 Meta AI重磅推出LIMA!媲美GPT-4、無需RLHF就能對齊!
Meta AI重磅推出LIMA!媲美GPT-4、無需RLHF就能對齊!
昨天Meta AI+CMU這篇文章一出,twitter都炸了!
LIMA,只使用1000個精心挑選的樣本微調一個 65B LLaMa,無需RLHF,性能媲美甚至優于GPT-4!
論文:LIMA: Less Is More for Alignment
地址:https://arxiv.org/pdf/2305.11206.pdf
天下人苦“對齊”久矣!要讓預訓練語言模型的響應和特定任務和用戶偏好對齊,動輒需要百萬示例數據集上的instruction tuning、以及最近從人類反饋中進行的強化學習,才能實現ChatGPT級別的性能。
這篇文章旨在用簡單的方法解決復雜的對齊問題,作者提出表面對齊假說(Superficial Alignment Hypothesis),將對齊視為一個簡單的過程:學習與用戶交互的樣式或格式,來展示預訓練期間就已經獲得的知識和能力!
結果發現,少量高質量樣例上的簡單微調就足以與當今最先進的技術競爭!這也證明預訓練過程的強大威力和重要性,遠勝于大規模instruction tuning和強化學習!

實驗設置
數據集來源:這1000個近似真實用戶提示和高質量響應的示例中,有750個來自Stack Exchange和wikiHow這樣的社區論壇,其余250個則是手動編寫。
微調的超參數:使用AdamW進行微調,其中,權重衰減為0.1。沒有熱身步驟,初始學習率設置為,并線性地降至訓練結束時的。批量大小設為32個示例(更小的模型為64個),長度大于2048 token的文本將被裁剪。與以往的顯著不同是在殘差連接上應用dropout,從底層的 開始,線性升高到最后一層的 (更小的模型為 )。
基準模型
實驗將 LIMA 與五個基準模型進行比較:
(1)Alpaca 65B:將 LLaMa 65B 在 Alpaca 訓練集中的 52,000 個樣例上進行微調;(2) OpenAI 的DaVinci003,經過 RLHF 訓練的大語言模型;(3) 基于 PaLM 的 谷歌Bard;(4) Anthropic 的Claude, 52B 參數,經過從 AI 反饋進行強化學習 (Constitutional AI) 訓練;(5) OpenAI 的GPT-4,經過 RLHF 訓練,目前認為最先進的大語言模型。
結果
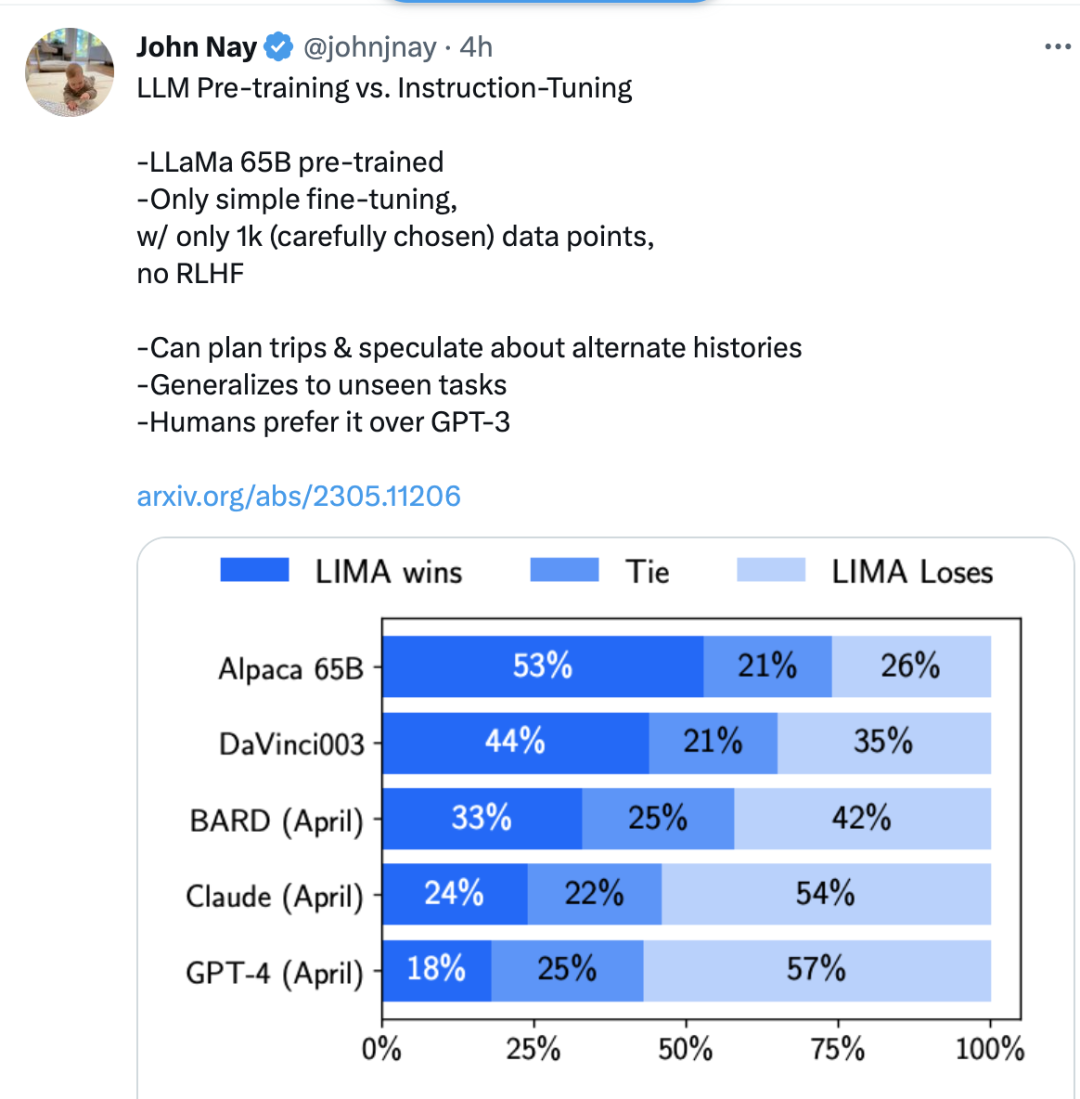
根據人類偏好的實驗結果,LIMA 的表現比 Alpaca 65B 和 DaVinci003 都要更好!盡管Alpaca 65B 的訓練數據量比 LIMA 高52倍,而DaVinci003 采用了 RLHF,一種被認為是更優秀的對齊方法。
Bard 情況要好,在 42% 的時間產生了比 LIMA 更好的響應;然而,這也意味著至少58%的時間, LIMA 的表現和 Bard 相當。
最后,雖然 Claude 和 GPT-4 通常比 LIMA 的表現更加出色,但很多情況下,LIMA 確實能產生更好的響應。有些諷刺的是,即使是 GPT-4 也有19% 的時間會認為 LIMA 的輸出更好。
我們來欣賞下LLaMa的出色表演。藍色文本為prompt,左邊是與訓練集中示例相關的提示,中間是訓練集中不存在的提示,右邊則是挑戰模型拒絕不安全行為。

數據質量和多樣性更重要
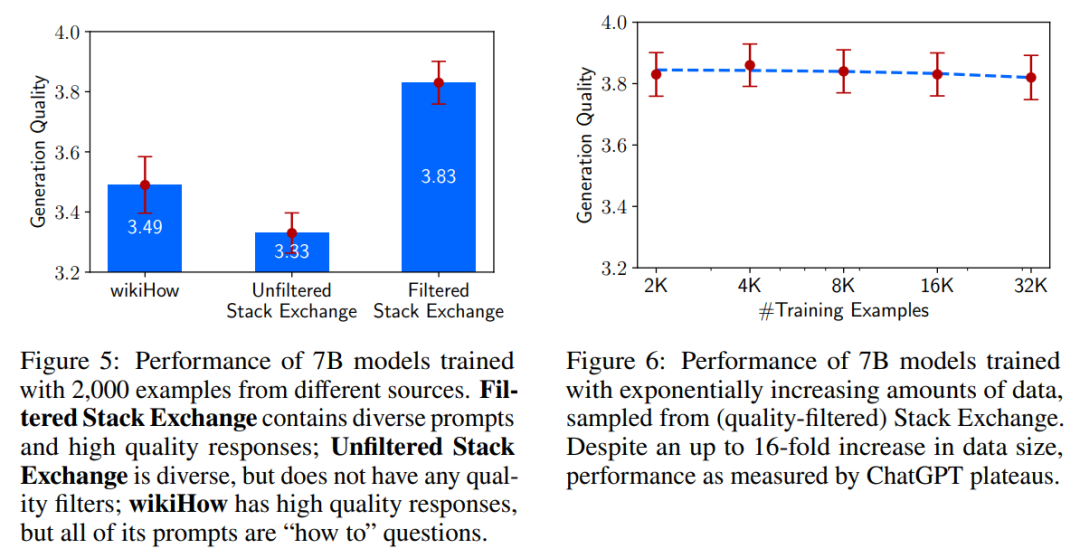
為了證明LIMA (Less Is More for Alignment)這個少勝于多的觀點,作者通過消融實驗研究了訓練數據的多樣性、質量和數量對模型的影響。
結果發現,數據質量對生成質量存在顯著影響,使用篩選過的數據集訓練的模型與使用未經過濾的數據源訓練的模型之間存在0.5分差異。但是,令人驚訝的是,示例數量的加倍并不能改善響應的質量。這表明對齊的 scaling laws 不僅僅取決于數量,而在于保證質量的同時提高提示的多樣性。
多輪對話
不過,一個僅在1,000個單輪對話上進行微調的模型能否從事多輪對話(Multi-Turn Dialogue)呢?
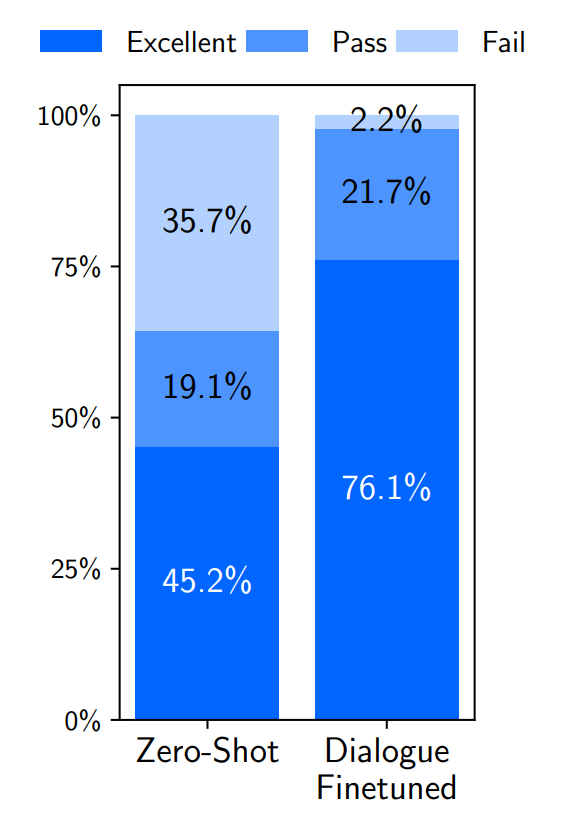
在零樣本上,LIMA的響應出奇地連貫,并引用了前面對話的信息。但很明顯,這個模型正在超出分布范圍;在10次交流中有6次,LIMA在3個互動之內未能遵循提示。
為了提高對話能力,作者收集了30個多輪對話鏈。使用組合的1,030個示例對預訓練的LLaMa模型進行微調,得到一個新版本的LIMA,并針對相同的提示進行了10次實時對話。發現加入這30個示例后生成質量顯著提升,優質響應比例從45.2%提高到76.1%!
30個樣本的有限監督就能調用模型的多輪對話能力,這也支持了作者提出的表面對齊假說,即:這些能力是在預訓練期間學習的。
總結
作者在discussion部分指出了該方法的一系列問題:比如構建數據集示例需要巨大的腦力投入、難以擴展,不如產品級別的模型穩健等~
話雖如此,這篇研究證明了簡單方法就有解決復雜對齊問題的潛力。幾乎所有大語言模型中的知識都是在預訓練期間學習的,教導模型產生高質量輸出只需少量但精心的instructional tuning.
簡單才是王道!
審核編輯 :李倩
-
語言模型
+關注
關注
0文章
524瀏覽量
10277 -
CMU
+關注
關注
0文章
21瀏覽量
15251 -
ChatGPT
+關注
關注
29文章
1561瀏覽量
7675
原文標題:Meta AI 重磅推出LIMA!媲美GPT-4、無需RLHF就能對齊!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT升級 OpenAI史上最強大模型GPT-4發布

AIGC(GPT-4)賦能通信行業應用白皮書
微軟GPT-4搜索引擎重大升級 新Bing開放AI能力
一樣媲美GPT-4、Bard,Meta發布650億參數語言模型LIMA

人工通用智能的火花:GPT-4的早期實驗
GPT-4已經會自己設計芯片了嗎?
GPT-4催生的接口IP市場空間
GPT-4沒有推理能力嗎?
ChatGPT重磅更新 OpenAI發布GPT-4 Turbo模型價格大降2/3

AI觀察 | 今年最火的GPT-4,正在締造科幻版妙手仁心!

ChatGPT plus有什么功能?OpenAI 發布 GPT-4 Turbo 目前我們所知道的功能






 工商網監
工商網監
評論