 小規模的web應用該怎么設置
小規模的web應用該怎么設置
我在研究HikariCP(一個數據庫連接池)時無意間在HikariCP的Github wiki上看到了一篇文章(即前面給出的鏈接),這篇文章有力地消除了我一直以來的疑慮,看完之后感覺神清氣爽。故在此做譯文分享。
接下來是正文
數據庫連接池的配置是開發者們常常搞出坑的地方,在配置數據庫連接池時,有幾個可以說是和直覺背道而馳的原則需要明確。
1萬并發用戶訪問
想象你有一個網站,壓力雖然還沒到Facebook那個級別,但也有個1萬上下的并發訪問——也就是說差不多2萬左右的TPS。那么這個網站的數據庫連接池應該設置成多大呢?結果可能會讓你驚訝,因為這個問題的正確問法是:
“這個網站的數據庫連接池應該設置成多小呢?”
下面這個視頻是Oracle Real World Performance Group發布的,請先看完:
http://www.dailymotion.com/video/x2s8uec
(因為這視頻是英文解說且沒有字幕,我替大家做一下簡單的概括:)
視頻中對Oracle數據庫進行壓力測試,9600并發線程進行數據庫操作,每兩次訪問數據庫的操作之間sleep 550ms,一開始設置的中間件線程池大小為2048:
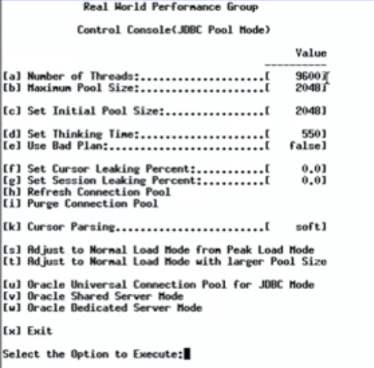
初始的配置
壓測跑起來之后是這個樣子的:

2048連接時的性能數據
每個請求要在連接池隊列里等待33ms,獲得連接后執行SQL需要77ms
此時數據庫的等待事件是這個熊樣的:

各種buffer busy waits
各種buffer busy waits,數據庫CPU在95%左右(這張圖里沒截到CPU)
接下來,把中間件連接池減到1024(并發什么的都不變),性能數據變成了這樣:

連接池降到1024后
獲取鏈接等待時長沒怎么變,但是執行SQL的耗時減少了。
下面這張圖,上半部分是wait,下半部分是吞吐量
wait和吞吐量
能看到,中間件連接池從2048減半之后,吐吞量沒變,但wait事件減少了一半。
接下來,把數據庫連接池減到96,并發線程數仍然是9600不變。

96個連接時的性能數據
隊列平均等待1ms,執行SQL平均耗時2ms。
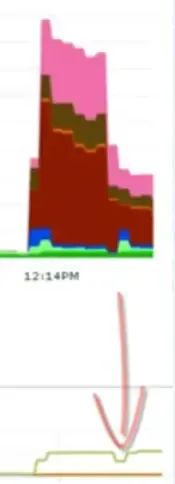
wait事件幾乎沒了,吞吐量上升。
沒有調整任何其他東西,僅僅只是縮小了中間件層的數據庫連接池,就把請求響應時間從100ms左右縮短到了3ms。
But why?
為什么nginx只用4個線程發揮出的性能就大大超越了100個進程的Apache HTTPD?回想一下計算機科學的基礎知識,答案其實是很明顯的。
即使是單核CPU的計算機也能“同時”運行數百個線程。但我們都[應該]知道這只不過是操作系統用時間分片玩的一個小把戲。一顆CPU核心同一時刻只能執行一個線程,然后操作系統切換上下文,核心開始執行另一個線程的代碼,以此類推。給定一顆CPU核心,其順序執行A和B永遠比通過時間分片“同時”執行A和B要快,這是一條計算機科學的基本法則。一旦線程的數量超過了CPU核心的數量,再增加線程數系統就只會更慢,而不是更快。
這幾乎就是真理了……
有限的資源
上面的說法只能說是接近真理,但還并沒有這么簡單,有一些其他的因素需要加入。當我們尋找數據庫的性能瓶頸時,總是可以將其歸為三類:CPU、磁盤、網絡。把內存加進來也沒有錯,但比起磁盤和網絡,內存的帶寬要高出好幾個數量級,所以就先不加了。
如果我們無視磁盤和網絡,那么結論就非常簡單。在一個8核的服務器上,設定連接/線程數為8能夠提供最優的性能,再增加連接數就會因上下文切換的損耗導致性能下降。數據庫通常把數據存儲在磁盤上,磁盤又通常是由一些旋轉著的金屬碟片和一個裝在步進馬達上的讀寫頭組成的。讀/寫頭同一時刻只能出現在一個地方,然后它必須“尋址”到另外一個位置來執行另一次讀寫操作。所以就有了尋址的耗時,此外還有旋回耗時,讀寫頭需要等待碟片上的目標數據“旋轉到位”才能進行操作。使用緩存當然是能夠提升性能的,但上述原理仍然成立。
在這一時間段(即"I/O等待")內,線程是在“阻塞”著等待磁盤,此時操作系統可以將那個空閑的CPU核心用于服務其他線程。所以,由于線程總是在I/O上阻塞,我們可以讓線程/連接數比CPU核心多一些,這樣能夠在同樣的時間內完成更多的工作。
那么應該多多少呢?這要取決于磁盤。較新型的SSD不需要尋址,也沒有旋轉的碟片。可別想當然地認為“SSD速度更快,所以我們應該增加線程數”,恰恰相反,無需尋址和沒有旋回耗時意味著更少的阻塞,所以更少的線程[更接近于CPU核心數]會發揮出更高的性能。只有當阻塞創造了更多的執行機會時,更多的線程數才能發揮出更好的性能。
網絡和磁盤類似。通過以太網接口讀寫數據時也會形成阻塞,10G帶寬會比1G帶寬的阻塞少一些,1G帶寬又會比100M帶寬的阻塞少一些。不過網絡通常是放在第三位考慮的,有些人會在性能計算中忽略它們。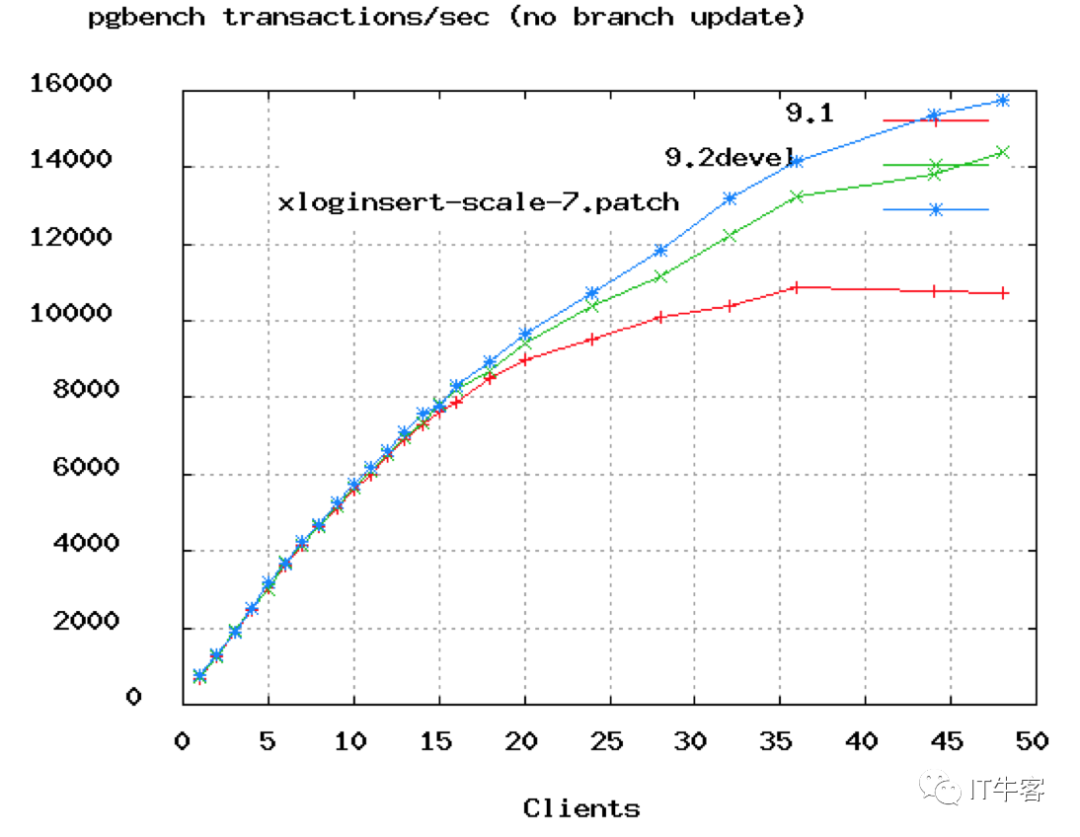
上圖是PostgreSQL的benchmark數據,可以看到TPS增長率從50個連接數開始變緩。在上面Oracle的視頻中,他們把連接數從2048降到了96,實際上96都太高了,除非服務器有16或32顆核心。
計算公式
下面的公式是由PostgreSQL提供的,不過我們認為可以廣泛地應用于大多數數據庫產品。你應該模擬預期的訪問量,并從這一公式開始測試你的應用,尋找最合適的連接數值。
連接數 = ((核心數 * 2) + 有效磁盤數)
核心數不應包含超線程(hyper thread),即使打開了hyperthreading也是。如果活躍數據全部被緩存了,那么有效磁盤數是0,隨著緩存命中率的下降,有效磁盤數逐漸趨近于實際的磁盤數。這一公式作用于SSD時的效果如何尚未有分析。
按這個公式,你的4核i7數據庫服務器的連接池大小應該為((4 * 2) + 1) = 9。取個整就算是是10吧。是不是覺得太小了?跑個性能測試試一下,我們保證它能輕松搞定3000用戶以6000TPS的速率并發執行簡單查詢的場景。如果連接池大小超過10,你會看到響應時長開始增加,TPS開始下降。
筆者注:
這一公式其實不僅適用于數據庫連接池的計算,大部分涉及計算和I/O的程序,線程數的設置都可以參考這一公式。我之前在對一個使用Netty編寫的消息收發服務進行壓力測試時,最終測出的最佳線程數就剛好是CPU核心數的一倍。
公理:你需要一個小連接池,和一個充滿了等待連接的線程的隊列
如果你有10000個并發用戶,設置一個10000的連接池基本等于失了智。1000仍然很恐怖。即是100也太多了。你需要一個10來個連接的小連接池,然后讓剩下的業務線程都在隊列里等待。連接池中的連接數量應該等于你的數據庫能夠有效同時進行的查詢任務數(通常不會高于2*CPU核心數)。
我們經常見到一些小規模的web應用,應付著大約十來個的并發用戶,卻使用著一個100連接數的連接池。這會對你的數據庫造成極其不必要的負擔。
-
cpu
+關注
關注
68文章
10863瀏覽量
211781 -
數據庫
+關注
關注
7文章
3799瀏覽量
64395 -
Web應用
+關注
關注
0文章
16瀏覽量
3482
原文標題:數據庫鏈接池終于搞對了,這次直接從100ms優化到3ms!
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
貼片機中小規模生產
用中小規模集成芯片設計并制作一種雙工對講機
小規模集成芯片電氣特性測試
三星2010存儲芯片將出現小規模短缺情況
如何在Win 2003環境中設置一個Web服務器
多相技術以小規模實現大型濾波器
百度Apollo無人駕駛車在今年開始小規模下放
創造億萬人之中只屬于你的那個“人”:微軟Avatar Framework小規模公測
電容補償柜的參數該如何設置
百望云緊急完成系統升級,可滿足小規模納稅人3%減征1%開票新政






 工商網監
工商網監
評論