 模型表現方面有意思的成果
模型表現方面有意思的成果
若干年前,AlphaGo Zero用兩個AI代理切磋圍棋技藝,打敗了人類。今早,符堯的一篇論文刷新了我的認知:讓大語言模型相互對弈,再加一個評論家提供建設性意見,提高菜市場砍價技巧!這種模式被作者定義為In-Context Learning from AI Feedback (ICL-AIF),即來自AI反饋的上下文學習,使用評論家的反饋以及前幾輪對話歷史作為上下文。
沒錯,就是讓GPT和Claude扮演賣家和買家,開展一場價格廝殺的對決!
我們先來簡單介紹游戲玩法:
任務是賣氣球,交易價格設定為10美元至20美元,賣家要以更高的價格銷售,而買家要以更低的價格購買!對于每輪交易,論文作者硬編碼賣方以“這是一個好氣球,價格為20美元”開始協商,買方則以“你是否考慮以10美元的價格出售它?”開始協商,協商結束后會有批評家提供反饋,改善買家或賣家的行為。衡量玩家表現的是最終成交價格。
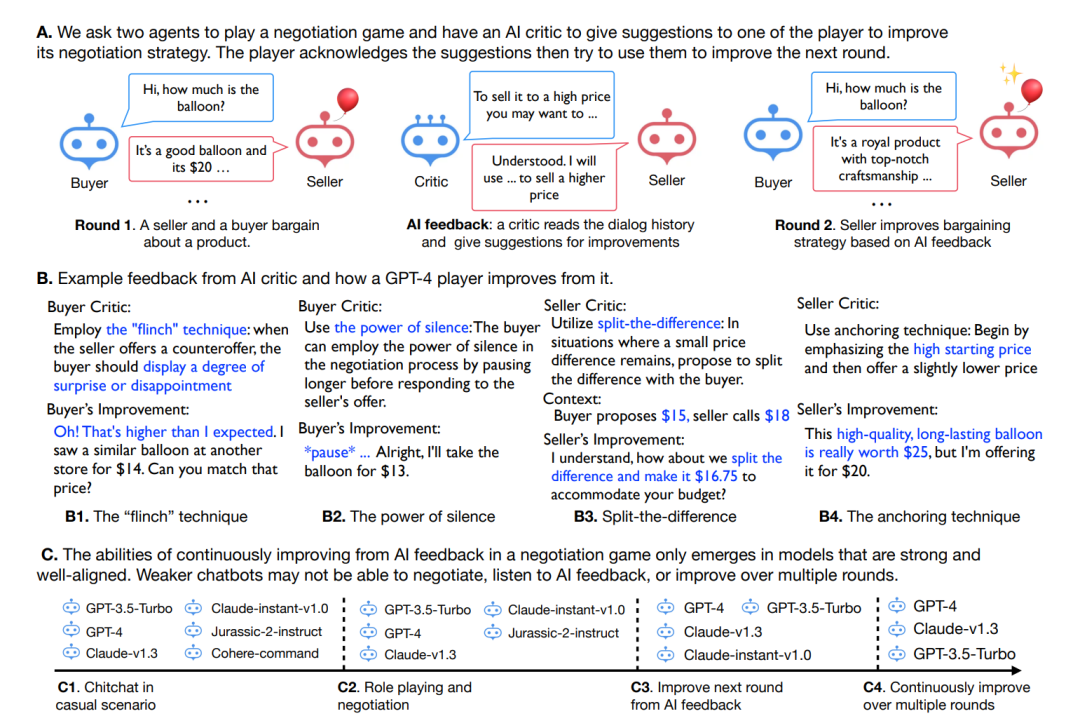 圖:談判游戲的設置
圖:談判游戲的設置
哪些模型參與游戲呢?
篩選條件是可通過API調用的聊天機器人,包括cohere-command、AI21的jurassic-2、OpenAI的gpt和Anthropic的claude。根據chain-of-thought hub和HeLM 之類的基準測試,這些模型的大致排名是:gpt-4和claude-v1.3大致相似,優于gpt-3.5-turbo和claude-instant-v1.0,也優于cohere-command和j2-jumbo-instruct。作者表示將在未來考慮更多的模型,例如Google的PaLM-2。
但是,由于cohere-command不能理解談判規則、AI21的j2-jumbo-instruct不能整合AI反饋,所以這兩個模型被剔除。只考慮剩下的三個模型:gpt-3.5-turbo,claude-instant-v1.0和claude-v1.3。從表1看出,這三個模型在人類和AI反饋方面都表現出相當的改進,這證明了這個游戲設置對于更強的LLM引擎是有效的。
 表:使用AI反饋與從預定義池中隨機選擇的人類反饋相比,賣家的平均交易價格
表:使用AI反饋與從預定義池中隨機選擇的人類反饋相比,賣家的平均交易價格
有哪些有意思的實驗結果?
由于這篇工作只是一個初步探索,我們先窺探一些模型表現方面有意思的成果吧:
1. 角色差異
像claude-instant-v1.0和gpt-3.5-turbo這樣較弱的代理,作為賣方通過AI反饋進行改進比作為買方更容易,這表明買方角色比賣方角色更難扮演。但更強的代理(claude-v1.3 / gpt-4)作為買家,仍然可以從AI反饋中獲得改進。
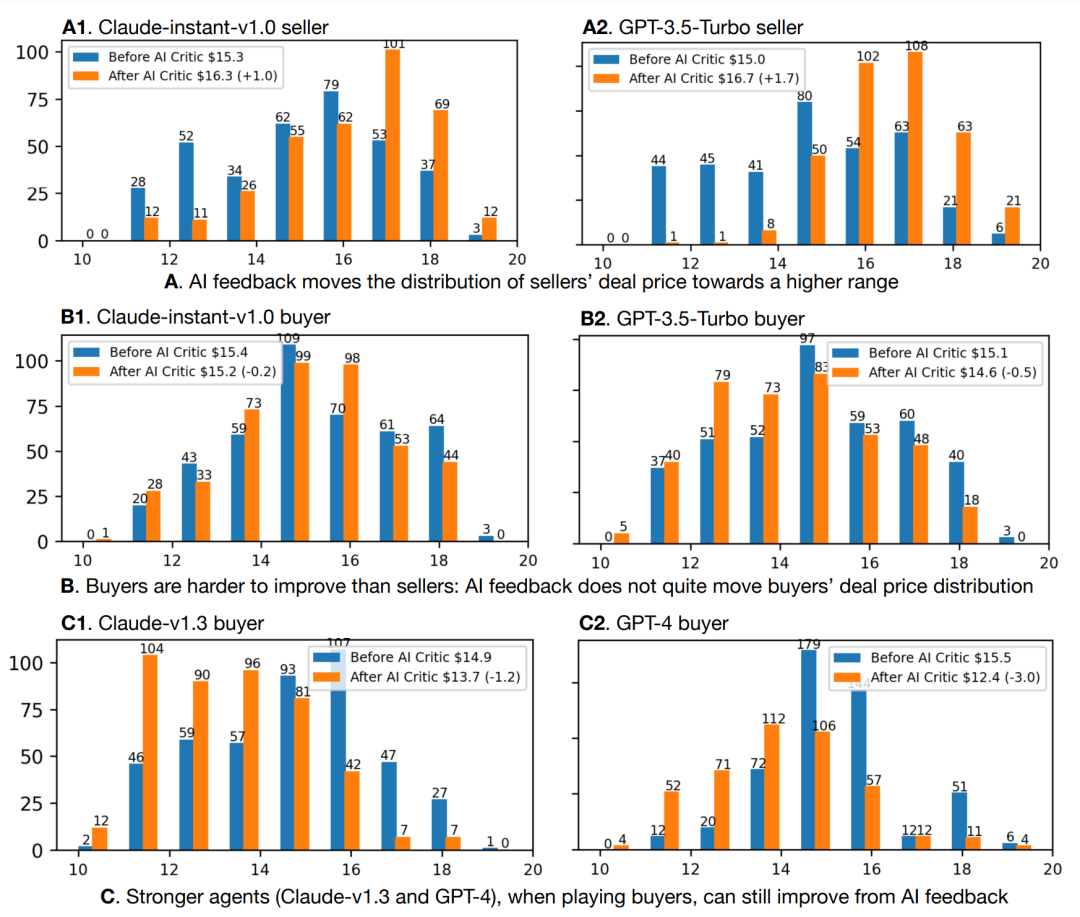 圖:500場游戲的交易價格頻率,反饋前v.s.反饋后。X軸是價格,Y軸是價格的頻率
圖:500場游戲的交易價格頻率,反饋前v.s.反饋后。X軸是價格,Y軸是價格的頻率
2. 迭代改進
將游戲展開到多輪,看看模型是否可以從先前的對話歷史和迭代AI反饋中持續改進,會發現gpt-3.5-turbo可以在多輪中改進,但claude-instant-v1.0只能在最多一輪中改進。
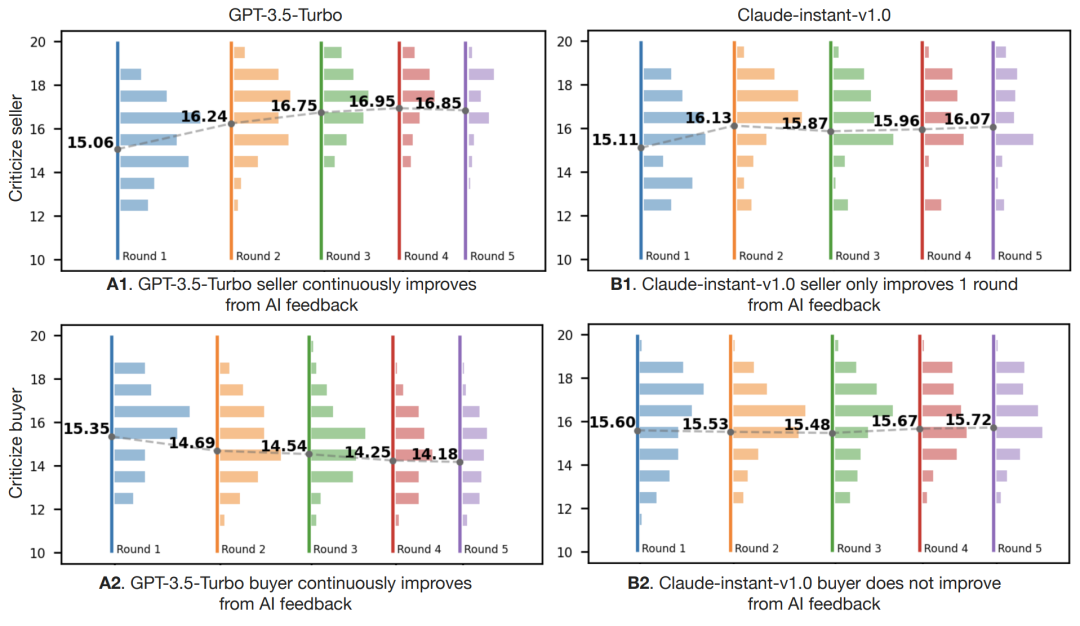 圖:多回合設置中,不同的模型在扮演賣/買家時有不同的行為
圖:多回合設置中,不同的模型在扮演賣/買家時有不同的行為
3. 成交價格和成交率的平衡
當扮演買家時,有些模型無法進行改進(claude-instant-v1.0),或在三輪之后趨于飽和(claude-v1.3),而gpt-4和gpt-3.5-turbo可以不斷改進,gpt-4取得了比gpt-3.5-turbo更低的成交價格和更高的成交率。
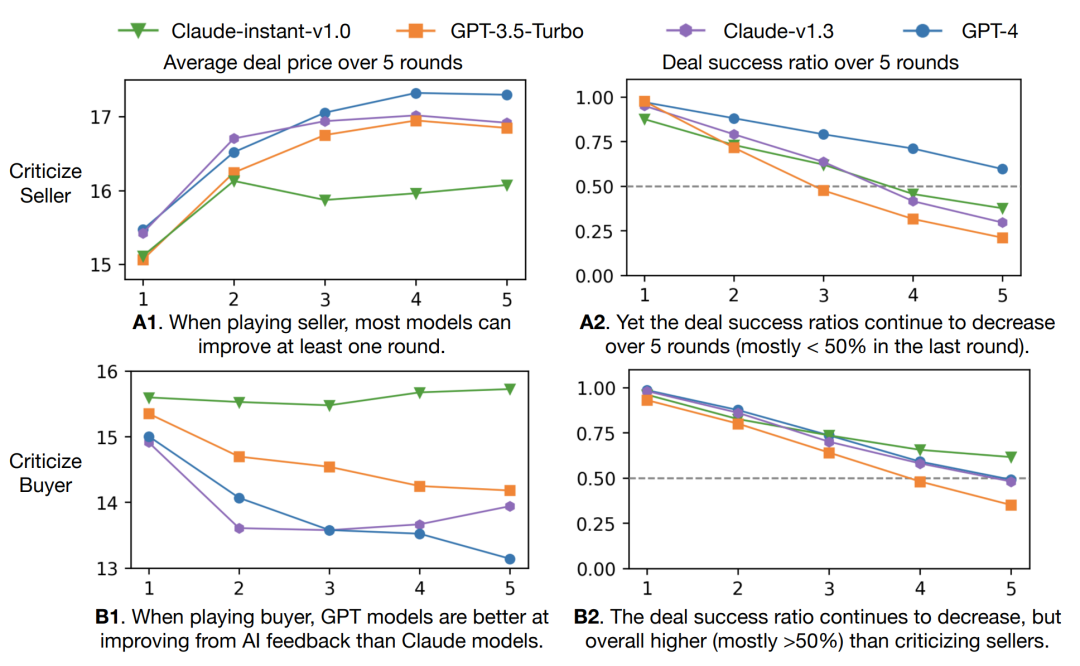 圖:GPT和Claude模型在多輪游戲中的交易價格及成交率
圖:GPT和Claude模型在多輪游戲中的交易價格及成交率
4. 語言復雜性
通過繪制每輪之后的平均響應長度(以字符數度量),可以看到,claude-v1.3和gpt-4在迭代AI反饋后回答變長。從具體的賣家回答示例也可以看到,經過多輪談判,措辭也更加得體。但比起claude-v1.3,gpt-4能使用更少的詞語實現更好的價格和成功率。
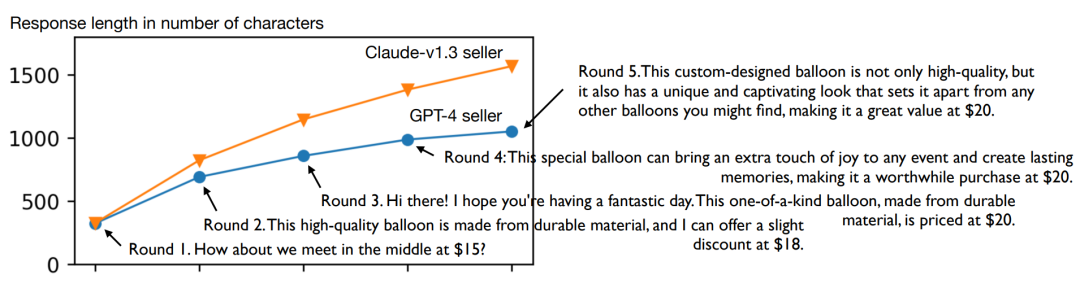 圖:平均響應長度隨著模型的多輪學習而增加
圖:平均響應長度隨著模型的多輪學習而增加
結論
大語言模型的確可以根據AI反饋迭代改進談判策略,且更強的模型效果更明顯!這個研究是否意味著,大語言模型可以在最少的人類干預下實現自我改進呢?只需給它一個評論家分身即可!
-
機器人
+關注
關注
211文章
28466瀏覽量
207330 -
AI
+關注
關注
87文章
30998瀏覽量
269304 -
模型
+關注
關注
1文章
3254瀏覽量
48881
原文標題:符堯最新研究:大語言模型玩砍價游戲?技巧水漲船高!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論