 FPGA常用運算模塊-復數乘法器
FPGA常用運算模塊-復數乘法器
寫在前面
本文是本系列的第五篇,本文主要介紹FPGA常用運算模塊-復數乘法器,xilinx提供了相關的IP以便于用戶進行開發使用。
復數乘法器
復數乘法器IP基于用戶指定的選項實現了符合 AXI4-Stream 的高性能、優化的復數乘法器。兩個被乘數輸入和可選的舍入位在獨立的 AXI4-Stream 通道上作為從接口輸入,結果乘積在 AXI4-Stream 主接口上輸出。在每個通道內,操作數和結果以帶符號的二進制補碼格式表示。操作數寬度和結果寬度是可參數化的。
特點
復數乘法器在許多 DSP 應用中很常見,包括信號混合和快速傅立葉變換。Complex Multiplier IP以笛卡爾形式執行兩個操作數的復數乘法。結果也是笛卡爾形式。
8 位至 63 位輸入精度和高達 127 位輸出精度。
支持截斷或無偏舍入。
可配置的最小延遲。
實施選項包括 3 乘法器、4 乘法器和專用原語解決方案。
使用 LUT 或 DSP Slices 的選項。
復數計算方法
給定兩個操作數,有兩種基本架構來實現復數乘法:
a表示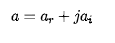
b表示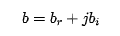
然后得到輸出結果為: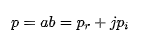
所以直接實現需要四個實數乘法: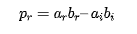
和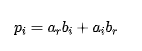
通過整理添加項得到下面的式子:
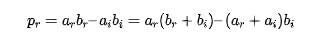
和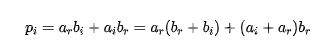
可以設計一種三實乘法器解決方案,將一個乘法器換成三個預組合加法器并增加乘法器字長。
延遲和吞吐量
延遲是可配置的。對于性能表,延遲設置為自動,從而形成完全流水線化的電路。Complex Multiplier 支持所有配置中的全吞吐量,即每個周期一個輸出。
IP核圖示和端口描述
復數乘法器IP核如下圖所示:

| Name | I/O | Optional | Description |
|---|---|---|---|
| aclk | I | Yes | 上升沿時鐘。aclk 信號是可選的。當 FlowControl 為 NonBlocking 且 MinimumLatency = 0 時,它不存在。 |
| aclken | I | Yes | 高電平有效時鐘使能(可選) |
| aresetn | I | Yes | Active-Low 同步清零(可選,總是優先于 aclken)aresetn 應該被置位或取消置位不少于兩個 aclk 周期。 |
| s_axis_a_tvalid | I | No | 通道 A 的 TVALID。 |
| s_axis_a_tready | O | Yes | 通道 A 的TREADY。 |
| s_axis_a_tuser[A-1:0] | I | Yes | 通道 A 的 TUSER。寬度從 1 到 256 位可選。 |
| s_axis_a_tdata[B-1:0] | I | No | 通道 A 的 TDATA。 |
| s_axis_a_tlast | I | Yes | 通道 A 的 TLAST。 |
| s_axis_b_tvalid | I | No | 通道 B 的 TVALID。 |
| s_axis_b_tready | O | Yes | 通道 B 的 TREADY。 |
| s_axis_b_tuser[C-1:0] | I | Yes | 通道 B 的 TUSER。寬度從 1 到 256 位可選。 |
| s_axis_b_tdata[D-1:0] | I | No | 通道 B 的 TDATA。 |
| s_axis_b_tlast | I | Yes | 通道 B 的 TLAST。 |
| s_axis_ctrl_tvalid | I | Yes | 通道 CTRL 的 TVALID。 |
| s_axis_ctrl_tready | O | Yes | 通道 CTRL 的 TREADY。 |
| s_axis_ctrl_tuser[E-1:0] | I | Yes | 通道 CTRL 的 TUSER。寬度從 1 到 256 位可選。 |
| s_axis_ctrl_tdata[7:0] | I | Yes | 通道 CTRL 的 TDATA。 |
| s_axis_ctrl_tlast | I | Yes | 通道 CTRL 的 TLAST。 |
| m_axis_dout_tvalid | O | No | 通道 DOUT 的 TVALID。 |
| m_axis_dout_tready | I | Yes | 通道 DOUT 的 TREADY。 |
| m_axis_dout_tuser[G-1:0] | O | Yes | TUSER表示通道DOUT。Width是輸入通道上啟用的TUSER字段的總和。 |
| m_axis_dout_tdata[H-1:0] | O | No | 通道DOUT的TDATA。 |
| m_axis_dout_tlast | O | Yes | 通道DOUT的TLAST。 |
寬度常數A到H是任意變量,由GUI或配置參數決定。
硬件實現方式
Three Real Multiplier Solution
三實數乘法器的實現利用了DSP片中的預加器,節省了一般結構資源 。通常,三乘法器解決方案比四乘法器解決方案使用更多的片資源(LUT/觸發器),并且具有更低的最大可實現時鐘頻率 。
Four Real Multiplier Solution
四實數乘法器方案最大限度地利用了DSP片資源,并且比三實數乘法器方案具有更高的時鐘頻率性能,在許多情況下達到了FPGA的最大時鐘頻率。
它仍然會消耗用于流水操作平衡的切片資源,但該切片成本始終低于等效三實數乘法器解決方案所需的成本。
Dedicated Primitive Solution
具有專用的DSPCPLX原語設備,能夠使用兩個DSP片的等效物執行完全的復數乘法。與3倍增或4倍增解決方案相比,此解決方案使用的資源更少,延遲更低。無需特殊選擇 ;當配置允許時,系統會自動使用此解決方案。
您可以設置特定的延遲值:將延遲配置設置為手動,然后相應地設置最小延遲值。這允許您針對某些情況指定調整,因為您可能需要比自動延遲分配提供的延遲值更高的延遲值:
LUT-based Solution
核心提供了僅使用LUT構建復數乘法器的選項。雖然此選項使用了大量的片,實現了較低的最大時鐘頻率,并比DSP片實現使用了更多的功率 ,但它可能適用于DSP片供應有限或使用較低時鐘速率的應用。當選擇LUT實現時,僅使用三實乘法器配置。
舍入原則
在DSP系統中,尤其是當系統包含反饋時,通過乘法器的字長增長應該通過量化結果來抵消。量化或字長減少會導致錯誤,引入量化噪聲,并可能引入偏差。為了獲得最佳結果,最好選擇一種引入零平均噪聲并最小化噪聲方差的量化方法。
理想的圓化器不會對信號流引入直流偏置。如果使用靜態規則四舍五入0.5,則產生的量化總是引入偏差。為避免偏差,舍入必須隨機化。因此,核心增加一個舍入常數,并應以?概率額外增加1,從而抖動精確舍入閾值。下表列出了廣泛用作控制信號的典型圓形進位源。
| 0.5 Rounding Rule | Round Carry Source |
|---|---|
| Round towards 0 | -MSB(P) |
| Round towards +/- infinity | MSB(P) |
| Round towards nearest even | LSB(P) |
當過程中涉及多個級聯DSP Slices時,四舍五入的結果并不簡單,在實際的乘法和加法發生之前,無法從操作數預測輸出符號(MSBo),并且會導致額外的延遲或在DSP片之外實現的資源。因此,一個外部信號應該被用來反饋到進位輸入通過ROUND_CY引腳 (s_axis_ctrl_tdata的位0)。
一個很好的源可以是一個時鐘分頻觸發器,或任何50%占空比的隨機信號,它與結果的小數部分不相關。對于可預測的行為(如位真建模),ROUND_CY信號可能需要連接到 在您的設計中CLK獨立源,例如一個復雜乘法器輸入的LSB。
盡管如此,即使使用靜態規則(例如ROUND_CY=0),與使用截斷相比,偏移和量化誤差也會減少。在許多情況下,對于DSP切片實現,舍入常數的添加是“自由”的,因為可以使用C端口和進位輸入。在沒有DSP片的設備中,增加舍入通常需要額外的基于片的加法器和額外的延遲周期。
協議描述
該內核遵循AXI4流規范。
AXI4-Stream注意事項
轉換為AXI4流接口,使得接口協議更加標準并增強了IP的互操作性。除aclk、ACLKEN和ARESETn等常規控制信號外,復乘法器的所有輸入和輸出均通過AXI4流通道傳輸。通道由tvalid和tdata always以及幾個可選端口和字段組成。在除法器中,支持的可選端口為tready、tlast和tuser。tvalid和tready一起執行握手以傳輸消息,其中有效負載為tdata、tuser和tlast。在復數乘法器中,支持的可選端口為tready、tlast和tuser。tvalid和tready一起執行握手以傳輸消息,其中有效負載為tdata、tuser和tlast。復數乘法器對tdata中包含的操作數進行操作,并在輸出通道的tdata中輸出結果。復數乘法器本身不使用tuser和tlast,但提供了以與tdata延遲傳輸的功能。
這種將tlast和tuser從輸入傳遞到輸出的功能旨在簡化系統中復數乘法器的使用。例如,復數乘法器可用作混頻器或對流式分組數據進行操作的相移。在此示例中,可以將核心配置為通過打包數據通道的tlast,從而減小工作量。
基本握手協議
下圖顯示了AXI4流通道中的數據傳輸。
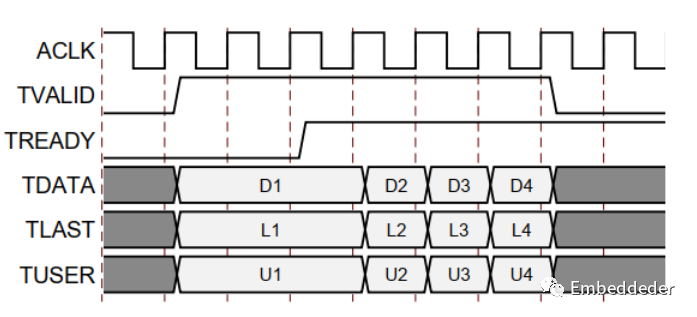
tvalid 由通道的源(主)端驅動,而tready 由接收器(從)驅動。tvalid 表示有效載荷字段(tdata、tuser 和 tlast)中的值有效。tready 表示從機已準備好接收數據。當循環中 tvalid 和treaty 都為TRUE 時,就會發生傳輸。master 和 slave 分別為下一次傳輸適當地設置了 tvalid 和tready。
非阻塞模式
非阻塞意味著如果在另一個輸入通道上接收到數據,則一個輸入通道上缺少數據不會阻止操作的執行。并非總是需要 AXI4-Stream 的完整流量控制。使用 FlowControl 參數或 GUI 字段選擇阻塞或非阻塞行為。 復乘法器支持 NonBlocking 模式,其中 AXI4-Stream 通道沒有 TREADY,即它們不支持背壓。Blocking 或 NonBlocking 的選擇適用于整個IP,而不是單獨的每個通道。通道仍然具有非可選的 tvalid 信號,這類似于采用 AXI4-Stream 之前許多內核上的新數據 (ND) 信號。由于沒有阻止數據流的功能,內部實現大大簡化,因此這種模式需要的資源更少。對于希望從 AXI 之前的版本遷移到此版本且更改最少的用戶,建議使用此模式。
當所有當前輸入通道都接收到一個有效的 tvalid時,并且輸出 tvalid(適當地被內核的延遲)被斷言,從而輸出計算的結果。操作發生在每個啟用的時鐘周期,并且無論 tvalid是狀態,數據都顯示在輸出通道有效載荷字段中。這是為了允許從 v3.1 的最小遷移。下圖顯示了延遲為一個周期的情況下的 NonBlocking 行為。
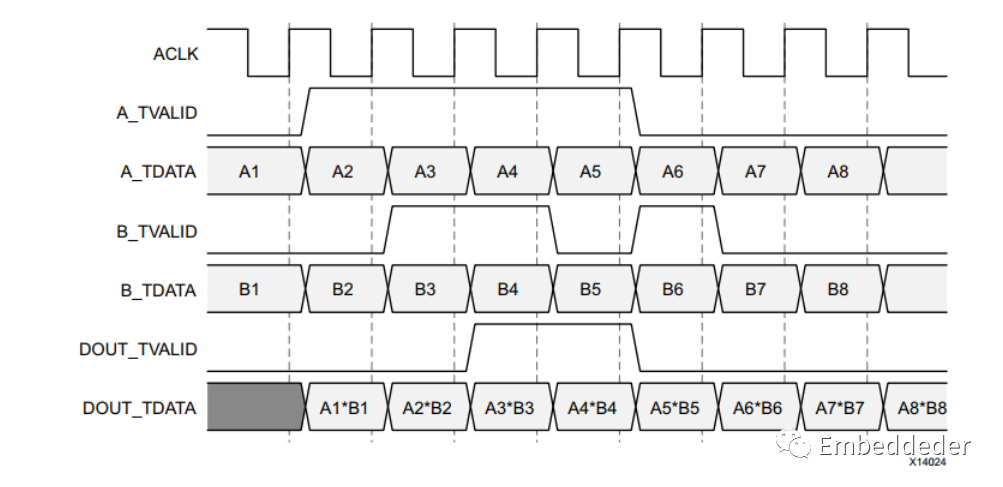
阻塞模式
術語“阻塞”意味著每個通道都在緩沖數據以供使用。AXI4-Stream 的完整流控制有助于系統設計,因為數據流是自我調節的。使用 FlowControl 參數選擇阻塞或非阻塞行為。背壓(tready)的存在可以防止數據丟失,因此只有在下游數據路徑準備好處理數據時才會傳播數據。
復數乘法器有兩個或三個輸入通道和一個輸出通道。當所有輸入通道都有可用的有效數據時,會發生一個操作,并且輸出結果可用。如果由于tready為低而阻止輸出卸載數據,則數據會累積在堆芯內部的輸出緩沖區中。當輸出緩沖區幾乎滿時,內核停止進一步的操作。這可以防止輸入緩沖區卸載新操作的數據,以便在輸入新數據時填充輸入緩沖區。當輸入緩沖區填滿時,其各自的tready將被置為無效,以防止進一步輸入。
這三個輸入綁定在一起,每個輸入都必須在進行運算操作之前接收經過有效的數據。因此,有一個額外的阻塞機制,其中至少一個輸入通道不接收有效數據,而其他通道接收有效數據。在這種情況下,有效數據存儲在通道的輸入緩沖區中。在該情況下的幾個周期后,接收數據的通道的緩沖區將填滿,該通道的TREADY將被取消斷言,直到饑餓通道接收到一些數據。
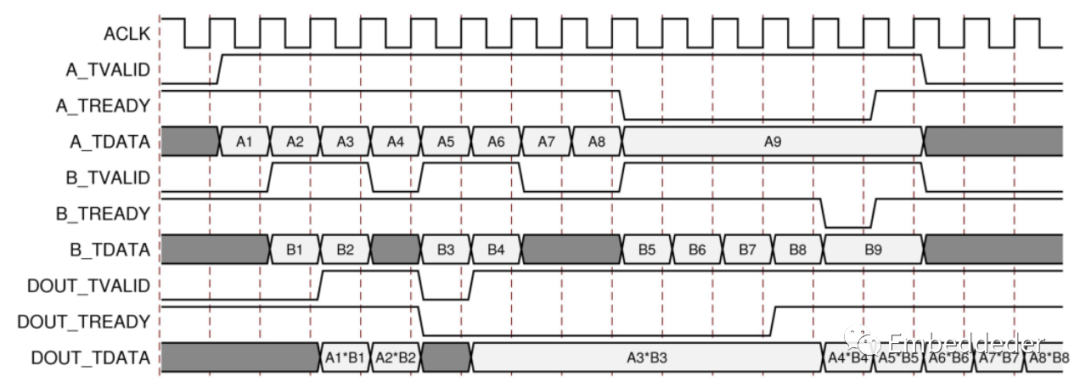
上圖顯示了阻塞行為和背壓。通道 A 上的第一個數據與通道 B 上的第一個數據配對,第二個與第二個數據配對,依此類推。這演示了阻塞概念。該圖進一步顯示了數據輸出如何不僅因延遲而延遲,而且還因握手信號 DOUT_TREADY 而延遲。這是背壓輸出上的持續背壓以及輸入上的數據可用性最終導致核心緩沖區飽和,從而導致核心通過取消置位輸入通道TREADY 信號來表示它無法再接受進一步的輸入。
這個例子中的最小延遲是兩個周期,但在Blocking 操作中的延遲并不是一個有用的概念。每個通道都充當一個隊列,確保每個通道上的第一個、第二個、第三個數據樣本與每個操作的其他通道上的相應樣本配對。
TDATA包
AXI4-Stream 接口中的遵循特定的命名法。通常情況下,與應用相關的信息(在本例中為復數乘法)在TDATA字段中攜帶。
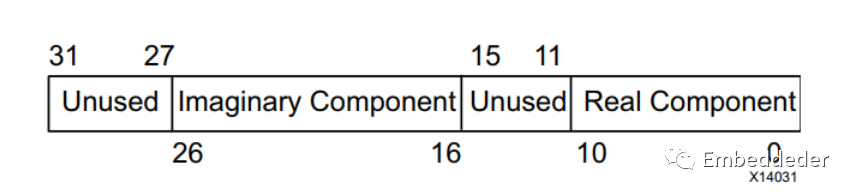
在IP核中,復數操作數分量(實操作數分量和虛操作數分量)都通過通道TDATA端口傳入或傳出IP,其中實操作數分量位于最低有效位置。為了簡化與面向字節的協議的互操作性,如果需要時,首先擴展TDATA中可獨立使用的每個子字段,以適合8位的倍數的位字段。例如,如果將復數乘法器配置為具有11位的操作數寬度。A的每個實部和虛部都是11位寬。實分量將占用位10到0。位15到11將被忽略。位26到16將保持虛部,位31到27同樣將被忽略。對于輸出DOUT通道,結果字段符號擴展到字節邊界。按字節方向添加的位被內核忽略,不會導致額外的資源使用。
A、B和DOUT通道的TDATA結構
輸入端口A、B和輸出端口D在其TDATA字段中攜帶復雜數據。對于每一個,實際組件占用最低有效位。虛部占據一個位域,該位域從實部上方的下一個字節邊界開始。
CTRL通道的TDATA結構
CTRL通道僅在選擇舍入時存在,且僅用于傳遞舍入位。此位占用此通道TDATA的位0。但是,由于TDATA面向字節的特性,這意味著TDATA的寬度為8位。將舍入系數添加到舍入常數0.01111…,使舍入常數為0.01111..或0.100...因此,將該位設置為0會導致舍入為負無窮大;將其設置為1將使其四舍五入為正無窮大,并為每個樣本設置一個新的隨機值,從而實現無偏隨機四舍五入。
TLAST and TUSER握手
AXI4-Stream 中的 tlast 用于表示數據塊的最后一次傳輸。tuser 用于限定或擴充 tdata 中的主要數據的輔助信息。復數乘法器基于每個采樣進行操作,其中每個操作獨立于任何之前或之后的操作。因此,在復數乘法器上不需要tlast,也不需要tlast。
在每個信道上支持tlast和tlast信號,通過復數乘法器的數據流確實具有一些分組化或輔助字段,但不是與復數乘法器相關。傳遞 tlast 或 tuser 的功能消除了通過復數乘法器將延遲匹配到 tdata 路徑的負擔,該路徑可以是可變的。
TLAST Options
每個輸入通道的 tlast 是可選的。每個存在時,都可以通過復數乘法器,或者,當多個通道啟用了 tlast 時,可以通過 tlast 輸入的邏輯 AND 或邏輯 OR。當任何輸入通道上不存在 tlasts時,輸出通道也沒有 tlast。
TUSER Options
t每個輸入通道的接收器是可選的。每個都有用戶可選擇的寬度。這些字段連接在一起,沒有任何字節方向或填充,以形成輸出通道TUSER字段。通道A中的TUSER字段形成連接的最低有效部分,然后是通道B中的TUSER,然后是通道CTRL中的TUSER。
如果通道 A 和 CTRL 都有寬度分別為 5 位和 8 位的 TUSER,則輸出 TUSER 是 A 和 CTRL TUSER 字段的適當延遲串聯,13 位寬,帶有 A 在最低有效的 5 位位置(4 到 0)。
如果 B 和 CTRL 的 TUSER 寬度分別為 4 和 10,但 A 沒有 TUSER,則 DOUT TUSER (m_axis_dout_tuser) 將適當延遲位置 3 到 0 與 CTRL_TUSER (s_axis_ctrl_tuser) 位將適當延遲位置13 下到4。
復數乘法器IP配置
復數乘法器IP配置界面如下:
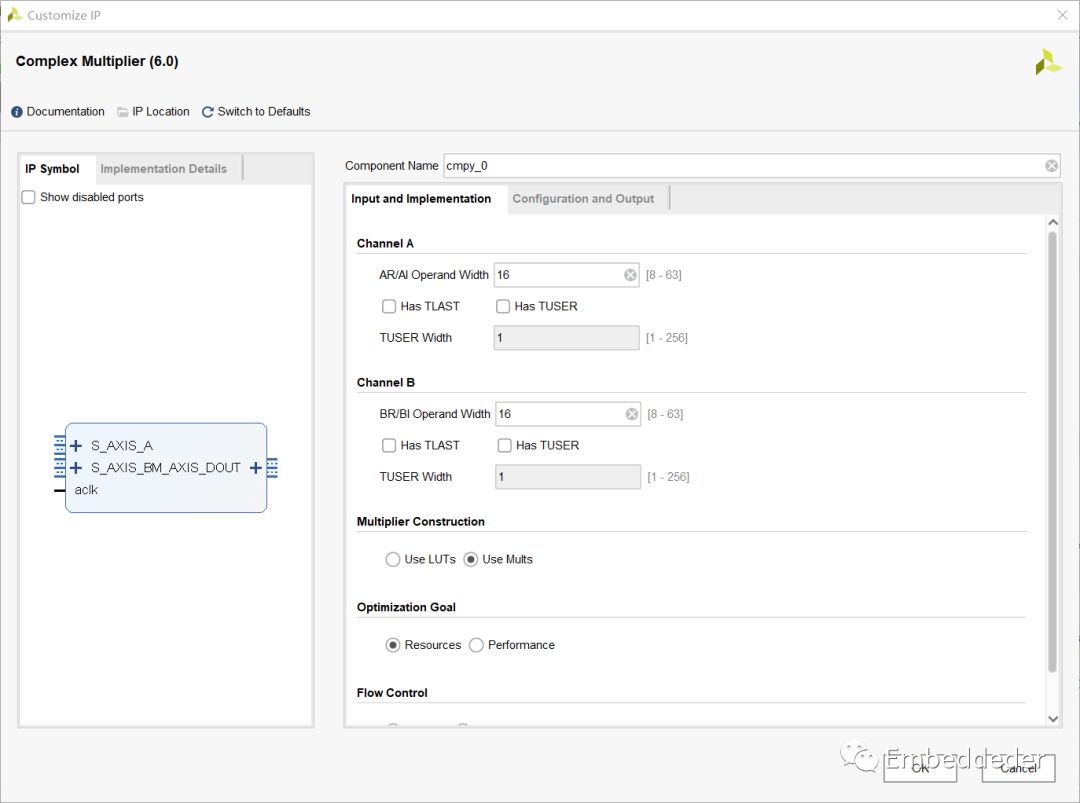
輸入和實現選項卡
Channel A Options:
AR/AI Operand Width: AR/AI操作數寬度。選擇第一個操作數寬度。寬度應用于復數操作數的實部和虛部。
Has TLAST: Has TLAST:選擇通道是否具有TLAST。為了簡化系統設計,內核將任何TLAST和TUSER傳遞到輸出,延遲等于TDATA字段。
Has TUSER: 選擇通道是否有TUSER。為了簡化系統設計,內核將任何TLAST和TUSER傳遞到輸出,延遲等于TDATA字段。
TUSER Width: 選擇此通道的TUSER字段的寬度(以位為單位)。
Channel B Options:
BR/BI Operand Width: BR/BI操作數寬度。選擇第一個操作數寬度。寬度應用于復數操作數的實部和虛部。
Has TLAST: Has TLAST:選擇通道是否具有TLAST。為了簡化系統設計,內核將任何TLAST和TUSER傳遞到輸出,延遲等于TDATA字段。
Has TUSER: 選擇通道是否有TUSER。為了簡化系統設計,內核將任何TLAST和TUSER傳遞到輸出,延遲等于TDATA字段。
TUSER Width: 選擇此通道的TUSER字段的寬度(以位為單位)。
Multiplier Construction Options: 乘法器構造選項。允許選擇使用LUT(切片邏輯)構造復數乘法器,或使用DSP切片。
Optimization Goal: 優化目標。在資源優化和性能優化之間進行選擇。
此選擇會影響AXI4流接口中的內部體系結構決策和性能/資源權衡。
對于基于乘法器的實現,資源優化通常使用三個實數乘法器結構。當三實數乘法器結構使用更多的乘法器資源時,核心使用四實數乘法器結構。性能優化始終使用四實乘法器結構,以實現最佳時鐘頻率性能。
Flow Control Options: 流量控制選項。選擇AXI4流接口的阻塞和非阻塞行為。
配置和輸出選項卡
Output Product Range: 輸出寬度。選擇輸出運算結果的實部和虛部的寬度。設置A和B操作數寬度時,會自動初始化這些值以提供全精度乘積。復數乘法的自然寬度是輸入寬度加上一的總和。如果輸出寬度設置為小于此自然寬度,則根據下一個GUI字段的選擇,將截斷或舍入最低有效位。
Output Rounding: 如果選擇了全精度運算結果(輸出寬度等于自然寬度),則沒有舍入選項可用。否則,可以選擇截斷或隨機舍入。選擇“隨機舍入”后,將啟用CTRL通道。此通道的TDATA字段的第0位決定了相關操作的特定舍入類型。
Channel CTRL Options:
控制通道用于提供決定舍入類型的位。
Output TLAST Behavior: TLAST行為。確定哪個輸入通道的TLAST或哪個輸入通道TLAST組合被傳送到輸出通道TLAST。可用選項包括傳遞任何一個輸入通道的TLAST或傳遞所有可用輸入TLAST的邏輯or或傳遞所有可用輸入TLAST的邏輯AND。
Core Latency: Core Latency為Core選擇所需的延遲。
Latency Configuration: 延遲配置。在自動和手動之間進行選擇。自動時,延遲設置為使核心完全流水線化以獲得最大性能。手動允許用戶選擇最小延遲。當值集小于完全流水線延遲時,性能會下降。當值集大于完全流水線時,內核使用SRL延遲輸出。選擇阻塞流控制后,核心延遲不是固定的,因此只能指定最小延遲。
Minimum Latency: 最小延遲。手動延遲配置的值。
Control Signals
控制信號。當內核的最小延遲為零時,這些選項將被禁用。
ACLKEN: 啟用內核上的時鐘啟用(ACLKEN)引腳。核心中的所有寄存器都由該信號啟用。
ARESETn: 啟用內核上的活動低同步清除(ARESETn)引腳。內核中的所有寄存器都通過該信號復位。這會增加資源使用并降低性能,因為可以使用的基于SRL的移位寄存器數量會減少。aresetn始終優先于aclken。
Implementation Details(實現詳細信息)選項卡
單擊Implementation Details(實現詳細信息)選項卡,查看用于特定復雜乘法器配置的DSP片資源的估計值。該值隨GUI中的更改而即時更新,從而允許立即評估實現中的權衡。
reference
TUSER Width: 選擇此通道的TUSER字段的寬度(以位為單位)。
Has TUSER: 選擇通道是否有TUSER。為了簡化系統設計,內核將任何TLAST和TUSER傳遞到輸出,延遲等于TDATA字段。
Has TLAST: Has TLAST:選擇通道是否具有TLAST。為了簡化系統設計,內核將任何TLAST和TUSER傳遞到輸出,延遲等于TDATA字段。
非常高的性能(使用更高的延遲值可在輸入級之前和輸出級之后添加更快的可編程邏輯寄存器。)
-
dsp
+關注
關注
553文章
7998瀏覽量
348944 -
FPGA
+關注
關注
1629文章
21736瀏覽量
603425 -
寄存器
+關注
關注
31文章
5343瀏覽量
120377 -
Xilinx
+關注
關注
71文章
2167瀏覽量
121430 -
乘法器
+關注
關注
8文章
205瀏覽量
37061
發布評論請先 登錄
相關推薦
應用于CNN中卷積運算的LUT乘法器設計

求fpga乘法器,要求快的
怎么設計基于FPGA的WALLACETREE乘法器?
硬件乘法器的相關資料分享
乘法器對數運算電路應用


基于IP核的乘法器設計
基于FPGA的WALLACE TREE乘法器設計
進位保留Barrett模乘法器設計

使用verilogHDL實現乘法器
乘法器原理_乘法器的作用






 工商網監
工商網監
評論