 AI算法說-圖像分割
AI算法說-圖像分割
1、簡介

圖像分割任務,即算法需要預測出圖片中的每一個像素點的類別。它解決了“圖像中每一個像素點是什么類別的問題”。上圖所示了一個自動駕駛場景下的圖像分割效果,圖片中相同的顏色表示相同的類別,不同的顏色表示不同的類別。
圖像分割方法種類繁多,包括傳統的基于閾值、邊緣和區域的方法,以及近年來基于深度學習的方法,如全卷積網絡(FCN)、編碼器-解碼器網絡、視覺注意力機制、對抗生成網絡等。在圖像分割任務中,需注意逐像素標注方式和實例級別標注方式的區別,并需要針對不同的應用場景選擇適合的評價指標和數據集。
2、發展歷程
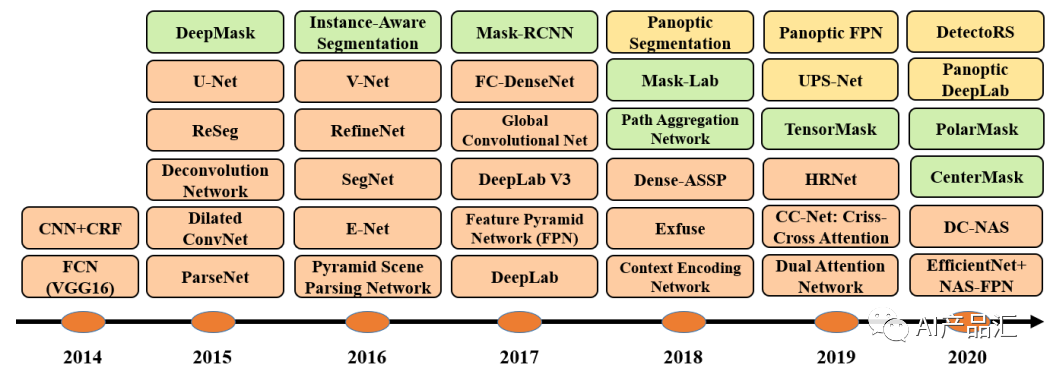
2014年,J. Long, E. Shelhamer, and T. Darrell等人發表了“Fully convolutional networks for semantic segmentation”了算法(https://arxiv.org/pdf/2001.05566.pdf),即FCN算法。FCN的核心思想是將傳統的全連接層轉變為卷積層,并且采用反卷積技術將最后一層卷積輸出映射回原始圖像大小。
2015年,O. Ronneberger, P. Fischer, and T. Brox等人發表了“U-net: Convolutional networks for biomedical image segmentation”,即U-net算法。U-net的特點是通過一系列卷積、池化和反卷積操作實現了圖像分割,并在特征提取過程中保留了高分辨率的細節信息。
2016年,V. Badrinarayanan, A. Kendall, and R. Cipolla等人發表了“Segnet: A deep convolutional encoder-decoder architecture for image segmentation”,即SegNet算法。SegNet的特點是采用了輕量級卷積神經網絡結構,并設計了一種基于池化索引的解碼器,能夠實現快速而準確的圖像分割。
2017年,L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille等人發表了“Semantic image segmentation with deep convolutional nets and fully connected crfs”,即DeepLab算法,后續陸續推出DeepLabV2和DeepLabV3等算法。該算法首次在CNN中引入了完全連接的條件隨機場(CRFs),該CRF模型建模了圖像的全局上下文,通過允許標簽之間的相互作用來獲得更準確的分割結果。
2018年,L.-C. Chen, A. Hermans, G. Papandreou, F. Schroff, P. Wang, and H. Adam等人發表了“Masklab: Instance segmentation by refining object detection with semantic and direction features”,即Mask-Lab算法。該算法的主要思想是,在卷積神經網絡中添加實例感知模塊,以分離不同對象的實例。
2019年,Y. Yuan, X. Chen, and J. Wang等人發表了“Object-contextual representations for semantic segmentation”,即HRNet算法。HRNet算法的主要思想是在多個分辨率上進行特征提取,同時跨層連接以消除分辨率差異和信息損失。
2020年,B. Zoph, G. Ghiasi, T.-Y. Lin, Y. Cui, H. Liu, E. D. Cubuk, and Q. V. Le等人發表了“Rethinking pre-training and self-training”,即EfficientNet+NAS-FPN算法。該算法的核心思想是在無標簽數據上進行預訓練和自訓練,從而提高有標簽數據的分割性能。
2020年之后,圖像分割算法的性能基本達到了精度天花板,很多學者轉做實例分割和全景分割。
3、應用場景

自動駕駛-目標分割可以應用在自動駕駛場景中完成靜態障礙物和動態障礙物的精準分割,從而構建一個語義地圖傳遞給后面的規劃和控制模塊。
交互標定-利用目標算法可以基于幾個點快速的標注目標物體,這樣可以極大的提升人員的標注成本。
人像摳圖-人像摳圖功能在我們的日常生活中有著大量的應用,最常用的就是各種遠程會議軟件上面的摳圖功能。該算法基本能達到扣頭發絲的精度。
醫學圖像分析-圖像分割算法可以針對人體各器官進行精細的分割,協助醫生完成一些醫學診斷的問題。該功能已經在一些醫院有所應用。
4、算法類別
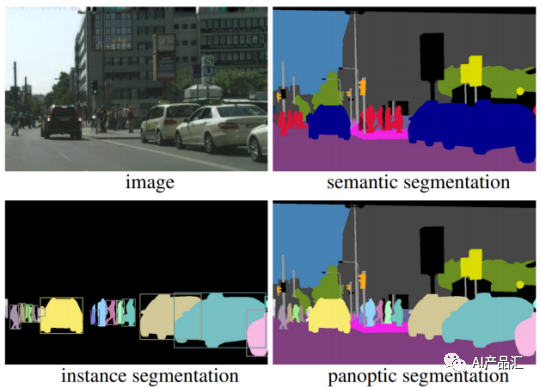
對于圖像分割任務而言,我們可以將其細分為語義分割、實例分割和全景分割三種類別。如上圖所示,輸入的是一張街拍場景的圖片。語義分割任務只能區分不同的類別,無法區別相同的類別。實例分割任務不僅可以區分不同的類別,也可以區分相同類別中的不同個數,如圖片中的行人和車輛 ,不同的人用不同的顏色進行顯示。全景分割則是語義分割和實例分割的交集。
語義分割是區分同類物體的分割任務,實例分割是區分不同實例的分割任務,而全景分割則同時達到這兩個目標。全景分割既可以區分彼此相關的物體,也可以區分它們在圖像中的位置,這使其非常適合對圖像中所有類別的目標進行分割。
5、經典算法剖析
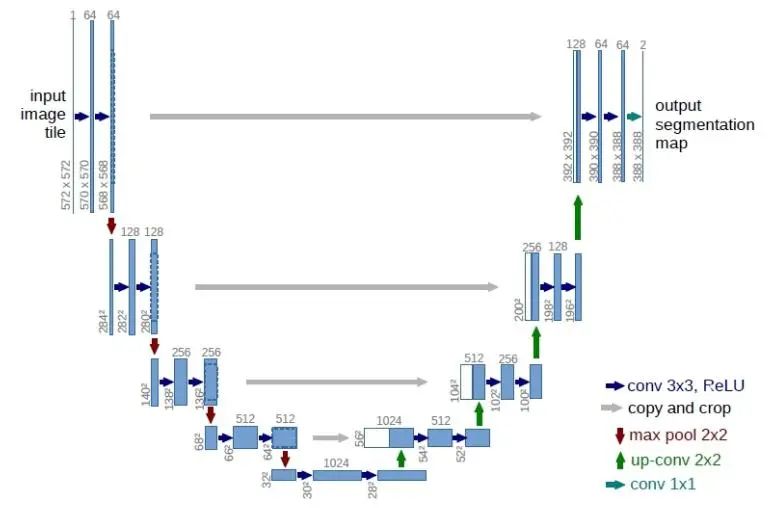
5.1 UNet算法詳解
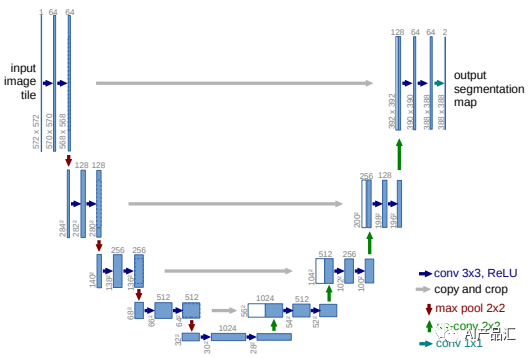
算法簡介:
UNet是一種基于卷積神經網絡的圖像分割算法,它于2015年由Olaf Ronneberger等人提出。與FCN等分割算法不同,UNet采用了一種新的網絡結構,能夠更好地處理物體邊緣和小的物體。
創新點:
UNet算法的創新點在于其網絡結構,即將傳統的編碼器-解碼器架構與跳躍連接技術相結合,形成了一個“U”形的網絡結構。UNet算法流程:1. 圖像編碼:首先,通過卷積層實現圖像特征的提取和縮小,構建編碼器。采用類似于VGG網絡的結構,通過不斷重復卷積、下采樣的過程,將輸入的圖像逐漸縮小,并提取出不同尺度的特征。2. 圖像解碼:構建解碼器,是為了逐步將圖像還原回原始的分辨率。UNet算法中的解碼器采用了鏡像反卷積操作,逐步還原特征圖的尺寸,也通過不斷重復卷積、上采樣的過程,將特征融合到更高的分辨率上。3. 跳躍連接:UNet算法引入了跳躍連接(skip connection),將編碼層和對應的解碼層中的特征圖進行連接。這種方式能夠將底層的語義信息(例如邊緣信息)直接提供給解碼器,有利于保留物體邊緣信息,同時也有利于消除某些不必要的噪聲。4. 輸出結果:通過在UNet網絡的最后一層卷積后接一個含有類別數+1個通道的全連接層,并使用softmax函數得到像素分類的概率值,就可以生成語義分割圖了。總的來說,UNet算法采用了跳躍連接,能夠更好地保留圖像的信息,使得算法更適用于分割小物體和物體之間的邊界。該算法在實際應用中被廣泛使用,特別是在醫學圖像分割領域,如肝臟分割和胰腺分割等。
5.2Mask-RCNN算法詳解
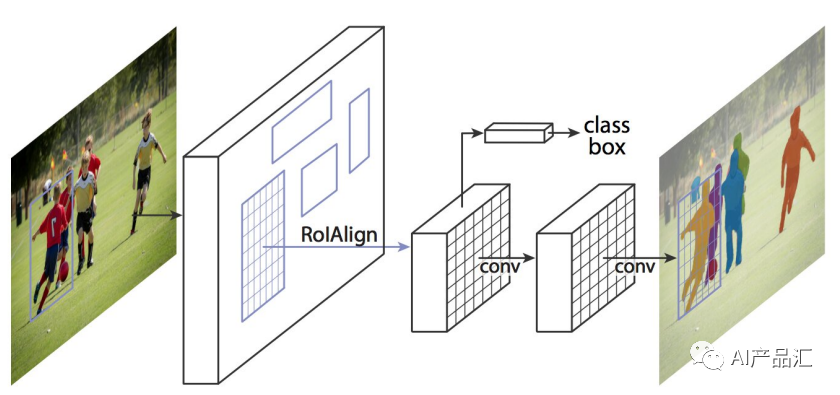
簡介:
Mask RCNN是一種深度學習圖像分割算法,由FAIR(Facebook AI Research)于2018年提出。它是RCNN系列算法的最新版本,在Faster RCNN和Mask RCNN的基礎上加入了全新的分割網絡。算法創新點:1. Mask RCNN是第一種能夠實現目標檢測和實例分割的統一框架算法,不需要額外的分割網絡; 2. Mask RCNN通過于Faster RCNN相似的兩個分支結構,檢測出每個物體的對象邊界框,并且對其中的每個對象實現語義分割; 3. Mask RCNN創新性地加入了RoIAlign模塊,可以以像素級別的準確度提取ROI特征; 4. Mask RCNN在訓練時采用了多尺度訓練和水平翻轉等數據增強技術,提高了魯棒性; 5. Mask RCNN利用了實例分割結果來輔助目標檢測,提高了檢測的效率和準確性。算法步驟:1. 首先,在特征提取器(如ResNet)的基礎上,添加一個RoI pooling層,用來提取每個BoundingBox內的特征向量; 2. 然后,進入到Proposal Generation 階段,使用RPN來產生多個區域框,對每個區域框進行候選區域的分類(物體還是非物體)和邊界框回歸(Bounding Box Regression); 3. 在Proposal Refinement(即Detection)階段,結合Proposal Generation的結果,利用Fast RCNN的方法,先將每個候選區域的特征向量轉換成一個固定尺寸的特征圖(由RoI pooling提取),然后通過全連接層來實現分類和位置回歸; 4. 最后,加入Mask RCNN的核心部分,即Mask Generation階段。我們以RoIAlign代替RoI Pooling,對每個RoI內的坐標點都采用雙線性濾波,從而在ROI范圍內等距采樣得到RoIAlign Feature Map。使用一個分支來預測分割,并對每個ROI生成一個mask.
6、評估指標
6.1 定量指標1.精確度(Accuracy):分割正確的像素數占總像素數的比例,即TP+TN/(TP+TN+FP+FN),其中TP為真正例,TN為真反例,FP為假正例,FN為假反例。2.召回率(Recall):正確分割出的像素數占實際應分割像素數的比例,即TP/(TP+FN)。3.精度(Precision):正確分割出的像素數占分割出的像素總數的比例,即TP/(TP+FP)。4.F1值(F1-score):綜合考慮Precision和Recall,即2*Precision*Recall/(Precision+Recall)。5.歐拉距離(Euclidean distance):分割圖像與真實分割圖像之間的歐拉距離。6.交并比(IoU):分割圖像與真實分割圖像之間的重疊像素數占并集像素數的比例,即TP/(TP+FP+FN)。7.像素錯誤率(Pixel error rate):錯誤分割像素數占總像素數的比例,即FP+FN/(TP+TN+FP+FN)。8.平均準確度(Mean accuracy):分類正確的像素數占各類應分割像素數的平均值,即(∑TP_i)/(∑(TP_i+FP_i)),其中i為類別。9.平均交并比(Mean IoU):所有類別的IoU的平均值,即(∑TP_i)/(∑(TP_i+FP_i+FN_i)),其中i為類別。

6.2 定性指標
1.視覺效果(Visual quality):分割結果能否符合人的感受,如邊界清晰、區域連續等。2.時間復雜度(Time complexity):計算分割結果所需的時間和計算復雜度,對于實時應用來說尤為重要。3.空間復雜度(Space complexity):占用內存的大小,對于大型圖片和數據量來說尤為重要。4.可擴展性(Scalability):算法的擴展性,能否適應不同規模的數據集和不同的場景。5.魯棒性(Robustness):算法的穩定性和適應性,對于噪聲和異常情況的處理能力。

7、開源數據集
1. Cityscapes-https://www.cityscapes-dataset.com/
Cityscapes是一個針對城市街景圖像分割的大規模數據集,包含了街景照片、標記為19個不同類別的圖像分割或實例分割等多種圖像數據類型。
2. COCO-http://cocodataset.org/#overview
COCO是一個通用的目標檢測、圖像分割和實例分割數據集,包含了各種場景下的圖像,涵蓋了多種物體類別。
3. PASCAL VOC-http://host.robots.ox.ac.uk/pascal/VOC/
PASCAL VOC是一個流行的計算機視覺數據集,包含了20多個物體類別的圖像樣本,以及這些物體的位置標記。
4. ADE20K-https://groups.csail.mit.edu/vision/datasets/ADE20K/
ADE20K是一個基于社區貢獻的大規模場景理解和圖像分割數據集,其中包含了超過20,000張圖像和類別標注。
5. BSDS500-https://www2.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/segbench/
BSDS500是一個用于邊緣檢測、分割和顯著性檢測的數據集,包含了幾百張圖像和像素級標注。
6. CamVid-http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
CamVid是一個針對道路場景的圖像分割數據集,包含了對不同類別的道路元素(如汽車、行人等)的標記。
7. SUN RGB-D-https://rgbd.cs.princeton.edu/
SUN RGB-D是一個室內場景3D圖像分割數據集,其包括了帶深度信息的RGB圖像,用于分割物體、家具、地板等不同場景中的元素。
8. MS COCO Panoptic Segmentation-https://cocodataset.org/#panoptic-2018
MS COCO Panoptic Segmentation是一個多種物體檢測圖像分類和實例分割任務的數據集。其包含80類物體和133k張圖像。

8、熱門論文
1. Fully Convolutional Networks for Semantic Segmentation-https://arxiv.org/abs/1411.4038 簡介:本文提出了一種基于完全卷積網絡的圖像分割方法,能夠同時獲得像素級別的分類和空間信息。
2. U-Net: Convolutional Networks for Biomedical Image Segmentation-https://arxiv.org/abs/1505.04597 簡介:該文介紹了一種特殊結構的U-Net卷積神經網絡用于生物醫學圖像分割。U-Net結構的主要特點是在解碼階段引入了跳躍連接,從而提高了分割的質量。
3. Mask R-CNN-https://arxiv.org/abs/1703.06870 簡介:Mask R-CNN是一種基于Faster R-CNN的圖像分割模型,相比于其他模型,Mask R-CNN能夠在不損失精度的情況下在檢測任務上同時實現像素級別的分割。
4. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs-https://arxiv.org/abs/1606.00915 簡介:本文提出了一種語義圖像分割方法DeepLab,該方法通過引入擴張卷積和CRF的全連接層,能夠提高分割結果的準確性。
5. DenseNet: Densely Connected Convolutional Networks-https://arxiv.org/abs/1608.06993 簡介:本文介紹了一種新型的卷積神經網絡DenseNet,并將其成功應用于圖像分類和物體檢測等任務中。DenseNet的主要特點是將每個層的輸入與前面所有層的輸出相連接,從而提高了信息流的利用效率。
6. FC-DenseNet: Fully Convolutional DenseNets for Semantic Segmentation-https://arxiv.org/abs/1611.09326 簡介:FC-DenseNet是一種基于DenseNet的圖像分割模型,通過將DenseNet的結構應用于分割任務中,從而提高了分割的準確性和效率。
7. PSPNet: Pyramid Scene Parsing Network-https://arxiv.org/abs/1612.01105 簡介:本文提出了一種新的分割模型PSPNet,該模型引入了金字塔池化模塊,能夠在不同尺度下提取特征信息,并增加了局部和全局上下文的信息。
8. Attention U-Net: Learning Where to Look for the Pancreas-https://arxiv.org/abs/1804.03999 簡介:Attention U-Net是一種關注梯度信息的全卷積網絡,它通過自適應上下文注意力機制,可以更加準確地實現器官分割任務。
9. Squeeze-and-Excitation Networks-https://arxiv.org/abs/1709.01507 簡介:本文提出了一種新型的卷積神經網絡Squeeze-and-Excitation Networks(SENet),該網絡通過增加逐通道的注意力機制,提高了信息的利用效率和精度。
10. UNet++: A Nested U-Net Architecture for Medical Image Segmentation-https://arxiv.org/abs/1807.10165 簡介:UNet++是一種基于U-Net的嵌套結構圖像分割方法,通過逐級連接不同大小的U-Net,可以更加準確地獲取不同尺度的特征信息。

9、熱門倉庫
1. Mask R-CNN- https://github.com/matterport/Mask_RCNN
簡介:一個基于Faster R-CNN的全卷積神經網絡,用于對圖像中目標進行實例分割,支持多方向的邊界框和掩膜生成。
2. DeepLab- https://github.com/tensorflow/models/tree/master/research/deeplab
簡介:一個基于深度卷積神經網絡的神經圖像分割框架,支持多尺度和多特征融合,能處理大尺度和高分辨率圖像。
3. U-Net- https://github.com/zhixuhao/unet
簡介:一個專用于醫學圖像分割的神經網絡模型,結構簡單,訓練效果優秀,已廣泛應用于醫學圖像分析領域。
4. FCN- https://github.com/shelhamer/fcn.berkeleyvision.org
簡介:一個基于Fully Convolutional Network的全卷積神經網絡模型,用于對圖像進行像素級別的分割,支持多分辨率輸入和多尺度融合。
5. PSPNet- https://github.com/hszhao/PSPNet
簡介:一個基于Pyramid Scene Parsing Network的圖像分割模型,通過多尺度和多分辨率的金字塔池化來獲取圖像的全局和局部信息,進行像素級別的分割。
6. Mask-RCNN-Benchmark- https://github.com/facebookresearch/maskrcnn-benchmark
簡介:一個由Facebook Research開發的Mask R-CNN庫,使用PyTorch框架實現,支持多GPU并行訓練和測試,訓練速度快、效果好。
7. HRNet-Semantic-Segmentation- https://github.com/HRNet/HRNet-Semantic-Segmentation
簡介:一個基于高分辨率網絡的圖像分割模型,支持多尺度融合和多分支特征提取,可用于處理高分辨率圖像。
8. TensorFlow-Segmentation- https://github.com/divamgupta/image-segmentation-keras
簡介:一個使用TensorFlow框架實現的圖像分割庫,提供了多種經典的分割網絡模型,簡單易用。
9. PyTorch-Segmentation- https://github.com/qubvel/segmentation_models.pytorch
簡介:一個使用PyTorch框架實現的圖像分割庫,支持多個經典的分割網絡模型和多種損失函數,適用于各種應用場景。
10. Semantic-Segmentation-Suite- https://github.com/GeorgeSeif/Semantic-Segmentation-Suite
簡介:一個基于深度卷積神經網絡的圖像分割工具包,支持多個分割網絡模型和多種損失函數,具有高效和易用的特點。
11. PaddleSeg-https://github.com/PaddlePaddle/PaddleSeg
簡介:PaddleSeg是百度維護的一個基于PaddlePaddle開發的有關圖像分割任務的一個高性能部署的工具集,里面包含眾多性能優異的圖像分割算法。12. mmsegmentation-https://github.com/open-mmlab/mmsegmentation
簡介: mmsegmentation是一個基于Pytorch構建的一個開源語義分割庫,里面集成了很多經典的語義分割算法,研究人員可以用來快速的開發自己新的算法。

審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100772 -
算法
+關注
關注
23文章
4612瀏覽量
92901 -
AI
+關注
關注
87文章
30896瀏覽量
269108
原文標題:AI算法說-圖像分割
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
免疫克隆SAR圖像分割算法
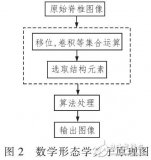
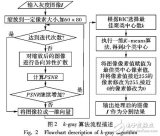
一種新的彩色圖像分割算法
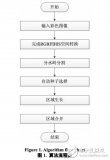

圖像分割算法的深入研究






 工商網監
工商網監
評論