 如何利用LLM做一些多模態任務
如何利用LLM做一些多模態任務
大型語言模型LLM(Large Language Model)具有很強的通用知識理解以及較強的邏輯推理能力,但其只能處理文本數據。雖然已經發布的GPT4具備圖片理解能力,但目前還未開放多模態輸入接口并且不會透露任何模型上技術細節。因此,現階段,如何利用LLM做一些多模態任務還是有一定的研究價值的。
本文整理了近兩年來基于LLM做vision-lanuage任務的一些工作,并將其劃分為4個類別:
凍住LLM,訓練視覺編碼器等額外結構以適配LLM,例如mPLUG-Owl,LLaVA,Mini-GPT4,Frozen,BLIP2,Flamingo,PaLM-E[1]
將視覺轉化為文本,作為LLM的輸入,例如PICA(2022),PromptCap(2022)[2],ScienceQA(2022)[3]
利用視覺模態影響LLM的解碼,例如ZeroCap[4],MAGIC
利用LLM作為理解中樞調用多模態模型,例如VisualChatGPT(2023), MM-REACT(2023)
接下來每個類別會挑選代表性的工作進行簡單介紹:
訓練視覺編碼器等額外結構以適配LLM
這部分工作是目前關注度最高的工作,因為它具有潛力來以遠低于多模態通用模型訓練的代價將LLM拓展為多模態模型。
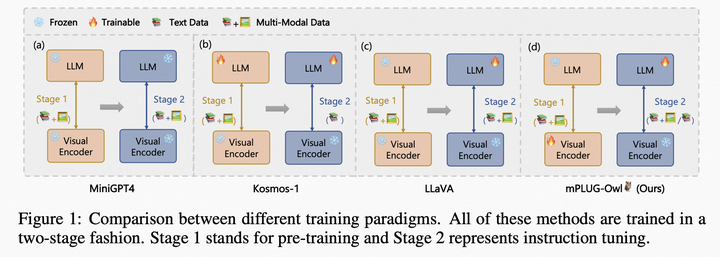
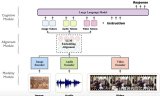
隨著GPT4的火熱,近期涌現了大量的工作,如LLaVA, Mini-GPT4和mPLUG-Owl。這三個工作的主要區別如下圖所示,總體而言,模型結構和訓練策略方面大同小異,主要體現在LLaVA和MiniGPT4都凍住基礎視覺編碼器,mPLUG-Owl將其放開,得到了更好的視覺文本跨模態理解效果;在實驗方面mPLUG-Owl首次構建并開源視覺相關的指令理解測試集OwlEval,通過人工評測對比了已有的模型,包括BLIP2、LLaVA、MiniGPT4以及系統類工作MM-REACT。
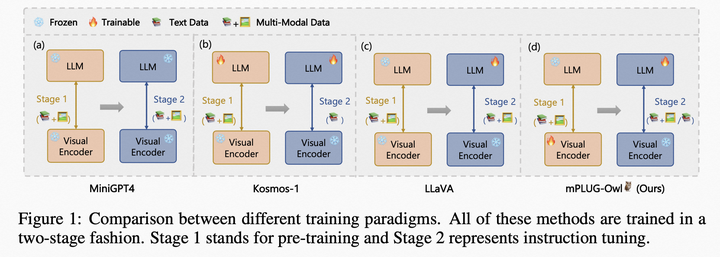 mPLUG-Owl vs MiniGPT4 vs LLaVA
mPLUG-Owl vs MiniGPT4 vs LLaVA
mPLUG-Owl
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
mPLUG-Owl是阿里巴巴達摩院mPLUG系列的最新工作,繼續延續mPLUG系列的模塊化訓練思想,將LLM遷移為一個多模態大模型。此外,Owl第一次針對視覺相關的指令評測提出一個全面的測試集OwlEval,通過人工評測對比了已有工作,包括LLaVA和MIniGPT4。該評測集以及人工打分的結果都進行了開源,助力后續多模態開放式回答的公平對比。
模型結構:采用CLIP ViT-L/14作為"視覺基礎模塊",采用LLaMA初始化的結構作為文本解碼器,采用類似Flamingo的Perceiver Resampler結構對視覺特征進行重組(名為"視覺摘要模塊"),如圖。
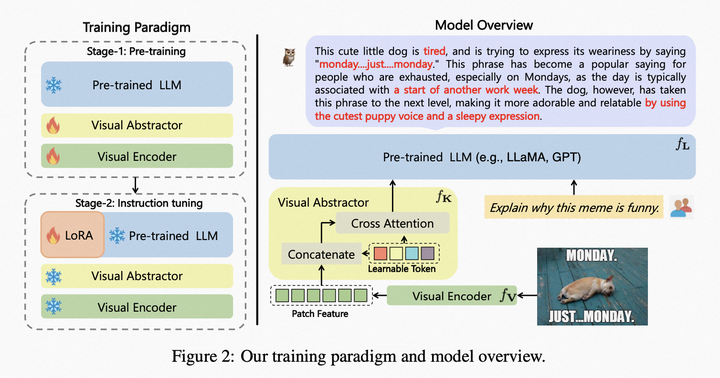 mPLUG-Owl模型結構
mPLUG-Owl模型結構
模型訓練
第一階段: 主要目的也是先學習視覺和語言模態間的對齊。不同于前兩個工作,Owl提出凍住視覺基礎模塊會限制模型關聯視覺知識和文本知識的能力。因此Owl在第一階段只凍住LLM的參數,采用LAION-400M,COYO-700M,CC以及MSCOCO訓練視覺基礎模塊和視覺摘要模塊。
第二階段: 延續mPLUG和mPLUG-2中不同模態混合訓練對彼此有收益的發現,Owl在第二階段的指令微調訓練中也同時采用了純文本的指令數據(102k from Alpaca+90k from Vicuna+50k from Baize)和多模態的指令數據(150k from LLaVA)。作者通過詳細的消融實驗驗證了引入純文本指令微調在指令理解等方面帶來的收益。第二階段中視覺基礎模塊、視覺摘要模塊和原始LLM的參數都被凍住,參考LoRA,只在LLM引入少量參數的adapter結構用于指令微調。
實驗分析
除了訓練策略,mPLUG-Owl另一個重要的貢獻在于通過構建OwlEval評測集,對比了目前將LLM用于多模態指令回答的SOTA模型的效果。和NLP領域一樣,在指令理解場景中,模型的回答由于開放性很難進行評估。
SOTA對比:本文初次嘗試構建了一個基于50張圖片(21張來自MiniGPT-4, 13張來自MM-REACT, 9張來自BLIP-2, 3來自GPT-4以及4張自收集)的82個視覺相關的指令回答評測集OwlEval。由于目前并沒有合適的自動化指標,本文參考Self-Intruct對模型的回復進行人工評測,打分規則為:A="正確且令人滿意";B="有一些不完美,但可以接受";C="理解了指令但是回復存在明顯錯誤";D="完全不相關或不正確的回復"。實驗證明Owl在視覺相關的指令回復任務上優于已有的OpenFlamingo、BLIP2、LLaVA、MiniGPT4以及集成了Microsoft 多個API的MM-REACT。作者對這些人工評測的打分同樣進行了開源以方便其他研究人員檢驗人工評測的客觀性。
多維度能力對比:多模態指令回復任務中牽扯到多種能力,例如指令理解、視覺理解、圖片上文字理解以及推理等。為了細粒度地探究模型在不同能力上的水平,本文進一步定義了多模態場景中的6種主要的能力,并對OwlEval每個測試指令人工標注了相關的能力要求以及模型的回復中體現了哪些能力。在該部分實驗,作者既進行了Owl的消融實驗,驗證了訓練策略和多模態指令微調數據的有效性,也和上一個實驗中表現最佳的baseline——MiniGPT4進行了對比,結果顯示Owl在各個能力方面都優于MiniGPT4。
LLaVA
Visual instruction tuning
自然語言處理領域的instruction tuning可以幫助LLM理解多樣化的指令并生成比較詳細的回答。LLaVA首次嘗試構建圖文相關的instruction tuning數據集來將LLM拓展到多模態領域。具體來說,基于MSCOCO數據集,每張圖有5個較簡短的ground truth描述和object bbox(包括類別和位置)序列,將這些作為text-only GPT4的輸入,通過prompt的形式讓GPT4生成3種類型的文本:1)關于圖像中對象的對話;2)針對圖片的詳細描述;3)和圖片相關的復雜的推理過程。注意,這三種類型都是GPT4在不看到圖片的情況下根據輸入的文本生成的,為了讓GPT4理解這些意圖,作者額外人工標注了一些樣例用于in-context learning。
模型結構:采用CLIP的ViT-L/14作為視覺編碼器,采用LLaMA作為文本解碼器,通過一個簡單的線性映射層將視覺編碼器的輸出映射到文本解碼器的詞嵌入空間,如圖。
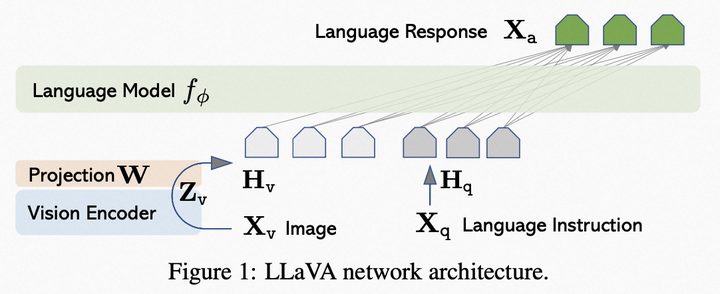 LLaVA模型結構
LLaVA模型結構
模型訓練1/ 第一階段:跨模態對齊預訓練,從CC3M中通過限制caption中名詞詞組的最小頻率過濾出595k圖文數據,凍住視覺編碼器和文本解碼器,只訓練線性映射層;2. 第二階段:指令微調,一版針對多模態聊天機器人場景,采用自己構建的158k多模態指令數據集進行微調;另一版針對Science QA數據集進行微調。微調階段,線性層和文本解碼器(LLaMA)都會進行優化。
實驗分析
消融實驗: 在30個MSCOCO val的圖片上,每張圖片設計3個問題(對話、詳細描述、推理),參考 Vicuna[8],用GPT4對LLaVA和text-only GPT4的回復進行對比打分,報告相對text-only GPT4的相對值。
SOTA對比: 在Science QA上微調的版本實現了該評測集上的SOTA效果。
Mini-GPT4
Minigpt-4: Enhancing vision-language under- standing with advanced large language models
Mini-GPT4和LLaVA類似,也發現了多模態指令數據對于模型在多模態開放式場景中表現的重要性。
模型結構:采用BLIP2的ViT和Q-Former作為視覺編碼器,采用LLaMA經過自然語言指令微調后的版本Vicuna作為文本解碼器,也通過一個線性映射層將視覺特征映射到文本表示空間,如圖:
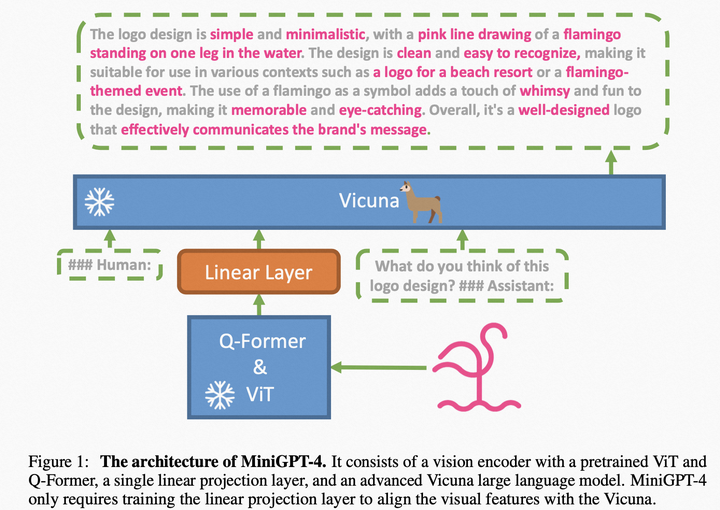 MiniGPT4模型結構
MiniGPT4模型結構
模型訓練
第一階段:目標通過大量圖文對數據學習視覺和語言的關系以及知識,采用CC+SBU+LAION數據集,凍住視覺編碼器和文本解碼器,只訓練線性映射層;
第二階段:作者發現只有第一階段的預訓練并不能讓模型生成流暢且豐富的符合用戶需求的文本,為了緩解這個問題,本文也額外利用ChatGPT構建一個多模態微調數據集。具體來說,1)其首先用階段1的模型對5k個CC的圖片進行描述,如果長度小于80,通過prompt讓模型繼續描述,將多步生成的結果合并為一個描述;2)通過ChatGPT對于構建的長描述進行改寫,移除重復等問題;3)人工驗證以及優化描述質量。最后得到3.5k圖文對,用于第二階段的微調。第二階段同樣只訓練線性映射層。
DeepMind于2021年發表的Frozen,2022年的Flamingo以及Saleforce 2023年的BLIP2也都是這條路線,如圖所示。
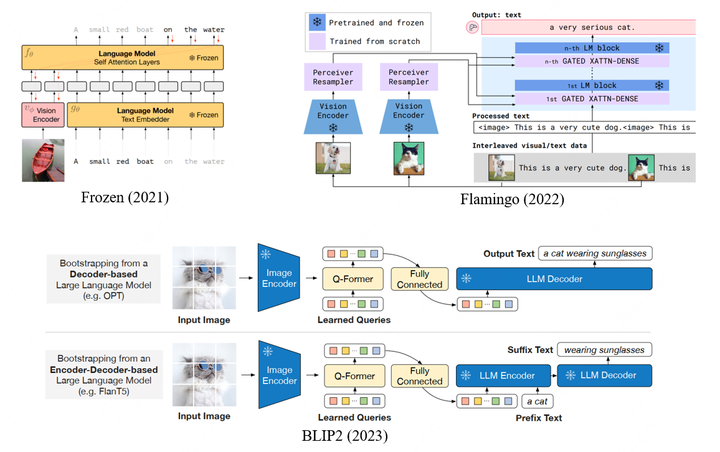
Frozen
Multimodal Few-Shot Learning with Frozen Language Models.
Frozen訓練時將圖片編碼成2個vision token,作為LLM的前綴,目標為生成后續文本,采用Conceptual Caption作為訓練語料。Frozen通過few-shot learning/in-context learning做下游VQA以及image classification的效果還沒有很強,但是已經能觀察到一些多模態in-context learning的能力。
Flamingo
Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo為了解決視覺feature map大小可能不一致(尤其對于多幀的視頻)的問題,用Perceiver Resampler (類似DETR的解碼器)生成固定長度的特征序列(64個token),并且在LLM的每一層之前額外增加了一層對視覺特征進行注意力計算的cross-attention layer,以實現更強的視覺相關性生成。Flamingo的訓練參數遠高于Frozen,因此采用了大量的數據:1)MultiModal MassiveWeb(M3W) dataset:從43million的網頁上收集的圖文混合數據,轉化為圖文交叉排列的序列(根據網頁上圖片相對位置,決定在轉化為序列后,token 在文本token系列中的位置);2)ALIGN (alt-text & image Pairs): 1.8 million圖文對;3)LTIP (LongText & Image Pairs):312 million圖文對;4)VTP (Video & Text Pairs) :27 million視頻文本對(平均一個視頻22s,幀采樣率為1FPS)。類似LLM,Flamingo的訓練目標也為文本生成,但其對于不同的數據集賦予不同的權重,上面四部分權重分別為1.0、0.2、0.2、0.03,可見圖文交叉排列的M3W數據集的訓練重要性是最高的,作者也強調這類數據是具備多模態in-context learning能力的重要因素。Flamingo在多個任務上實現了很不錯的zero-shot以及few-shot的表現。
BLIP2
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
BLIP2采用了類似于Flamingo的視覺編碼結構,但是采用了更復雜的訓練策略。其包含兩階段訓練,第一階段主要想讓視覺編碼器學會提取最關鍵的視覺信息,訓練任務包括image-Text Contrastive Learning, Image-grounded Text Generation以及Image-Text Matching;第二階段則主要是將視覺編碼結構的輸出適配LLM,訓練任務也是language modeling。BLIP2的訓練數據包括MSCOCO,Visual Genome,CC15M,SBU,115M來自于LAION400M的圖片以及BLIP在web images上生成的描述。BLIP2實現了很強的zero-shot capitoning以及VQA的能力,但是作者提到未觀察到其in-context learning的能力,即輸入樣例并不能提升它的性能。作者分析是因為訓練數據里不存在Flamingo使用的圖文交錯排布的數據。不過Frozen也是沒有用這類數據,但是也觀察到了一定的in-context learning能力。因此多模態的in-context learning能力可能和訓練數據、訓練任務以及位置編碼方法等都存在相關性。
將視覺轉化為文本,作為LLM的輸入
PICA
An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
以PICA為例,它的目標是充分利用LLM中的海量知識來做Knowledge-based QA。給定一張圖和問題,以往的工作主要從外部來源,例如維基百科等來檢索出相關的背景知識以輔助答案的生成。但PICA嘗試將圖片用文本的形式描述出來后,直接和問題拼在一起作為LLM的輸入,讓LLM通過in-context learning的方式直接生成回答,如圖所示。
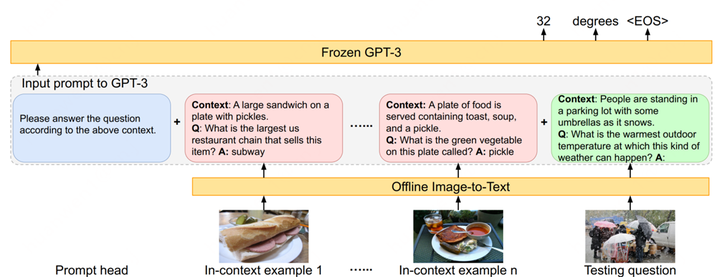 PICA
PICA
In-context learning的效果比較依賴example/demonstration的質量,為此PICA的作者利用CLIP挑選了和當前測試樣例在問題和圖片上最接近的16個訓練樣例作為examples。
利用視覺模態影響LLM的解碼
MAGIC
Language Models Can See: Plugging Visual Controls in Text Generation
以MAGIC為例,它的目標是讓LLM做image captioning的任務,它的核心思路是生成每一個詞時,提高視覺相關的詞的生成概率,公式如圖所示。
 MAGIC解碼公式
MAGIC解碼公式
該公式主要由三部分組成:
LLM預測詞的概率
退化懲罰(橙色)
視覺相關性(紅色)
退化懲罰主要是希望生成的詞能帶來新的信息量。視覺相關性部分為基于CLIP計算了所有候選詞和圖片的相關性,取softmax之后的概率作為預測概率。
利用LLM作為理解中樞調用多模態模型
Visual ChatGPT
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
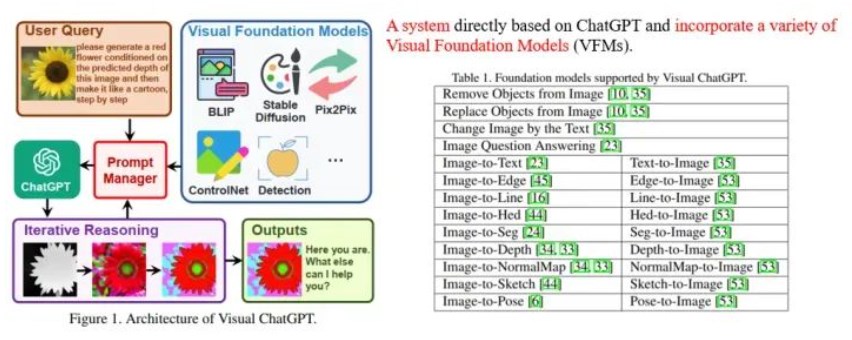
以微軟Visual ChatGPT為例,它的目標是使得一個系統既能和人進行視覺內容相關的對話,又能進行畫圖以及圖片修改的工作。為此,Visual ChatGPT采用ChatGPT作為和用戶交流的理解中樞,整合了多個視覺基礎模型(Visual Foundation Models),通過prompt engineering (即Prompt Manager)告訴ChatGPT各個基礎模型的用法以及輸入輸出格式,讓ChatGPT決定為了滿足用戶的需求,應該如何調用這些模型,如圖所示。
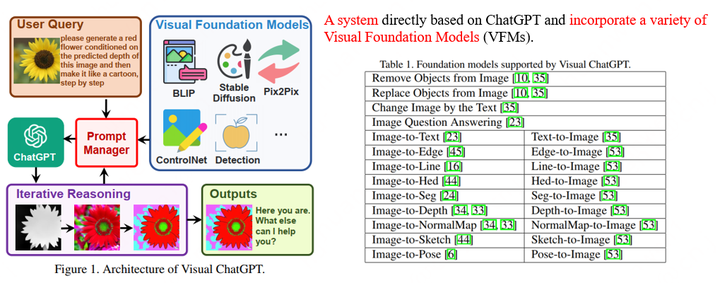
微軟另一個小組稍晚一段時間提出的MM-REACT[5]也是同樣的思路,區別主要在于prompt engineering的設計以及MM-REACT更側重于視覺的通用理解和解釋,包含了很多Microsoft Azure API,例如名人識別、票據識別以及Bing搜索等。
總結
對比幾種融入方式:
“訓練視覺編碼器等額外結構以適配LLM”具有更高的研究價值,因為其具備將任意模態融入LLM,實現真正意義多模態模型的潛力,其難點在于如何實現較強的in-context learning的能力。
“將視覺轉化為文本,作為LLM的輸入”和“利用視覺模態影響LLM的解碼”可以直接利用LLM做一些多模態任務,但是可能上限較低,其表現依賴于外部多模態模型的能力。
“利用LLM作為理解中樞調用多模態模型”可以方便快捷地基于LLM部署一個多模態理解和生成系統,難點主要在于prompt engineering的設計來調度不同的多模態模型。
-
編碼器
+關注
關注
45文章
3643瀏覽量
134519 -
數據
+關注
關注
8文章
7030瀏覽量
89036 -
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
LLM
+關注
關注
0文章
288瀏覽量
335
原文標題:總結
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法
多模態中NLP與CV融合的方式有哪些?
如何使用多模態信息做prompt
基于圖文多模態領域典型任務
一個真實閑聊多模態數據集TikTalk
利用大語言模型做多模態任務
如何利用LLM做多模態任務?
邱錫鵬團隊提出具有內生跨模態能力的SpeechGPT,為多模態LLM指明方向

Macaw-LLM:具有圖像、音頻、視頻和文本集成的多模態語言建模
更強更通用:智源「悟道3.0」Emu多模態大模型開源,在多模態序列中「補全一切」

如何利用OpenVINO加速LangChain中LLM任務
大模型+多模態的3種實現方法

自動駕駛和多模態大語言模型的發展歷程

一文理解多模態大語言模型——下






 工商網監
工商網監
評論