 編譯器優化那些事兒:寄存器分配
編譯器優化那些事兒:寄存器分配
概念介紹
在介紹算法之前,我們回顧下基本概念:
- |X| :X的度數,(無向圖中)節點的鄰居個數。
- CFG :控制流圖。
- successor :本文指CFG中基本塊的后繼。
- 四元式 :(op,result,arg1,arg2),比如常見的
a=b+c就可以看作四元式(+,a,b,c)。 - SSA(Static Single Assignment) :靜態單賦值。
- use/def :舉個例子,對于指令
n: c <- c+b來說 use[n]={c,b},def[n]={c}。 - live-in :當以下任一條件滿足時,則稱變量a在節點n中是live-in的,寫作a∈in[n]。節點n本文中代表指令。
- a∈use[n];
- 存在從節點n到其他節點的路徑使用了a且不包括a的def。
- live-out : 變量a在節點n的任一后繼的live-in集合中。寫作a∈out[n]

- 干涉 :在某一時刻,兩個變量在同一
live-in集合中。 - RIG(Register Interfere Graph) : 無向圖,其點集和邊集構成如下:
- 節點:變量
- 邊:如果兩節點存在干涉,那么這兩節點之間就有一條干涉邊
- k-著色 :給定無向圖G=(V,E),其中V為頂點集合,E為邊集合。將V分為k個組,每組中沒有相鄰頂點,可稱該圖G是k著色的。當然可著色前提下,k越小越好。
需要注意的是,我們后續的算法會作用在最普通的四元式上,而不是SSA。在介紹寄存器分配算法之前,我們需要活躍變量分析來構建干涉圖。
活躍變量分析與圖著色算法
活躍變量分析
簡單來說,就是計算每個點上有哪些變量被使用。
算法描述如下[1]:
`input: CFG = (N, E, Entry, Exit)
begin
// init
for each basic block B in CFG
in[B] = ?
// iterate
do{
for each basic block B other than Exit{
out[B] = ∪(in[s]),for all successors s of B
in[B] = use[B]∪(out[B]-def[B])
}
}until all in[] do't change`
活躍變量分析還有孿生兄弟叫Reaching Definitions,不過實現功能類似,不再贅述。
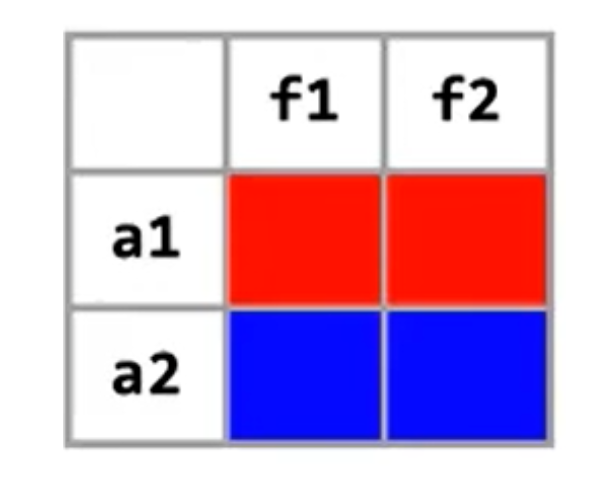
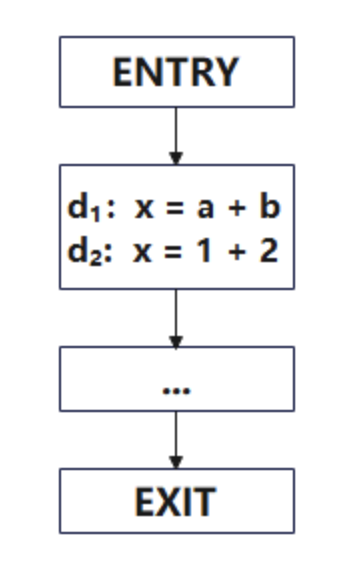
舉個例子:對圖1的代碼進行活躍變量分析

可以得到每個點的活躍變量如圖2所示:

過程呢?限于篇幅,僅僅計算第一輪指令1的結果,剩余部分讀者可自行計算。

可畫出RIG如圖3:

圖著色
經過上文的活躍變量分析,我們得到了干涉圖,下一步對其進行上色。
但是圖著色是一個NP問題,我們會采用啟發式算法對干涉圖進行著色。基本思路是:
- 找到度小于k的節點;
- 從圖中刪除;
- 判斷是否為可著色的圖;
- 迭代運行前3步直到著色完成。
算法描述[3]:
`input: RIG, k
// init
stack = {}
// iterate
while RIG != {} {
t := pick a node with fewer than k neighbors from RIG // 這里RIG可以先按度數排序節點再返回
stack.push(t)
RIG.remove(t)
}
// coloring
while stack != {} {
t := stack.pop()
t.color = a color different from t's assigned colored neighbors
}`
對于例子1,假設有4個寄存器r1、r2、r3、r4可供分配。

寄存器分配

所以圖3中的RIG是4-著色的。但如果只有三種顏色可用,怎么辦呢?
沒關系,我們還有大容量的內存,雖然速度慢了那么一點點。著色失敗就把變量放在內存里,用的時候再取出來。
依然是上例,但是k=3,只有三個顏色。

如果f的鄰居是2-著色的就好了,但不是。那就只能選一個變量存入內存了。這里我們選擇將變量f溢出至內存。溢出后的IR和RIG如圖:


所以,溢出其實是分割了變量的生命周期以降低被溢出節點的鄰居數量。溢出后的著色圖如圖6:

這里溢出變量f并不是明智的選擇,關于如何優化溢出變量讀者可自行查閱資料。
至此,圖著色算法基本介紹完畢。不過,如果代碼中的復制指令,應該怎么處理呢?
寄存器分配之前會有Copy Propagation和Dead Code Elimination優化掉部分復制指令,但是兩者并不是全能的。
比如:代碼段1中,我們可以合并Y和X。但是代碼段2中Copy Propagation就無能為力了,因為分支會導致不同的Y值。
`// 代碼段1
X = ...
A = 10
Y = X
Z = Y + A
return Z
// 代碼段2
X= A + B
Y = C
if (...) {Y = X}
Z = Y + 4`
所以,寄存器分配算法也需要對復制指令進行處理。如何處理?給復制指令的源和目標分配同一寄存器。
那么如何在RIG中表示呢?如果把復制指令的源和目標看作 RIG中相同的節點 ,自然會分配同一寄存器。
- 相同節點?可以擴展RIG:新增虛線邊,代表合并候選人。
- 成為合并候選人的條件是:如果X和Y的生命周期不重合,那么對于
Y=X指令中的X和Y是可合并的。 - 為了保證合并合法且不造成溢出:合并后局部的度數
那么如何計算局部的度數?介紹三種算法:
- 簡單算法
- Brigg's 算法
- George's 算法
- 簡單算法:
(|X|+|Y|)
比如k=2時,圖7應用簡單算法是沒辦法合并的
`

圖7\\[3\\]
但明顯圖7可以合并成圖8:

圖8\\[3\\]
Brigg's 算法:X和Y可合并,如果X和Y中度數≥k的鄰居個數<k。但是如果X的度數很大,算法效率就不高
George's算法:X和Y可合并,如果對Y的每個鄰居T,|T| ?比如k=2時,圖9就可以合并X和Y。或者t和x沖突。

相對于Brigg算法、George算法不用遍歷節點的鄰居。注意,圖著色時可以按節點度數從小到大依次訪問。
到此,圖著色算法介紹完畢。
線性掃描
接下來介紹一種不同思路的算法:線性掃描。算法描述如下[4]:
`LinearScanRegisterAllocation:
active := {}
for i in live interval in order of increasing start point
ExpireOldIntervals(i)
if length(avtive) == R
SpillAtInterval(i)
else
register[i] := a regsiter removed from pool of free registers
add i to active, sorted by increasing end point
ExpireOldInterval(i)
for interval j in active, in order of increaing end point
if endpoint[j] >= startpoint[i]
return
remove j from active
add register[j] to pool of free registers
SpillAtInterval(i)
spill := last interval in active
if endpoint[spill] > endpoint[i]
register[i] := register[spill]
location[spill] := new stack location
remove spill from active
add i to active, sorted by increasing end point
else
location[i] := new stack location`
live interval其實就是變量的生命期,用活躍變量分析可以算出來。不過需要標識第一次出現和最后一次出現的時間點。
舉個例子:


llvm中實現
在上文中介紹的算法都是作用在最普通的四元式上,但LLVM-IR是SSA形式,有PHI節點,但PHI節點沒有機器指令表示,所以在寄存器分配前需要把PHI節點干掉,消除PHI節點的算法限于篇幅不展開,如感興趣的話請后臺留言。
llvm作為工業級編譯器,有多種分配算法,可以通過llc的命令行選項-regalloc=pbqp|greedy|basic|fast來手動控制分配算法。
不同優化等級默認使用算法也不同:O2和O3默認使用greedy,其他默認使用fast。
fast算法的策略很簡單,掃描代碼并為出現的變量分配寄存器,寄存器不夠用就溢出到內存。用途主要是 調試 。
basic算法以linearscan為基礎并對life interval設置了溢出權重而且用優先隊列來存儲life interval。
greedy算法也使用優先隊列,但特點是先為生命期長的變量分配寄存器,而短生命期的變量可以放在間隙中,詳情可以參考[5]。
pbqp算法全稱是Partitioned Boolean Quadratic Programming,限于篇幅,感興趣的讀者請查閱[6]。
至于具體實現,自頂向下依次是:
TargetPassConfig::addMachinePasses含有寄存器分配和其他優化addOptimizedRegAlloc中是與寄存器分配密切相關的pass,比如上文提到的消除PHI節點addRegAssignAndRewriteOptimized是實際的寄存器分配算法寄存器分配相關文件在lib/CodeGen下的RegAllocBase.cpp、RegAllocGreedy.cpp、RegAllocFast.cpp、RegAllocBasic.cpp和RegAllocPBQP.cpp等。
RegAllocBase類定義了一系列接口,重點是selectOrSplit和enqueue/dequeue方法,數據結構的重點是priority queue。selectOrSplit方法可以類比上文中提到的SpillAtInterval。priority queue類比active list。簡要代碼如下:
void RegAllocBase::allocatePhysRegs() { // 1. virtual reg其實就是變量 while (LiveInterval *VirtReg = dequeue()) { // 2.selectOrSplit 會返回一個可用的物理寄存器然后返回新的live intervals列表 using VirtRegVec = SmallVector4>; VirtRegVec SplitVRegs; MCRegister AvailablePhysReg = selectOrSplit(*VirtReg, SplitVRegs); // 3.分配失敗檢查 if (AvailablePhysReg == ~0u) { ... } // 4.正式分配 if (AvailablePhysReg) Matrix->assign(*VirtReg, AvailablePhysReg); for (Register Reg : SplitVRegs) { // 5.入隊分割后的liver interval LiveInterval *SplitVirtReg = &LIS->getInterval(Reg); enqueue(SplitVirtReg); } }}
,>至于這四種算法的性能對比,我們主要考慮三個指標:運行時間、編譯時間和溢出次數。

橫坐標是測試集,縱坐標是以秒為單位的運行時間

橫坐標是測試集,縱坐標是編譯時間

從這三幅圖可以看出greedy算法在大多數測試集上都優于其他算法,因此greedy作為默認分配器是可行的。
小結
我們通過一個例子介紹了活躍變量分析和圖著色算法。借助活躍變量分析,我們知道了變量的生命期,有了變量生命期建立干涉圖,對干涉圖進行著色。如果著色失敗,可以選擇某個變量溢出到內存中。之后在RIG的基礎上介紹了寄存器合并這一變換。
然后我們簡單介紹了不同思路的寄存器分配算法:linearscan。最后介紹了llvm12中算法的實現并對比了llvm中四種算法的性能差異。
`-
寄存器
+關注
關注
31文章
5359瀏覽量
120806 -
SSA
+關注
關注
0文章
8瀏覽量
2968
發布評論請先 登錄
相關推薦
編譯器優化那些事兒(5):寄存器分配
編譯器優化的靜態調度介紹


基于C++編譯器的節點融合優化方法
編譯器優化那些事兒:別名分析概述
編譯器優化那些事兒之區域分析
編譯器的優化選項





 工商網監
工商網監
評論