 GPU平臺生態,英偉達CUDA和AMD ROCm對比分析
GPU平臺生態,英偉達CUDA和AMD ROCm對比分析
成熟且完善的平臺生態是 GPU 廠商的護城河。相較于持續迭代的微架構帶來的技術壁壘硬實力,成熟的軟件生態形成的強大用戶粘性將在長時間內塑造 GPU廠商的軟實力。以英偉達 CUDA 為例的軟硬件設計架構提供了硬件的直接訪問接口,不必依賴圖形 API 映射,降低 GPGPU 開發者編譯難度,以此實現高粘性的開發者生態。目前主流的開發平臺還包括 AMD ROCm 以及 OpenCL。
CUDA(Compute Unified Device Architectecture),是 NVIDIA 于 2006 年推出的通用并行計算架構,包含 CUDA 指令集架構(ISA)和 GPU 內部的并行計算引擎。該架構允許開發者使用高級編程語言(例如 C 語言)利用 GPU 硬件的并行計算能力并對計算任務進行分配和管理,CUDA 提供了一種比 CPU 更有效的解決大規模數據計算問題的方案,在深度學習訓練和推理領域被廣泛使用。
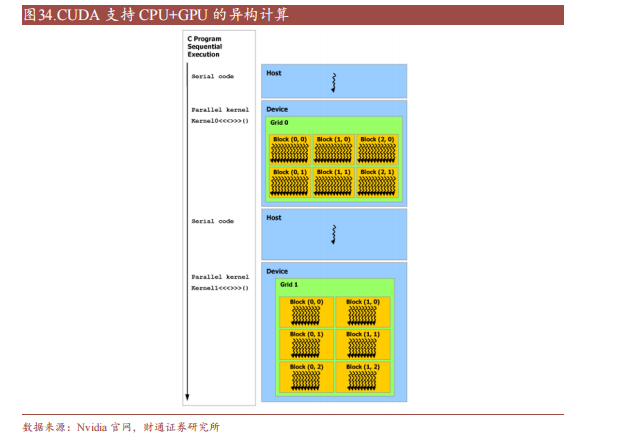
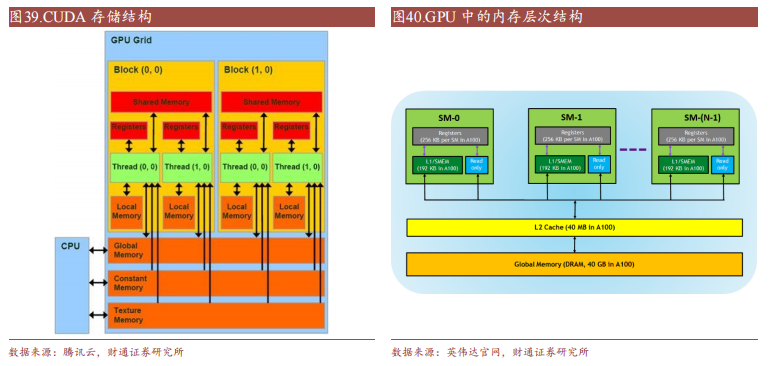
CUDA 除了是并行計算架構外,還是 CPU 和 GPU 協調工作的通用語言。在CUDA 編程模型中,主要有 Host(主機)和 Device(設備)兩個概念,Host 包含 CPU 和主機內存,Device 包含 GPU 和顯存,兩者之間通過 PCI Express 總線進行數據傳輸。在具體的 CUDA 實現中,程序通常劃分為兩部分,在主機上運行的 Host 代碼和在設備上運行的 Device 代碼。Host 代碼負責程序整體的流程控制和數據交換,而 Device 代碼則負責執行具體的計算任務。
一個完整的 CUDA程序是由一系列的設備端函數并行部分和主機端的串行處理部分共同組成的,主機和設備通過這種方式可以高效地協同工作,實現 GPU 的加速計算。
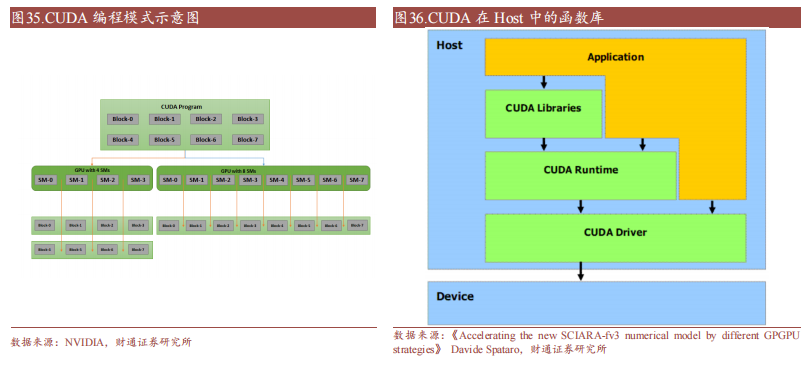
CUDA 在 Host 運行的函數庫包括了開發庫(Libraries)、運行時(Runtime)和驅動(Driver)三大部分。其中,Libraries 提供了一些常見的數學和科學計算任務運算庫,Runtime API 提供了便捷的應用開發接口和運行期組件,開發者可以通過調用 API 自動管理 GPU 資源,而 Driver API 提供了一系列 C 函數庫,能更底層、更高效地控制 GPU 資源,但相應的開發者需要手動管理模塊編譯等復雜任務。
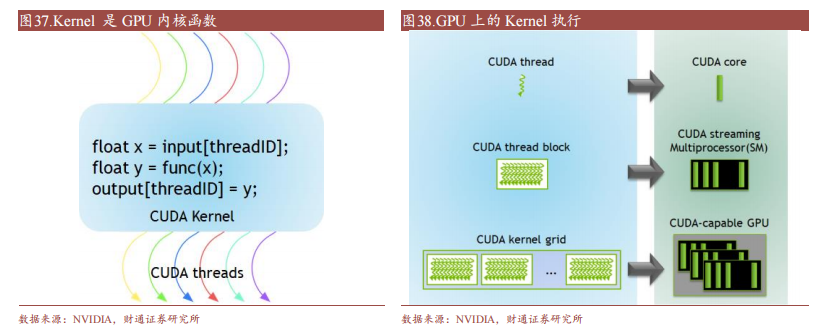
CUDA 在 Device 上執行的函數為內核函數(Kernel)通常用于并行計算和數據處理。在 Kernel 中,并行部分由 K 個不同的 CUDA 線程并行執行 K 次,而有別于普通的 C/C++函數只有 1 次。每一個 CUDA 內核都以一個聲明指定器開始,程序員通過使用內置變量__global__為每個線程提供一個唯一的全局 ID。一組線程被稱為 CUDA 塊(block)。CUDA 塊被分組為一個網格(grid),一個內核以線程塊的網格形式執行。每個 CUDA 塊由一個流式多處理器(SM)執行,不能遷移到 GPU 中的其他 SM,一個 SM 可以運行多個并發的 CUDA 塊,取決于CUDA 塊所需的資源,每個內核在一個設備上執行,CUDA 支持在一個設備上同時運行多個內核。
豐富而成熟的軟件生態是 CUDA 被廣泛使用的關鍵原因。
(1)編程語言:CUDA 從最初的 1.0 版本僅支持 C 語言編程,到現在的 CUDA 12.0 支持 C、C++、Fortran、Python 等多種編程語言。此外,NVIDIA 還支持了如 PyCUDA、ltimesh Hybridizer、OpenACC 等眾多第三方工具鏈,不斷提升開發者的使用體驗。
(2)庫:NVIDIA 在 CUDA 平臺上提供了名為 CUDA-X 的集合層,開發人員可以通過 CUDA-X 快速部署如 cuBLA、NPP、NCCL、cuDNN、TensorRT、OpenCV 等多領域常用庫。
(3)其他:NVIDIA 還為 CUDA 開發人員提供了容器部署流程簡化以及集群環境擴展應用程序的工具,讓應用程序更易加速,使得CUDA 技術能夠適用于更廣泛的領域。
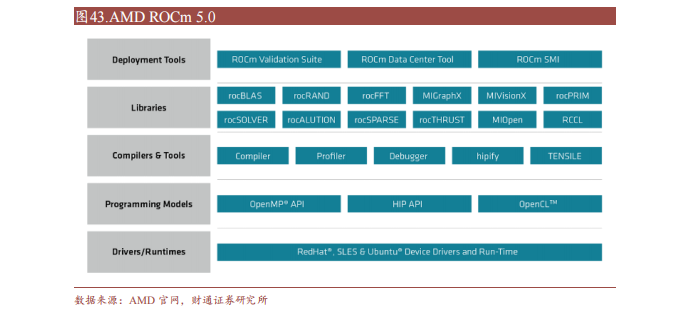
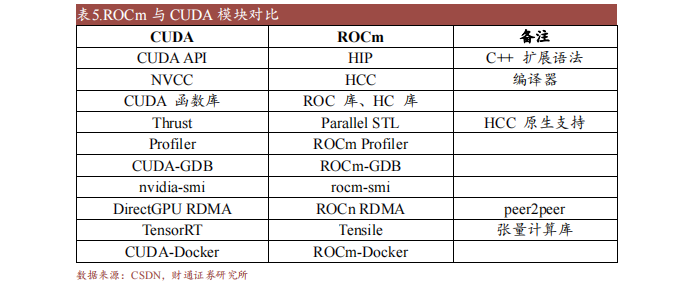
ROCm (Radeon Open Compute Platform )是 AMD 基于開源項目的 GPU計算生態系統,類似于 NVIDIA 的 CUDA。ROCm 支持多種編程語言、編譯器、庫和工具,以加速科學計算、人工智能和機器學習等領域的應用。ROCm還支持多種加速器廠商和架構,提供了開放的可移植性和互操作性。
ROCm 支持HIP(類 CUDA)和 OpenCL 兩種 GPU 編程模型,可實現 CUDA 到 ROCm 的遷移。最新的 ROCm 5.0 支持 AMD Infinity Hub 上的人工智能框架容器,包括TensorFlow 1.x、PyTorch 1.8、MXNet 等,同時改進了 ROCm 庫和工具的性能和穩定性,包括 MIOpen、MIVisionX、rocBLAS、rocFFT、rocRAND 等。
OpenCL(Open Compute Language),是面向異構系統通用并行編程、可以在多個平臺和設備上運行的開放標準。OpenCL 支持多種編程語言和環境,并提供豐富的工具來幫助開發和調試,可以同時利用 CPU、GPU、DSP 等不同類型的加速器來執行任務,并支持數據傳輸和同步。
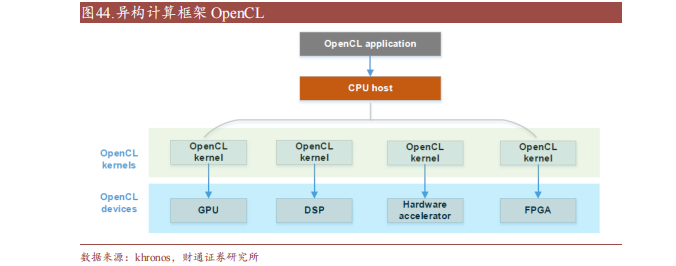
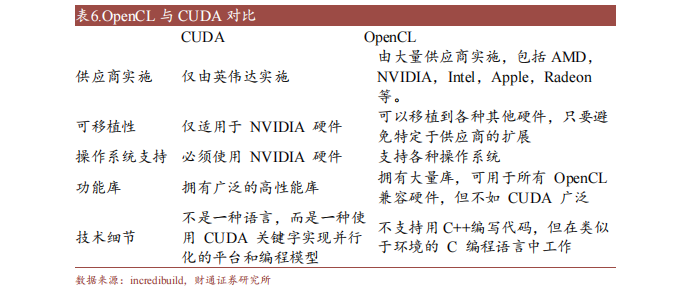
此外,OpenCL 支持細粒度和粗粒度并行編程模型,可根據應用需求選擇合適模型提高性能和效率。而 OpenCL可移植性有限,不同平臺和設備的功能支持和性能表現存在一定差異,與 CUDA相比缺少廣泛的社區支持和成熟的生態圈。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4741瀏覽量
128963 -
指令集
+關注
關注
0文章
226瀏覽量
23384 -
英偉達
+關注
關注
22文章
3776瀏覽量
91138
原文標題:GPU平臺生態,英偉達CUDA和AMD ROCm對比分析
文章出處:【微信號:架構師技術聯盟,微信公眾號:架構師技術聯盟】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
軟銀升級人工智能計算平臺,安裝4000顆英偉達Hopper GPU
打破英偉達CUDA壁壘?AMD顯卡現在也能無縫適配CUDA了
英國公司實現英偉達CUDA軟件在AMD GPU上的無縫運行
英偉達GPU新品規劃與HBM市場展望
英偉達CUDA-Q平臺推動全球量子計算研究
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
英偉達、AMD、英特爾GPU產品及優勢匯總
印度政府考慮購買英偉達GPU以發展人工智能生態系統
英偉達GPU壟斷局面下,開源能否成為顛覆市場的關鍵力量?






 工商網監
工商網監
評論