 大模型時代下,普通科研人怎么辦?
大模型時代下,普通科研人怎么辦?
眾所周知,隨著ChatGPT的爆火,AI全面進入大模型時代,NLP、CV大有統一之勢,回顧發布的各種大模型,Google BARD,openAI的GPT,Meta的SAM,百度的文心一言等等,這些基本都是有實力有技術的大公司引領著來研究的,但是作為一名普通的高校科研工作者,我們大多數基本上是沒有這么多資源算力去開發這樣的大模型的,但是大模型在各個方向效果精度幾乎是碾壓,導致很多領域方向就消失了,很多研究生也是很焦慮,可能在申的論文以及畢業答辯時肯定會comment你的性能差距大模型這么多,還有研究的必要嗎?
所以,大模型時代下,作為一名普普通通,沒有很多資源算力的科研人如何繼續研究呢?
最近在arXiv上刷到一篇文章,也許能提供一些思路。
論文名稱:
AV-SAM: Segment Anything Model Meets Audio-VisualLocalization and Segmentation
論文地址:
https://arxiv.org/abs/2305.01836

主要內容:
首先,Segment Anything Model(SAM)大模型是Meta提出的一種CV大模型,在1100萬張圖像中的10億個masks上進行訓練,并且在各種分割任務上具有很強的零樣本性能,它在打破分割邊界方面取得了重大進展,極大地促進了計算機視覺基礎模型的發展,這個視覺基礎模型由三個主要組件組成:圖像編碼器、提示編碼器和掩碼解碼器。
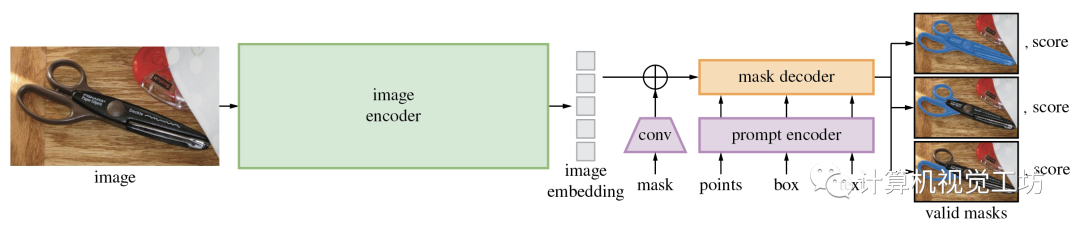

SAM的項目地址:https://github.com/facebookresearch/segment-anything
我們普通科研人如果想重新設計訓練這樣一個大模型顯然不現實,那么這篇論文的作者另辟蹊徑,雖然大模型的泛化性很好,在很多任務上做的不錯,但是不可能面面俱到,往往是大而不精的,這篇論文就利用已經預訓練好的SAM大模型去做更具體的下游任務——視聽定位和分割。
視聽定位和分割:
視聽定位和分割是以熱圖或掩模的方式預測視頻中單個聲源的位置。
所以,這篇arXiv的論文提出了一個簡單而有效的基于SAM大模型的視聽定位和分割框架,即AV-SAM,它可以生成與音頻相對應的發聲對象掩碼。具體而言,利用SAM中預先訓練的圖像編碼器的視覺特征,把它和音頻特征逐像素視聽融合來聚合跨模態表示,然后將聚合的跨模態特征輸入到提示編碼器和掩碼解碼器以生成最終的視聽分割掩碼。
方向主要包括:3D視覺領域各細分方向,比如相機標定|三維點云|三維重建|視覺/激光SLAM|感知|控制規劃|模型部署|3D目標檢測|TOF|多傳感器融合|AR|VR|編程基礎等。
Methods
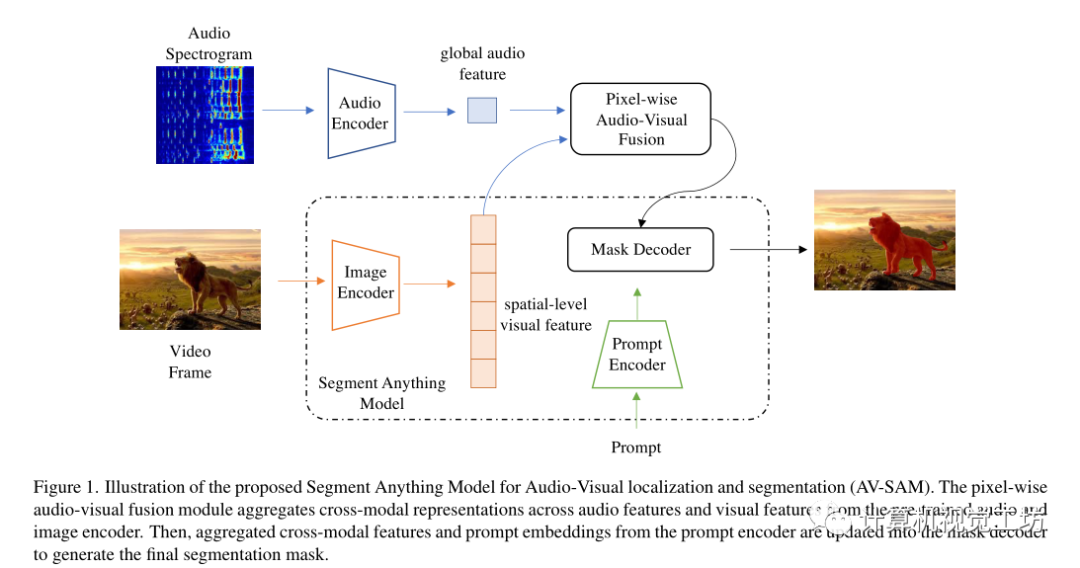
給定圖像和音頻,目標是預測圖像上聲音對象的像素掩碼。主要由兩個模塊組成,像素級視聽融合和視聽掩碼解碼器。
讓表示聽覺和視覺數據對,T、F分別表示音頻頻譜圖的時間和頻率維度。
首先使用雙流編碼器和投影頭對音頻和視覺輸入進行編碼,分別表示為,音頻編碼器計算全局音頻特征,視覺編碼器為每s階段生成多尺度空間級特征。
為了解決視聽分割問題,引入了逐像素視聽融合模塊來對多尺度空間級視覺特征和全局音頻表示進行編碼,以更新輸入到SAM的掩碼解碼器。在跨模態融合之后,第s階段的視聽特征被更新為:
其中,表示全局音頻表示ai的復制版本,該復制版本在第s階段重復次。這里表示1×1×1的卷積。通過這種特殊的視聽融合,推動學習到的視覺標記嵌入與全局音頻特征有區別地對齊。
利用逐像素視聽融合的優勢,使用多尺度特征圖的最后階段更新SAM中預訓練圖像編碼器的原始視覺特征。然后這些更新的多級特征圖被傳遞到SAM中的掩碼解碼器和提示編碼器,以生成最終的輸出掩碼,以像素級標注Y作為監督,將預測和標簽之間的二進制交叉熵(BCE)作為損失:
實驗:
在VGG-Sound中使用144k對的子集進行訓練,并在Flickr SoundNet測試集上用250對聲音對象的視聽對測試模型。
使用在ImageNet上預訓練的ResNet50通過特征圖的雙線性插值來生成偽掩碼。
對于輸入視覺幀,分辨率調整為1024×1024。對于輸入音頻,使用長度為3s的對數頻譜圖,采樣率為22050Hz。
使用輕量級的ResNet18作為音頻編碼器,并使用SAM發布的權重初始化視覺模型。該模型使用128的batch size,學習率為1e?4的Adam優化器進行了100個epochs的訓練。

與SAM相比,在兩個基準的所有指標方面都取得了最佳結果。
這表明了逐像素視聽融合對聚合跨模態輸入的重要性。

同時進行了消融研究以證明SAM凍結和微調預訓練重量的效果。
在表2中凍結/微調每個模塊(掩碼解碼器、提示編碼器、圖像編碼器)參數。
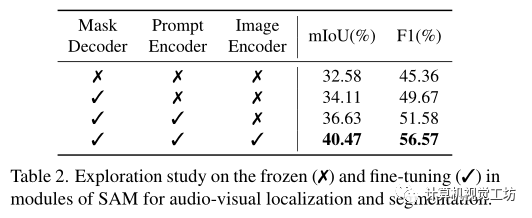
可以觀察到,對掩碼解碼器進行微調會增加視聽分割的結果,表明視聽掩碼解碼器在從聚合的跨模態特征生成準確掩碼方面的優勢。同時微調提示編碼器也提高了視覺聲源在所有指標方面的分割性能。
總結:
本篇是一篇基于大模型來做研究的文章,針對大模型在視聽定位和分割上不夠魯棒準確的問題,設計模塊去聚合跨模態表示,顯著提高了在這一具體任務上的性能。這也許可以給我們普通科研工作者一些啟發,如果我們不能重新研究設計訓練大模型情況下,我們可以在有限的資源算力下用大模型做一些具體的下游任務,擴展大模型的應用點,用他們已經預訓練好的模型權重去做更具體的任務,原始的大模型不可能面面俱到,其中很多點還是可以去做的。思考大模型如何在自己的研究方向上發揮它的價值,如何融合進自己的研究。
審核編輯 :李倩
-
解碼器
+關注
關注
9文章
1143瀏覽量
40767 -
編碼器
+關注
關注
45文章
3645瀏覽量
134623 -
模型
+關注
關注
1文章
3252瀏覽量
48874
原文標題:大模型時代下,普通科研人怎么辦?
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論