

- 數據湖漫游指南
- 文件大小和文件數
- 文件格式
- 分區方案
- 使用查詢加速
- 我如何管理對我的數據的訪問?
- 我選擇什么數據格式?
- 如何管理我的數據湖成本?
- 如何監控我的數據湖?
- ADLS Gen2 何時是您數據湖的正確選擇?
- 設計數據湖的關鍵考慮因素
- 術語
- 組織和管理數據湖中的數據
- 我想要集中式還是聯合式數據湖實施?
- 如何組織我的數據?
- 優化數據湖以獲得更好的規模和性能
- 推薦閱讀
- 問題、意見或反饋?
Azure Data Lake Storage Gen2 (ADLS Gen2) 是用于大數據分析的高度可擴展且經濟高效的數據湖解決方案。隨著我們繼續與客戶合作,利用 ADLS Gen2 從他們的數據中發掘關鍵洞察,我們已經確定了一些關鍵模式和注意事項,可幫助他們在大規模大數據平臺架構中有效利用 ADLS Gen2。
本文檔記錄了我們在與客戶合作的基礎上學到的這些注意事項和最佳實踐。就本文檔而言,我們將重點介紹我們的大型企業客戶在 Azure 上大量使用的現代數據倉庫模式,包括我們的解決方案,例如 Azure Synapse Analytics。
我們將改進此文檔以在未來的迭代中包含更多分析模式。
重要提示:請將此文檔的內容視為指導和最佳實踐,以幫助您做出架構和實施決策。這不是官方的 HOW-TO 文檔。
ADLS Gen2 何時是您數據湖的正確選擇?#
企業數據湖旨在成為大數據平臺中使用的非結構化、半結構化和結構化數據的中央存儲庫。企業數據湖的目標是消除數據孤島(數據只能由組織的一部分訪問)并促進單一存儲層,以適應組織的各種數據需求有關選擇正確的更多信息存儲解決方案,請訪問在 Azure 中選擇大數據存儲技術一文。
出現的一個常見問題是何時使用數據倉庫與數據湖。我們敦促您將數據湖和數據倉庫視為互補的解決方案,它們可以協同工作,幫助您從數據中獲得關鍵見解。數據湖是存儲來自各種來源的所有類型數據的存儲庫。自然形式的數據存儲為原始數據,并在此原始數據上應用模式和轉換,以根據業務試圖回答的關鍵問題獲得有價值的業務洞察力。數據倉庫是高度結構化的模式化數據的存儲,這些數據通常被組織和處理以獲得非常具體的見解。例如。零售客戶可以將過去 5 年的銷售數據存儲在數據湖中,此外,他們可以處理來自社交媒體的數據,從零售分析解決方案中提取消費和情報的新趨勢,并利用所有這些作為輸入一起生成一個數據集,可用于預測明年的銷售目標。然后,他們可以將高度結構化的數據存儲在數據倉庫中,BI 分析師可以在其中構建目標銷售預測。此外,他們可以使用數據湖中相同的銷售數據和社交媒體趨勢來構建智能機器學習模型,以在其網站上進行個性化推薦。
ADLS Gen2 是適用于大數據分析工作負載的企業級超大規模數據存儲庫。ADLS Gen2 通過分層命名空間提供更快的性能和 Hadoop 兼容訪問,通過細粒度訪問控制和本機 AAD 集成降低成本和安全性。這適合作為專注于大數據分析場景的企業數據湖的選擇——使用轉換從非結構化數據中提取高價值的結構化數據、使用機器學習的高級分析或實時數據攝取和分析以獲得快速洞察力。值得注意的是,我們已經看到客戶對超大規模的定義有不同的定義——這取決于存儲的數據、交易數量和交易吞吐量。當我們說超大規模時,我們通常指的是數 PB 的數據和數百 Gbps 的吞吐量——這種分析所涉及的挑戰與吞吐量中的數百 GB 數據和幾 Gbps 的事務非常不同。
設計數據湖的關鍵考慮因素#
當您在 ADLS Gen2 上構建企業數據湖時,了解您對關鍵用例的需求很重要,包括
- 我在數據湖中存儲了什么?
- 我在數據湖中存儲了多少數據?
- 您在數據的哪一部分上運行分析工作負載?
- 誰需要訪問我的數據湖的哪些部分?
- 我將在我的數據湖上運行哪些各種分析工作負載?
- 分析工作負載有哪些不同的事務模式?
- 我的工作預算是多少?
對于我們一直從客戶那里聽到的一些關鍵設計/架構問題,我們希望將本文檔的其余部分固定在以下結構中。
- 有優缺點的可用選項
- 選擇適合您的選項時要考慮的因素
- 適用時推薦的模式
- 您想要避免的反模式
為了最好地利用本文檔,請確定您的關鍵場景和要求,并根據您的要求權衡我們的選項以決定您的方法。如果您無法選擇完全適合您的場景的選項,我們建議您使用一些選項進行概念驗證 (PoC),讓數據指導您的決策。
術語#
在我們討論構建數據湖的最佳實踐之前,熟悉我們將在使用 ADLS Gen2 構建數據湖的上下文中使用的各種術語非常重要。本文檔假設您在 Azure 中有一個帳戶。
- 資源:可通過 Azure 獲得的可管理項目。虛擬機、存儲帳戶、VNET 是資源的示例。
- 訂閱:Azure 訂閱是一個邏輯實體,用于分離 Azure 資源的管理和財務(計費)邏輯。訂閱與 Azure 資源的限制和配額相關聯,您可以在此處閱讀有關它們的信息。
- 資源組:用于容納 Azure 解決方案所需資源的邏輯容器可以作為一個組一起管理。您可以在此處閱讀有關資源組的更多信息。
- 存儲帳戶:包含所有 Azure 存儲數據對象的 Azure 資源:blob、文件、隊列、表和磁盤。您可以在此處閱讀有關存儲帳戶的更多信息。就本文檔而言,我們將重點介紹 ADLS Gen2 存儲帳戶——它本質上是一個啟用了分層命名空間的 Azure Blob 存儲帳戶,您可以在此處閱讀更多相關信息。
- 容器(也稱為非 HNS 啟用帳戶的容器):一個容器組織一組對象(或文件)。一個存儲帳戶對容器的數量沒有限制,容器可以存儲無限數量的文件夾和文件。有些屬性可以應用于容器級別,例如 RBAC 和 SAS 鍵。
- 文件夾/目錄:文件夾(也稱為目錄)組織一組對象(其他文件夾或文件)。一個文件夾下可以創建多少個文件夾或文件沒有限制。文件夾還具有與之關聯的訪問控制列表 (ACL),有兩種類型的 ACL 與文件夾關聯——訪問 ACL 和默認 ACL,您可以在此處閱讀有關它們的更多信息。
- 對象/文件:文件是保存可以讀/寫的數據的實體。一個文件有一個與之關聯的訪問控制列表。文件只有訪問 ACL,沒有默認 ACL。
組織和管理數據湖中的數據#
隨著我們的企業客戶制定他們的數據湖戰略,ADLS Gen2 的關鍵價值主張之一是作為其所有分析場景的單一數據存儲。請記住,這個單一數據存儲是一個邏輯實體,根據設計考慮,它可以表現為單個 ADLS Gen2 帳戶或多個帳戶。一些客戶擁有分析管道組件的端到端所有權,而其他客戶則擁有一個中央團隊/組織來管理數據湖的基礎架構、運營和治理,同時為多個客戶提供服務——無論是他們企業中的其他組織還是外部的其他客戶到他們的企業。
在本節中,我們針對客戶在設計企業數據湖時聽到的一系列常見問題提出了我們的想法和建議。作為說明,我們將以大型零售客戶 Contoso.com 為例,構建他們的數據湖策略以幫助處理各種預測分析場景。
我想要集中式還是聯合式數據湖實施?#
作為企業數據湖,您有兩種可用的選擇——要么將所有數據管理集中在一個組織內以滿足您的分析需求,要么擁有一個聯合模型,您的客戶管理他們自己的數據湖,而集中式數據團隊提供指導并管理數據湖的幾個關鍵方面,例如安全性和數據治理。重要的是要記住,集中式和聯合數據湖策略都可以使用一個存儲帳戶或多個存儲帳戶來實施。
客戶問我們的一個常見問題是,他們是否可以在單個存儲帳戶中構建數據湖,或者他們是否需要多個存儲帳戶。雖然從技術上講,單個 ADLS Gen2 可以解決您的業務需求,但客戶選擇多個存儲帳戶的原因有多種,包括但不限于本節其余部分中的以下場景。
關鍵考慮#
在決定要創建的存儲帳戶數時,以下注意事項有助于決定要預配的存儲帳戶數。
- 單個存儲帳戶使您能夠管理一組控制平面管理操作,例如存儲帳戶中所有數據的 RBAC、防火墻設置、數據生命周期管理策略,同時允許您使用容器、文件和存儲帳戶上的文件夾。如果您想優化以簡化管理,特別是如果您采用集中式數據湖策略,這將是一個值得考慮的好模型。
- 多個存儲帳戶使您能夠在不同帳戶之間隔離數據,以便可以對它們應用不同的管理策略或單獨管理它們的計費/成本邏輯。如果您正在考慮采用聯合數據湖策略,每個組織或業務部門都有自己的一組可管理性要求,那么此模型可能最適合您。
讓我們將這些方面放在一些場景的上下文中。
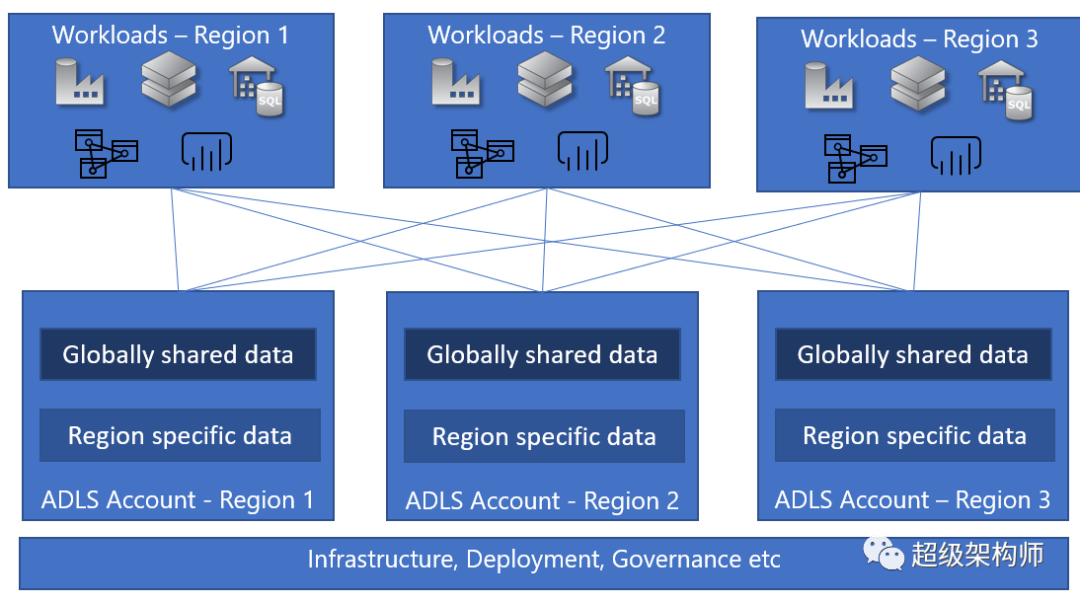
覆蓋全球的企業數據湖#
在全球市場和/或地理分布的組織的推動下,有些情況下,企業的分析場景將多個地理區域考慮在內。數據本身可以分為兩大類。
- 可以在所有地區全球共享的數據——例如Contoso 正在嘗試規劃下一個財政年度的銷售目標,并希望從各個地區獲取銷售數據。
- 需要隔離到一個區域的數據——例如Contoso 希望根據買家的個人資料和購買模式提供個性化的買家體驗。鑒于這是客戶數據,需要滿足主權要求,因此數據不能離開該區域。
在這種情況下,客戶將提供特定于區域的存儲帳戶來存儲特定區域的數據并允許與其他區域共享特定數據。這里仍然有一個集中的邏輯數據湖,其中包含一組由多個存儲帳戶組成的中央基礎設施管理、數據治理和其他操作。
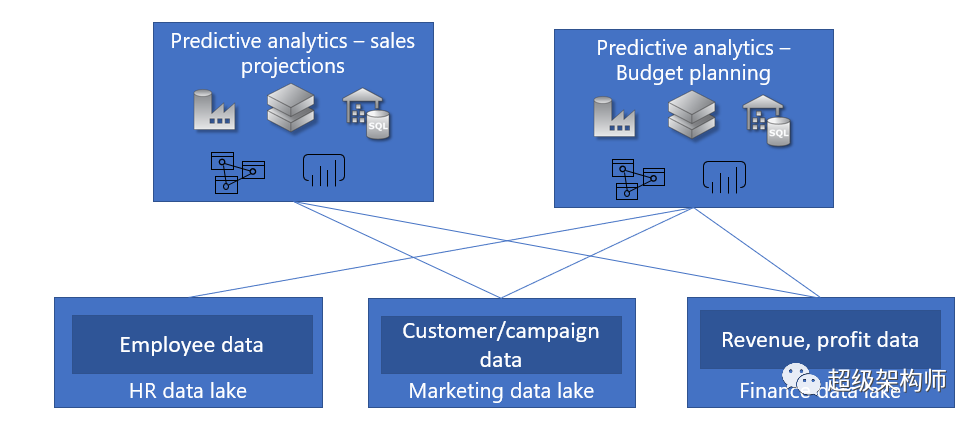
客戶或數據特定隔離#
存在企業數據湖服務于多個客戶(內部/外部)場景的場景,這些場景可能會受到不同的要求——不同的查詢模式和不同的訪問要求。讓我們以我們的 Contoso.com 為例,他們有分析方案來管理公司運營。在這種情況下,他們擁有各種數據源——員工數據、客戶/活動數據和財務數據,這些數據受不同治理和訪問規則的約束,也可能由公司內的不同組織管理。在這種情況下,他們可以選擇為各種數據源創建不同的數據湖。
在另一種情況下,作為為多個客戶提供服務的多租戶分析平臺的企業最終可能會為不同訂閱中的客戶提供單獨的數據湖,以幫助確保客戶數據及其相關的分析工作負載與其他客戶隔離,以幫助管理他們的成本和計費模式。
建議#
- 為您的開發和生產環境創建不同的存儲帳戶(最好在不同的訂閱中)。除了確保需要不同 SLA 的開發和生產環境之間有足夠的隔離之外,這還有助于您有效地跟蹤和優化管理和計費策略。
- 確定數據的不同邏輯集,并考慮以統一或隔離的方式管理它們的需求——這將有助于確定您的帳戶邊界。
- 從一個存儲帳戶開始您的設計方法,并考慮為什么需要多個存儲帳戶(隔離、基于區域的要求等)而不是相反的原因。
- 其他資源(例如 VM 核心、ADF 實例)也有訂閱限制和配額——在設計數據湖時要考慮這些因素。
反模式#
謹防多重數據湖管理#
當您決定 ADLS Gen2 存儲帳戶的數量時,請確保針對您的消費模式進行優化。如果您不需要隔離并且您沒有充分利用您的存儲帳戶的功能,您將承擔管理多個帳戶的開銷,而沒有有意義的投資回報。
來回復制數據#
當您擁有多個數據湖時,您需要謹慎對待的一件事是您是否以及如何跨多個帳戶復制數據。這會產生一個管理問題,即真相的來源是什么以及它需要有多新鮮,并且還會消耗涉及來回復制數據的事務。如果您有一個合法的方案來復制您的數據,我們的路線圖中有一些功能可以使此工作流程更容易。
可擴展性注釋#
我們的客戶問的一個常見問題是,單個存儲帳戶是否可以無限地繼續擴展以滿足他們的數據、事務和吞吐量需求。我們在 ADLS Gen2 中的目標是滿足客戶所需的極限。當您遇到需要真正存儲大量數據(數 PB)并需要帳戶支持真正大的事務和吞吐量模式(數萬 TPS 和數百 Gbps 吞吐量)的場景時,我們確實要求),通常通過 Databricks 或 HDInsight 進行分析處理需要 1000 個計算能力核心,請聯系我們的產品組,以便我們可以計劃適當地支持您的要求。
如何組織我的數據?#
ADLS Gen2 帳戶中的數據組織可以在容器、文件夾和文件的層次結構中按順序完成,如我們上面所見。當我們與客戶合作制定他們的數據湖策略時,一個非常常見的討論點是他們如何最好地組織他們的數據。有多種方法可以在數據湖中組織數據,本節記錄了許多構建數據平臺的客戶采用的通用方法。
該組織跟蹤數據的生命周期,因為它通過源系統一直流向最終消費者——BI 分析師或數據科學家。例如,讓我們跟隨銷售數據通過 Contoso.com 的數據分析平臺的旅程。

例如,將原始數據視為自然狀態下有水的湖泊/池塘,數據按原樣攝取和存儲,未經轉換,豐富的數據是水庫中的水,經過清洗并以可預測的狀態存儲(以我們的數據為例),策劃的數據就像準備消費的瓶裝水。工作區數據就像一個實驗室,科學家可以在其中攜帶自己的數據進行測試。值得注意的是,雖然所有這些數據層都存在于單個邏輯數據湖中,但它們可能分布在不同的物理存儲帳戶中。在這些情況下,擁有 Metastore 有助于發現。
- 原始數據:這是來自源系統的數據。此數據按原樣存儲在數據湖中,并由分析引擎(例如 Spark)使用以執行清理和充實操作以生成精選數據。原始區域中的數據有時也存儲為聚合數據集,例如在流場景的情況下,數據通過消息總線(如事件中心)攝取,然后通過實時處理引擎(如 Azure Stream 分析或 Spark Streaming)聚合,然后存儲在數據湖中。根據您的業務需求,您可以選擇保持數據原樣(例如來自服務器的日志消息)或聚合它(例如實時流數據)。這一層數據由中央數據工程團隊高度控制,很少被其他消費者訪問。根據您企業的保留策略,此數據要么在保留策略要求的期限內按原樣存儲,要么在您認為數據不再使用時將其刪除。例如。這將是從在其本地系統中運行的 Contoso 的銷售管理工具中提取的原始銷售數據。
- 豐富的數據:這一層數據是原始數據(按原樣或聚合)具有定義模式的版本,并且數據經過清理、豐富(與其他來源),可供分析引擎使用以提取高價值數據。數據工程師生成這些數據集,并繼續從這些數據集中提取高價值/精選數據。例如。這將是豐富的銷售數據 - 確保銷售數據被模式化,豐富了其他產品或庫存信息,并為 Contoso 內部的不同業務部門分成多個數據集。
- 精選數據:這一層數據包含提供給數據消費者(BI 分析師和數據科學家)的高價值信息。該數據具有結構,可以按原樣(例如數據科學筆記本)或通過數據倉庫提供給消費者。該層中的數據資產通常受到高度管理和良好記錄。例如。業務部門的高質量銷售數據(即與其他需求預測信號(如社交媒體趨勢模式)相關的豐富數據區域中的數據),用于預測分析以確定下一財政年度的銷售預測。
- 工作區數據:除了數據工程團隊從源頭攝取的數據之外,數據的消費者還可以選擇帶來其他可能有價值的數據集。在這種情況下,數據平臺可以為這些消費者分配工作空間,以便他們可以使用精選數據以及他們帶來的其他數據集來生成有價值的見解。例如。數據科學團隊正在嘗試確定新地區的產品放置策略,他們可以帶來其他數據集,例如客戶人口統計數據和該地區其他類似產品的使用數據,并使用高價值的銷售洞察數據來分析產品市場契合度和發行策略。
- 存檔數據:這是您組織的數據“保險庫” - 存儲的數據主要符合保留策略,并且具有非常嚴格的用途,例如支持審計。您可以使用 ADLS Gen2 中的 Cool 和 Archive 層來存儲此數據。您可以閱讀有關我們的數據生命周期管理政策的更多信息,以確定適合您的計劃。
關鍵考慮#
在決定數據結構時,請考慮數據本身的語義以及訪問數據的消費者,以確定適合您的數據組織策略。
建議#
- 為不同的數據區域創建不同的文件夾或容器(更多關于文件夾與容器之間的注意事項) - 原始數據集、豐富數據集、策劃數據集和工作區數據集。
- 在一個區域內,選擇根據邏輯分隔在文件夾中組織數據,例如日期時間或業務單位或兩者兼而有之。您可以在我們的最佳實踐文檔中找到有關目錄布局的更多示例和場景。
- 在設計文件夾結構時考慮分析使用模式。例如。如果您有一個 Spark 作業讀取過去 3 個月內來自特定地區的產品的所有銷售數據,那么理想的文件夾結構是 /enriched/product/region/timestamp。
- 在決定文件夾結構時,請考慮您希望遵循的訪問控制模型。
- 下表提供了一個框架,供您考慮數據的不同區域以及具有常見模式的區域的相關管理。
| 考慮 | 原始數據 | 豐富的數據 | 策劃的數據 | 工作空間數據 |
|---|---|---|---|---|
| 消費者 | 數據工程團隊 | 數據工程團隊,由數據科學家/BI分析師提供臨時訪問模式 | 數據工程師、BI分析師、數據科學家 | 數據科學家/BI分析師 |
| 訪問控制 | 數據工程團隊已鎖定訪問權限 | 完全控制數據工程團隊,并對BI分析師/數據科學家具有讀取權限 | 完全控制數據工程團隊,對BI分析師/數據科學家具有讀寫權限 | 完全控制數據工程師、數據科學家/BI 分析師 |
| 數據生命周期管理 | 一旦生成了豐富的數據,就可以將其移動到較冷的存儲層以管理成本。 | 較舊的數據可以移動到較冷的層。 | 較舊的數據可以移動到較冷的層。 | 雖然最終消費者可以控制這個工作區,但要確保有清理不必要數據的流程和策略——例如,使用基于策略的 DLM,數據可以很容易地建立起來。 |
| 文件夾結構和層次結構 | 文件夾結構以反映攝入模式。 | 文件夾結構反映組織,例如業務部門。 | 文件夾結構反映組織,例如業務部門。 | 文件夾結構反映了工作區所使用的團隊。 |
| 實例 | /raw/sensordata /raw/lobappdata /raw/userclickdata | /enriched/sales /enriched/manufacturing | /curated/sales /curated/manufacturing | /workspace/salesBI /workspace/manufacturindatascience |
- 我們的客戶詢問何時使用容器以及何時使用文件夾來組織數據的另一個常見問題。雖然在更高級別,它們都用于數據的邏輯組織,但它們有一些關鍵區別。
| 考慮 | 容器 | 文件夾 |
|---|---|---|
| 等級 | 容器可以包含文件夾或文件。 | 文件夾可以包含其他文件夾或文件。 |
| 使用AAD的訪問控制 | 在容器級別,可以使用RBAC設置粗粒度的訪問控制。這些RBAC適用于容器內的所有數據。 | 在文件夾級別,可以使用ACL設置細粒度的訪問控制。ACL僅適用于該文件夾(除非使用默認ACL,在這種情況下,在該文件夾下創建新文件/文件夾時會對其進行快照)。 |
| 非AAD訪問控制 | 在容器級別,可以啟用匿名訪問(通過共享密鑰)或設置特定于容器的SAS密鑰。 | 文件夾不支持非AAD訪問控制。 |
反模式#
不相關數據無限增長#
雖然 ADLS Gen2 存儲不是很昂貴,并且允許您在存儲帳戶中存儲大量數據,但即使您不需要整個數據語料庫,生命周期管理策略的缺失也可能最終導致存儲中數據的增長非常快為您的方案。我們看到這種數據增長的兩種常見模式是:-
- 使用較新版本的數據刷新數據——客戶通常會保留一些較舊版本的數據以供分析,當同一數據有一段時間刷新時,例如當上個月的客戶參與數據在 30 天的滾動窗口中每天刷新時,您每天都會獲得 30 天的參與數據,如果您沒有適當的清理流程,您的數據可能會呈指數級增長。
- 工作區數據積累——在工作區數據區,您的數據平臺的客戶,即 BI 分析師或數據科學家可以帶來他們自己的數據集 通常,我們已經看到,當未使用的數據是留在存儲空間周圍。
我如何管理對我的數據的訪問?#
ADLS Gen2 支持結合 RBAC 和 ACL 來管理數據訪問的訪問控制模型。您可以在此處找到有關訪問控制的更多信息。除了使用 RBAC 和 ACL 使用 AAD 身份管理訪問之外,ADLS Gen2 還支持使用 SAS 令牌和共享密鑰來管理對 Gen2 帳戶中數據的訪問。
我們從客戶那里聽到的一個常見問題是何時使用 RBAC 以及何時使用 ACL 來管理對數據的訪問。RBAC 允許您將角色分配給安全主體(AAD 中的用戶、組、服務主體或托管標識),并且這些角色與容器中數據的權限集相關聯。RBAC 可以幫助管理與控制平面操作(例如添加其他用戶和分配角色、管理加密設置、防火墻規則等)或數據平面操作(例如創建容器、讀寫數據等)相關的角色。有關 RBAC 的更多信息,您可以閱讀這篇文章。
RBAC 本質上僅限于頂級資源——ADLS Gen2 中的存儲帳戶或容器。您還可以在資源組或訂閱級別跨資源應用 RBAC。ACL 允許您將安全主體的一組特定權限管理到更窄的范圍 - ADLS Gen2 中的文件或目錄。有 2 種類型的 ACL——訪問 ADL 控制對文件或目錄的訪問,默認 ACL 是為與目錄關聯的目錄設置的 ACL 模板,這些 ACL 的快照由在下創建的任何子項繼承那個目錄。
關鍵考慮#
下表提供了如何使用 ACL 和 RBAC 來管理 ADLS Gen2 帳戶中數據權限的快速概覽——在較高級別,使用 RBAC 來管理粗粒度權限(適用于存儲帳戶或容器)并使用用于管理細粒度權限的 ACL(適用于文件和目錄)。
| Consideration | RBACs | ACLs |
|---|---|---|
| Scope | Storage accounts, containers. Cross resource RBACs at subscription or resource group level. | Files, directories |
| Limits | 2000 RBACs in a subscription | 32 ACLs (effectively 28 ACLs) per file, 32 ACLs (effectively 28 ACLs) per folder, default and access ACLs each |
| Supported levels of permission | Built-in RBACs or custom RBACs | ACL permissions |
在容器級別使用 RBAC 作為數據訪問控制的唯一機制時,請注意 2000 的限制,尤其是在您可能擁有大量容器的情況下。您可以在門戶的任何訪問控制 (IAM) 刀片中查看每個訂閱的角色分配數量。
建議#
- 為對象(通常是我們在客戶那里看到的目錄中的目錄)創建所需權限級別的安全組,并將它們添加到 ACL。對于要提供權限的特定安全主體,請將它們添加到安全組,而不是為它們創建特定的 ACL。遵循這種做法將幫助您最大限度地減少管理新身份訪問的過程——如果您想將新身份遞歸添加到容器中的每個文件和文件夾,這將需要很長時間。讓我們舉一個例子,您的數據湖中有一個目錄 /logs,其中包含來自服務器的日志數據。您可以通過 ADF 將數據攝取到此文件夾中,還可以讓服務工程團隊的特定用戶上傳日志并管理其他用戶到此文件夾。此外,您還有各種 Databricks 集群分析日志。您將創建 /logs 目錄并創建兩個具有以下權限的 AAD 組 LogsWriter 和 LogsReader。
- LogsWriter 添加到具有 rwx 權限的 /logs 文件夾的 ACL。
- LogsReader 添加到具有 r-x 權限的 /logs 文件夾的 ACL。
- ADF 的 SPN/MSI 以及用戶和服務工程團隊可以添加到 LogsWriter 組。
- Databricks 的 SPN/MSI 將添加到 LogsReader 組。
我選擇什么數據格式?#
數據可能以多種格式到達您的數據湖帳戶——人類可讀的格式,如 JSON、CSV 或 XML 文件,壓縮的二進制格式,如 .tar.gz 和各種大小——巨大的文件(幾 TB),如從本地系統導出 SQL 表或從 IoT 解決方案導出大量小文件(幾 KB),例如實時事件。雖然 ADLS Gen2 支持在不施加任何限制的情況下存儲所有類型的數據,但最好考慮數據格式以最大限度地提高處理管道的效率并優化成本——您可以通過選擇正確的格式和正確的文件大小來實現這兩個目標。Hadoop 有一組它支持的文件格式,用于優化存儲和處理結構化數據。讓我們看看一些常見的文件格式——Avro、Parquet 和 ORC。所有這些都是機器可讀的二進制文件格式,提供壓縮來管理文件大小,并且本質上是自描述的,文件中嵌入了模式。格式之間的區別在于數據的存儲方式——Avro 以基于行的格式存儲數據,而 Parquet 和 ORC 格式以列格式存儲數據。
關鍵考慮#
- Avro 文件格式適用于 I/O 模式更重的寫入或查詢模式傾向于完整檢索多行記錄。例如。Avro 格式受到消息總線的青睞,例如 Event Hub 或 Kafka 連續寫入多個事件/消息。
- 當 I/O 模式讀取量更大和/或查詢模式專注于記錄中的列的子集時,Parquet 和 ORC 文件格式受到青睞——其中可以優化讀取事務以檢索特定列而不是讀取整個記錄。
如何管理我的數據湖成本?#
ADLS Gen2 為您的分析場景提供數據湖存儲,目標是降低您的總擁有成本。可以在此處找到 ADLS Gen2 的定價。由于我們的企業客戶滿足多個組織的需求,包括中央數據湖上的分析用例,他們的數據和交易往往會急劇增加。由于很少或沒有集中控制,相關成本也會增加。本部分提供了可用于管理和優化數據湖成本的關鍵注意事項。
關鍵考慮#
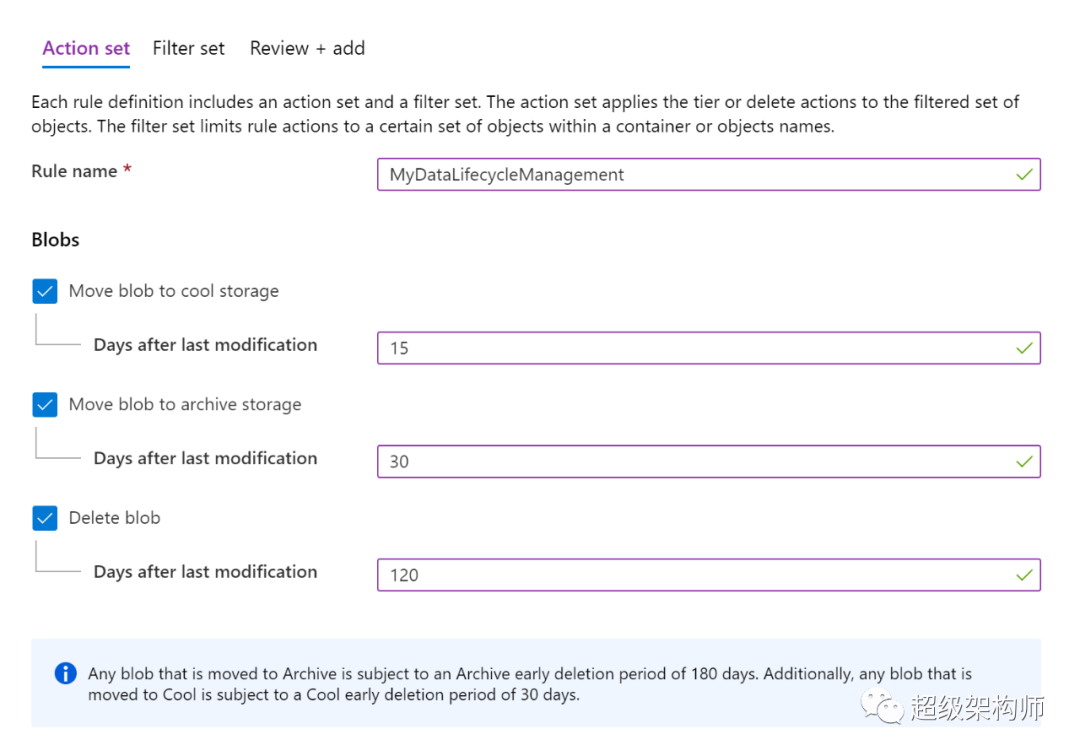
- ADLS Gen2 提供策略管理,您可以使用它來利用存儲在您的 Gen2 帳戶中的數據的生命周期。您可以在此處閱讀有關這些政策的更多信息。例如。如果您的組織有保留數據 5 年的保留策略要求,您可以設置策略以在數據 5 年未修改時自動刪除數據。如果您的分析方案主要對上個月攝取的數據進行操作,您可以將早于該月的數據移動到較低的層(冷層或存檔層),這些層的數據存儲成本較低。請注意,較低層的靜態數據價格較低,但交易策略較高,因此如果您希望頻繁處理數據,請不要將數據移動到較低層。
- 確保您為您的帳戶選擇了正確的復制選項,您可以閱讀數據冗余文章以了解有關您的選項的更多信息。例如。雖然 GRS 賬戶確保您的數據跨多個區域復制,但它的成本也高于 LRS 賬戶(數據在同一數據中心復制)。當您擁有生產環境時,GRS 等復制選項對于通過高可用性和災難恢復確保業務連續性非常有價值。但是,LRS 帳戶可能足以滿足您的開發環境。
- 正如您從 ADLS Gen2 的定價頁面中看到的,您的讀寫交易按 4 MB 的增量計費。例如。如果您執行 10,000 次讀取操作,并且每次讀取的文件大小為 16 MB,則您需要為 40,000 次交易付費。當您在事務中讀取幾 KB 的數據時,您仍需為 4 MB 的事務付費。優化單個事務中的更多數據,即優化事務中的更高吞吐量不僅可以節省成本,還可以極大地提高您的性能。
如何監控我的數據湖?#
了解您的數據湖的使用方式及其執行方式是操作您的服務并確保它可供使用其中包含的數據的任何工作負載使用的關鍵組成部分。這包括:
- 能夠根據頻繁操作來審計您的數據湖
- 了解關鍵性能指標,例如高延遲的操作
- 了解常見錯誤、導致錯誤的操作以及導致服務端節流的操作
關鍵考慮#
數據湖的所有遙測數據均可通過 Azure Monitor 中的 Azure 存儲日志獲得。Azure Monitor 中的 Azure 存儲日志是 Azure 存儲的一項新預覽功能,它允許您的存儲帳戶與 Log Analytics、事件中心以及使用標準診斷設置將日志存檔到另一個存儲帳戶之間的直接集成。可以在 Azure 存儲監視數據參考中找到指標和資源日志的完整列表及其關聯架構的參考。
- 在考慮訪問方式時,選擇將 Azure 存儲日志中的日志存儲在何處變得很重要:
- 如果要近乎實時地訪問日志并能夠將日志中的事件與來自 Azure Monitor 的其他指標相關聯,則可以將日志存儲在 Log Analytics 工作區中。這允許您使用 KQL 和作者查詢來查詢您的日志,這些查詢枚舉您工作區中的 StorageBlobLogs 表。
- 如果要存儲日志以用于近實時查詢和長期保留,可以配置診斷設置以將日志發送到 Log Analytics 工作區和存儲帳戶。
- 如果您想通過另一個查詢引擎(例如 Splunk)訪問您的日志,您可以配置您的診斷設置以將日志發送到事件中心并將日志從事件中心攝取到您選擇的目的地。
- 可以通過 Azure 門戶、PowerShell、Azure CLI 和 Azure 資源管理器模板啟用 Azure Monitor 中的 Azure 存儲日志。對于大規模部署,可以使用 Azure Policy 并完全支持修復任務。有關更多詳細信息,請參閱:
- Azure/社區政策
- ciphertxt/AzureStoragePolicy
Azure Monitor 中 Azure 存儲日志的常見 KQL 查詢
以下查詢可用于深入了解數據湖的性能和健康狀況:
- Frequent operations
StorageBlobLogs | where TimeGenerated > ago(3d) | summarize count() by OperationName | sort by count_ desc | render piechart - High latency operations
StorageBlobLogs | where TimeGenerated > ago(3d) | top 10 by DurationMs desc | project TimeGenerated, OperationName, DurationMs, ServerLatencyMs, ClientLatencyMs = DurationMs - ServerLatencyMs - Operations causing the most errors
StorageBlobLogs | where TimeGenerated > ago(3d) and StatusText !contains "Success" | summarize count() by OperationName | top 10 by count_ desc
Azure Monitor 中 Azure 存儲日志的所有內置查詢的列表可在 GitHub 上的 Azure Montior 社區的 Azure 服務/存儲帳戶/查詢文件夾中找到。
-
大數據分析
+關注
關注
1文章
135瀏覽量
17222 -
Azure
+關注
關注
1文章
125瀏覽量
13108
發布評論請先 登錄
相關推薦
AZURE IOT Hub接收數據的過程是什么
Azure云平臺軟件包示例程序展示設備與IoT中心之間進行數據交換的功能
阿里云宣布推出業內首個云原生企業級數據湖解決方案

如何將SAP歸檔數據合并到數據湖中
數據湖真的能取代數據倉庫嗎?【SNP SAP數據轉型 】
湖倉一體:揭秘數據湖架構現代化之道
湖倉一體:揭秘數據湖架構現代化之道






 工商網監
工商網監

評論