 STM32采集傳感器數據通過冒泡排序取穩定值
STM32采集傳感器數據通過冒泡排序取穩定值
一、前言
在物聯網、單片機開發中,經常需要采集各種傳感器的數據。比如:溫度、濕度、MQ2、MQ3、MQ4等等傳感器數據。這些數據采集過程中可能有波動,偶爾不穩定,為了得到穩定的值,我們可以對數據多次采集,進行排序,去掉最大和最小的值,然后取平均值返回。
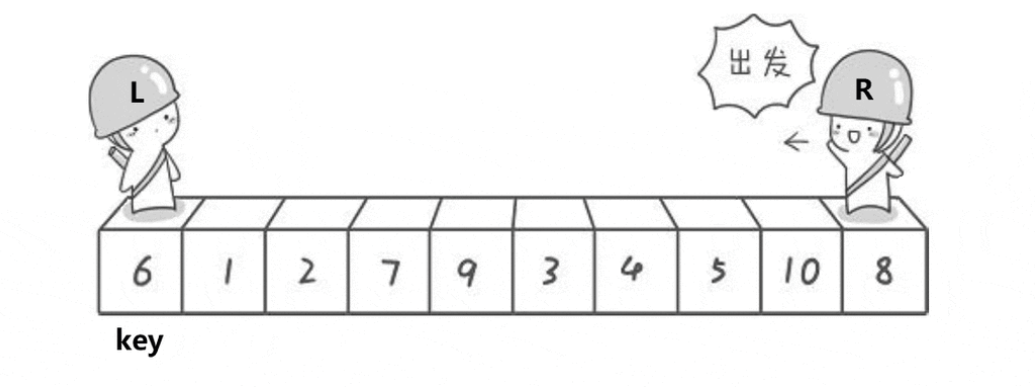
二、排序算法
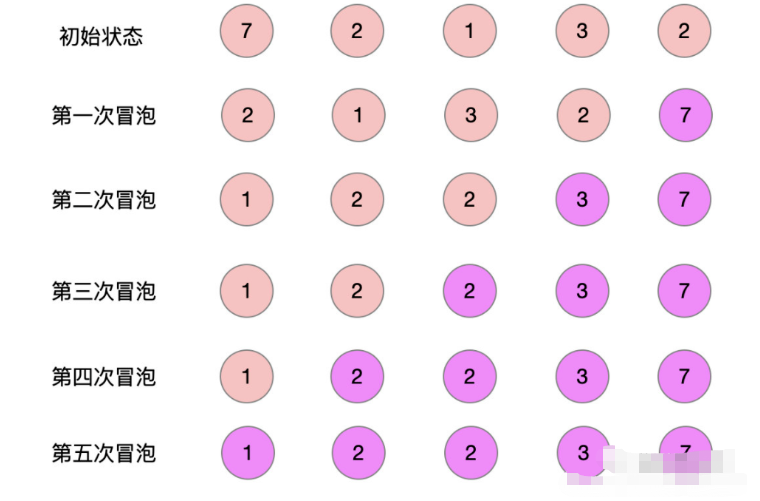
【1】冒泡排序
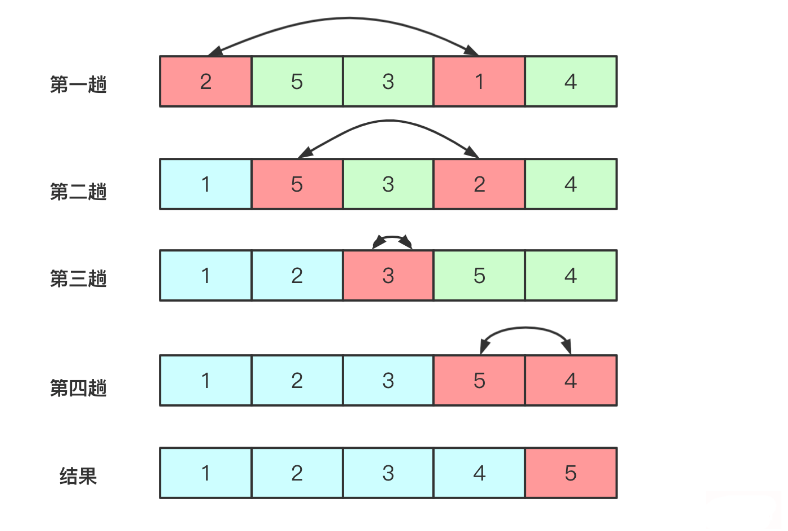
冒泡排序(Bubble Sort)是一種簡單的排序算法,也是最基礎、最容易理解的一種排序算法。它會遍歷要排序的數組,依次比較相鄰兩個元素的大小,如果前一個元素比后一個元素大,就交換這兩個元素的位置。
冒泡排序的過程如下:
- 從數組的第一個元素開始,依次比較相鄰的兩個元素,如果前一個元素比后一個元素大,則交換這兩個元素的位置。
- 繼續比較相鄰的元素,直到數組的最后一個元素。
- 重復執行步驟1和步驟2,直到整個數組都按照從小到大的順序排列好。
冒泡排序的時間復雜度是O(N^2),其中N是數組中元素的數量。在實際應用中,由于其時間復雜度較高,冒泡排序很少被用于大規模數據的排序,但它仍然是一種優秀的教學工具,因為它容易理解和實現,并且可以幫助初學者理解排序算法的基本思想。
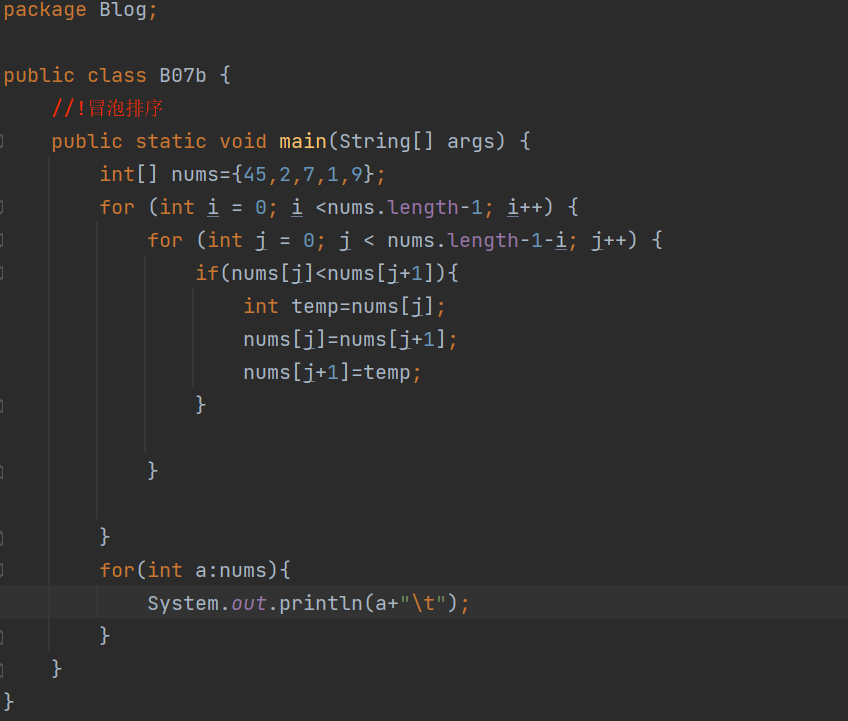
以下是C語言代碼的實現,封裝為名為calculateAverage的函數。
#define ARRAY_SIZE 20
?
// 冒泡排序算法函數
void bubbleSort(int arr[], int n) {
for(int i = 0; i < n-1; i++) {
for(int j = 0; j < n-i-1; j++) {
if(arr[j] > arr[j+1]) {
int temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
?
// 計算平均值函數,去除最大值和最小值
int calculateAverage() {
int arr[ARRAY_SIZE];
// 連續讀取20次數據
for(int i = 0; i < ARRAY_SIZE; i++) {
arr[i] = ReadADC();
}
// 對數組進行排序
bubbleSort(arr, ARRAY_SIZE);
// 去掉最大值和最小值
int sum = 0;
for(int i = 1; i < ARRAY_SIZE-1; i++) {
sum += arr[i];
}
// 計算平均值并返回
return sum / (ARRAY_SIZE-2);
}
在函數中,首先定義了一個常量ARRAY_SIZE表示需要讀取的數據的數量。然后,使用一個循環讀取20次數據,并將它們存儲到一個數組中。接著,用冒泡排序算法對數組進行排序。在排序完成后,計算數組中除去最大值和最小值的元素之和,并計算平均值。最后,返回計算得到的平均值。
【2】插入排序
插入排序(Insertion Sort)是一種簡單直觀的排序算法,它的基本思想是將一個元素插入到已排序好的序列中的適當位置,使得插入后仍然有序。
插入排序的過程如下:
- 假設第一個元素已經是排好序的序列,從第二個元素開始,依次將每個元素插入到已經排好序的序列中。
- 每次從未排序的部分中取出一個元素,與已排序的序列中的元素從后向前依次比較,找到插入的位置,即找到一個比當前元素小的值或者已經到了開頭位置。
- 將當前元素插入到已排序序列的合適位置上,重新調整已排序的序列,繼續對未排序的序列進行排序。
- 重復執行步驟2和步驟3,直到整個數組都按照從小到大的順序排列好。
插入排序的時間復雜度是O(N^2),其中N是數組中元素的數量。在實際應用中,插入排序通常適用于處理小規模數據或者已經接近有序的數據,因為此時插入排序的效率高于其他排序算法。
以下是C語言代碼的實現,封裝為名為calculateAverage的函數。
#define ARRAY_SIZE 20
?
// 插入排序算法函數
void insertionSort(int arr[], int n) {
for(int i = 1; i < n; i++) {
int key = arr[i];
int j = i-1;
while(j >= 0 && arr[j] > key) {
arr[j+1] = arr[j];
j--;
}
arr[j+1] = key;
}
}
?
// 計算平均值函數,去除最大值和最小值
int calculateAverage() {
int arr[ARRAY_SIZE];
// 連續讀取20次數據
for(int i = 0; i < ARRAY_SIZE; i++) {
arr[i] = ReadADC();
}
// 對數組進行排序
insertionSort(arr, ARRAY_SIZE);
// 去掉最大值和最小值
int sum = 0;
for(int i = 1; i < ARRAY_SIZE-1; i++) {
sum += arr[i];
}
// 計算平均值并返回
return sum / (ARRAY_SIZE-2);
}
在函數中,首先定義了一個常量ARRAY_SIZE表示需要讀取的數據的數量。然后,使用一個循環讀取20次數據,并將它們存儲到一個數組中。接著,用插入排序算法對數組進行排序。在排序完成后,計算數組中除去最大值和最小值的元素之和,并計算平均值。最后,返回計算得到的平均值。
【3】希爾排序
希爾排序(Shell Sort)是一種由Donald Shell在1959年發明的排序算法,它是插入排序的一種變體,旨在減少排序中元素的移動次數,從而使算法更快。希爾排序的基本思想是把數組中相距某個“增量”的元素組成一個子序列,對每個子序列進行插入排序,然后逐步縮小增量,重復進行上述操作,直到增量為1,最后再對整個數組進行一次插入排序。
希爾排序的過程如下:
- 選擇一個增量序列,將待排序的數組按照這個增量序列分成若干組(子序列)。通常,在第一次排序時,增量取數組長度的一半,以后每次將增量減半,直到增量為1。
- 對每個子序列進行插入排序,即將每個子序列中的元素按照遞增的順序插入到已排序好的序列中。
- 重復執行步驟2,改變增量,直到增量為1。
- 最后再對整個數組進行插入排序。
希爾排序的時間復雜度與所選取的增量序列有關。最壞情況下的時間復雜度為O(N^2),其中N是數組中元素的數量。但在大多數情況下,希爾排序的時間復雜度優于O(N^2),可以達到O(N log N)的級別。希爾排序的空間復雜度為O(1),因為它在排序過程中只需要常數個額外的存儲空間。
以下是C語言代碼實現,封裝為名為calculateAverage的函數。
#define ARRAY_SIZE 20
?
// 希爾排序算法函數
void shellSort(int arr[], int n) {
for(int gap = n/2; gap > 0; gap /= 2) {
for(int i = gap; i < n; i++) {
int temp = arr[i];
int j;
for(j = i; j >= gap && arr[j-gap] > temp; j -= gap) {
arr[j] = arr[j-gap];
}
arr[j] = temp;
}
}
}
?
// 計算平均值函數,去除最大值和最小值
int calculateAverage() {
int arr[ARRAY_SIZE];
// 連續讀取20次數據
for(int i = 0; i < ARRAY_SIZE; i++) {
arr[i] = ReadADC();
}
// 對數組進行排序
shellSort(arr, ARRAY_SIZE);
// 去掉最大值和最小值
int sum = 0;
for(int i = 1; i < ARRAY_SIZE-1; i++) {
sum += arr[i];
}
// 計算平均值并返回
return sum / (ARRAY_SIZE-2);
}
在函數中,首先定義了一個常量ARRAY_SIZE表示需要讀取的數據的數量。然后,使用一個循環讀取20次數據,并將它們存儲到一個數組中。接著,用希爾排序算法對數組進行排序。在排序完成后,計算數組中除去最大值和最小值的元素之和,并計算平均值。最后,返回計算得到的平均值。
審核編輯:湯梓紅
-
傳感器
+關注
關注
2552文章
51237瀏覽量
754753 -
單片機
+關注
關注
6039文章
44583瀏覽量
636494 -
數據
+關注
關注
8文章
7085瀏覽量
89203 -
物聯網
+關注
關注
2910文章
44778瀏覽量
374665 -
STM32
+關注
關注
2270文章
10910瀏覽量
356604
發布評論請先 登錄
相關推薦
冒泡排序
常用排序法之一 ——冒泡排序法和選擇排序法
嵌入式stm32實用的排序算法 - 交換排序
基于STM32單片機水質檢測PH值檢測采集傳感器模塊設計資料分享
冒泡排序的基本思想
php版冒泡排序是如何實現的?

怎樣運用Java實現冒泡排序和Arrays排序出來
jwt冒泡排序的原理





 工商網監
工商網監
評論