTE 僅需以相同的成本使用具有 mP 個參數(shù)的層一次。 3. 并行解碼。transformer 必須在生成期間串行執(zhí)行所有計算,因為每個時間步的輸入是前一個時間步的輸出。通過并行生成 patch 的表征,MEGABYTE 在生成過程中實現(xiàn)了更大的并行性。例如,具有 1.5B 參數(shù)的 MEGABYTE 模型生成序列的速度比標準的 350M 參數(shù) transformer 快 40%,同時在使用相同的計算進行訓練時還改善了困惑度(perplexity)。 總的來說,MEGABYTE 讓我們能夠以相同的計算預算訓練更大、性能更好的模型,將能夠處理非常長的序列,并提高部署期間的生成速度。 MEGABYTE 還與現(xiàn)有的自回歸模型形成鮮明對比,后者通常使用某種形式的 tokenization,其中字節(jié)序列被映射成更大的離散 token(Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2021) 。tokenization 使預處理、多模態(tài)建模和遷移到新領(lǐng)域變得復雜,同時隱藏了模型中有用的結(jié)構(gòu)。這意味著大多數(shù) SOTA 模型并不是真正的端到端模型。最廣泛使用的 tokenization 方法需要使用特定于語言的啟發(fā)式方法(Radford et al., 2019)或丟失信息(Ramesh et al., 2021)。因此,用高效和高性能的字節(jié)模型代替 tokenization 將具有許多優(yōu)勢。 該研究對 MEGABYTE 和一些強大的基線模型進行了實驗。實驗結(jié)果表明,MEGABYTE 在長上下文語言建模上的性能可與子詞模型媲美,并在 ImageNet 上實現(xiàn)了 SOTA 的密度估計困惑度,并允許從原始音頻文件進行音頻建模。這些實驗結(jié)果證明了大規(guī)模無 tokenization 自回歸序列建模的可行性。 MEGABYTE 主要組成部分

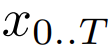 映射成一個長度為
映射成一個長度為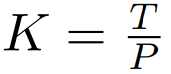 、維度為
、維度為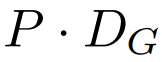 的 patch 嵌入序列。
的 patch 嵌入序列。
首先,每個字節(jié)都嵌入了一個查找表
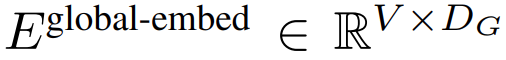 ,形成一個大小為 D_G 的嵌入,并添加了位置嵌入。
,形成一個大小為 D_G 的嵌入,并添加了位置嵌入。
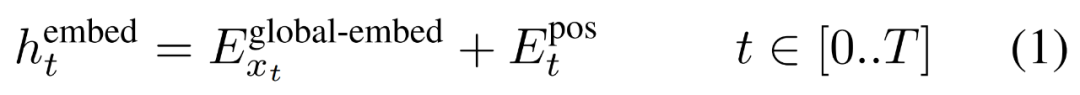
然后,字節(jié)嵌入被重塑成維度為
的 K 個 patch 嵌入的序列。為了允許自回歸建模,該 patch 序列被填充以從可訓練的 patch 大小的填充嵌入(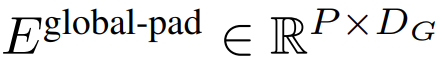 ),然后從輸入中移除最后一個 patch。該序列是全局模型的輸入,表示為
),然后從輸入中移除最后一個 patch。該序列是全局模型的輸入,表示為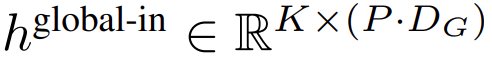 。
。
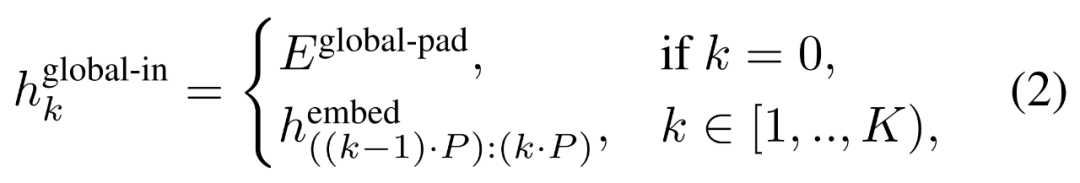
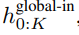 ,并通過對先前 patch 執(zhí)行自注意力來輸出更新的表示
,并通過對先前 patch 執(zhí)行自注意力來輸出更新的表示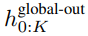 。
。
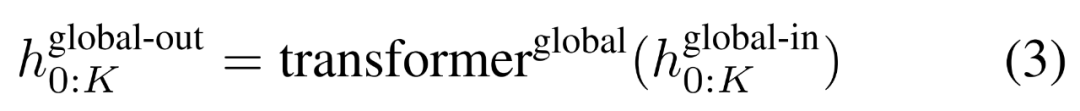
最終全局模塊的輸出
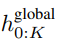 包含 P?D_G 維的 K 個 patch 表示。對于其中的每一個,研究者將它們重塑維長度為 P、維度為 D_G 的序列,其中位置 p 使用維度 p?D_G to (p + 1)?D_G。然后將每個位置映射到具有矩陣
包含 P?D_G 維的 K 個 patch 表示。對于其中的每一個,研究者將它們重塑維長度為 P、維度為 D_G 的序列,其中位置 p 使用維度 p?D_G to (p + 1)?D_G。然后將每個位置映射到具有矩陣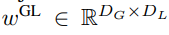 的局部模塊維度,其中 D_L 為局部模塊維度。接著將這些與大小為 D_L 的字節(jié)嵌入相結(jié)合,用于下一個
的局部模塊維度,其中 D_L 為局部模塊維度。接著將這些與大小為 D_L 的字節(jié)嵌入相結(jié)合,用于下一個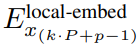 的 token。
的 token。局部字節(jié)嵌入通過可訓練的局部填充嵌入(E^local-pad ∈ R^DL)偏移 1,從而允許在 path 中進行自回歸建模。最終得到張量
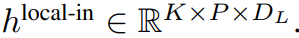 ?
?
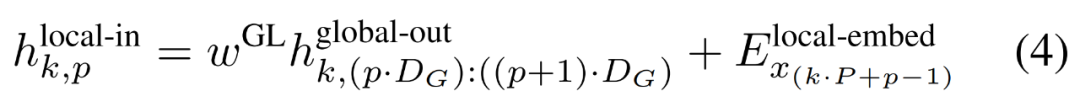
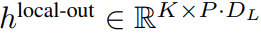 。
。

最后,研究者可以計算每個位置的詞匯概率分布。第 k 個 patch 的第 p 個元素對應于完整序列的元素 t,其中 t = k?P + p。
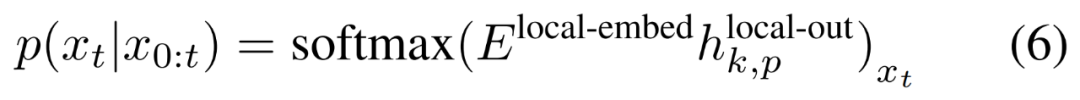
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學習之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請聯(lián)系本站處理。
舉報投訴
-
AI
+關(guān)注
關(guān)注
87文章
31318瀏覽量
269661 -
數(shù)據(jù)轉(zhuǎn)換
+關(guān)注
關(guān)注
0文章
88瀏覽量
18016 -
模型
+關(guān)注
關(guān)注
1文章
3279瀏覽量
48980
原文標題:一定要「分詞」嗎?Andrej Karpathy:是時候拋棄這個歷史包袱了
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
為什么第一盞燈一定要用0xfe,其他的燈也一定要用該數(shù)值才有效?
為什么第一盞燈一定要用0xfe,其他的燈也一定要用該數(shù)值才有效?因為接觸這個時間不多,請你們盡量教會我啊 ,謝謝雖然你們都會說這很簡單,但我還是不懂,請你們耐心指導
發(fā)表于 10-18 22:46
自然語言處理中的分詞問題總結(jié)
的分詞系統(tǒng)了,2-3 行代碼就可以實現(xiàn)分詞調(diào)用和詞性標注,速度還不錯。基于 HMM 模型實現(xiàn),可以實現(xiàn)一定程度的未登錄詞識別。Jieba 有精確模式、全模式、搜索模式三種。全模式是找到
發(fā)表于 10-26 13:48
基于hanlp的es分詞插件
摘要:elasticsearch是使用比較廣泛的分布式搜索引擎,es提供了一個的單字分詞工具,還有一個分詞插件ik使用比較廣泛,hanlp是
發(fā)表于 07-01 11:34
hanlp分詞工具應用案例:商品圖自動推薦功能的應用
怎么實現(xiàn)了。分析了一下解決方案步驟: 1、圖庫建設:至少要有圖片吧,圖片肯定要有關(guān)聯(lián)的商品名稱、商品類別、商品規(guī)格、關(guān)鍵字等信息。 2、商品分詞
發(fā)表于 08-07 11:47
DSP和SDRAM之間的數(shù)據(jù)總線一定要加電阻嗎
俺也是個初學者,對信號完整性了解不多。只是看到參考電路上,DSP和SDRAM之間的數(shù)據(jù)總線,地址總線中間都加了小電阻。感覺是信號完整性用的 。但是現(xiàn)在布線的時候,感覺比較麻煩,不如不加這個呢。所以,我想問一下。DSP(單片機)和
發(fā)表于 07-20 14:23
請問ch582使用串口下載程序的時候一定要將PB22接地嗎?
請問ch582使用串口下載程序的時候一定要將PB22接地嗎?如果不接地直接重新上電可不可以下載的了?
發(fā)表于 08-05 06:52
基于二元關(guān)系分詞模型解決歧義詞切分
歧義詞的切分是中文分詞要面對的數(shù)個難題之一,解決好了這個問題就能夠有力提升中文分詞的正確率。對此,本文簡要介紹了漢語
發(fā)表于 01-15 16:09
?18次下載
北大開源了一個中文分詞工具包,名為——PKUSeg
多領(lǐng)域分詞:不同于以往的通用中文分詞工具,此工具包同時致力于為不同領(lǐng)域的數(shù)據(jù)提供個性化的預訓練模型。根據(jù)待分詞文本的領(lǐng)域特點,用戶可以自由地選擇不同的模型。 我們目前支持了新聞領(lǐng)域,網(wǎng)
手機充電一定要充滿嗎
充電一定要在手機沒電之前充電,也不能充滿電,要充到一定電量就拔掉充電器,這樣才能更好的保護手機的電池,不要等手機電量全部用沒之后在充電,這個叫做深度放電,這樣對手機的損害是非常大的,所以說小編請大家千萬不要這么做。
在購買洗衣機的時候 一定要結(jié)合自身的實際需求
洗衣機的種類非常多,很多人在挑選的時候都會感到非常頭疼,不知道要買哪種洗衣機更好,所以,我們在挑選之前一定要有自己的想法,多點學習相關(guān)的知識,這樣才不會買到一些不實用的洗衣機,而且也不會白白浪費錢。
發(fā)表于 04-09 14:50
?432次閱讀
特斯拉前AI總監(jiān)Andrej Karpathy:大模型有內(nèi)存限制,這個妙招挺好用!
為了讓大家更好的理解 Karpathy 的內(nèi)容。我們先介紹一下「Speculative decoding」方法,對后續(xù)理解更加有益,其主要用于加速大模型的推理。據(jù)了解,GPT-4 泄密報告也提到了 OpenAI 線上模型推理使用了它(不確定是否 100%)。





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論