 FPGA常用運算模塊-除法器
FPGA常用運算模塊-除法器
寫在前面
本文是本系列的第四篇,本文主要介紹FPGA常用運算模塊-除法器,xilinx提供了相關的IP以便于用戶進行開發使用。
除法器
除法器生成器IP 創建了一個基于基數 2 非恢復除法或具有預分頻的高基數除法的整數除法電路。 Radix-2 算法利用 FPGA 邏輯來實現一系列吞吐量選項,包括單周期,而高基數算法在較低吞吐量下利用 DSP 切片,但通過重用來減少資源。
該IP符合 AXI4-Stream 的接口。操作數最大為 64 位寬的整數除法。提供Radix-2、LUTMult 和High Radix 實現算法以允許選擇資源和延遲權衡。可選操作數寬度、同步控制和可選延遲。可選的除以零檢測。
三種除法器實現方式
LUTMult
除數倒數的簡單查找估計,后跟乘數。 由于倒數估計中需要偏差,因此僅支持余數輸出類型。 如果用于創建小數輸出,此偏差會引入偏移(錯誤)。 推薦用于小于或等于 12 位的操作數寬度。 此實現方式使用 DSP Slice、塊 RAM 和少量 FPGA 邏輯原語(寄存器和 LUT)。 對于可以使用 Radix2 或 LUTMult 選項的操作數寬度,由于使用了 DSP 和塊 RAM 原語,LUTMult 解決方案提供了使用較少 FPGA 邏輯資源的解決方案。
該實現方式特點如下:
提供了帶有整數余數的商;
可以使用流水線并行架構以提高吞吐量;
可配置延遲;
2 到 17 位的分頻寬度;
2 到 12 位的除數寬度(被除數寬度和除數寬度之和限制為 23 位);
獨立的除數和除數位寬;
使用單個時鐘的完全同步設計;
支持無符號或二進制補碼有符號數。
Radix-2
使用整數操作數的基數 2 非恢復整數除法,允許生成小數或整數余數。 對于小于 16 位左右的操作數寬度或需要高吞吐量的應用程序,建議使用該種實現方式。 實現使用 FPGA 邏輯原語(寄存器和 LUT)。Radix2 解決方案不使用 DSP 或塊 RAM 原語,因此當其他地方需要這些原語時,建議使用此實現。
該實現方式特點如下:
提供整數或小數余數的商;
流水線并行架構以提高吞吐量;
減少流水線大小與吞吐量可選;
被除數寬度從 2 到 64 位;
除數寬度從 2 到 64 位;
獨立的被除數、除數和小數位寬;
使用單個時鐘的同步設計;
支持無符號數或二進制補碼有符號數;
可以實現 1/X(倒數)功能。
High Radix
帶有預縮放的高基數除法。 對于大于 16 位左右的操作數寬度,建議這樣做。 此實現使用 DSP Slice 和 Block RAM。
該實現方式特點如下:
通過預縮放啟用高基數除法;
提供可選的商和小數輸出;
可配置寬度、同步控制、可選延遲和除以零檢測;
使用 DSP Slices。
Divider Generator 內核使用三種實現中的一種。 LUTMult 推薦用于非常小的操作數寬度、高吞吐量以及必須最小化切片使用的情況。 對于較小的操作數寬度、高吞吐量或必須最小化 DSP 切片使用的情況,建議使用 Radix-2 解決方案。 對于較大的操作數寬度,建議使用高基數解決方案。
三種實現方式延遲對比
分頻器內核的延遲是 AXI4-Stream 配置參數和所選算法延遲的函數。 當 AXI4-Stream 模式設置為非阻塞且核心算法和吞吐量設置為每個時鐘周期輸入一個樣本時,延遲僅是一個常數。 如果選擇了完整的 AXI4-Stream 行為。 這是因為 FIFO 用于管理此模式的數據,并且 FIFO 的深度增加了延遲。
LUTMult
完全流水線化的 LUTMult 的延遲為 8。
Radix-2
完全流水線分頻器的延遲(內核生成第一個有效輸出之前所需的啟用時鐘周期數)是被除數位寬的函數。 如果需要小數輸出,則完全流水線延遲也是小數位寬的函數。 一般來說:
對于整數余數除法器,完全流水線延遲的數量級為 M,其中 M 是商的寬度。
對于分數余數除法器,完全流水線延遲的數量級為 M + F,其中 F 是分數輸出的寬度。
下表提供了用于分頻器選擇的完全流水線延遲公式的列表。 通過完整的流水線,可以實現最大可能的性能。 當每格時鐘數為 1 時,可以手動將延遲設置為介于 0 和表 2-1 中所示值之間的數字。 這允許以降低內核可以計時的最大時鐘頻率為代價來減少內核的延遲。 減少延遲會減少使用的寄存器數量,但 LUT 計數保持大致相同。
| Signed | Fractional | Clocks Per Division | Fully Pipelined Latency |
|---|---|---|---|
| FALSE | FALSE | 1 | M+A+2 |
| FALSE | FALSE | >1 | M+A+3 |
| FALSE | TRUE | 1 | M+F+A+2 |
| FALSE | TRUE | >1 | M+F+A+3 |
| TRUE | FALSE | 1 | M+A+4 |
| TRUE | FALSE | >1 | M+A+5 |
| TRUE | TRUE | 1 | M+F+A+4 |
| TRUE | TRUE | >1 | M+F+A+5 |
M = 被除數和商寬度,F = 小數寬度,A = AXI 接口的總延遲。
High Radix
表中位寬范圍為被除數和商寬度 + 分數寬度。
| 4 to 12 | 13 to 26 | 27 to 40 | 41 to 54 | 55 to 68 | 69 to 82 |
|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | 7 |
表中行位寬范圍為被除數和商寬度 + 分數寬度。
| Divisor Width | 4 to 12 | 13 to 26 | 41 to 54 | 27 to 40 | 55 to 68 | 69 to 82 |
|---|---|---|---|---|---|---|
| 4 to 8 | 16 | 20 | 29 | 24 | 33 | 37 |
| 9 to 18 | 17 | 21 | 30 | 25 | 34 | 38 |
| 19 to 32 | 18 | 22 | 31 | 26 | 35 | 39 |
| 33 to 35 | 19 | 23 | 32 | 27 | 36 | 40 |
| 36 to 48 | 20 | 24 | 33 | 28 | 37 | 41 |
| 49 to 52 | 22 | 26 | 35 | 30 | 39 | 43 |
| 53 to 54 | 23 | 27 | 36 | 31 | 40 | 44 |
三種實現方式吞吐量對比
LUTMult
此解決方案始終支持全吞吐量。
Radix-2
Clocks per Division 參數允許對吞吐量與資源進行一系列選擇。當 Clocks per Division 設置為 1 時,內核是完全流水線化的,因此每個時鐘周期的最大吞吐量為一個分頻,但使用的資源最多。 Clock per Division 設置為 2、4 和 8,對于較小的內核尺寸,這些相應的因素會降低吞吐量。AXI 接口為非阻塞提供 0 的額外延遲,無輸出線程的阻塞為 1,輸出線程為阻塞 (m_axis_dout_tready) 為 3。但是,當選擇阻塞模式時,延遲會隨運行時間而變化。
High Radix
迭代過程是作為循環來實現的,以減少資源。 這意味著必須推遲新輸入,直到在迭代電路中完成先前的計算。 因此,最大可能的吞吐量是每個時鐘 1/N 分頻,其中 N 是所需的迭代次數。 然而,為了達到這個最大吞吐量,輸入可能需要是突發的。 這是因為迭代引擎可以通過管道的每個階段進行流水線化,為隔行分割提供一個輪播位置。
添加 AXI4-Stream 接口后,平均吞吐量保持不變。 阻塞模式為數據提供了 FIFO 緩沖元素,因此無法對內核何時準備好接受新數據進行確定性預測。 對于 NonBlocking 模式,時序更可預測。 Vivado IDE 中的分頻器生成器接口提供分頻器以恒定間隔連續接受輸入的速率(N 中的 1)的反饋。 這在接口的吞吐量字段上表示,并表示為每 N 個啟用的時鐘周期 1 個輸入。
IP核圖示及端口介紹
IP核圖示如下圖所示:
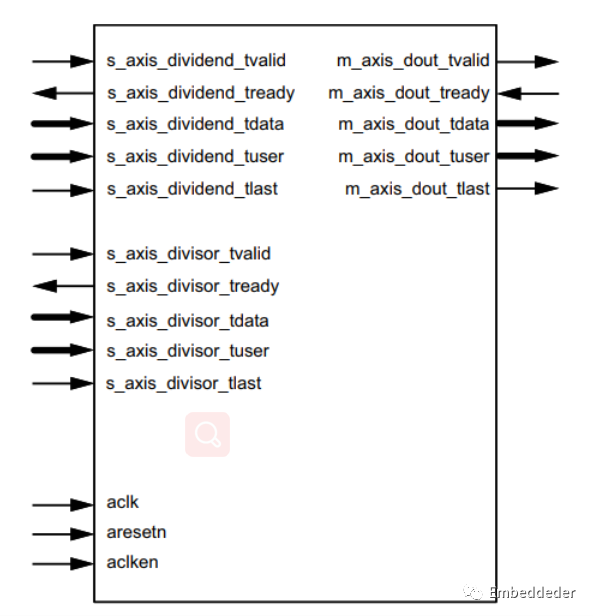
| Signal | I/O | Optional | Description |
|---|---|---|---|
| aclk | I | No | 時鐘 |
| ACLKEN | I | Yes | 高有效使能 |
| ARESETn | I | Yes | Active-Low 同步清零(可選,始終優先于 ACLKEN) ARESETn 應被置位或置位不少于兩個 aclk 周期。 |
| s_axis_dividend_tvalid | I | No | s_axis_dividend 通道的 tvalid。(被除數) |
| s_axis_dividend_tready | O | Yes | s_axis_dividend 通道的 tready。(被除數) |
| s_axis_dividend_tdata | I | No | s_axis_dividend 通道的 tdata。 (被除數) |
| s_axis_dividend_tuser | I | Yes | s_axis_dividend 通道的 tuser。(被除數) |
| s_axis_dividend_tlast | I | Yes | s_axis_dividend 通道的 tlast。(被除數) |
| s_axis_divisor_tvalid | I | No | s_axis_divisor 通道的 tvalid。(除數) |
| s_axis_divisor_tready | O | Yes | s_axis_divisor 通道的 tready 。(除數) |
| s_axis_divisor_tdata | I | No | s_axis_divisor 通道的 tdata。 (除數) |
| s_axis_divisor_tuser | I | Yes | s_axis_divisor 通道的 tuser。 (除數) |
| s_axis_divisor_tlast | I | Yes | s_axis_divisor 通道的 tlast。(除數) |
| m_axis_dout_tvalid | O | No | m_axis_dout 通道的 tvalid。(結果) |
| m_axis_dout_tready | I | Yes | m_axis_dout 通道的 tready。(結果) |
| m_axis_dout_tdata | O | No | m_axis_dout 通道的 tdata。(結果) |
| m_axis_dout_tuser | O | Yes | m_axis_dout 通道的 tuser。(結果) |
| m_axis_dout_tlast | O | Yes | m_axis_dout 通道的 tlast。(結果) |
運算方式區別
LUTMult
此參數化解決方案將M位寬的變量除數除以N位寬的變量除數。輸出由商和整數余數組成。除法的結果是M位寬的商和N位寬的整數余數。
被除數商除數整數余數
當選擇有符號運算時,所有操作數和結果都使用兩個補號,但會導致結果的大小減少一位。
分數余數整數余數除數
LUTMult解決方案支持可選的零除輸出。對于除零,商和余數結果是未定義的。LUTMult解決方案始終支持全吞吐量(每個時鐘周期一個結果)。延遲可以配置為完全流水線所需的最大值(超過該值,進一步的寄存器將無法提高性能)。由于LUTMult解使用倒數的常數有限精度估計乘以被除數,從而獲得結果,因此除數的最大寬度是被除數寬度的函數。操作數寬度之和限制為23位。就商和余數的符號而言,LUTMult解決方案以與Radix2解決方案相同的方式處理負操作數。
Radix-2
此參數化解決方案將M位寬的變量除數除以N位寬的變量除數。輸出由商和整數余數或分數結果(商繼續超過二進制點)組成。在整數余數情況下,除法的結果是商的M位寬字段和整數余數的N位寬字段。對于帶整數余數的有符號模式,商和余數的正負也對應于下式。
被除數商除數整數余數
在分數情況下,結果是商的M位寬字段,結果的分數部分為F位寬字段。
分數余數整數余數除數
當選擇有符號運算時,所有操作數和結果都使用一個2補符號位,從而使結果的大小減少一位。
分數余數整數余數除數
對于帶分數輸出的帶符號模式,在商和分數字段中都有符號位。對于除零,商、余數和分數結果未定義。IP是高度流水化的。核心的吞吐量是可配置的,可以從每個分區1個時鐘周期減少到每個分區2、4或8個時鐘周期,以減少資源。可以獨立設置被除數和除數的位寬度。商的位寬度等于被除數的位寬度。整數余數的位寬度等于除數的寬度。對于分數輸出,余數位寬度與被除數和除數無關。核心處理2到64位的數據范圍,用于被除數、除數和分數輸出。
除法器可用于實現X的倒數;這就是1/X函數。為此,將被除數位寬度設置為2,并選擇分數模式。然后,對于無符號或有符號運算,被除數輸入都綁定到01,并且X值通過除數輸入提供。上電復位或ARESETn后,IP的輸出商和分數的零,直到出現新結果。
High Radix Solution
高基數實現在采用加速高基數除法算法之前,通過預縮放操作數執行除法。該設計是完全流水線的最大時鐘頻率。首先,對除數進行歸一化,然后對其倒數進行估計。兩個操作數都乘以此估計值,使除數更接近1。預刻度的精度和精確度決定了在每次后續迭代中可以解析的商位數。預縮放除數接近于1的事實允許新商位的估計正好是上一次迭代剩余的頂部位。迭代操作本身以進位保存表示法執行,因此沒有長進位鏈限制性能。由于只使用剩余的頂部位作為估計值,且除數不完全為1,因此每次迭代的內部結果中都會出現錯誤;因此,在每次迭代中解析的商位與先前解析的位略微重疊,以允許在后續迭代中校正錯誤。 由于迭代計算由進位-保存乘法和減法組成,因此它非常適合于DSP(乘法-加法)切片,從而提供高效、低延遲的迭代。
協議描述
該內核遵循AXI4流規范。
AXI4-Stream注意事項
轉換為AXI4流接口,使得接口協議更加標準并增強了IP的互操作性。除aclk、ACLKEN和ARESETn等常規控制信號外,除法器發生器的所有輸入和輸出均通過AXI4流通道傳輸。通道由tvalid和tdata always以及幾個可選端口和字段組成。在除法器中,支持的可選端口為tready、tlast和tuser。tvalid和tready一起執行握手以傳輸消息,其中有效負載為tdata、tuser和tlast。除法器對tdata中包含的操作數進行操作,并在輸出通道的tdata中輸出結果。除法器不使用input、tuser和tlast,但提供了以與tdata延遲傳輸的功能。
除法器使用輸出tuser保持除法零(divide_by_zero)指示信號。這種將tlast和tuser從輸入傳遞到輸出的功能旨在簡化系統中除法器的使用。例如,除法器可能對流式分組數據進行操作。在此示例中,可以將核心配置為通過打包數據通道的tlast,從而減小工作量。
基本握手協議
下圖顯示了AXI4流通道中的數據傳輸。
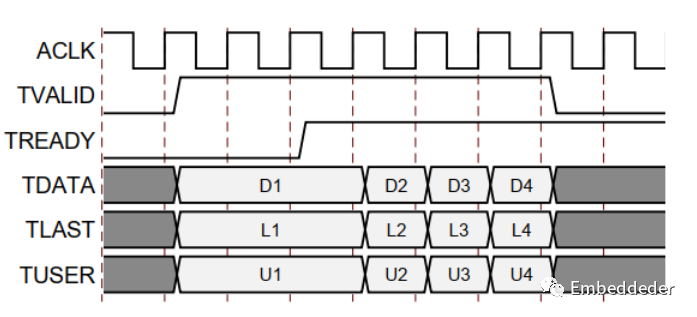
tvalid 由通道的源(主)端驅動,而tready 由接收器(從)驅動。 tvalid 表示有效載荷字段(tdata、tuser 和 tlast)中的值有效。 tready 表示從機已準備好接收數據。 當循環中 tvalid 和treaty 都為TRUE 時,就會發生傳輸。master 和 slave 分別為下一次傳輸適當地設置了 tvalid 和tready。
非阻塞模式
除法器提供了一種模式,用于簡化從該內核以前的非 AXI 版本遷移。 非阻塞用于表示一個輸入通道上缺少數據不會導致另一通道上的傳入數據被緩沖。 因為在 NonBlocking 模式下,輸出通道沒有不穩定的信號。 并非總是需要 AXI4-Stream 的完整流量控制。 使用 FlowControl 參數或用戶界面字段選擇阻塞或非阻塞行為。Blocking 或 NonBlocking 的選擇適用于整個IP,而不是單獨的每個通道。 通道仍然具有非可選的 tvalid 信號,這類似于采用 AXI4-Stream 之前許多內核上的新數據 (ND) 信號。 由于沒有阻止數據流的功能,內部實現大大簡化,因此這種模式需要的資源更少。 對于希望從 AXI 之前的版本遷移到此版本且更改最少的用戶,建議使用此模式。
當所有當前的輸入通道都接收到一個有效的 tvalid(并且tready被斷言),那么這個操作是有效的。這是為了允許從 v3.0 進行最小的遷移。如果一個通道接收到 tvalid 而另一個沒有接收,則不會發生操作,即使存在和斷言tready也是如此。 因此,與完全符合 AXI4-Stream 的阻塞模式不同,在非阻塞模式下可以忽略單個通道上的有效事務。 出于性能考慮,ARESETn 是在內部的,這會將其操作延遲一個時鐘周期。效果是在取消置位 ARESETn 之后的循環中,內核仍然復位并且不接受輸入。 tvalid 在此周期的輸出通道上也處于非活動狀態。
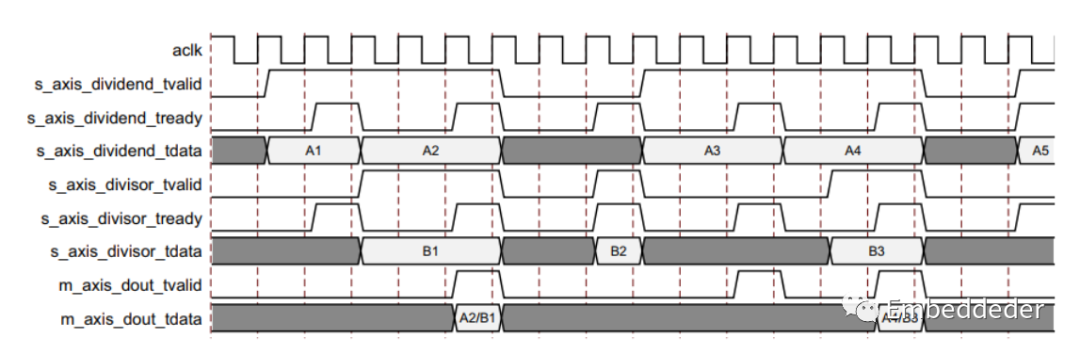
上圖顯示了操作中的非阻塞模式。 內核的延遲為零。 正如 s_axis_dividend_tready 和 s_axis_divisor_tready 所指示的,它們最終是相同的信號,內核可以每三個周期接受一次數據。 由于 s_axis_divisor_tvalid 被置低,被除數通道中的數據 A1 被忽略。 數據輸入 A2 和 B1 被接受,因為 tvalids 和 traily 都被斷言。
阻塞模式
術語“阻塞”意味著每個通道都在緩沖數據以供使用。 AXI4-Stream 的完整流控制有助于系統設計,因為數據流是自我調節的。使用 FlowControl 參數選擇阻塞或非阻塞行為。 背壓(tready)的存在可以防止數據丟失,因此只有在下游數據路徑準備好處理數據時才會傳播數據。
除法器有兩個輸入通道和一個輸出通道。 當所有輸入通道都有可用的有效數據時,就會發生操作,結果在輸出上可用。 如果由于 m_axis_dout_tready 為低而阻止輸出裝載數據,則數據會在內部的輸出緩沖區中累積。當這個輸出緩沖器快滿時,內核停止進一步的操作。 這可以防止輸入緩沖區為新操作裝載數據,以便在輸入新數據時填充輸入緩沖區。 當輸入緩沖區填滿時,它們各自(s_axis_divisor_tready 和 s_axis_dividend_tready)被置為無效以防止進一步輸入。
從某種意義上說,這兩個輸入通道是相互關聯的,每個通道都必須先接收經過有效的數據,然后才能繼續進行操作。 因此,有一種額外的阻塞機制,其中一個輸入通道不接收有效數據,而另一個接收。 在這種情況下,經過有效的數據存儲在通道的輸入緩沖區中。
在這種情況下,經過有效的數據存儲在通道的輸入緩沖區中。 在這種情況的幾個循環之后,接收數據的通道的緩沖區被填滿并且該通道的tready被取消斷言,直到饑餓的通道接收到一些數據。
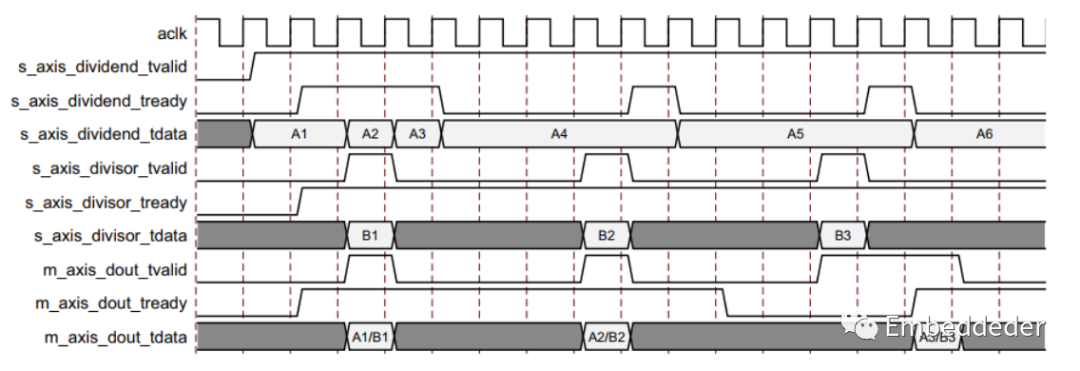
上圖顯示了阻塞行為和背壓。 通道 s_axis_dividend 上的第一個數據與通道 s_axis_divisor 上的第一個數據配對,第二個與第二個數據配對,依此類推。 這展示了“阻塞”的概念。 概念上使用通道名稱 s_axis_dividend 和 s_axis_divisor。 兩者都可以表示除數或被除數通道。
并且在圖中進一步顯示了數據輸出是如何被延遲的,不僅是延遲,還有握手信號 m_axis_dout_tready。 是背壓的。 輸出上的持續背壓以及輸入上的數據可用性最終會導致核心緩沖區飽和,從而導致核心發出信號,表明它無法再通過取消斷言來接受進一步的輸入通道的tready信號。
這個例子中的最小延遲是兩個周期,但需要注意的是,Blocking 操作中的延遲并不是一個有用的概念。 一個重要的思想是每個通道都充當一個隊列,確保每個通道上的第一個、第二個、第三個數據樣本與其他通道上的相應樣本配對以進行每次操作。
TDATA包
AXI4-Stream 接口中的遵循特定的命名法。 在該內核中,操作數通過通道 tdata 端口傳入或傳出內核。 為了簡化協議的互操作性,如果需要時,首先擴展 tdata 中可以獨立使用的每個子字段,以適應 8 位倍數的位字段。 對于輸出 DOUT 通道,結果字段符號擴展到字節邊界。 由字節方向添加的位被內核忽略并且不會導致額外的資源使用。
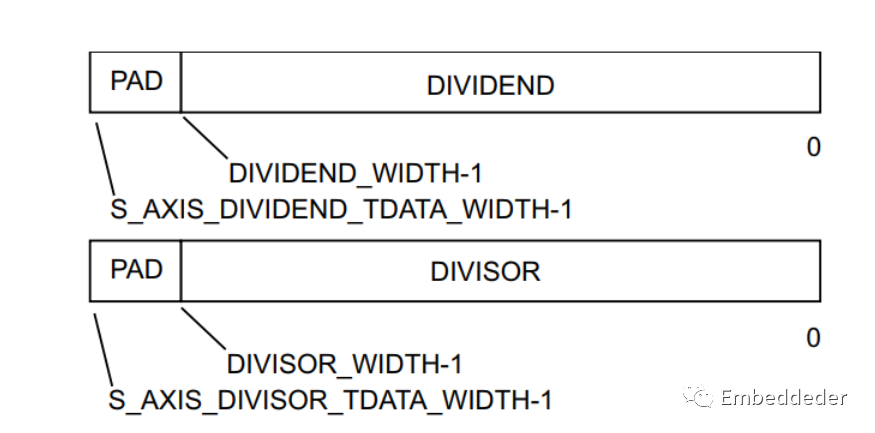
被除數和除數通道的 TDATA 結構
輸入通道 Dividend 和 Divisor 僅在其 tdata 字段中攜帶其操作數。 對于每個操作數占據最低有效位。tdata 端口寬度本身是包含操作數所需的字節寬度的最小倍數。
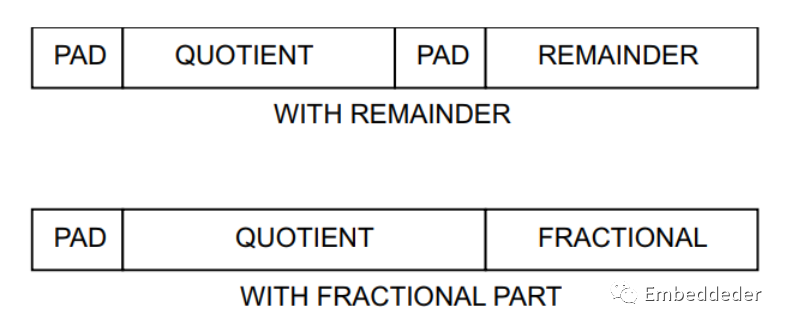
輸出(DOUT)通道的TDATA結構
m_axis_dout_tdata 的結構比較復雜。 此端口包含商和(余數或小數輸出如果存在)。當余數類型設置為余數時,兩個輸出被認為是分開的,因此在串聯以形成 m_axis_dout_tdata 信號之前是面向字節的。 當余數類型為小數時,小數部分被視為商的擴展,因此這兩個字段在填充到下一個字節邊界之前連接。
TLAST and TUSER握手
AXI4-Stream 中的 tlast 用于表示數據塊的最后一次傳輸。 tuser 用于限定或擴充 tdata 中的主要數據的輔助信息。 除法器在每個樣本的基礎上運行,其中每個操作都獨立于之前或之后的任何操作。因此,不需要在除法器上放置 tlast。
在每個輸入通道上支持 tlast 和 tuser 信號純粹是作為系統設計的一個可選輔助,在這種情況下,通過除法器的數據流確實具有一些分組化或輔助字段,但不是與除法器相關。 傳遞 tlast 或 tuser 的功能消除了通過除法器將延遲匹配到 tdata 路徑的負擔,該路徑可以是可變的。
當選擇Divide_by_zero detect(除以零檢測)時,指示除以零的信號在輸出通道tuser端口的最低有效位上輸出。
TLAST Options
每個輸入通道的 tlast 是可選的。 每個存在時,都可以通過除法器,或者,當多個通道啟用了 tlast 時,可以通過 tlast 輸入的邏輯 AND 或邏輯 OR。 當任何輸入通道上不存在 tlasts時,輸出通道也沒有 tlast。
TUSER Options
每個輸入通道的 tuser 是可選的。 每個都有用戶可選擇的寬度。 Divider IP也可能生成一個 tuser 位。 這是選擇divide_by_zero 檢測時。divide_by_zero 位占據最低有效位置,然后是來自除數通道的 tuser,然后是來自最高有效位置的被除數通道的 tuser。

除法器IP配置
除法器IP配置界面如下:
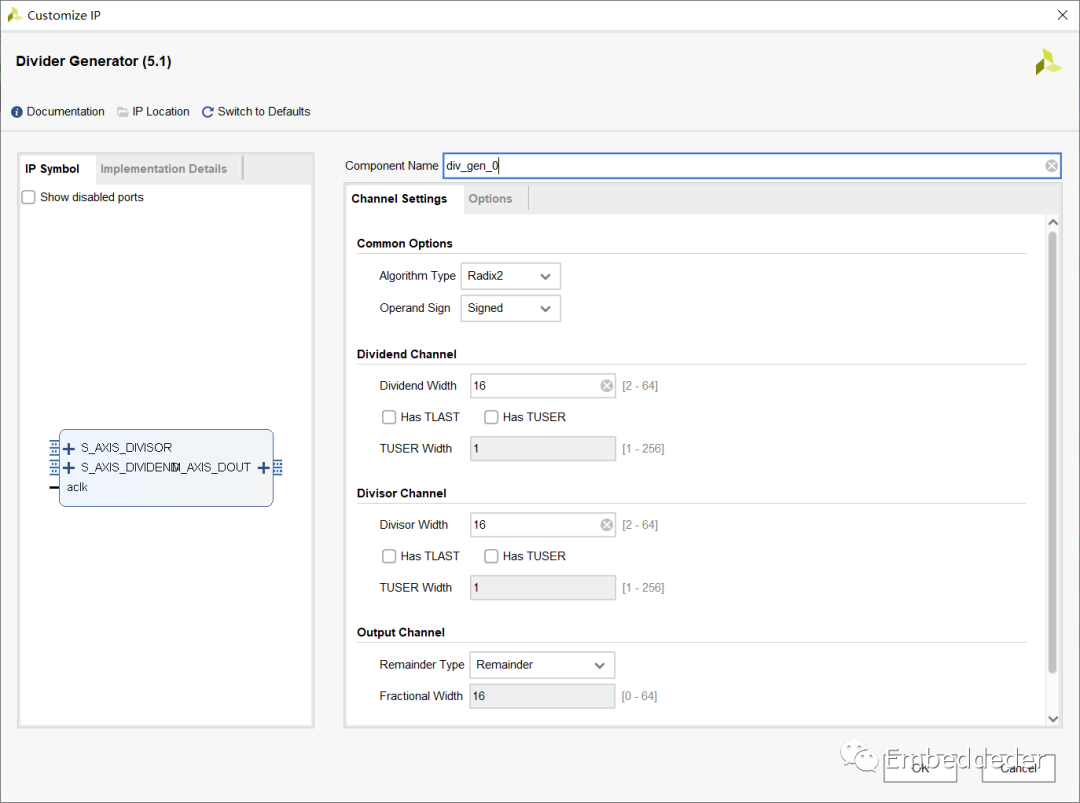
Common Options
描述了兩種實現的參數,并允許選擇除法器實現。
Algorithm Type: 算法類型:這在基數 2、LUTMult 和高基數劃分解決方案之間進行選擇。
Dividend Channel
Dividend Width: 被除數寬度,指定在 DIVIDEND (s_axis_dividend_tdata) 和 QUOTIENT(m_axis_dout_tdata 的子字段)上提供的整數位數。 這必須設置為滿足最大可能的商結果。 由于二進制補碼表示的非對稱性,從被除數到商的位增長是可能的,但僅適用于最大負數除以負數的單個組合(即 -2(M-1)/-1)。 如果需要適應這種情況,被除數(以及商)的寬度可以擴展 1 位。
Has TLAST: 指定此通道是否具有 tlast 端口。 除法器不使用此信息。 該項用于簡化系統設計。tlast信息以和數據路徑相同的延遲傳送到輸出通道。
Has TUSER: 指定此通道是否具有 tuser 端口。 與 tlast 一樣, 除法器不使用此信息。 該項用于簡化系統設計。 tuser 位以和數據路徑相同的延遲傳送到輸出。
TUSER Width: 當 Has tuser 為 TRUE 時可用,這將設置此通道的 tuser 端口的寬度。
Divisor Channel
Divisor Width: 除數寬度。指定在 s_axis_divisor_tdata 的 DIVISOR 字段上提供的整數位數。 當配置有余數輸出時,余數的寬度也等于該參數的值。
Has TLAST: 指定此通道是否具有 tlast 端口。 除法器不使用此信息。 該項用于簡化系統設計。 tuser 位以和數據路徑相同的延遲傳送到輸出。
Has TUSER: 指定此通道是否具有 tuser 端口。 與 tlast 一樣, 除法器不使用此信息。 該項用于簡化系統設計。 tuser 位以和數據路徑相同的延遲傳送到輸出。
TUSER Width: 當 Has tuser 為 TRUE 時可用,這將設置此通道的 tuser 端口的寬度。
Output Channel
Remainder Type: 余數類型。這可以在輸出 tdata 端口 (m_axis_dout_tdata) 的 FRACTIONAL 上顯示的余數類型小數和余數之間進行選擇。分數余數類型是高基數的唯一選項。
Fractional Width: 小數寬度。如果選擇小數余數類型,這將確定在輸出通道 (m_axis_dout_tdata) 的小數字段上提供的位數。 選擇高基數時,總輸出寬度(商部分加小數部分)限制為 82。
商的寬度等于被除數的寬度,并在被除數通道部分設置。
如果divide_by_zero 檢測處于有效狀態,tuser 端口的寬度是當前輸入通道tuser 字段的總和加上1。 如果任一輸入通道具有 tlast 端口,則該通道也具有 tlast 端口。
Detect Divide-by-Zero: 檢測被零除。確定內核在輸出 tuser 端口 (m_axis_dout_tuser) 中是否有 DIVIDE_BY_ZERO 以在執行除以零時發出信號。
Radix-2 Options
Clocks Per Division: 分頻時鐘。確定 Radix-2 解決方案的吞吐量(輸入(或輸出)之間的時鐘間隔)。 此參數的低值會導致高吞吐量,但也會導致更多資源使用。
High Radix and LUTMult Options
Number of iterations (High Radix only) 迭代次數(僅限高基數): 只讀,報告高基數操作模式為每次除法執行的迭代次數。 這設置了分頻器的最大吞吐量。為實現此吞吐量,必須在s_axis_dividend_tready 和 s_axis_divisor_tready 輸出請求時立即提供操作數。
Number of iterations (High Radix only)吞吐量(僅限高基數) :只讀,報告以恒定速率提供操作數時除法器可維持的最大吞吐量。 在 AXI 阻塞模式下,由于緩沖,吞吐量可能略高。 當FlowControl 設置為 NonBlocking 并且輸出通道 DOUT 沒有tready 時,此速率適用。
AXI4-Stream Options
Flow Control: 流控制。阻塞或非阻塞。非阻塞模式提供了從之前版本的分頻器生成器內核的更簡單的遷移路徑。 阻塞模式以一些額外的資源和延遲為代價,簡化了進出其他 AXI4-Stream 阻塞模式內核的數據流管理。
Optimize Goal: 優化目標。這僅適用于阻塞模式。 選擇ACLKEN并優化目標設置為資源時,可能會降低性能。
Output has TREADY: 選擇輸出通道是否有tready信號。 這是允許來自下游的背壓所必需的。例如,如果連接到另一個 AXI4-Stream Blocking內核。 如果沒有tready,下游電路無法停止來自分頻器的數據流,但會節省一些資源。
Output TLAST Behavior: 輸出 TLAST行為。選擇輸出通道 tlast 信號的來源。 當沒有或只有一個輸入通道有 tlast 時,輸出 tlast 不存在或適當地從輸入 tlast 派生。當兩個輸入通道都有 tlast 時,輸出通道 tlast 可以單獨從兩個輸入的邏輯 OR或邏輯 AND 得出。
Latency Options
Latency Configuration: 延遲配置。自動(完全流水線)或手動。Radix2 解決方案的延遲配置僅在每格時鐘設置為 1 時才可配置。這是由于迭代反饋,因此當每格時鐘大于 1 時非可選寄存器。
Latency :延遲,當Latency Configuration 設置為Automatic 時,提供從輸入到輸出的延遲,以時鐘使能時鐘周期為單位。 手動時,此字段用于指定所需的延遲。 當不需要高性能(時鐘頻率)時,該字段中較低的值可以節省資源。
Control Signals
ACLKEN :確定內核是否具有時鐘使能輸入 (ACLKEN)。信號ARESETn始終優先于ACLKEN,即無論ACLKEN的狀態如何,ARESETn都生效。
ARESETn :確定內核是否具有低電平有效同步清零輸入 (ARESETn)。為低電平有效。信號 ARESETn 應保持有效至少兩個時鐘周期。 這是因為,為了性能,ARESETn 在被饋送到原語的重置端口之前在內部注冊。
-
dsp
+關注
關注
553文章
8014瀏覽量
349177 -
FPGA
+關注
關注
1629文章
21748瀏覽量
603959 -
接口
+關注
關注
33文章
8617瀏覽量
151311 -
Xilinx
+關注
關注
71文章
2167瀏覽量
121600 -
除法器
+關注
關注
2文章
14瀏覽量
13901
發布評論請先 登錄
相關推薦
基于FPGA的除法器純邏輯設計案例
哪位有模擬除法器的電路仿真?
基于FPGA的除法器
FPGA除法器IP核運算出錯
FPGA中的除法運算及初識AXI總線
乘除法和開方運算的FPGA串行實現
并行除法器 ,并行除法器結構原理是什么?

實例九— 除法器設計

如何實現FPGA中的除法運算
FPGA常用運算模塊-復數乘法器







 工商網監
工商網監
評論